Библиотека сайта rus-linux.net
Что каждый программист должен знать о памяти. Часть 5.
Оригинал: What every programmer should know about memory. Memory part 5: What programmers can do.
Автор: Ulrich Drepper
Дата публикации: 23.10.2007
Перевод: Капустин С.В.
Дата перевода: 30.10.2009
6. Что могут делать программисты - оптимизация кэша
Исходя из изложенного в предыдущих главах ясно, что существует много, очень много возможностей для программиста влиять на производительность программы, позитивно или негативно. И это только для операций, связанных с использованием памяти. Мы будем описывать эти возможности снизу вверх - начнем с нижних уровней физического доступа к памяти и кэшу L1 и закончим функциональностью операционной системы, которая влияет на работу с памятью.
6.1 Обход кэша
Когда данные произведены и не (сразу) используются снова, тот факт, что операции сохранения в памяти требуют сначала чтения полной строки кэша, затем модификации кэшированных данных, отрицательно сказывается на производительности. Эта операция выталкивает из кэшей данные, которые могут понадобится снова, заменяя их на данные, которые не скоро понадобятся. Это особенно верно для больших структур данных, таких как матрицы, которые заполняются и затем используются позднее. Прежде чем заполнен последний элемент матрицы, из-за большого размера первые элементы выталкиваются, делая кэширование записи неэффективным.
Для этой и подобных ситуаций процессоры поддерживают запись данных методом "не промежуточного" (non-temporal) сохранения. "Не промежуточное" в этом контексте означает, что данные будут использоваться не скоро, поэтому нет смысла их кэшировать. Это "не промежуточное" сохранение не читает строку из кэша и не меняет её, вместо этого новые данные сохраняются непосредственно в память.
Это может показаться весьма затратным процессом, но это не обязательно так. Процессор попытается использовать политику записи write-combining (см. 3.3.3), чтобы заполнить целую строку кэша. Если это удастся, не нужно будет никаких операций чтения. Для архитектур x86 и x86-64 gcc предоставляет несколько встроенных функций компилятора:
#include <emmintrin.h> void _mm_stream_si32(int *p, int a); void _mm_stream_si128(int *p, __m128i a); void _mm_stream_pd(double *p, __m128d a); #include <xmmintrin.h> void _mm_stream_pi(__m64 *p, __m64 a); void _mm_stream_ps(float *p, __m128 a); #include <ammintrin.h> void _mm_stream_sd(double *p, __m128d a); void _mm_stream_ss(float *p, __m128 a);
Эти инструкции работают наиболее эффективно, если они обрабатывают большие объемы данных за один раз. Данные загружаются из памяти, обрабатываются за один или более шагов, и затем записываются обратно в память. Данные идут "потоком" через процессор, отсюда и название функций.
Адреса памяти должны быть выравнены по 8 или 16 бит соответственно. В коде, использующем
мультимедийные расширения, можно заменять обычные встроенные функции _mm_store_* этими "не промежуточными" версиями. В программе перемножения матриц в разделе 9.1 мы не делаем этого, так как записанные значения вскоре снова будут использованы. Это пример, когда потоковые инструкции не подходят. Подробнее об этой программе в разделе 6.2.1.
Буфер процессора, используемый для write-combining, может хранить запросы на частичную запись в строку кэша только небольшое время. В общем необходимо использовать инструкции, модифицирующие одну строку кэша, одну следом за другой, чтобы метод write-combining мог действительно работать. Вот пример того, как это делать:
#include <emmintrin.h>
void setbytes(char *p, int c)
{
__m128i i = _mm_set_epi8(c, c, c, c,
c, c, c, c,
c, c, c, c,
c, c, c, c);
_mm_stream_si128((__m128i *)&p[0], i);
_mm_stream_si128((__m128i *)&p[16], i);
_mm_stream_si128((__m128i *)&p[32], i);
_mm_stream_si128((__m128i *)&p[48], i);
}
Предполагая, что указатель p подходящим образом выравнен, вызов этой функции устанавит
все байты адресуемой строки кэша равными c. Логика, управляющая write-combining, увидит
четыре сгенерированные инструкции movntdq и выполнит команду на запись в память только
когда последняя инструкция будет выполнена. Суммируя: эта последовательность кода позволит избежать
не только чтения строки кэша перед записью, но и засорения кэша данными, которые могут не скоро
понадобиться. Это может принести огромную пользу в определенных ситуациях. Примером обычного кода, использующего эту технику может служить функция memset из библиотеки C, которая должна использовать такую же последовательность кода для больших блоков.
Некоторые архитектуры предлагают специализированные решения. Архитектура PowerPC определяет инструкцию dcbz, которая может быть использована, чтобы очистить целую строку кэша. Эта инструкция не обходит кэш, так как для результата выделяется строка кэша, но данные из памяти не читаются. Она более ограничена, чем инструкции "не промежуточного" сохранения, так как строка кэша может быть заполнена только нулями и это загрязняет кэш (если данные не должны вскоре использоваться), но для неё не требуется логики write-combining.
Чтобы увидеть эти "не промежуточные" инструкции в действии, мы рассмотрим новый тест, измеряющий запись в матрицу, организаванную как двумерный массив. Компилятор располагает матрицу в памяти так, что левый (первый) индекс адресует строку, элементы которой располагаются в памяти последовательно. Правый (второй) индекс адресует элементы строки. Тестовая программа проходит матрицу двумя путями: сначала во внутреннем цикле увеличивается номер колонки, потом во внутреннем цикле увеличивается номер строки. Это означает, что мы имеем процесс как на рисунке 6.1.
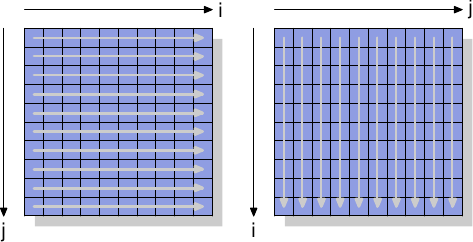
Рисунок 6.1: Образцы доступа к матрице
Мы измеряем сколько потребуется времени для того чтобы инициализировать матрицу размером 3000×3000. Чтобы увидеть как ведет себя память, мы используем инструкции сохранения, которые не используют кэш. На процессорах архитектуры IA-32 для этого используется индикатор ⌠non-temporal hint■. Для сравнения мы измеряем также обычные операции сохранения. Результаты приведены в таблице 6.1.
Приращение внутреннего цикла Строка Колонка Обычная 0.048с 0.127с Не промежуточная 0.048с 0.160с Table 6.1: Инициализация матрицы
Для обычной записи, которая использует кэш, мы видим ожидаемый результат: если память используется последовательно, мы имеем гораздо лучший результат, 0.048с на всю операцию, что составляет примерно 750Мб/с, в сравнении с более или менее случайным доступом который занимает 0.127с (около 280Мб/с). Матрица достаточно велика, чтобы сделать кэш неэффективным.
Нас здесь больше интересует запись, делаемая в обход кэша. Может показаться удивительным, что последовательный доступ здесь такой же быстрый как в случае использования кэша. Причина этого в том, что процессор использует политику записи write-combining как объяснялось выше. К тому же правила упорядочивания памяти для "не промежуточной" записи ослаблены: программа должна явным образом указывать барьеры памяти (инструкция sfence для процессоров x86 и x86-64). Это означает, что процессор имеет больше свободы при записи данных и использует доступную пропускную способность наиболее эффективно.
В случае доступа по колонкам во внутреннем цикле ситуация другая. Результат значительно медленнее, чем при использовании кэша (0.16с, около 225Мб/с). Здесь мы видим, что write combining невозможно и каждая ячейка памяти адресуется индивидуально. Это требует постоянного выбора новых строк в чипе RAM с сопутствующими этому задержками. Результат на 25% хуже, чем при использовании кэша.
В отношении чтения, процессорам до недавних пор недоставало поддержки, если не считать слабых индикаторов, использующих инструкции предварительной выборки "не промежуточного" доступа (NTA, non-temporal access). Для чтения нет эквивалента политике write-combining, что особенно плохо для некэшируемой памяти, такой как отображаемый в память ввод/вывод. Intel в расширениях SSE4.1 вводит загрузки NTA. Они реализованы с использованием небольшого количества потоковых буферов загрузки, каждый буфер содержит строку кэша. Первая инструкция movntdqa для заданной строки кэша загружает строку кэша (т.е. строку, которая могла бы быть загружена в кэш) в буфер, возможно замещая там другую строку. Последующие обращения, выравненные по 16 байт, к этой строке будут обслуживаться буфером с небольшими затратами. Если для этого не будет других причин, то строка кэша не будет загружена в кэш, что позволит загружать большие объемы памяти, не загрязняя кэш. Компилятор предоставляет встроенную функцию для этой инструкции
#include <smmintrin.h> __m128i _mm_stream_load_si128 (__m128i *p);
Эта встроенная функция должна быть использована много раз с адресами 16-байтовых блоков, передаваемых в качестве параметра, пока не прочитаны все строки кэша. Только тогда можно начинать следующую строку кэша. Так как буферов чтения несколько, возможно чтение из двух мест в памяти одновременно.
Из этого эксперимента мы должны вынести то, что современные процессоры очень хорошо оптимизируют некэшированный доступ на запись и (с недавних пор) на чтение, при условии что этот доступ последовательный. Это знание может быть очень полезно при работе с большими структурами данных, которые используются только один раз. Второе - кэши могут помочь покрыть некоторые, хотя и не все, затраты на произвольный доступ к памяти. Произвольный доступ в этом примере на 70% медленнее из-за особенностей устройства доступа к RAM. Пока эти устройства не поменяются, произвольного доступа следует по возможности избегать.
В разделе, посвященном предварительной выборке мы еще рассмотрим "не промежуточный" флаг.
| Назад | Оглавление | Вперед |