





Библиотека сайта rus-linux.net
Что каждый программист должен знать о памяти.
Часть 4: Поддержка устройств NUMA
Оригинал: "Memory part 4: NUMA support"Автор: Ulrich Drepper
Дата публикации: October 17, 2007
Перевод: Н.Ромоданов
Дата перевода: апрель 2012 г.
| Назад | Оглавление | Вперед |
5.4 Стоимость удаленного доступа
Дистанция является релеватным значением. В работе [amdccnuma] фирма AMD приводит документацию по затратам NUMA для машин с четырьмя соединениями. На рис.5.3 приведены значения для операций записи.
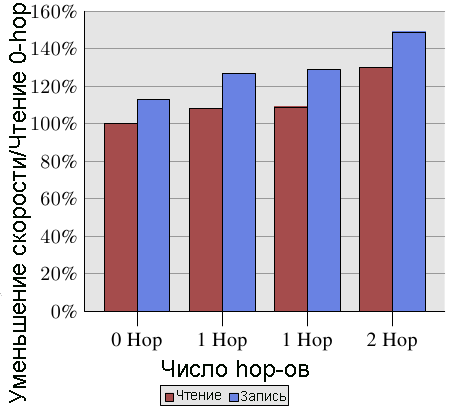
Рис.5.3: Приоизводительность записи / чтения для нескольких узлов
Запись, что не удивительно, осуществляется медленнее, чем чтение. Интересны значения затрат для случаев 1- hop и 2-hop. Случай с двумя значениями 1-hop немножко отличается. Подробности смотрите в [amdccnuma]. Мы из этого графика должны запомнить, что чтение и запись для 2-hop на 30% и 49% (соответственно) выполняется медленнее, чем чтение 0-hop. Запись для 2-hop на 32% медленнее, чем запись для 0-hop, и на 17% медленнее, чем запись для 0-hop. Большая разница может быть обусловлена взаимным расположением узлов процессора и памяти. В следующих поколениях процессоров фирмы AMD в каждом процессоре будет по четыре одинаковых соединения HyperTransport. В этом случае для машины с четырьмя соединениями значение диаметра будет одно и то же. При использовании восьми соединений проблема возникает снова с удвоенным эффектом, т.к. диаметр гиперкуба для восьми узлов равен трем.
Вся эта информация доступна, но она громоздка. В разделе 6.5 мы рассмотрим интерфейс, с помощью которого станет проще пользоваться этой информацией.
Последнюю часть информации система предоставляет в описании состояния самого процесса. Состояние процесса позволяет опререлить как в системе распределены по узлам файлы отображения памяти, страницы Copy-On-Write (COW) и анонимная память. { Copy-On-Write является способом, который часто используется в реализациях операционной в случаях, когда станица памяти принадлежит сначала одному владельцу, а затем эта страница должна копироваться другому пользователю. Во многих ситуациях копирование либо вообще не нужно, либо не нужно на начальном этапе. Оно имеет смысл в случае, когда кто-нибудь из пользователей изменяет содержимое памяти. Операционная система перехватывает операцию записи, делает копию страницы памяти, а затем позволяет продолжить операцию записи.} Для каждого процесса есть файл /proc/PID/numa_maps, где PID является идентификатором процесса, такой как показан на рисунке 5.2.
00400000 default file=/bin/cat mapped=3 N3=3 00504000 default file=/bin/cat anon=1 dirty=1 mapped=2 N3=2 00506000 default heap anon=3 dirty=3 active=0 N3=3 38a9000000 default file=/lib64/ld-2.4.so mapped=22 mapmax=47 N1=22 38a9119000 default file=/lib64/ld-2.4.so anon=1 dirty=1 N3=1 38a911a000 default file=/lib64/ld-2.4.so anon=1 dirty=1 N3=1 38a9200000 default file=/lib64/libc-2.4.so mapped=53 mapmax=52 N1=51 N2=2 38a933f000 default file=/lib64/libc-2.4.so 38a943f000 default file=/lib64/libc-2.4.so anon=1 dirty=1 mapped=3 mapmax=32 N1=2 N3=1 38a9443000 default file=/lib64/libc-2.4.so anon=1 dirty=1 N3=1 38a9444000 default anon=4 dirty=4 active=0 N3=4 2b2bbcdce000 default anon=1 dirty=1 N3=1 2b2bbcde4000 default anon=2 dirty=2 N3=2 2b2bbcde6000 default file=/usr/lib/locale/locale-archive mapped=11 mapmax=8 N0=11 7fffedcc7000 default stack anon=2 dirty=2 N3=2
Рис. 5.2: Содержимое файла /proc/PID/numa_maps
В файле важной информацией являются значения с N0 по N3, которые указывают на количество страниц, выделенных в качестве области памяти на узлах с 0 по 3. Ясно видно, что программа выполнялась в ядре на узле 3. Сама программа и измененные ею страницы располагаются на том же самом узле. Отображение, используемое только для чтения, такое, как первое отображение для ld-2.4.so и libc-2.4.so, а также общедоступный файл locale-archive, располагаются на других узлах.
Как мы видели на рисунке 5.3, скорость чтения между узлами падает на 9% и 30% соответственно для чтения в случаях 1-hop и 2-hop. Если при выполнении программы потребуется такое чтение, а в кэш-памяти L2 возникают промахи, то эти дополнительные затраты делят между собой кэш-строки. В случае, если память не является локальной памятью процессора, все затраты, измеренные для больших рабочих нагрузок, которые превышаю размер кэш-памяти, должны увеличиваться на 9% / 30%.
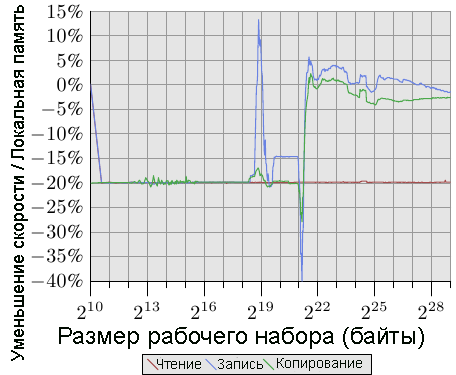
Рис.5.4: Использование удаленной памяти
Чтобы увидеть реально существующий эффект, мы точно также, как мы делали в разделе 3.5.1, можем измерить пропускную способность, но на этот раз с памятью, которая находится на удаленном узле на расстоянии в 1 hop. На рис.5.4 приведен результат этого теста в сравнении с данными, полученными при использовании локальной памяти. На графике есть несколько больших пиков в обоих направлениях, которые связаны с проблемой измерения многопоточного кода и которые можно проигнорировать. На этом графике важно то, что операции чтения всегда выполняются на 20% медленнее. Это значительно медленнее, чем 9% на рисунке 5.3, где, скорее всего, нет прерываний чтения и записи, что может особенностью старых версий процессоров. Об этом знает только фирма AMD.
Для рабочих наборов, которые по размерам вписываются в кэш-память, производительность записи и копирования также на 20% медленнее. Для рабочих наборов, размер которых превышает размер кэш-памяти, скорость записи по измерениям не сильно медленнее, чем операции на локальном узле. Скорость соединения достаточно быстрая для того, чтобы можно было работать с памятью. Доминирующим фактором является время ожидания в основной памяти.
| Назад | Оглавление | Вперед |