





Библиотека сайта rus-linux.net
| [ < ] | [ > ] | [ << ] | [ Up ] | [ >> ] | [Top] | [Contents] | [Index] | [ ? ] |
12. Grammar and Reference
The tools and resources for writing and editing on Linux-based systems include spell checkers, dictionaries, and reference files. This chapter shows methods for using them.
12.1 Spelling Spell checking. 12.2 Dictionaries 12.3 Checking Grammar Grammar tools. 12.4 Word Lists and Reference Files Word lists and reference files.
| [ < ] | [ > ] | [ << ] | [ Up ] | [ >> ] | [Top] | [Contents] | [Index] | [ ? ] |
12.1 Spelling
There are several ways to spell check text and files on Linux; the following recipes show how to find the correct spellings of particular words and how to perform batch, interactive, and Emacs-based spell checks.
The system dictionary file, `/usr/dict/words',(18) is nothing more than a word
list (albeit a very large one), sorted in alphabetical order and
containing one word per line. Words that are correct regardless of case
are listed in lowercase letters, and words that rely on some form of
capitalization in order to be correct (such as proper nouns) appear in
that form. All of the Linux spelling tools use this text file to check
spelling; if a word does not appear in the dictionary file, it is
considered to be misspelled.
NOTE: None of the computerized spell-check tools will correct your writing if you are using the wrong word to begin with--for example, if you have `there' when you mean `their', the computer will not catch it (yet!).
12.1.1 Finding the Correct Spelling of a Word Spell checking a word. 12.1.2 Listing the Misspellings in a Text Spell checking a file. 12.1.3 Keeping a Spelling Word List Keeping a personal dictionary. 12.1.4 Interactive Spell Checking Interactive spell checking. 12.1.5 Spell Checking in Emacs Spell checking in Emacs.
| [ < ] | [ > ] | [ << ] | [ Up ] | [ >> ] | [Top] | [Contents] | [Index] | [ ? ] |
12.1.1 Finding the Correct Spelling of a Word
If you're unsure whether or not you're using the correct spelling of a
word, use spell to find out. spell reads from the standard
input and outputs any words not found in the system dictionary--so if a
word is misspelled, it will be echoed back on the screen after you type
it.
-
For example, to check whether the word `occurance' is misspelled, type:
$ spell RET occurance RET occurance C-d $
In the example, spell echoed the word `occurance', meaning
that this word was not in the system dictionary and therefore was quite
likely a misspelling. Then, C-d was typed to exit spell.
| [ < ] | [ > ] | [ << ] | [ Up ] | [ >> ] | [Top] | [Contents] | [Index] | [ ? ] |
12.1.2 Listing the Misspellings in a Text
To output a list of misspelled words in a file, give the name of the
file to check as an argument to spell. Any misspelled words in
the file are output, each on a line of its own and in the order that
they appear in the file.
-
To spell check the file
`fall-lecture.draft', type:$ spell fall-lecture.draft RET occurance willl occurance $
In this example, three words are output: `occurance', `willl'
and `occurance' again, meaning that these three words were found in
`fall-lecture.draft', in that order, and were not in the system
dictionary (and so were probably misspelled). Note that the misspelling
`occurance' appears twice in the file.
To correct the misspellings, you could then open the file in your preferred text editor and edit it. Later in this section I'll describe an interactive spell checker that allows you to correct misspellings as they are found. Still another option is to use a text editor with spell-checking facilities built in, such as Emacs.
-
To spell check the file
`fall-lecture.draft', and output any possibly misspelled words to a file`fall-lecture.spelling', type:$ spell fall-lecture.draft > fall-lecture.spelling RET
In this example, the standard output redirection character, `>', is used to redirect the output to a file (see section Redirecting Output to a File).
To output an alphabetical list of the misspelled words, pipe the
output to sort; then pipe the sorted output to the uniq
filter to remove duplicates from the list (uniq removes duplicate
adjacent lines from its input, outputting the "unique" lines).
-
To output a sorted list of the misspelled words that are in the file
`fall-lecture.draft', type:$ spell fall-lecture.draft | sort | uniq RET
| [ < ] | [ > ] | [ << ] | [ Up ] | [ >> ] | [Top] | [Contents] | [Index] | [ ? ] |
12.1.3 Keeping a Spelling Word List
The stock American English dictionary installed with Linux-based systems includes over 45,000 words. However large that number may seem, a lot of words are invariably left out--including slang, jargon, and some proper names.
You can view the system dictionary as you would any other text file, but
users never edit this file to add words to it.(19) Instead, you add new words to
your own personal dictionary, a file in the same format as the
system dictionary, but kept in your home directory as the file
`~/.ispell_default'.
Users can have their own personal dictionary; the spelling commands discussed in this chapter automatically use your personal dictionary, if you have one, in addition to the system dictionary.
You build your personal dictionary using the i
and u options of ispell, which insert words into your
personal dictionary. Use these options either with the stand-alone tool
or with the various ispell Emacs functions (see Interactive Spell Checking and Spell Checking in Emacs).
NOTE: You can also add (or remove) words by manually editing the file with a text editor, but take care so that the list is kept in alphabetical order!
Over time, personal dictionaries begin to look very personal, as a reflection of their owners; Gregory Cosmo Haun made a work of art by photographing the portraits of a dozen users superimposed with listings of their personal dictionaries (accessible online at http://www.reed.edu/~cosmo/art/DictPort.html).
| [ < ] | [ > ] | [ << ] | [ Up ] | [ >> ] | [Top] | [Contents] | [Index] | [ ? ] |
12.1.4 Interactive Spell Checking
Use ispell to spell check a file interactively, so that
every time a misspelling is found, you're given a chance to replace it
then and there.
-
To interactively spell check
`fall-lecture.notes', type:$ ispell fall-lecture.notes RET
When you type this, ispell begins checking the file. It stops at
the first misspelling it finds:

On the top line of the screen, ispell displays the misspelled
word, followed by the name of the file. Underneath this is the sentence
in which the misspelling appears, with the word in question
highlighted. Following this is a list of suggested words, each offset by
a number--in this example, ispell has only one suggestion:
`lectures'.
To replace a misspelling with a suggested word, type the number that corresponds to the suggested word (in this example, you would type 0 to replace the misspelling with `lectures'). You only need to type the number of your selection--a RET is not required.
You can also type a correction yourself; this is useful when
ispell either offers no suggestions, or when it does and the word
you want is not one of them. To do this, type r (for "replace")
and then type the replacement word, followed by RET.
Sometimes, ispell will question a word that you may not want to
count as a misspelling, such as proper names and the like--words that
don't appear in the system dictionary. There are a few things you can do
in such cases, as follows.
To accept a misspelled word as correct for the current ispell
session only, type a; from then on during the current session,
this word will be considered correct.
If, however, you want ispell (and spell, and all other
tools that access the system dictionary) to remember this word as being
correct for this and all future sessions, insert the word in your own
personal dictionary. Type u to insert a copy of the word
uncapitalized, in all lowercase letters--this way, even if the
word is capitalized at the beginning of a sentence, the lowercase
version of the word is saved. From then on, in the current ispell
session and in future sessions, this word, regardless of case, will be
considered correct.
When case is important to the spelling--for example, in a word that is a proper name such as `Seattle', or a word with mixed case, such as `LaTeX'---type i to insert a copy of the word in your personal dictionary with its case just as it appears; this way, words spelled with the same letters but with different case will be considered misspellings.
When ispell finishes spell checking a file, it saves its changes
to the file and then exits. It also makes a copy of the original file,
without the changes applied; this file has the same name as the original
but with `.bak' added to the end--so in our example, the backup
file is called `fall-lecture.notes.bak'. This is useful if you
regret the changes you've made and want to restore the file to how it
was before you mucked it up--just remove the spell-checked file and
then rename the `.bak' file to its original name.
The following table is a reference to the ispell key commands.
| KEY | COMMAND |
| SPC | Accept misspelled word as correct, but only for this particular instance. |
| number | Replace the misspelled word with the suggestion that corresponds to the given number. |
? |
Display a help screen. |
a |
Accept misspelled word as correct for the remainder of this
ispell session.
|
i |
Accept misspelled word as correct and add it to your private dictionary with the capitalization as it appears. |
l |
Look up words in the system dictionary according to a pattern you then give. |
q |
Quit checking and restore the file to how it was before this session. |
r |
Replace misspelled word with a word you type. |
u |
Accept misspelled word as correct and add it to your private dictionary in all lowercase letters. |
x |
Save the changes thus made, and then stop checking this file. |
| [ < ] | [ > ] | [ << ] | [ Up ] | [ >> ] | [Top] | [Contents] | [Index] | [ ? ] |
12.1.5 Spell Checking in Emacs
Emacs has several useful commands for spell checking. The
ispell-word, ispell-region, and ispell-buffer
functions, as you might guess from their names, use the ispell
command inside Emacs to check portions of the current buffer.
The first command, ispell-word, checks the spelling of the word
at point; if there is no word at point, it checks the first word to the
left of point. This command has a keyboard shortcut, M-$. The
second command, ispell-region, checks the spelling of all words
in the currently selected region of text. The third command,
ispell-buffer, checks the spelling of the entire buffer.
-
To check the spelling of the word at point, type:
M-x ispell-word RET
-
To check the spelling of all words in the currently selected region of
text, type:
M-x ispell-region RET
-
To check the spelling of all words in the current buffer, type:
M-x ispell-buffer RET
Flyspell mode is another useful Emacs spelling command that, when
set in a buffer, highlights misspelled words. This function is useful
when you are writing a first draft in a buffer, because it lets you
catch misspellings as you type them.
-
To turn on
Flyspellmode in a buffer, type:M-x flyspell-mode RET
NOTE: This command is a toggle; run it again to turn it off.
To correct a word in Flyspell mode, click and release the middle
mouse button on the word to pull up a menu of suggestions; you then use
the mouse to select the replacement word or add it to your personal
dictionary.
If there are words you frequently misspell, you can define abbrevs for them (see section Making Abbreviations in Emacs). Then, when you type the misspelled word, Emacs will automatically replace it with the correct spelling.
Finally, if you prefer the sparse, non-interactive interface of
spell, you can use the Emacs interfaces to that command instead:
Spell word, Spell region, and Spell buffer. When
any of these commands find a misspelling, they prompt for a replacement
in the minibuffer but do not offer suggestions or provide any of
ispell's other features.
| [ < ] | [ > ] | [ << ] | [ Up ] | [ >> ] | [Top] | [Contents] | [Index] | [ ? ] |
12.2 Dictionaries
@sf{Debian}: `wordnet-dev'
@sf{WWW}: http://www.cogsci.princeton.edu/~wn/
The term dictionary on Linux systems generally refers to one of two things: the traditional Unix-style dictionary, which is an alphabetically sorted word list containing no actual definitions, and the newer database-style dictionary that contains the headwords as well as their definitions. The latter is the kind of thing most people mean when they talk about dictionaries. (When most Unix folk talk about dictionaries, however, they almost always mean the former.)
WordNet is a lexical reference system in the form of a database
containing thousands of words arranged in synonym sets. You can search
the database and output the results in text with the wn tool or
the wnb X client (the "WordNet browser").
Use of the X client is fairly straightforward--type a word in the dialog box near the top of the screen, followed by RET, to get its definition(s), which are displayed in the large output window underneath the dialog box.
For example, this is what appears when you do a search for the definition of the word `browse':
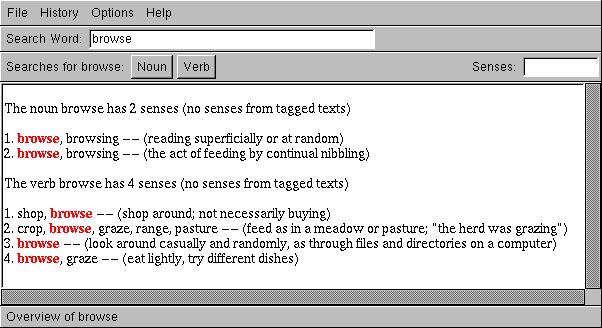
Between the dialog box and the output window, there are menus for searching for synonyms and other word senses. A separate menu is given for each part of speech a word may have; in the preceding example, the word `browse' can be either a noun or a verb, so two menus are shown.
To get a list of all word sense information available for a given word,
run wn with the name of the word as an argument. This outputs a
list of all word sense information available for the word, with each
possible sense preceded with the name of the option to use to output it.
-
To output a list of word senses available for the word `browse',
type:
$ wn browse RET
The following sections show how to use wn on the command line.
NOTE: For more information on WordNet, consult the
wnintro man page (see section Reading a Page from the System Manual).
12.2.1 Listing Words that Match a Pattern Listing words that match a pattern. 12.2.2 Listing the Definitions of a Word Looking up a word's definition. 12.2.3 Listing the Synonyms of a Word Finding Synonyms. 12.2.4 Listing the Antonyms of a Word Finding Antonyms. 12.2.5 Listing the Hypernyms of a Word Finding Hypernyms. 12.2.6 Online Dictionaries Free dictionaries on the WWW.
| [ < ] | [ > ] | [ << ] | [ Up ] | [ >> ] | [Top] | [Contents] | [Index] | [ ? ] |
12.2.1 Listing Words that Match a Pattern
There are several ways to search for and output words from the system dictionary.
Use look to output a list of words in the system dictionary that
begin with a given string--this is useful for finding words that begin
with a particular phrase or prefix. Give the string as an argument; it
is not case sensitive.
-
To output a list of words from the dictionary that begin with the string
`homew', type:
$ look homew RET
This command outputs words like `homeward' and `homework'.
Since the system dictionary is an ordinary text file, you can also use
grep to search it for words that match a given pattern or regular
expression (see section Regular Expressions--Matching Text Patterns).
-
To list all words in the dictionary that contain the string `dont',
regardless of case, type:
$ grep -i dont /usr/dict/words RET
-
To list all words in the dictionary that end with `ing', type:
$ grep ing^ /usr/dict/words RET
-
To list all of the words that are composed only of vowels, type:
$ grep -i '^[aeiou]*$' /usr/dict/words RET
To find some words that rhyme with a given word, use grep to
search `/usr/dict/words' for words ending in the same last few
characters as the word they should rhyme with (see section Matching Lines Ending with Certain Text).
-
To output a list of words that rhyme with `friend', search
`/usr/dict/words'for lines ending with `end':$ grep 'end$' /usr/dict/words RET
Finally, to do a search on the WordNet dictionary, use wn with
one of the `-grep' options. When you give some text to search for
as an argument, this command does the equivalent search as look,
except only the particular kind of word sense you specify is searched:
`-grepn' searches nouns, `-grepv' searches verbs,
`-grepa' searches adjectives, and `-grepr' searches
adverbs. You can combine options to search multiple word senses.
-
To search the WordNet dictionary for nouns that begin with `homew',
type:
$ wn homew -grepn RET
-
To search the WordNet dictionary for both nouns and adjectives that
begin with `homew', type:
$ wn homew -grepn -grepa RET
| [ < ] | [ > ] | [ << ] | [ Up ] | [ >> ] | [Top] | [Contents] | [Index] | [ ? ] |
12.2.2 Listing the Definitions of a Word
To list the definitions of a word, give the word as an argument to
wn, followed by the `-over' option.
-
To list the definitions of the word `slope', type:
$ wn slope -over RET
| [ < ] | [ > ] | [ << ] | [ Up ] | [ >> ] | [Top] | [Contents] | [Index] | [ ? ] |
12.2.3 Listing the Synonyms of a Word
A synonym of a word is a different word with a similar meaning
that can be used in place of the first word in some context. To output
synonyms for a word with wn, give the word as an argument,
followed by one of the following options: `-synsn' for nouns,
`-synsv' for verbs, `-synsa' for adjectives, and `-sysnr'
for adverbs.
-
To output all of the synonyms for the noun `break', type:
$ wn break -synsn RET
-
To output all of the synonyms for the verb `break', type:
$ wn break -synsv RET
| [ < ] | [ > ] | [ << ] | [ Up ] | [ >> ] | [Top] | [Contents] | [Index] | [ ? ] |
12.2.4 Listing the Antonyms of a Word
An antonym of a word is a different word that has the opposite
meaning of the first in some context. To output antonyms for a word with
wn, give the word as an argument, followed by one the following
options: `-antsv' for verbs, `-antsa' for adjectives, and
`-antsr' for adverbs.
-
To output all of the antonyms for the adjective `sad', type:
$ wn sad -antsa RET
| [ < ] | [ > ] | [ << ] | [ Up ] | [ >> ] | [Top] | [Contents] | [Index] | [ ? ] |
12.2.5 Listing the Hypernyms of a Word
A hypernym of a word is a related term whose meaning is more general than the given word. (For example, the words `mammal' and `animal' are hypernyms of the word `cat'.)
To output hypernyms for a word with wn, use one of the following
options: `-hypen' for nouns and `-hypev' for verbs.
-
To output all of the hypernyms for the noun `cat', type:
$ wn cat -hypen RET
| [ < ] | [ > ] | [ << ] | [ Up ] | [ >> ] | [Top] | [Contents] | [Index] | [ ? ] |
12.2.6 Online Dictionaries
@sf{Debian} `dict'
@sf{WWW}: http://www.dict.org/
The DICT Development Group has a number of free dictionaries on their Web site at http://www.dict.org/. On that page, you can look up the definitions of words (including thesaurus and other searches) from a dictionary that contains over 300,000 headwords, or make a copy of their dictionary for use on your own system. A
dict client exists for
accessing DICT servers and outputting definitions locally; this tool is
available in the `dict' package.
DICT also has a number of specialized dictionaries that are plain text files (including the author's Free Journalism Dictionary, containing jargon and terms used in the journalism and publishing professions). Their FILE project, The Free Internet Lexicon and Encyclopedia, is an effort to build a free, open source collection of modern-word, idiom, and jargon dictionaries. FILE is a volunteer effort and depends on the support of scholars and lexicographers; the DICT pages contain information on how to help contribute to this worthy project.
| [ < ] | [ > ] | [ << ] | [ Up ] | [ >> ] | [Top] | [Contents] | [Index] | [ ? ] |
12.3 Checking Grammar
@sf{WWW}: http://www.gnu.org/software/diction/diction.html
Two venerable Unix tools for checking writing have recently been made available for Linux-based systems:
style and diction.
Old-timers probably remember these names--the originals came with AT&T UNIX as part of the much-loved "Writer's Workbench" (WWB) suite of tools back in the late 1970s and early 1980s.(20)
AT&T "unbundled" the Writer's Workbench from their UNIX version 7 product, and as the many flavors of Unix blossomed over the years, these tools were lost by the wayside--eventually becoming the stuff of Unix lore.
In 1997, Michael Haardt wrote new Linux versions of these tools from scratch. They support both the English and German languages, and they're now part of the GNU Project.
Two additional commands that were part of the Writer's Workbench have
long been standard on Linux: look and spell, described
previously in this chapter.
12.3.1 Checking Text for Misused Phrases Checking for misused phrases. 12.3.2 Checking Text for Doubled Words Checking for doubled words. 12.3.3 Checking Text for Readability Checking writing style. 12.3.4 Checking Text for Difficult Sentences Checking for difficult sentences. 12.3.5 Checking Text for Long Sentences Checking for long sentences.
| [ < ] | [ > ] | [ << ] | [ Up ] | [ >> ] | [Top] | [Contents] | [Index] | [ ? ] |
12.3.1 Checking Text for Misused Phrases
Use diction to check for wordy, trite, clichéd, or misused
phrases in a text. It checks for all the kind of expressions William
Strunk warned us about in his Elements of Style.
According to The UNIX Environment, by Andrew Walker, the
diction tool that came with the old Writer's Workbench just
found the phrases, and a separate command called suggest
would output suggestions. In the GNU version that works for Linux
systems, both functions have been combined in the single diction
command.
In GNU diction, the words or phrases are enclosed in brackets
`[like this]'. If diction has any suggested replacements,
it gives them preceded by a right arrow, `-> like this'.
When checking more than just a screenful of text, you'll want to pipe
the output to less so that you can peruse it on the screen
(see section Perusing Text), or pipe the output to a file
for later examination.
-
To check file
`dissertation'for clichés or other misused phrases, type:$ diction dissertation | less RET
-
To check file
`dissertation'for clichés or other misused phrases, and write the output to a file called`dissertation.diction', type:$ diction dissertation > dissertation.diction RET
If you don't specify a file name, diction reads text from the
standard input until you type C-d on a line by itself. This is
especially useful when you want to check a single sentence:
$ diction RET Let us ask the question we wish to state. RET (stdin):1: Let us [ask the question -> ask] [we wish to state -> (cliche, avoid)]. C-d $ |
To check the text of a Web page, use the text-only Web browser
lynx with the `-dump' and `-nolist' options to output
the plain text of a given URL, and pipe this output to diction.
(If you expect there to be a lot of output, add another pipe at the end
to less so you can peruse it.)
-
To peruse a copy of the text of http://example.org/1.html with
markings for possible wordy and misused phrases, type:
$ lynx -dump -nolist http://example.org/1.html | diction | less RET |
| [ < ] | [ > ] | [ << ] | [ Up ] | [ >> ] | [Top] | [Contents] | [Index] | [ ? ] |
12.3.2 Checking Text for Doubled Words
One of the things that diction looks for is doubled words--words
repeated twice in a row. If it finds such a sequence, it encloses the
second member of the doubled pair in brackets, followed by a right arrow
and the text `Double word', like `this [<i>this -> Double
word.]'.
To check a text file for doubled words only, and not for any of
the other things diction checks, use grep to find only
those lines in diction's output that contain the text
`Double word', if any.
-
To output all lines containing double words in the file
`dissertation', type:$ diction dissertation | grep 'Double word' RET
| [ < ] | [ > ] | [ << ] | [ Up ] | [ >> ] | [Top] | [Contents] | [Index] | [ ? ] |
12.3.3 Checking Text for Readability
The style command analyzes the writing style of a given text. It
performs a number of readability tests on the text and outputs their
results, and it gives some statistical information about the sentences
of the text. Give as an argument the name of the text file to check.
-
To check the readability of the file
`dissertation', type:$ style dissertation RET
Like diction, style reads text from the standard input if
no text is given--this is useful for the end of a pipeline, or for
checking the writing style of a particular sentence or other text you
type.
The sentence characteristics of the text that style outputs are
as follows:
-
Number of characters
-
Number of words, their average length, and their average number of
syllables
-
Number of sentences and average length in words
-
Number of short and long sentences
-
Number of paragraphs and average length in sentences
- Number of questions and imperatives
The various readability formulas that style uses and outputs are
as follows:
-
Kincaid formula, originally developed for Navy training manuals; a
good readability for technical documentation
-
Automated Readability Index (ARI)
-
Coleman-Liau formula
-
Flesch Reading Ease Score, which gives an approximation of readability
from 0 (difficult) to 100 (easy)
-
Fog Index, which gives a school-grade reading level
-
WSTF Index, a readability indicator for German documents
- Wheeler-Smith Index, Lix formula, and SMOG-Grading tests, all readability indicators that give a school-grade reading level
| [ < ] | [ > ] | [ << ] | [ Up ] | [ >> ] | [Top] | [Contents] | [Index] | [ ? ] |
12.3.4 Checking Text for Difficult Sentences
To output just the "difficult" sentences of a text, use style
with the `-r' option followed by a number; style will output
only those sentences whose Automated Readability Index (ARI) is greater
than the number you give.
-
To output all sentences in the file
`dissertation'whose ARI is greater than a value of 20, type:$ style -r 20 dissertation RET
| [ < ] | [ > ] | [ << ] | [ Up ] | [ >> ] | [Top] | [Contents] | [Index] | [ ? ] |
12.3.5 Checking Text for Long Sentences
Use style to output sentences longer than a certain length by
giving the minimum number of words as an argument to the `-l'
option.
-
To output all sentences longer than 14 words in the
file
`dissertation', type:$ style -l 14 dissertation RET
| [ < ] | [ > ] | [ << ] | [ Up ] | [ >> ] | [Top] | [Contents] | [Index] | [ ? ] |
12.4 Word Lists and Reference Files
@sf{Debian}: `miscfiles'
@sf{WWW}: ftp://ftp.gnu.org/pub/gnu/miscfiles/miscfiles-1.1.tar.gz
The GNU Miscfiles are a collection of text files containing various facts and reference material, such as common abbreviations, telephone area codes, and English connective phrases.
The files are stored in the `/usr/share/misc' directory, and they
are all compressed; use zless to peruse them (see section Perusing Text).
The following table lists the files in `/usr/share/misc' and
describes their contents.
| FILE | DESCRIPTION |
GNU-manifesto.gz |
The GNU Manifesto. |
abbrevs.talk.gz abbrevs.gen.gz |
Collections of common abbreviations used in electronic communication. (This is the place to look to find the secrets of `TTYL' and `LOL'.) |
airport.gz |
List of three-letter city codes for some of the major airports. The city code is useful for querying the National Weather Service computers to get the latest weather report for your region. |
ascii.gz |
A chart of the ASCII character set. |
birthtoken.gz |
The traditional stone and flower tokens for each month. |
cities.dat.gz |
The population, political coordinates (nation, region), and geographic coordinates (latitude, longitude) of many major cities. |
inter.phone.gz |
International country and city telephone codes. |
languages.gz |
Two-letter codes for languages, from ISO 639. |
latin1.gz |
A chart of the extended ASCII character set, also known as the ISO 8859 ("Latin-1") character set. |
mailinglists.gz |
Description of all the public Project GNU-related mailing lists. |
na.phone.gz |
North American (+1) telephone area codes. |
operator.gz |
Precedence table for operators in the C language. |
postal.codes.gz |
Postal codes for U.S. and Mexican states and Canadian provinces. |
us-constitution.gz |
The Constitution of the United States of America (no
Bill of Rights, though). (On Debian systems, this file is placed
in `/usr/share/state'.)
|
us-declaration.gz |
The Declaration of Independence of the Thirteen
Colonies. (On Debian systems, this file is placed in
`/usr/share/state'.)
|
rfc-index.txt |
Indexes of Internet standardization Request For Comments (RFC)
documents. (On Debian systems, this file is placed in
`/usr/share/rfc').
|
zipcodes.gz |
U.S. five-digit Zip codes. |
`miscfiles' is not the only reference package available for Debian
systems, though; other related packages include the following:
| PACKAGE | DESCRIPTION |
doc-iana |
Internet protocol parameter registry documents, as published by the Internet Assigned Numbers Authority. |
doc-rfc |
A collection of important RFCs, stored in `/usr/share/rfc'.
|
jargon |
The "Jargon file," which is the definitive dictionary of hacker slang. |
vera |
List of computer acronyms. |
NOTE: The official GNU miscfiles distribution also
includes the Jargon file and the `/usr/dict/words' dictionary file,
which are available in separate packages for Debian, and are removed
from the Debian `miscfiles' distribution. `/usr/dict/words' is
part of the standard spelling packages, and the Jargon file comes in the
optional `jargon' package, and installs in
`/usr/share/jargon'.
| [ << ] | [ >> ] | [Top] | [Contents] | [Index] | [ ? ] |