





Библиотека сайта rus-linux.net
База с "археологическим" принципом хранения данных
Оригинал: An Archaeology-Inspired Database
Автор: Yoav Rubin
Дата публикации: 20 October 2015
Перевод: Н.Ромоданов
Дата перевода: июль 2016 г.
Закладываем фундамент
Давайте начнем с объявления основных конструкций, которые будут составлять нашу базу данных.
(defrecord Database [layers top-id curr-time])
База данных состоит из:
- Слоев сущностей
layers, каждая сущность имеет свою собственным уникальную временную метку timestamp (кольца на рис.1). - Значения
top-id, которое является следующим доступным уникальным идентификатором ID - Времени
curr-time, указывающем когда база данных была последний раз обновлена.
defrecord Layer [storage VAET AVET VEAT EAVT])
Каждый слой Layer состоит из:
- Хранилища данных
storage, в котором хранятся сущности. - Индексов, которые используются для ускорения запросов к базе данных. (Эти индексы и смысл их имен будут объяснены позже).
В нашей конструкции, единственная концептуальная 'базы данных' может состоять из многих экземпляров Database, каждый из которых представляет собой снимок базы данных в некоторый текущий момент времени curr-time. В слое Layer может присутствовать та же самая сущность, что и в другом слое Layer в случае, если эта сущность не изменилась за то время, которое прошло между фиксацией этих двух слоев.
Сущности
От нашей базы данных не будет никакой пользы без сущностей, которые должны в ней храниться, поэтому мы определим их следующими. Как уже говорилось ранее, сущность имеет идентификатор и список атрибутов; мы создаем их с помощью функции make-entity.
(defrecord Entity [id attrs])
(defn make-entity
([] (make-entity :db/no-id-yet))
([id] (Entity. id {})))
Отметим, что если идентификатор ID не задан, то идентификатор ID сущности должен устанавливаться следующим образом :db/no-id-yet, что означает, что что-то другое ответственно за назначение ему идентификатора ID. Позже мы увидим, как это работает.
Атрибуты
Каждый атрибут состоит из имени, значения, и временной метки его последнего обновления, а также предыдущей временной метки. Каждый атрибут также имеет два поля, в которых описываются его тип type и кардинальность cardinality.
В случае, когда атрибут используется для представления связи с другой сущностью, ее тип type будет: :db/ref и его значение будет идентификатором соответствующей сущности. Такая система простых типов выступает в качестве средства расширения. Пользователи могут свободно определять свои собственные типы и использовать их для реализации дополнительной семантики для своих данных.
Свойства cardinality атрибута указывает, будет ли атрибут иметь одно значение или набор значений. Мы используем это поле для определения набора операций, которые допустимы для этого атрибута.
Создание атрибута выполняется при помощи функции make-attr.
(defrecord Attr [name value ts prev-ts])
(defn make-attr
([name value type ; these ones are required
& {:keys [cardinality] :or {cardinality :db/single}} ]
{:pre [(contains? #{:db/single :db/multiple} cardinality)]}
(with-meta (Attr. name value -1 -1) {:type type :cardinality cardinality})))
Есть несколько интересных паттернов, используемых в этой функции конструктора:
- Мы используем паттерн
Дизайн согласно контракта(Design by Contract) языка Clojure для проверки того, что параметр кардинальности имеет допустимое значение. - Мы используем механизм деструктуризации языка Clojure для определения значения, используемого по умолчанию, которым будет
:db/singleв случае, если это значение явно не задано. - Мы используем возможности метаданных языка Clojure для того, чтобы различать данные атрибута (имя, значение и временные метки) и его метаданные (тип и кардинальность). В языке Clojure обработка метаданных выполняется с помощью функции
with-meta(для установки значений) и функцииmeta(для чтения значений).
Атрибуты имеют смысл только если они являются частью сущности. Мы реализуем связь с помощью функции add-attr, которая добавляет заданный атрибут к атрибутам некоторой сущности (называется :attrs).
Обратите внимание, что вместо того, используя имя атрибута напрямую, мы сначала преобразуем его в ключевое слово с тем, чтобы придерживаться принципов использования механизма maps в языке Clojure.
(defn add-attr [ent attr]
(let [attr-id (keyword (:name attr))]
(assoc-in ent [:attrs attr-id] attr)))
Хранилище
До сих пор мы много говорили о том, что мы собираемся хранить и не думали о том, где мы это собираемся хранить. В этой главе мы используем простейший механизм хранения: хранения данных в памяти. Это, конечно, не самый надежный вариант, но он упрощает разработку и отладку и позволяет нам сосредоточиться на более интересных частях программы.
Мы будем иметь доступ к хранилищу с помощью простого протокола protocol, который позволяет определять дополнительных провайдеров сервиса хранения с тем, чтобы владелец базы данных мог выбрать одного из них.
(defprotocol Storage (get-entity [storage e-id] ) (write-entity [storage entity]) (drop-entity [storage entity]))
И вот наша реализация протокола хранения в памяти, в котором отображение map используется в качестве резервного хранилища:
(defrecord InMemory [] Storage (get-entity [storage e-id] (e-id storage)) (write-entity [storage entity] (assoc storage (:id entity) entity)) (drop-entity [storage entity] (dissoc storage (:id entity))))
Индексация данных
Теперь, когда мы определили основные элементы нашей базы данных, мы можем начать подумать о том, как мы собираемся делать запросы. В силу того, как мы структурировали наши данные, любой запрос обязательно выдаст, по крайней мере, один из идентификаторов сущности и имя и значение некоторых из атрибутов этой сущности. Такая тройка (entity-id, attribute-name, attribute-value) является достаточно важной в нашем процессе запроса, поэтому мы ему даем имя датом (datom).
Причина того, что датомы так важны, в том, что они представляют факты, а наша база данных накапливает факты.
Если вы прежде пользовались системой баз данных, вы, вероятно, уже знакомы с концепцией индекса, который является структурой данных, на поддержку которого требуется дополнительное место, но с его помощью уменьшается среднее время запроса. В нашей базе данных, индексы — это три структуры, в которых хранятся компоненты датом в строго определенном порядке. Каждый индекс получил свое название от того, что в каком порядке в нем в хранятся компоненты датом.
Например, давайте посмотрим на индекс, который показан на рис.2:
- На первом уровне хранятся идентификаторы сущностей
- На втором уровне хранятся соответствующие имена атрибутов
- На третьем уровне хранится связанное значение
Этот индекс называется EAVT, поскольку на верхнем уровне находятся идентификаторы сущностей (Entity ID), на втором уровне находятся имена атрибутов (Attribute names), а в качестве листьев хранятся значения (Values). Символ "T" указывает на то, что в каждом слое в базе данных есть свои собственные индексы и, следовательно, сам индекс актуален в течение определенного времени.
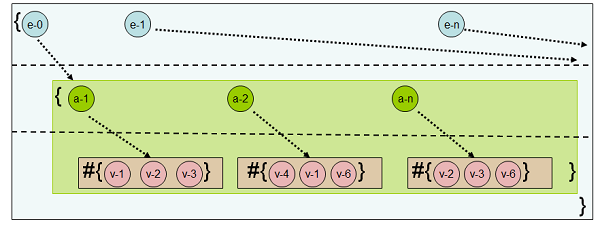
Рис.2: Индекс EAVT
На рис.3 показан индекс, который называется AVET т.к.:
- На первом уровне хранится имя атрибута (Attribute-name).
- На втором уровне находятся значения атрибутов (Values of the attributes).
- На третьем уровне находятся идентификаторы сущностей (Entity-ID) — тех сущностей, атрибуты которых хранятся на первом уровне.
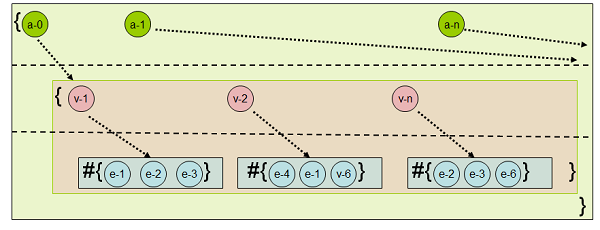
Рис.3: Индекс AVET
Наши индексы реализованы в виде отображений, действующих над отображениями, в которых ключи корневого отображения выступают в качестве первого уровня, каждый такой ключ указывает на отображение, ключи которого действуют как второй уровень индекса, а значения являются третьим уровнем индекса. Каждый элемент на третьем уровне представляет собой множеством, в котором хранятся листья индекса.
В каждом индексе хранятся компоненты датома в виде некоторой перестановки, полученной из канонического упорядоченной тройки 'EAV' (Entity_id — идентификатор сущерсти, Attribute-name — имя атребута, attribute-Value — значение атрибута). Но когда мы работаем с датом без использования индекса, мы предполагаем, что датом будет представлен в каноническом формате. Поэтому мы для каждого индекса предоставляем функции from-eav и to-eav, которые осуществляют преобразования из и в канонический формат.
В большинстве систем баз данных индексы являются дополнительным компонентом; например, в реляционных СУБД (RDBMS - Relational Database Management System), таких как PostgreSQL или MySQL, вам следует выбрать, к каким конкретным столбцам таблицы вы будете добавлять индексы. Мы для работы с индексами предоставляем функцию usage-pred, с помощью которой определяется, должен ли атрибут быть включен в конкретный индекс или нет.
(defn make-index [from-eav to-eav usage-pred]
(with-meta {} {:from-eav from-eav :to-eav to-eav :usage-pred usage-pred}))
(defn from-eav [index] (:from-eav (meta index)))
(defn to-eav [index] (:to-eav (meta index)))
(defn usage-pred [index] (:usage-pred (meta index)))
В нашей базе данных есть четыре индекса: EAVT (рис.2) Авет (рис.3), VEAT и VAET. Мы можем получить доступ к ним как к вектору значений, возвращаемых функцией indexes.
(defn indexes[] [:VAET :AVET :VEAT :EAVT])
Чтобы продемонстрировать, как все это работает вместе, в таблице 1 показан результат индексации следующих пяти сущностей:
- Юлий Цезарь (Julius Caesar – обозначен как JC) живет в Риме (Rome)
- Брут (Brutus – обозначен как B) живет в Риме (Rome)
- Клеопатра (Cleopatra – обозначена как Cleo) живет в Египте (Egypt)
- Река в Риме (Rome) — Тибр (Tiber)
- Река в Египте (Egypt) — Нил (Nile)
Таблица 1: Индексы
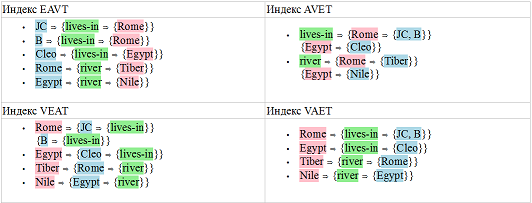
База данных
Теперь у нас есть все компоненты, которые нам нужны для построения нашей базы данных. Инициализация нашей базы данных означает следующее:
- создание первоначального пустого слоя без данных
- создание набора пустых индексов
- настройка, чтобы
top-idиcurr-timeбыли равны 0
(defn ref? [attr] (= :db/ref (:type (meta attr))))
(defn always[& more] true)
(defn make-db []
(atom
(Database. [(Layer.
(fdb.storage.InMemory.) ; storage
(make-index #(vector %3 %2 %1) #(vector %3 %2 %1) #(ref? %));VAET
(make-index #(vector %2 %3 %1) #(vector %3 %1 %2) always);AVET
(make-index #(vector %3 %1 %2) #(vector %2 %3 %1) always);VEAT
(make-index #(vector %1 %2 %3) #(vector %1 %2 %3) always);EAVT
)] 0 0)))
Но есть одна загвоздка: все коллекции в языке Clojure немутируемы. Поскольку операции записи имеют решающее значение в базе данных, то мы определим нашу структуру, которая будет называться Atom и будет ссылочным типом языка Clojure, что позволит делать атомарные записи.
Вы, возможно, удивитесь, почему мы используем функцию always для индексов AVET, VEAT и EAVT, а ref? является предикатом индекса VAET. Это связано с тем, что эти индексы используются в различных сценариях, что мы увидим позже, когда более глубже станем разбираться с запросами.
Базовые средства доступа
Прежде, чем мы сможем строить сложные запросы к нашей базе, мы должны предоставить API низкого уровня, различные части которого можно будет использовать для получения компонентов, ассоциируемых нами с идентификаторами в любой момент времени. Этим API могут также пользоваться потребители данных; но, что более вероятно, они будут использовать более полнофункциональными компонентами, построенными на этом API.
Этот API низкого уровня состоит из следующих четырех функций доступа:
(defn entity-at ([db ent-id] (entity-at db (:curr-time db) ent-id)) ([db ts ent-id] (stored-entity (get-in db [:layers ts :storage]) ent-id))) (defn attr-at ([db ent-id attr-name] (attr-at db ent-id attr-name (:curr-time db))) ([db ent-id attr-name ts] (get-in (entity-at db ts ent-id) [:attrs attr-name]))) (defn value-of-at ([db ent-id attr-name] (:value (attr-at db ent-id attr-name))) ([db ent-id attr-name ts] (:value (attr-at db ent-id attr-name ts)))) (defn indx-at ([db kind] (indx-at db kind (:curr-time db))) ([db kind ts] (kind ((:layers db) ts))))
Поскольку мы рассматриваем нашу базу данных точно также, как и любой другой объект, каждая из этих функций получает базу данных в виде аргумента. Каждый элемент извлекается по связанному с ним идентификатору, и, возможно, временной метке, если она интересует. Эта метка используется для выбора соответствующего слоя, в котором должен выполняться наш поиск.
Эволюция
Первое, что нам нужно, это API, позволяющий "читать из прошлого". Это возможно, т. к. в нашей базе данных операции обновления делаются путем добавления нового слоя (а не с помощью перезаписи значений). Поэтому мы можем использовать свойство prev-ts для того, чтобы просмотреть атрибут в этом слое, а затем продолжать искать вглубь истории с тем, чтобы наблюдать, как значение атрибута изменялось в течение времени.
Именно это делает функция evolution-of. Она возвращает последовательность пар, каждая из которых состоит из метки времени и обновленного значения атрибута.
Продолжение статьи смотрите здесь