





Библиотека сайта rus-linux.net
The book is available and called simply "Understanding The Linux Virtual Memory Manager". There is a lot of additional material in the book that is not available here, including details on later 2.4 kernels, introductions to 2.6, a whole new chapter on the shared memory filesystem, coverage of TLB management, a lot more code commentary, countless other additions and clarifications and a CD with lots of cool stuff on it. This material (although now dated and lacking in comparison to the book) will remain available although I obviously encourge you to buy the book from your favourite book store :-) . As the book is under the Bruce Perens Open Book Series, it will be available 90 days after appearing on the book shelves which means it is not available right now. When it is available, it will be downloadable from http://www.phptr.com/perens so check there for more information.
To be fully clear, this webpage is not the actual book.
Next: 11.3 Manipulating the Page Up: 11. Page Frame Reclamation Previous: 11.1 Pageout Daemon (kswapd) Contents Index
Subsections
11.2 Page Cache
The page cache is a list of pages that are backed by regular files, block devices or swap. There are basically four types of pages that exist in the cache:
- Pages that were faulted in as a result of reading a memory mapped file;
- Blocks read from a block device or filesystem are packed into special
pages called buffer pages. The number of blocks that may fit depends
on the size of the block and the page size of the architecture;
- Anonymous pages first enter the page cache with no backing storage
but are allocated slots in the backing storage when the kernel needs to
swap them out, discussed furhter in Chapter 12;
- Pages belonging to shared memory regions which are treated in a similar
fashion to anonymous pages. The only difference is that shared pages
are added to the swap cache and space reserved in backing storage
immediately after the first write to the page.
Pages exist in this cache for two reasons. The first is to eliminate
unnecessary disk reads. Pages read from disk are stored in a page
hash table hashed on the struct address_space and the
offset. This table is always searched before the disk is accessed. The
second reason is that the page cache forms the queue as a basis for the page
replacement algorithm to select which page to discard or pageout.
The cache collectively consists of two lists defined in
mm/page_alloc.c called active_list and
inactive_list which broadly speaking store the ``hot''
and ``cold'' pages respectively. The lists are protected by the
pagemap_lru_lock. An API is provided that is responsible for
manipulating the page cache which is listed in Table 11.1.

11.2.1 Page Cache Hash Table
As stated, there is a requirement that pages in the page cache
be quickly located. To facilitate this, pages are inserted
into a table page_hash_table and the fields
page![]()
next_hash and page![]()
pprev_hash
are used to handle collisions.
The table is declared as follows in mm/filemap.c
45 atomic_t page_cache_size = ATOMIC_INIT(0); 46 unsigned int page_hash_bits; 47 struct page **page_hash_table;
The table is allocated during system initialisation by
page_cache_init() which takes the number of physical pages in the
system as a parameter. The desired size of the table (htable_size)
is enough to hold pointers to every struct page in the system
and is calculated by
To allocate a table, the system begins with an order allocation large
enough to contain the entire table. It calculates this value by starting at 0
and incrementing it until
![]() . This
may be roughly expressed as the integer component of the following simple
equation.
. This
may be roughly expressed as the integer component of the following simple
equation.
An attempt is made to allocate this order of pages with
__get_free_pages(). If the allocation fails, lower orders will
be tried and if no allocation is satisfied, the system panics.
The value of page_hash_bits is based on the size of the
table for use with the hashing function _page_hashfn().
The value is calculated by successive divides by two but in real terms,
this is equivalent to:
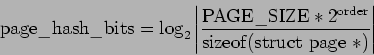
This makes the table a power-of-two hash table which negates the need to use a modulus which is a common choice for hashing functions.
11.2.2 Inode Queue
The inode queue is part of the struct address_space
introduced in Section 5.4.1. The
struct contains three lists: clean_pages is a list of clean
pages associated with the inode; dirty_pages which have been
written to since the list sync to disk; and locked_pages
which are those currently locked. These three lists in combination
are considered to be the inode queue for a given mapping and the
page![]()
list field is used to link pages on it. Pages
are added to the inode queue with add_page_to_inode_queue()
which places pages on the clean_pages lists and removed with
remove_page_from_inode_queue().
Next: 11.3 Manipulating the Page Up: 11. Page Frame Reclamation Previous: 11.1 Pageout Daemon (kswapd) Contents Index Mel 2004-02-15