





Библиотека сайта rus-linux.net
База с "археологическим" принципом хранения данных
Оригинал: An Archaeology-Inspired Database
Автор: Yoav Rubin
Дата публикации: 20 October 2015
Перевод: Н.Ромоданов
Дата перевода: июль 2016 г.
Глава 7 из предварительной версии книги "500 Lines or Less", которая входит в серию "Архитектура приложений с открытым исходным кодом", том 4.
Creative Commons
Перевод сделан в соответствие с лицензией . С русским вариантом лицензии можно ознакомиться .
Сегодня мы представляем седьмую главу предварительной публикации нашего нового сборника «500 строк или меньше». Глава написана Йоавом Рубиным ().
В начале своей карьеры программистам часто требуется использовать какое-нибудь постоянное хранилище данных. И нет ничего столь непрозрачного и загадочного, как системы полнофункциональных баз данных, не зависящих от основной парадигмы организации данных.
Как и обычно, если вы обнаружите ошибки, о которых, как вы считаете, стоит сообщить, пожалуйста, сделайте запись на .
Приятного чтения!
В этой главе, автор показывает, как использование немутируемости в качестве основного принципа позволяет нам строить удивительно емкую систему баз данных, размер которой меньше 500 строк языка Clojure. В ней есть система транзакций, миниатюрный декларативный язык запросов и множество других функций.
Это предварительная публикация главы из сборника , четвертой книги из серии книг Архитектура приложений с открытым исходным кодом. Пожалуйста, сообщайте в нашем о любых проблемах, которые вы обнаружите при чтении этой главы. Следите в или в за объявлениями о предварительных публикациях новых глав и окончательной публикацией.
Йоав Рубин является старшим инженером-программистом в Microsoft, ранее был научным сотрудником и мастером изобретатель в IBM Research. Сейчас его работа связана с вопросами безопасности данных в облачном хранилище, а в прошлом он занимался разработкой облачного хранилища и среды разработки на основе веб-технологий. Йоав имеет степень магистра по медицине в области неврологии, а также степень бакалавра наук в области инженерии информационных систем. Его можно найти в Twitter-е по ссылке , а иногда и в блогах в .
Введение
Разработка программного обеспечения часто рассматривается как строгий процесс, в котором входными данными являются требования, а выходом - рабочий продукт. Тем не менее, разработчики программного обеспечения — это люди, с их точками зрения и предубеждениями, что сказывается на результате их работы.
В этой главе мы рассмотрим, как изменение в общепринятой точке зрения влияет на разработку и реализацию хорошо изученной типа программного обеспечения: базы данных.
Системы управления базами данных предназначены для хранения данных и выполнения к ним запросов. Это именно то, что делают все, кто работает с информацией; но сами системы были разработаны учеными-компьторщиками. В результате, на современные системы баз данных сильно влияет то, как ученые-компьтерщики определяют, что такое данные и что с ними можно делать.
Например, в большинстве современных баз данных обновления осуществляются посредством переписывания данных на место старых данных вместо того, чтобы добавить новые данные и сохранить старые данные. Этот механизм, который Рич Хикки () назвал "позиционно-ориентированным программированием", экономит пространство, но делает невозможным получить всю историю конкретной записи. Это дизайнерское решение отражает точку зрения ученых о том, что "история" является менее важной, чем стоимость хранения данных.
Если бы вы вместо этого спросили археолога, где можно найти старые данные, то ответ был бы следующим - "будем надеяться, что они просто похоронены ниже".
(Отказ от ответственности:. Мое понимание взглядов типичного археолога основано на посещении нескольких музеев, чтении нескольких статей Википедии, и просмотра всей серии участием Индиана Джонса).
Создаем базу с «археологическим» принципом хранения данных
Если бы мы попросили нашего друга-археолога спроектировать базу данных, то могли бы ожидать, что требования будут отражать то, что можно обнаружить на месте раскопок:
- Все данные найдены и каталогизированы в определенном месте.
- Если копать глубже, то можно обнаружить предметы из более ранних времен.
- Артефакты, найденные в том же слое, принадлежать одному и тому же периоду.
- На состоянии каждого артефакта отражается влияние разных периодов.
Например, на стене в одном слое могут быть римские символы, а в нижнем слое могут быть греческие символы. Обе эти находки формируют артефакт состояния стены.
На рис.1 визуально представлена аналогичная ситуация:
- Вся круг представляет собой место раскопок.
- Каждое кольцо представляет собой слой (они пронумерованы от 0 до 4).
- Каждый сектор помечен как артефакт (от "А" и до "E").
- Каждый артефакт имеет «символьный» атрибут (где пусто, то это означает, что ничего не изменилось).
- Толстые стрелки обозначают изменение символа при перемещении между слоями
- Пунктирные стрелки являются произвольными взаимосвязями между артефактами (например, от "E" до "А").
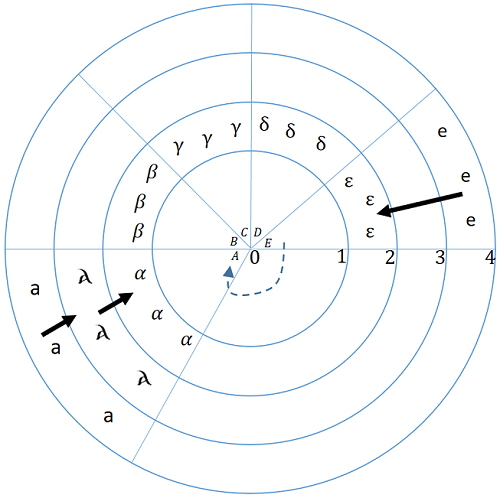
Рис.1: Место раскопок
Если перевести язык археолога в термины разработчика баз данных, то это будет означать следующее:
- Место раскопок является базой данных.
- Каждый артефакт является сущностью с соответствующим идентификатором ID.
- Каждая сущность имеет набор атрибутов, которые могут меняться с течением времени.
- Каждый атрибут в заданное время имеет определенное значение.
Этот подход может очень отличаться от тех видов баз данных, которыми вы пользуетесь для работы. Подобная архитектура иногда называется "функциональной базой данных", так как в ней используются идеи из области функционального программирования. В оставшейся части главы описывается, как реализовать такую базу данных.
Поскольку мы строим функциональную базу данных, мы будем использовать функциональный язык программирования под названием Clojure.
Язык Clojure имеет несколько качеств, которые делают его хорошим языком реализации функциональной базы данных, например, немутируемость, имеющаяся в нем сразу «из коробки», функции высшего порядка и средства метапрограммирования. Но, в конечном счете, причина, из-за которой был выбран язык Clojure, была в том, что в нем акцент делается на ясный и строгий дизайн, которым обладают немного языков программирования.
Продолжение статьи смотрите здесь