





Библиотека сайта rus-linux.net
The book is available and called simply "Understanding The Linux Virtual Memory Manager". There is a lot of additional material in the book that is not available here, including details on later 2.4 kernels, introductions to 2.6, a whole new chapter on the shared memory filesystem, coverage of TLB management, a lot more code commentary, countless other additions and clarifications and a CD with lots of cool stuff on it. This material (although now dated and lacking in comparison to the book) will remain available although I obviously encourge you to buy the book from your favourite book store :-) . As the book is under the Bruce Perens Open Book Series, it will be available 90 days after appearing on the book shelves which means it is not available right now. When it is available, it will be downloadable from http://www.phptr.com/perens so check there for more information.
To be fully clear, this webpage is not the actual book.
Next: 5.7 Copying To/From Userspace Up: 5. Process Address Space Previous: 5.5 Exception Handling Contents Index
Subsections
- 5.6.1 Handling a Page Fault
- 5.6.2 Demand Allocation
- 5.6.3 Demand Paging
- 5.6.4 Copy On Write (COW) Pages
5.6 Page Faulting
Pages in the process linear address space are not necessarily resident
in memory. For example, allocations made on behalf of a process
are not satisfied immediately as the space is just reserved with the
vm_area_struct. Other examples of non-resident pages include
the page having been swapped out to backing storage or writing a read-only
page.
Linux, like most operating systems, has a Demand Fetch policy as
its fetch policy for dealing with pages not resident. This states that the
page is only fetched from backing storage when the hardware raises a page
fault exception which the operating system traps and allocates a page. The
characteristics of backing storage imply that some sort of page prefetching
policy would result in less page faults [#!maekawa87!#] but Linux is
fairly primitive in this respect. When a page is paged in from swap space,
a number of pages after it, up to
![]() are read in by
are read in by
swapin_readahead() and placed in the swap cache. Unfortunately
there is only a chance that pages likely to be used soon will be adjacent in
the swap area making it a poor prepaging policy. Linux would likely benefit
from a prepaging policy that adapts to program behavior [#!kapl02!#].
There are two types of page fault, major and minor faults. Major page
faults occur when data has to be read from disk which is an expensive
operation, else the fault is referred to as a minor, or soft page
fault. Linux maintains statistics on the number of these types of
page faults with the task_struct![]()
maj_flt and
task_struct![]()
min_flt fields respectively.
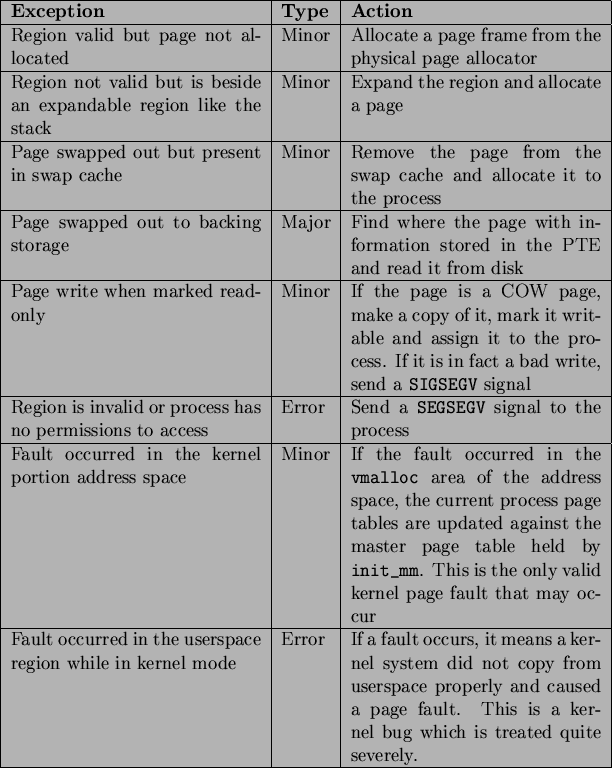
The page fault handler in Linux is expected to recognise and act on a number of different types of page faults listed in Table 5.4 which will be discussed in detail later in this chapter.
Each architecture registers an architecture-specific function for the
handling of page faults. While the name of this function is arbitrary,
a common choice is do_page_fault() whose call graph for
the x86 is shown in Figure 5.12.
![\includegraphics[width=15cm]{graphs/do_page_fault.ps}](/MyLDP/BOOKS/VirtMem/img35.png)
This function is provided with a wealth of information such as the address of the fault, whether the page was simply not found or was a protection error, whether it was a read or write fault and whether it is a fault from user or kernel space. It is responsible for determining which type of fault has occurred and how it should be handled by the architecture-independent code. The flow chart, in Figure 5.17, shows broadly speaking what this function does. In the figure, identifiers with a colon after them corresponds to the label as shown in the code.
handle_mm_fault() is the architecture independent top level
function for faulting in a page from backing storage, performing COW and so on.
If it returns 1, it was a minor fault, 2 was a major fault, 0 sends a SIGBUS
error and any other value invokes the out of memory handler.
5.6.1 Handling a Page Fault
Once the exception handler has decided the fault is a valid page
fault in a valid memory region, the architecture-independent function
handle_mm_fault(), whose call graph is shown in Figure 5.13, takes over. It allocates the required page table entries
if they do not already exist and calls handle_pte_fault().
Based on the properties of the PTE, one of the handler functions shown in
Figure 5.13 will be used. The first stage of the decision
is to check if the PTE is marked not present or if it has been allocated
which is checked by pte_present() and pte_none(). If
no PTE has been allocated (pte_none() returned true),
do_no_page() is called which handles Demand
Allocation, otherwise it is a page that has been swapped out to disk and
do_swap_page() performs Demand Paging.
![\includegraphics[width=10cm]{graphs/handle_mm_fault.ps}](/MyLDP/BOOKS/VirtMem/img36.png)
The second option is if the page is being written to. If the PTE is write
protected, then do_wp_page() is called as the page is a
Copy-On-Write (COW) page. A COW page is one which is shared between multiple
processes(usually a parent and child) until a write occurs after which
a private copy is made for the writing process. A COW page is recognised
because the VMA for the region is marked writable even though the individual
PTE is not. If it is not a COW page, the page is simply marked dirty as it
has been written to.
The last option is if the page has been read and is present but a fault still occurred. This can occur with some architectures that do not have a three level page table. In this case, the PTE is simply established and marked young.
5.6.2 Demand Allocation
When a process accesses a page for the very first time, the page has to be
allocated and possibly filled with data by the do_no_page()
function. If the parent VMA provided a vm_ops struct with a
nopage() function, it is called. This is of importance to a memory
mapped device such as a video card which needs to allocate the page and
supply data on access or to a mapped file which must retrieve its data from
backing storage. We will first discuss the case where the faulting page is
anonymous as this is the simpliest case.
5.6.2.0.1 Handling anonymous pages
If vm_area_struct![]()
vm_ops field is not filled
or a nopage() function is not supplied, the function
do_anonymous_page() is called to handle an anonymous
access. There are only two cases to handle, first time read and first
time write. As it is an anonymous page, the first read is an easy case
as no data exists so the system-wide empty_zero_page
which is just a page of zeros5.11 is mapped for the PTE and the PTE is write
protected. The PTE is write protected so that another page fault will occur
if the process writes to the page.
![\includegraphics[width=8cm]{graphs/do_no_page.ps}](/MyLDP/BOOKS/VirtMem/img37.png)
If this is the first write to the page alloc_page() is called to
allocate a free page (see Chapter 7) and
is zero filled by clear_user_highpage(). Assuming the page was
successfully allocated, the Resident Set Size (RSS) field in the
mm_struct will be incremented; flush_page_to_ram()
is called as required when a page has been inserted into a userspace process
by some architectures to ensure cache coherency. The page is then inserted
on the LRU lists so it may be reclaimed later by the page reclaiming code.
Finally the page table entries for the process are updated for the new mapping.
5.6.2.0.2 Handling file/device backed pages
If backed by a file or device, a nopage() function will be
provided. In the file backed case the function filemap_nopage()
is the nopage() function for allocating a page and reading a
page-sized amount of data from disk. Each device driver provides a different
nopage() whose internals are unimportant to us here as long as it
returns a valid struct page to use.
On return of the page, a check is made to ensure a page was successfully
allocated and appropriate errors returned if not. A check is then made to see
if an early COW break should take place. An early COW break will take place
if the fault is a write to the page and the VM_SHARED flag is
not included in the managing VMA. An early break is a case of allocating a
new page and copying the data across before reducing the reference count to
the page returned by the nopage() function.
In either case, a check is then made with pte_none() to ensure there
is not a PTE already in the page table that is about to be used. It is possible
with SMP that two faults would occur for the same page at close to the same
time and as the spinlocks are not held for the full duration of the fault,
this check has to be made at the last instant. If there has been no race,
the PTE is assigned, statistics updated and the architecture hooks for cache
coherency called.
5.6.3 Demand Paging
When a page is swapped out to backing storage, the function
do_swap_page() is responsible for reading the page back in.
The information needed to find it is stored within the PTE itself. The
information within the PTE is enough to find the page in swap. As pages
may be shared between multiple processes, they can not always be swapped
out immediately. Instead, when a page is swapped out, it is placed within
the swap cache.
![\includegraphics[width=17cm]{graphs/do_swap_page.ps}](/MyLDP/BOOKS/VirtMem/img38.png)
A shared page can not be swapped out immediately because there is no way
of mapping a struct page to the PTEs of each process it is
shared between. Searching the page tables of all processes is simply far too
expensive. It is worth noting that the late 2.5.x kernels and 2.4.x with a
custom patch have what is called Reverse Mapping (RMAP). With
RMAP, the PTEs a page is mapped by are linked together by a chain so they
can be reverse looked up.
With the swap cache existing, it is possible that when a fault occurs it still exists in the swap cache. If it is, the reference count to the page is simply increased and it is placed within the process page tables again and registers as a minor page fault.
If the page exists only on disk swapin_readahead() is called
which reads in the requested page and a number of pages after it. The number
of pages read in is determined by the variable page_cluster
defined in mm/swap.c. On low memory machines with less than
16MiB of RAM, it is initialised as 2 or 3 otherwise. The number of pages
read in is
![]() unless a bad or empty swap entry
is encountered. This works on the premise that a seek is the most expensive
operation in time so once the seek has completed, the succeeding pages should
also be read in.
unless a bad or empty swap entry
is encountered. This works on the premise that a seek is the most expensive
operation in time so once the seek has completed, the succeeding pages should
also be read in.
5.6.4 Copy On Write (COW) Pages
Traditionally when a process forked, the parent address space was copied to duplicate it for the child. This was an extremely expensive operation as it is possible a significant percentage of the process would have to be swapped in from backing storage. To avoid this considerable overhead, a technique called Copy-On-Write (COW) is employed.
![\includegraphics[width=17cm]{graphs/do_wp_page.ps}](/MyLDP/BOOKS/VirtMem/img39.png)
During fork, the PTEs of the two processes are made read-only so that when a
write occurs there will be a page fault. Linux recognises a COW page because
even though the PTE is write protected, the controlling VMA shows the region
is writable. It uses the function do_wp_page() to handle
it by making a copy of the page and assigning it to the writing process.
If necessary, a new swap slot will be reserved for the page. With this
method, only the page table entries have to be copied during a fork.
Footnotes
Next: 5.7 Copying To/From Userspace Up: 5. Process Address Space Previous: 5.5 Exception Handling Contents Index Mel 2004-02-15