Библиотека сайта rus-linux.net
Процессы и демоны в Linux
В.А.Костромин
(написано 16 марта 2003 г., опубликовано 13 февраля 2004 г.)
Понятие процесса, наравне с понятием файла, является, безусловно, одним из самых важных понятий любой операционной системы.
Понятие процесса
В самом первом приближении можно считать, что процесс — это программа, выполняющаяся в оперативной памяти компьютера. Но такая формулировка как бы подразумевает, что речь идет только о наборе машинных инструкций, последовательно выполняемых процессором. Фактически же в многозадачных системах понятие процесса является значительно более сложным.
В любой многозадачной системе одновременно может быть запущено много программ, то есть много процессов. Впрочем, слово "одновременно" здесь применено не совсем корректно, поскольку на самом деле в каждый момент времени выполняется только один процесс. Ядро (точнее, особый процесс ядра – планировщик) выделяет каждому процессу небольшой квант времени и по истечении этого кванта передает управление следующему процессу. Кванты времени, выделяемые каждому процессу, так малы, что у пользователя создается иллюзия одновременного выполнения многих процессов. Но, чтобы организовать переключение между процессами по истечении кванта времени, приходится делать как бы «мгновенный снимок» состояния программы и сохранять этот снимок где-то в памяти. Этот «снимок» содержит информацию о состоянии регистров центрального процессора на момент прерывания программы, указание на то, с какой команды возобновить исполнение программы (состояние счетчика команд), содержимое стека и тому подобные данные. Когда процесс снова получает в свое распоряжение ЦП, состояние регистров ЦП и стека восстанавливается из сделанного «снимка» и выполнение программы возобновляется в точности с того места, где она была остановлена. Примерно такие же действия выполняются в тех случаях, когда какому-то процессу необходимо вызвать некоторую системную функцию (вызов ядра).
Кроме организации переключения процессов, ядро в многозадачной системе берет на себя заботу о том, чтобы процессы не мешали друг другу, в частности, чтобы два процесса не пытались одновременно изменять какие-то данные в памяти. Для этого каждому процессу выделяется свое виртуальное адресное пространство. Его размер может даже превышать размер реальной оперативной памяти, что обеспечивается за счет применения страничной организации памяти и механизма свопинга. И физическая и виртуальная память организована в виде страниц – областей памяти фиксированного размера (обычно 4 Кбайта). Если страница долго не используется, ее содержимое переносится в область свопинга на жестком диске, а страница в оперативной памяти предоставляется в распоряжение другого процесса. Подсистема управления памятью поддерживает таблицу соответствия между страницами виртуальной памяти процессов и страницами физической памяти (включая страницы, перенесенные в область свопинга). В современных компьютерных системах эти механизмы реализуются на аппаратном уровне с помощью устройств управления памятью – Memory Management Unit (MMU). Если процесс обращается к странице виртуальной памяти, которая размещается в оперативной памяти, операция чтения или записи осуществляется немедленно. Если же страница в оперативной памяти отсутствует, генерируется аппаратное прерывание, в ответ на которое подсистема управления памятью определяет положение сохраненного содержимого страницы в области свопинга, считывает страницу в оперативную память, корректирует таблицу отображения виртуальных адресов в физические, и сообщает процессу о необходимости повторить операцию. Все эти действия невидимы для приложения, которое работает с виртуальной памятью. При этом один процесс не может прочитать что-либо из памяти (или записать в нее) другого процесса без «разрешения» на то со стороны подсистемы управления памятью. При такой организации работы крах одного процесса никак не повлияет на другие выполняющиеся процессы и на всю систему в целом.
Для хранения всех данных, которые необходимо запоминать в целях организации работы процессов, в памяти, выделенной для ядра, создается для каждого процесса особая структура данных типа task_struct (структура задачи, см. [1]). В ней можно выделить следующие функциональные группы данных:
- идентификационная информация о процессе;
- статус процесса;
- информация для планировщика;
- информация для организации межпроцессорного взаимодействия;
- ссылки и связи процесса;
- информация о времени исполнения и таймеры;
- информация об используемых процессом ресурсах файловой системы;
- информация о выделенном процессу адресном пространстве;
- контекст процесса – информация о состоянии регистров процессора, стеке и т.д.
Подробнее структура task_struct будет рассмотрена ниже, а пока отметим, что максимальное количество процессов, одновременно запущенных в системе, для ядер версии 2.4 определяется как раз объемом структур task_struct и ограничивается только объемом физической памяти. Точнее – структуры процессов не могут занимать больше половины имеющихся страниц памяти [1].
Как рождаются процессы
Новые процессы создаются в Linux методом «клонирования» какого-то уже существующего процесса, путем вызова системных функций clone(2) и fork(2). Процедура порождения нового процесса выполняется в режиме ядра и происходит следующим образом.
- Создается новая структура task_struct в таблице процессов ядра и содержание такой же структуры старого (или текущего) процесса копируется в новую структуру.
- Назначается идентификатор (PID) нового процесса. PID – это уникальное положительное число, которое присваивается каждому процессу при его рождении. Именно по этим идентификаторам система различает процессы.
- Увеличиваются счетчики открытия файлов (порожденный процесс наследует все открытые файлы родительского процесса).
- После того, как процесс создан, запускается выполняемая им программа с помощью одного из вариантов системного вызова exec. Параметрами функции exec является имя выполняемого файла и, если нужно, параметры, которые будут переданы этой программе. Программа из указанного файла загружается в адресное пространство процесса, порожденного с помощью fork(), счетчик команд устанавливается в начальное значение и вновь созданный процесс переходит в режим ожидания того момента, когда планировщик выделит ему время центрального процессора.
- В том процессе, откуда вызывались функции fork() и exec, управление передается в точку возврата из системного вызова и выполнение этого процесса продолжается. Родительский процесс может дожидаться окончания выполнения всех своих процессов-потомков с помощью системного вызова wait.
Приведенное описание позволяет сделать два важных вывода:
- во-первых, вы видите, что еще до того, как какая-то программа начинает исполняться, создается новый процесс, который после его создания и «выполняет программу» [2];
- во-вторых, каждый процесс порожден каким-то другим процессом, то есть для каждого процесса однозначно определен его "родитель" (или "предок"), для которого данный процесс является "дочерним" (или "потомком").
Когда система стартует, вначале запускается ядро, которое тоже представляет собой процесс. Для него, как и для всех процессов, создается структура task_struct, которая имеет идентификатор 0. В конце процесса инициализации ядра порождается процесс init, который имеет идентификатор 1. Он первоначально запускается как поток ядра, выполняет некоторые системные операции (такие как монтирование корневой файловой системы и открытие системной консоли), после чего выполняет программу инициализации системы, которую он ищет в одном из файлов /sbin/init, /etc/init или /bin/init на диске. Программа init использует конфигурационный файл /etc/inittab для определения того, какие процессы еще должны быть запущены. Эти новые процессы в свою очередь могут запускать другие процессы и так далее. Например, процесс getty может создавать процесс login, когда пользователь делает попытку войти в систему. Таким образом, все процессы в системе происходят от одного первого процесса – потока ядра init.
При чтении описания процедуры создания нового процесса может возникнуть вопрос: а зачем нужно копировать в новый процесс все данные процесса-родителя (например, код программы) и не слишком ли много времени займет копирование. Ответ на этот вопрос заключается в том, что при создании копии процесса его индивидуальные данные физически никуда не копируются. Вместо этого используется метод copy-on-write (копирование при записи): страницы данных обоих процессов особым образом помечаются, и только тогда, когда новый процесс пытается изменить содержимое какой-либо своей страницы, она дублируется.
Демоны и потоки
Среди всех процессов можно выделить несколько особых типов процессов.
Системные процессы являются частью ядра и всегда находятся в оперативной памяти. Такие процессы не имеют соответствующих им программ в виде исполняемых файлов и запускаются особым образом при инициализации ядра системы. Примерами системных процессов являются планировщик процессов, диспетчер свопинга, диспетчер буферного кэша, диспетчер памяти ядра. Такие процессы являются фактически потоками ядра.
Демоны отличаются от обычных процессов только тем, что они работают в неинтерактивном режиме. Если с обычным процессом всегда ассоциирован какой-то терминал или псевдотерминал, через который осуществляется взаимодействие процесса с пользователем, то демон такого терминала не имеет. Демоны обычно используются для выполнения сервисных функций, обслуживания запросов от других процессов, причем не обязательно выполняющихся на данном компьютере. Пользователь не может непосредственно управлять демонами, он может влиять на их работу, только посылая им какие-то задания, например, отправляя документ на печать.
Одним из главных, если можно так выразиться, демонов в системе является демон init. Как уже говорилось, init является прародителем всех процессов в системе и имеет идентификатор 1. Выполнив задачи, поставленные в ему в файле inittab, демон init не завершает свою работу – он постоянно находится в памяти и отслеживает выполнение других процессов.
Прикладные процессы – это все остальные процессы, выполняющиеся в системе. Как правило, эти процессы порождаются в рамках сеанса работы пользователя. В каждом таком сеансе работы вначале запускается оболочка (командный интерпретатор) shell. Этот экземпляр оболочки называется login shell и завершение соответствующего процесса приводит к отключению пользователя от системы.
Процессы могут запускать ("внутри себя") отдельные потоки или, в буквальном переводе с английского, – нити (thread). Потоки — это параллельно выполняемые части одной программы. Потоки появились как логическое продолжение понятия процесса. Во-первых, появились некоторые задачи внутри ядра, которые требовалось выполнять параллельно с остальными работающими процессами. Во-вторых, ядро современной операционной системы должно уметь работать одновременно на нескольких процессорах. Эти две проблемы решаются посредством разделения некоторых частей ядра на отдельные потоки управления. Потоки ядра не имеют своего собственного адресного пространства и работают внутри пространства ядра. Фактически, они представлены лишь стеком данных и набором регистров, что позволяет ядру очень быстро переключаться между ними. Потоки ядра порождаются с помощью функции kernel_thread(), которая делает системный вызов clone(2) в режиме ядра. Потоки ядра обычно имеют высокий приоритет и не имеют пользовательского адресного пространства, они получают прямой доступ к адресному пространству ядра. Идентификаторы этих потоков находятся в начале диапазона числовых значений идентификаторов.
Потоки могут быть реализованы не только внутри ядра, но в пользовательских программах (более подробно об этом вы можете прочитать в статье [3]). С точки зрения системы потоки отличаются от других процессов только тем, что они выполняются в виртуальном адресном пространстве родительского процесса. В Linux потоки реализованы как процессы, запускаемые со специальным флагом.
Структуры данных процесса
А теперь подробнее рассмотрим, какие данные о процессе хранятся в структуре task_struct.
Идентификационные данные процесса
Когда создается новый процесс, ядро присваивает ему идентификатор – PID. Когда выполнение процесса завершилось, идентификатор освобождается и может быть присвоен другому процессу. Присвоение идентификаторов происходит последовательно по возрастанию, начиная с единицы. Идентификатор нового процесса обычно больше, чем идентификатор процесса, созданного ранее. Если идентификатор уже достиг максимально возможного значения, следующий процесс получит минимальный из свободных идентификаторов и цикл продолжается. В системе не может быть двух процессов с одинаковыми идентификаторами и на время жизни процесса его идентификатор не меняется.
Идентификаторы используются, в частности, для организации доступа к структурам ядра, хранящим информацию о процессах. А именно, отдельные записи типа task_struct, соответствующие процессам, взаимосвязаны двумя способами:
- как упорядоченный массив, индексированный по идентификаторам процессов;
как кольцевой двухсвязный список, в котором элементы ссылаются друг на друга посредством указателей next_task (предыдущий) и prev_task (последующий).
Каждый процесс хранит в своей структуре task_struct свой PID и идентификатор родительского процесса PPID – Parent Process ID.
Для каждого процесса запоминаются также реальный и эффективный идентификаторы пользователя и реальный и эффективный идентификаторы группы. Реальный идентификатор пользователя для процесса определяется идентификатором пользователя, запустившего процесс. Эффективный идентификатор процесса обычно совпадает с реальным. Однако в некоторых случаях процессу требуются дополнительные права для получения доступа к некоторым системным ресурсам (в первую очередь к ресурсам файловой системы). В таком случае права процесса могут быть расширены. Примером такого расширения прав служит случай запуска на выполнение исполняемого файла, для которого установлен атрибут SUID. В таком случае эффективный идентификатор запускаемого процесса будет равен идентификатору владельца исполняемого файла (которым может быть, например, администратор). Реальный и эффективный идентификаторы группы для процесса задаются аналогичным образом.
Контекст процесса
Под контекстом процесса понимают совокупность той информации, которая необходима для организации переключения между процессами, а именно:
- Указатели на адресное пространство процесса в режиме задачи. Сюда входят указатели на сегменты кода, данных и стека, а также указатели на области разделяемой памяти и динамических библиотек.
- Окружение процесса, т. е. перечень заданных для данного процесса переменных с их текущими значениями.
- Аппаратный контекст процесса, то есть значения общих и ряда системных регистров процессора. Сюда относятся состояния счетчика выполняемых команд (указатель на адрес очередной исполняемой инструкции), указатель стека и так далее.
- Указатели на каждый открытый процессом файл, а также указатели на два каталога – домашний (или корневой) каталог процесса и его текущий каталог. Счетчики числа обращений в индексных дескрипторах этих каталогов увеличиваются на единицу при создании процесса (при смене текущего каталога), в силу чего вы (или другой процесс) не можете удалить эти каталоги, пока процесс их не «освободит».
Можно сказать, что контекст процесса и его виртуальное адресное пространство образуют как бы «виртуальный компьютер», в котором и исполняется процесс.
Состояния процессов
Каждый запущенный процесс в любой момент времени находится в одном из следующих состояний (которое называют еще статусом процесса)
- Активен (R=Running) – процесс находится в очереди на выполнение, то есть либо выполняется в данный момент, либо ожидает выделения ему очередного кванта времени центрального процессора.
- «Спит» (S=Sleeping) – процесс находится в состоянии прерываемого ожидания, то есть ожидает какого-то события, сигнала или освобождения нужного ресурса.
- Находится в состоянии непрерываемого ожидания (D=Direct) – процесс ожидает определенного («прямого») сигнала от аппаратной части и не реагирует на другие сигналы;
- Приостановлен (T) – процесс находится в режиме трассировки (обычно такое состояние возникает при отладке программ).
- «Зомби» (Z=Zombie) – это процесс, выполнение которого завершилось, но относящиеся к нему структуры ядра по каким-то причинам не освобождены. Одной из причин их появления в системе может быть следующая ситуация. Обычно освобождение структур ядра, относящихся к процессу, выполняет процесс-родитель после получения от потомка сигнала о завершении. Но бывают случаи, когда родительский процесс завершается раньше дочернего. Процессы, не имеющие родителя, называются "сиротами". "Сироты" автоматически усыновляются процессом init, который и принимает сигналы об их завершении. Если процесс-родитель или init по каким-то причинам не может принять сигнал о завершении дочернего процесса, то процесс-потомок превращается в "зомби" и получает статус Z. Процессы-зомби не занимают процессорного времени (т. е. их выполнение прекращается), но соответствующие им структуры ядра не освобождаются. В некотором смысле это «мертвые» процессы. Уничтожение таких процессов — одна из обязанностей системного администратора.
Другие параметры процесса
Кроме перечисленных выше данных в структуре типа task_struct хранятся и другие параметры (или атрибуты) процесса. Вот только некоторые из них:
- Приоритет процесса устанавливается в тот момент, когда процесс порождается, и учитывается планировщиком процессов при выделении процессам времени центрального процессора. Приоритет процесса определяется так называемым "значением nice", которое лежит в пределах от +20 (наименьший приоритет, процесс выполняется только тогда, когда ничто другое не занимает процессор), до -20 (наивысший приоритет).
- Каждому процессу (кроме демонов) при рождении ставится в соответствие терминальная линия (TTY).
- Данные о времени создания процесса, а также о том, сколько времени центрального процессора было этим процессом потрачено. Кроме того, ядро может поддерживать внутренние таймеры процесса, позволяющие посылать процессу сигналы об истечении установленных временных интервалов.
- Пользовательская маска (umask) или маска доступа — указание на то, какие права надо удалить при создании нового файла или каталога из стандартного набора прав, присваиваемых файлу (каталогу).
- Полная командная строка запуска выполняемой процессом задачи.
Рамки журнальной статьи не позволяют рассмотреть все параметры, хранящиеся в структуре task_struct.
Режимы выполнения процессов
В каждый момент времени процесс находится в одном из двух режимов выполнения: либо в режиме ядра (kernel mode), либо в режиме задачи или пользовательском режиме (user mode). В режиме задачи выполняются инструкции прикладной программы, допустимые на непривилегированном уровне защиты процессора. Когда процессу требуется выполнить какие-то операции на уровне ядра, он делает системный вызов. Выполнение процесса при этом переходит в режим ядра (но от имени процесса, сделавшего системный вызов). Таким образом система защищает собственное адресное пространство от доступа прикладного процесса, который мог бы иначе нарушить целостность структур данных ядра.
Существуют всего три события, при которых выполнение процесса переходит в режим ядра: аппаратные прерывания, особые ситуации и системные вызовы.
Аппаратные прерывания генерируются периферийными устройствами при наступлении определенных событий (например, завершение дисковой операции ввода/вывода или поступления данных на последовательный порт) и имеют асинхронный характер, то есть в рамках процесса невозможно предсказать, в какой момент поступит то или иное прерывание. Обработка таких прерываний не должна блокироваться, поскольку это может вызвать блокирование выполнения независимого процесса.
Особые ситуации вызваны самим процессом и связаны с выполнением каких-то недопустимых инструкций, например, делением на ноль или обращением к несуществующей странице памяти. Обработка таких ситуаций происходит в контексте процесса, при этом может использоваться его адресное пространство, а сам процесс, при необходимости, блокироваться.
Системные вызовы позволяют процессам воспользоваться базовыми услугами ядра. Обращение к ним изменяет режим выполнения процесса и позволяет выполнить привилегированные инструкции ядра. Выполнение системного вызова происходит в режиме ядра, но в контексте процесса, сделавшего вызов.
Во всех этих случаях ядро получает управление и вызывает соответствующую системную процедуру для обработки события. Перед вызовом этой процедуры ядро сохраняет состояние процесса, а после завершения процедуры состояние процесса восстанавливается, и процесс возвращается в исходный режим выполнения.
Средства межпроцессорного взаимодействия
Хотя процессы изолированы друг от друга, они могут обмениваться данными с помощью предоставляемых системой средств межпроцессорного взаимодействия. К таким средствам относятся каналы (pipes), именованные каналы (FIFO), сообщения (messages), разделяемая память (shared memory), семафоры (semaphores), сигналы (signals) и сокеты (sockets).
Каналы
Канал обеспечивает однонаправленную передачу данных между двумя процессами, причем только между «родственными» процессами. Например, когда выполняется команда
cat myfile | wc
оба процесса cat и wc создаются процессом shell, и являются родственными. Поэтому каналы не могут использоваться в качестве средства межпроцессорного взаимодействия между независимыми процессами.
FIFO
FIFO тоже являются средством однонаправленной передачи данных, но, в отличие от программных каналов, имеют имена (поэтому и называются именованными каналами), которые позволяют независимым процессам получить к этим объектам доступ. FIFO является отдельным типом файла в файловой системе Linux. FIFO создаются либо системным вызовом mknod(2), либо командой mknod. После создания FIFO может быть открыт на запись и чтение, причем в разных независимых процессах.
Сообщения
Очереди сообщений размещаются в адресном пространстве ядра и являются разделяемым системным ресурсом. Каждая очередь сообщений имеет свой уникальный идентификатор. Процессы могут записывать сообщения в очередь и читать сообщения из очереди. При этом процесс, пославший сообщение в очередь, не обязан ожидать приема этого сообщения другим процессом (или процессами). Он может даже завершиться, а его сообщение будет прочитано позже. Отдельное сообщение содержит:
- тип сообщения;
- длину передаваемых данных в байтах (может быть нулевой);
- собственно данные (могут быть структурированными).
Процессы могут выбирать из очереди сообщения определенного типа, поэтому можно, например, организовать внеочередной прием срочных сообщений, если рассматривать тип как приоритет сообщений. Кроме того, процесс-отправитель может идентифицировать себя или клиента (например, указав в данных соответствующий PID), за счет чего может быть организована передача сообщений определенным процессам.
Семафоры
Семафоры, собственно говоря, не являются средством передачи данных. Они выполняют в межпроцессорном взаимодействии вспомогательную роль и служат для организации одновременного использования разделяемых данных несколькими процессами. Если два процесса читают один набор данных и выполнение процессов — последовательное, то это, очевидно, не создает проблем. Если же два процесса пытаются изменить один и тот же набор данных, то результат уже будет зависеть от того, в какой последовательности выполняется считывание и запись этих данных. Для управления такими процессами и вводятся семафоры.
В простейшем случае семафор представляет собой просто счетчик, содержащий 0 или единицу. Значение счетчика, равное 1, означает доступность соответствующего ресурса (например, файла или страницы виртуальной памяти). Если же в счетчике 0, значит, ресурс занят, и операция недопустима.
В общем случае семафор представляет собой не один счетчик, а группу из нескольких счетчиков, причем каждый счетчик может принимать не только значения 0 и 1, а любое значение из определенного интервала. Чаще всего число в семафоре представляет собой количество процессов, которые могут получить доступ к данным. Каждый раз, когда процесс обращается к данным, значение в семафоре, должно быть уменьшено на единицу, и увеличено, когда работа с данными будет прекращена. Семафоры можно использовать и для других целей, например, для счётчика ресурсов. В этом случае число в семафоре — количество свободных ресурсов (например, количество свободных ячеек памяти).
Семафоры должны быть доступны различным процессам, поэтому они размещаются в адресном пространстве ядра и операции с ними осуществляются через интерфейс системных вызовов.
Разделяемая память
Интенсивное использование таких механизмов межпроцессорного взаимодействия, как каналы, FIFO и очереди сообщений, может привести к значительному падению производительности системы. Это связано с тем, что данные, передаваемые с помощью этих механизмов, копируются из буфера передающего процесса в буфер ядра, а затем в буфер принимающего процесса. Механизм разделяемой памяти позволяет избавиться от излишних пересылок данных, предоставляя двум и более процессам доступ к одной и той же области оперативной памяти. Проблема совместного обращения двух процессов к одним и тем же данным решается с помощью семафоров.
Сокеты
Сокет (от англ. “socket” – разъем, гнездо) – это унифицированный интерфейс взаимодействия процессов с использованием стека сетевых протоколов в ядре. Сокет представляет собой виртуальный объект, аналогичный в некотором смысле сетевому интерфейсу. Такой объект характеризуется семейством протоколов и типом сокета, который представляет собой не что иное, как тип передаваемого через сокет потока данных. В настоящее время сокеты в Linux допускают использование примерно тридцати семейств протоколов и 6 типов сокетов (все они описываются в файле /usr/include/bits/socket.h)
Сокеты имеют соответствующий интерфейс доступа в файловой системе (имя, подобное имени файла или, точнее, устройства) и обращение к ним, так же как к обычным файлам, осуществляется через дескрипторы. Однако, в отличие от обычных файлов, сокеты представляют собой виртуальный объект, который существует, пока на него ссылается хотя бы один из процессов.
Чтобы использовать сокет, какой-то процесс должен его создать, а другие процессы – установить соединение с данным сокетом. Для создания сокетов используется системный вызов soket(2). Затем сокету присваивается имя путем вызова системного вызова bind(2). Другие процессы для установления соединения с сокетом используют системный вызов connect(2). По всем этим вызовам имеются man-странички, из которых вы можете получить дополнительную информацию о сокетах.
Сигналы
Сигналы — это средство, с помощью которого процессам можно передать сообщения о некоторых событиях в системе. С помощью сигналов можно осуществлять такие акции управления процессами, как приостановка процесса, запуск приостановленного процесса, завершение работы процесса. Пользователи тоже могут "общаться" с процессами путем посылки им сигналов. Когда мы нажимаем комбинацию клавиш <Ctrl>+<C>, чтобы завершить выполнение какой-то программы, мы фактически посылаем соответствующему процессу сигнал "Завершить работу". Завершаясь, процесс посылает родительскому процессу сигнал о своем завершении. Таким образом, сигналы напоминают программные прерывания, являясь средством, с помощью которого нормальное выполнение процесса может быть прервано. Сами процессы тоже могут генерировать сигналы, с помощью которых они передают определенные сообщения ядру и другим процессам.
Сигналы принято обозначать номерами или символическими именами. Все имена начинаются на SIG, но эту приставку иногда опускают: например, сигнал с номером 1 обозначают или как SIGHUP, или просто как HUP. Всего в Linux существует 63 разных сигнала, их перечень можно посмотреть по команде
[user]$ kill –l
Если после этой опции указать номер сигнала, то будет выдано его символическое имя, а если указать имя, то получим соответствующий номер.
Существуют несколько причин генерации сигналов или ситуаций, в которых отправляются сигналы.
- Терминальные прерывания. Нажатие пользователем некоторых комбинаций клавиш вызывает отправку определенного сигнала процессу, связанному с текущим терминалом.
- Особые ситуации. Когда выполнение процесса вызывает особую ситуацию, например, деление на ноль, процесс получает от ядра соответствующий сигнал.
- Межпроцессорное взаимодействие. Процесс может отправить сигнал другому процессу с помощью системного вызова kill(2).
- Управление заданиями. Командные интерпретаторы, поддерживающие управление заданиями, используют сигналы для манипулирования текущим и фоновыми заданиями.
- Квоты. Когда процесс превышает установленную для него квоту использования тех или иных ресурсов, ему отправляется соответствующий сигнал.
- Уведомления о готовности устройств или наступлении других событий тоже посылаются процессам с помощью сигналов.
- Если процесс установил таймер, то ему будет послан сигнал, когда значение таймера станет равным нулю.
Когда процесс получает сигнал, то возможен один из двух вариантов развития событий. Если в исполняемой процессом программе для данного сигнала определена подпрограмма обработки, то вызывается эта подпрограмма. В противном случае ядро выполняет от имени процесса действие, определенное по умолчанию для данного сигнала. Вызов подпрограммы обработки называется перехватом сигнала. Когда завершается выполнение подпрограммы обработки, процесс возобновляется с той точки, где был получен сигнал.
Можно заставить процесс игнорировать или блокировать некоторые сигналы. Игнорируемый сигнал просто отбрасывается процессом и не оказывает на него никакого влияния. Блокированный сигнал ставится в очередь на выдачу, но ядро не требует от процесса никаких действий до разблокирования сигнала. После разблокирования сигнала программа его обработки вызывается только один раз, даже если в течение периода блокировки данный сигнал поступал несколько раз.
Следует заметить, что любая обработка сигналов процессом производится только тогда, когда процесс выполняется. То есть процесс не получит сигнал, пока не будет выбран планировщиком и ему не будут предоставлено время центрального процессора.
Файловая система /proc
Чтобы управлять системой, ядро должно следить за каждым запущенным процессом, включая себя. Информация о запущенных процессах должна быть доступна и для многих пользовательских приложений, таких, как ps и top. Для организации управления процессами в Linux существует псевдо-файловая (или виртуальная) система процессов - /proc, к которой ядро хранит информацию о процессах. Файловая система процессов не предназначена для хранения файлов, создаваемых пользователями, она используется для получения информации о запущенных процессах.
Каталог /proc выглядит как часть общей каталоговой структуры, но фактически хранится в памяти, а не на диске. Если просмотреть файл /proc/mounts (который перечисляет все смонтированные файловые системы), то вы увидите строку:
/proc /proc proc rw 0 0
/proc контролируется ядром и не имеет соответствующего устройства.
В каталоге /proc содержится множество файлов и подкаталогов. Каждый подкаталог соответствует одному из запущенных в системе процессов и его имя совпадает с идентификатором процесса. В таблице 1 приведены для примера некоторые файлы, содержащиеся в каждом из подкаталогов, соответствующих процессам.
Таблица 1. Некоторые файлы из подкаталога процесса
|
cmdline |
Этот файл содержит полную командную строку запуска процесса до тех пор, пока процесс не будет "выгружен" или не станет "зомби". В последних двух случаях любое чтение информации из этого файла вернет 0 байтов информации. |
|
cwd |
Это символьная ссылка на текущий рабочий каталог процесса. Например, для того, чтобы узнать рабочий каталог процесса под номером 20, Вы можете ввести следующее: cd /proc/20/cwd; /bin/pwd |
|
environ |
Этот файл содержит окружение процесса. Записи отделяются друг от друга символами с кодом 0; 0 может также стоять в конце окружения. Чтобы узнать содержимое окружения процесса 1, надо выполнить следующее: (cat /proc/1/environ; echo) | tr "\000" "\n" |
|
status |
Информация о процессе, представленная в довольно удобном для просмотра виде. Она содержит, в частности, следующие строки:
Содержание других строк мы пока не рассматриваем. |
В корневом каталоге файловой системы /proc содержатся файлы, в которых хранится информация, относящаяся к параметрам ядра (см. табл. 2).
Таблица.2. Некоторые файлы из каталога /proc
|
cmdline |
Аргументы, переданные ядру Linux при загрузке. |
|
kcore |
Файл, отображающий физическую память системы. |
|
interrupts |
Счетчики количества прерываний IRQ в архитектуре i386. |
|
modules |
Список модулей, загруженных системой. См. lsmod(8). |
|
pci |
Полный список всех PCI-устройств, найденных во время инициализации ядра, а также их конфигурация. |
|
version |
Эта строка идентифицирует версию текущего ядра |
Более подробное описание файловой системы /proc, с описанием всех подкаталогов и файлов каталога /proc можно получить по команде man proc.
Управление процессами
Управление процессами заключается в том, чтобы уметь определить, какие процессы в системе запущены, запускать и останавливать их, изменять приоритеты процессов, менять режим выполнения процессов, переводя их в фоновый режим. Кратко рассмотрим используемые для этих целей команды.
Команда ps
Наиболее известной из таких команд является команда ps. Для того чтобы увидеть все процессы, выполняющиеся в данный момент в системе, достаточно запустить команду ps в следующем формате:
[user]$ ps -ef
Команда
[user]$ ps axf
позволяет увидеть все процессы в системе, с применением графического отображения отношения "предок-потомок". Впрочем, для того, чтобы увидеть "лес" деревьев "предок-потомок", лучше воспользоваться очень интересным аналогом команды ps axf — командой pstree. Вывод этой команды позволяет увидеть "дерево" запущенных в вашей системе процессов. Перечислить здесь все опции команды ps невозможно, воспользуйтесь для этого командой man ps.
Команда top
Команда ps позволяет сделать как бы "моментальный снимок" процессов, запущенных в системе. В отличие от ps команда top отображает состояние процессов и их активность "в реальном режиме времени". На рисунке 1 изображено окно терминала, в котором запущена программа top.
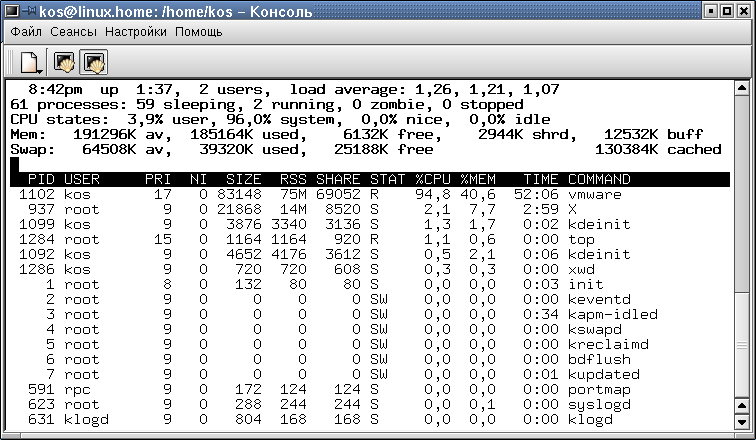
Рис. 1. Вывод команды top
В верхней части окна отображается астрономическое время, время, прошедшее с момента запуска системы, число пользователей в системе, число запущенных процессов и число процессов, находящихся в разных состояниях, данные об использовании ЦПУ, памяти и свопа. А далее идет таблица, характеризующая отдельные процессы. Число строк, отображаемых в этой таблице, определяется размером окна: сколько строк помещается, столько и выводится.
Содержимое окна обновляется каждые 5 секунд. Список процессов может быть отсортирован по используемому времени ЦПУ (по умолчанию), по использованию памяти, по PID, по времени исполнения. Переключать режимы отображения можно с помощью следующих клавиатурных команд:
- <Shift>+<N> — сортировка по PID;
- <Shift>+<A> — сортировать процессы по возрасту;
- <Shift>+<P> — сортировать процессы по использованию ЦПУ;
- <Shift>+<M> — сортировать процессы по использованию памяти;
- <Shift>+<T> — сортировка по времени выполнения.
С помощью команды <K> можно завершить некоторый процесс (его PID будет запрошен), а с помощью команды <R> можно переопределить значение nice для некоторого процесса.
Команды nice и renice
Для каждого процесса в момент порождения устанавливается его приоритет путем задания значения специального параметра nice. При обычном запуске команд или программ это значение принимается равным приоритету родительского процесса. Но существует специальная команда nice, которая позволяет запускать программы с заданным значением этого параметра, то есть изменять стандартное значение nice при запуске программы. Формат использования этой программы:
nice [- adnice] command [args]
где adnice — значение (от –20 до +19), добавляемое к значению nice процесса-родителя. Отрицательные значения может устанавливать только суперпользователь. Если опция adnice не задана, то по умолчанию для процесса-потомка устанавливается значение nice, увеличенное на 10 по сравнению со значением nice родительского процесса. Очевидно, что если вы не суперпользователь, то применять эту команду имеет смысл только тогда, когда вы хотите запустить некий процесс с низким значением приоритета.
Команда, renice служит для изменения значения nice для уже выполняющихся процессов. Суперпользователь может изменить приоритет любого процесса в системе. Другие пользователи могут изменять значение приоритета только для тех процессов, для которых данный пользователь является владельцем. При этом обычный пользователь может только уменьшить значение приоритета. Поэтому процессы с низким приоритетом не могут породить "высокоприоритетных детей".
Управление процессами с помощью сигналов
Как было сказано выше, одним из средств управления процессами являются сигналы. Некоторые сигналы можно сгенерировать с помощью определенных комбинаций клавиш, но такие комбинации существуют не для всех сигналов. Зато имеется команда kill, которая позволяет послать заданному процессу любой сигнал:
[user]$ kill [-сигн] PID [PID..]
где сигн — это номер сигнала, причем если указание сигнала опущено, то посылается сигнал 15 (SIGTERM — программное завершение процесса). Чаще всего используется сигнал 9 (KILL), с помощью которого суперпользователь может завершить любой процесс. Но сигнал этот очень "грубый", если можно так выразиться, потому что он просто «убивает» процесс, не давая ему времени на корректное сохранение всех обработанных данных. Поэтому в большинстве случаев рекомендуется использовать сигналы TERM или QUIT, которые завершают процесс более "мягко".
Обычные пользователи могут посылать сигналы только тем процессам, для которых они являются владельцами. Если в команде kill воспользоваться идентификатором процесса (PID), равным -1, то указанный в команде сигнал будет послан всем принадлежащим данному пользователю процессам. Суперпользователь root может посылать сигналы любым процессам. Когда суперпользователь посылает сигнал идентификатору -1, он рассылается всем процессам, за исключением системных. Если этим сигналом будет SIGKILL, то у простых пользователей будут потеряны все открытые ими, но не сохраненные файлы данных.
Перевод процесса в фоновый режим
При обычном запуске процесс работает, как говорят, "на переднем плане". Это значит, что процесс "привязывается" к терминалу, с которого он запущен, воспринимая ввод с этого терминала и осуществляя на него вывод. Но можно запустить процесс в фоновом режиме, когда он не связан с терминалом, для чего в конце командной строки запуска программы добавляют символ &.
В оболочке bash имеются две встроенные команды, которые служат для перевода процессов на передний план или возврата их в фоновый режим. Команда fg переводит указанный в аргументе процесс на передний план, а команда bg — переводит процесс в фоновый режим. Одной командой bg можно перевести в фоновый режим сразу несколько процессов, а вот возвращать их на передний план необходимо по одному. Аргументами команд fg и bg могут являться только номера заданий, запущенных из текущего экземпляра shell. Возможные значения заданий можно увидеть, выполнив команду jobs.
Команда nohup
При завершении сессии оболочка посылает всем порожденным ею процессам сигнал "отбой", по которому порожденные ею процессы могут завершиться, что не всегда желательно. Если вы хотите запустить в фоновом режиме программу, которая должна выполняться и после вашего выхода из оболочки, то ее нужно запускать с помощью утилиты nohup:
nohup команда &
Запущенный таким образом процесс будет игнорировать посылаемые ему сигналы (не игнорируются только сигналы HUP и QUIT).
Литература
- Т.Айвазян, Внутреннее устройство ядра Linux 2.4, 21 октября 2001 г., перевод А.Киселева,
- В.Хименко, "Процессы, задачи, потоки и нити", журнал «Мир ПК», 2000, №6.
- А.Калинин, «Потоки»,
Уже после написания данной статьи появилась интересная статья