





Библиотека сайта rus-linux.net
Что каждый программист должен знать о памяти.
Часть 2: Кэш-память процессора
Оригинал: "Memory part 2: CPU caches"Автор: Ulrich Drepper
Дата публикации: October 1, 2007
Перевод: Н.Ромоданов
Дата перевода: апрель 2012 г.
| Назад | Оглавление | Вперед |
3.3 Подробности реализации кэш-памяти процессора
Разработчики кэш-памяти столкнулись с проблемой, состоящей в том, что потенциально в кэш-памяти может оказаться любая ячейка огромной основной памяти. Если рабочий набор данных, используемых в программе, достаточно большой, то это означает, что за каждое место в кэш-памяти будут соревноваться многие фрагменты основной памяти. Как ранее уже сообщалось, нередко соотношение между кэш-памятью и основной памятью составляет 1 к 1000.
3.3.1 Ассоциативность
Можно было бы реализовать кэш-память, в которой каждая кэш-строка может хранить копию любой ячейки памяти. Это называется полностью ассоциативной кэш-памятью (fully associative cache). Чтобы получить доступ к кэш-строке, ядро процессора должно было бы сравнить теги всех до единой кэш-строк с тегом запрашиваемого адреса. Тег должен будет хранить весь адрес, который не будет указываться смещение в кэш-строке (это означает, что значение S, показанное на рисунке в разделе 3.2, будет равно нулю).
Есть кэш-память, которая реализована подобным образом, но взглянуть на размеры кэш-памяти L2, используемой в настоящее время, то видно, что это непрактично. Учтите, что 4 Мб кэш-памяти с кэш-строками размером в 64Б должна иметь 65 536 записей. Чтобы получить адекватную производительность, логические схемы кэш-памяти должны быть в состоянии в течение нескольких циклов выбрать из всех этих записей ту, которая соответствует заданному тегу. Затраты на реализацию такой схемы будут огромными.
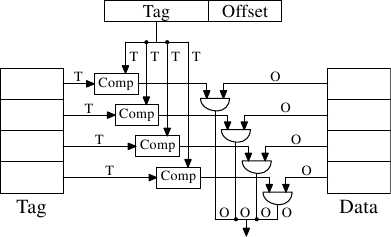
Рис.3.5: Схематическое изображение полностью ассоциативной кэш-памяти
Для каждой кэш-строки требуется, чтобы компаратор выполнил сравнение тега большого размера (заметьте, S равно нулю). Буква, стоящая рядом с каждым соединением, обозначает ширину соединения в битах. Если ничего не указано, то ширина соединения равна одному биту. Каждый компаратор должен сравнивать два значения, ширина каждого из которых равна Т бит. Затем, исходя из результата, должно выбираться и стать доступным содержимое соответствующей кэш-строки. Для этого потребуется объединить столько наборов линий данных О, сколько есть сегментов кэш-памяти (cache buckets). Число транзисторов, необходимых для реализации одного компаратора будет большим в частности из-за того, что компаратор должен работать очень быстро. Итеративный компаратор использовать нельзя. Единственный способ сэкономить на количестве компараторов, это снизить их число с помощью итеративного сравнения тегов. Это не подходит по той же самой причине, по которой не подходят итеративные компараторы: на это потребуется слишком много времени.
Полностью ассоциативная кэш-память практична для кэш-памяти малого размера (например, кэш-память TLB в некоторых процессорах Intel является полностью ассоциативной), но эта кэш-память должна быть небольшой - действительно небольшой. Речь идет максимум о нескольких десятках записей.
Для кэш-памяти L1i, L1d и кэш-памяти более высокого уровня необходим другой подход. Все, что можно сделать, это ограничить поиск. В самом крайнем случае каждый тег отображается точно в одну кэш-запись. Расчет прост: для кэш-памяти 4MB/64B с 65 536 записями мы можем напрямую обращаться к каждому элементу и использовать для этого с 6-го по 21-й биты адреса (16 битов). Младшие 6 битов являются индексом кэш-строки.
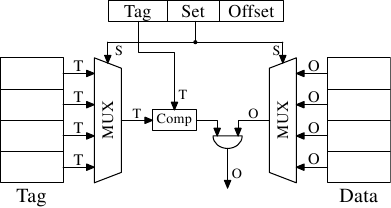
Рис.3.6: Схематическое изображение кэш-памяти с прямым отображением
Как видно из рисунка 3.6 реализация такой кэш-памяти с прямым отображением (direct-mapped cache) может быть быстрой и простой. Для нее требуется только один компаратор, один мультиплексор (на этой схеме приведены два, поскольку тег и данные разделены, но это не является строгим конструктивным требованием) и некоторая логическая схема для выбора контента, содержащего действительно допустимые кэш-строки. Компаратор сложный из-за требований, касающихся скорости, но теперь он только один; в результате можно потратить больше усилий, чтобы сделать его более быстрым. Реальная сложность такого подхода заключена в мультиплексорах. Количество транзисторов в простом мультиплексоре растет по закону O(log N), где N является количеством кэш-строк. Это приемлемо, но может получиться медленный мультиплексор, и в этом случае скорость можно увеличить, если потратиться на транзисторы в мультиплексорах и для увеличения скорости распараллелить часть работы. Общее количество транзисторов будет расти медленное в сравнении с ростом размера кэш-памяти, что делает это решение очень привлекательным. Но у такого подхода есть недостаток: он работает только в случае, если адреса, используемые в программе, равномерно распределены относительно битов, используемых для прямого отображения. Если это не так, и это обычно бывает, некоторые кэш-записи используются активно и, поэтому, неоднократно высвобождаются, в то время как другие практически вообще не используются, либо остаются пустыми.
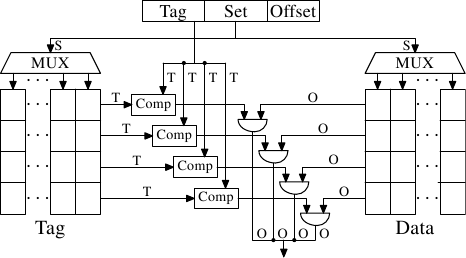
Рис.3.7: Схематическое изображение кэш-памяти с множественной ассоциативностью
Эту проблему можно решить с помощью кэш-памяти с множественной ассоциативностью (set associative). Кэш-память с множественностью ассоциативностью сочетает в себе черты кэш-памяти с полной ассоциативностью и кэш-памяти с прямым отображением, что позволяет в значительной степени избежать недостатков этих решений. На рис.3.7 показана схема кэш-памяти с множественной ассоциативностью. Память под теги и под данные разделена на наборы, выбор которых осуществляется в соответствие с адресом. Это похоже на кэш-память с прямым отображением. Но вместо того, чтобы для каждого значения из набора использовать отдельный элемент, один и тот же набор используется для кэширования некоторого небольшого количества значений. Теги для всех элементов набора сравниваются параллельно, что похоже на функционирование полностью ассоциативной кэш-памяти.
Результатом является кэш-память, которая достаточно устойчива к промахам из-за неудачного или преднамеренного выбора адресов с одними и теми же номерами наборов в одно и то же время, а размер кэш-памяти не ограничен количеством компараторов, которые могут работать параллельно. Если кэш-память увеличивается (смотрите рисунок), то увеличивается только количество столбцов, а не количество строк. Число строк увеличивается только в том случае, если повышается ассоциативность кэш-памяти. Сегодня процессоры для кэш-памяти L2 используют уровни ассоциативности до 16 и выше. Для кэш-памяти L1 обычно используется уровень, равный 8.
Таблица 3.1: Влияние размера кэш-памяти, ассоциативности и размера кэш-строки
| Размер кэш-памяти L2 |
Ассоциативность | |||||||
|---|---|---|---|---|---|---|---|---|
| Прямое отображение | 2 | 4 | 8 | |||||
| CL=32 | CL=64 | CL=32 | CL=64 | CL=32 | CL=64 | CL=32 | CL=64 | |
| 512k | 27 794 595 | 20 422 527 | 25 222 611 | 18 303 581 | 24 096 510 | 17 356 121 | 23 666 929 | 17 029 334 |
| 1M | 19 007 315 | 13 903 854 | 16 566 738 | 12 127 174 | 15 537 500 | 11 436 705 | 15 162 895 | 11 233 896 |
| 2M | 12 230 962 | 8 801 403 | 9 081 881 | 6 491 011 | 7 878 601 | 5 675 181 | 7 391 389 | 5 382 064 |
| 4M | 7 749 986 | 5 427 836 | 4 736 187 | 3 159 507 | 3 788 122 | 2 418 898 | 3 430 713 | 2 125 103 |
| 8M | 4 731 904 | 3 209 693 | 2 690 498 | 1 602 957 | 2 207 655 | 1 228 190 | 2 111 075 | 1 155 847 |
| 16M | 2 620 587 | 1 528 592 | 1 958 293 | 1 089 580 | 1 704 878 | 883 530 | 1 671 541 | 862 324 |
Если у нас кэш-память 4MB/64B и 8-канальная ассоциативность, то в кэш-памяти у нас будет 8192 наборов и для адресации кэш-наборов потребуется только 13 битов тега. Чтобы определить, какая из записей (если таковая имеется) содержит в кэш-наборе адресуемую кэш-строку, потребуется сравнить 8 тегов. Это можно сделать за очень короткое время. Как видно из практики, в этом смысл есть.
В таблице 3.1 показано количество промахов кэш-памяти L2 для некоторой программы (в данном случае — для компилятора gcc, который, по мнению разработчиков ядра Linux, является наиболее важным бенчмарком) при изменении размера кэш-памяти, размера кэш-строки, а также значения множественной ассоциативности. В разделе 7.2 мы познакомимся с инструментальным средством, предназначенным для моделирования кэш-памяти, которое необходимо для этого теста.
Просто, если это еще не очевидно, взаимосвязь всех этих значений в том, что размер кэш-памяти равен
размер кэш-строки х ассоциативность х количество множеств
Отображение адресов в кэш-память вычисляется как
O = log2 от размера кэш-строки
S = log2 от числа наборов
согласно рисунку в разделе 3.2.
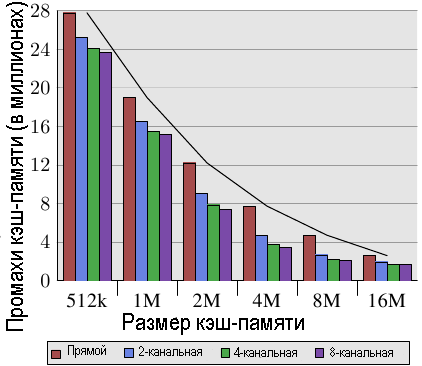
Рис.3.8: Размер кэш-памяти и уровень ассоциативности (CL=32)
Рис. 3.8 делает данные таблицы более понятными. На рисунке приведены данные для кэш-строки фиксированного размера, равного 32 байта. Если посмотреть на цифры для заданного размера кэш-памяти, то видно, что ассоциативность действительно может существенно помочь сократить число промахов кэш-памяти. Для кэш-памяти размером 8 МБ при переходе от прямого отображения на кэш-память с 2-канальной ассоциативностью экономится почти 44% кэш-памяти. В случае, если используется кэш-память со множественной ассоциативностью, то процессор может хранить в кэш-памяти рабочий набор большего размера, чем в случае кэш-памяти с прямым отображением.
В литературе иногда можно прочитать, что введение ассоциативности имеет тот же самый эффект, как удвоение размера кэш-памяти. Это, как это видно для случая перехода от кэш-памяти размером 4 МБ к кэш-памяти размером 8 МБ, верно в некоторых крайних случаях. Но это, конечно, не верно при последующем увеличении ассоциативности. Как видно из данных, последующее увеличение ассоциативности дает существенно меньший выигрыш. Нам, однако, не следует абсолютно не учитывать этот факт. В программе нашего примера пик использования памяти равен 5,6 MB. Так что при размере кэш-памяти в 8 Мб, что те же самые кэш-наборы будут использоваться многократно (более, чем дважды). С увеличением рабочего набора экономия может увеличиться, поскольку, как мы видим, при меньших размерах кэш-памяти преимущество от использования ассоциативности будет больше.
В целом, увеличение ассоциативность кэш-памяти выше 8, как кажется, дает слабый эффект при одном потоке рабочей нагрузки. С появлением многоядерных процессоров, которые используют общую кэш-память L2, ситуация меняется. Теперь у вас в основном есть две программы, которые обращаются к одной и той же кэш-памяти, в результате чего на практике эффект от использования ассоциативности должен увеличиться вдвое (или в четыре раза для четырехядерных процессоров). Таким образом, можно ожидать, что с увеличением числа ядер, ассоциативность общей кэш-памяти должна расти. Как это станет делать невозможным (16-канальную ассоциативность реализовывать уже трудно) разработчики процессоров начнут использовать общую кэш-память уровня L3 и далее, в то время как кэш-память уровня L2 будет, потенциально, совместно использоваться некоторым подмножеством ядер.
Другой эффект, который мы можем увидеть на рис.3.8, это то, как увеличение размера кэш-памяти способствует увеличению производительности. Эти данные нельзя интерпретировать без знания размера рабочего набора. Очевидно, что кэш-память такого размера, как основная память, должен привести к лучшим результатам, нежели кэш-память меньшего размера, так что в целом нет никаких ограничений на увеличение размера кэш-памяти и получения ощутимых преимуществ.
Как уже упоминалось выше, размер рабочего набора в его пиковом значении равен 5,6 Мб. Это значение не позволяет нам рассчитать размер памяти, который бы принес максимальную выгоду, но позволяет оценить этот размер. Проблема в том, что вся память используется не непрерывно и, следовательно, у нас есть конфликты даже при наличии 16M кэш-памяти и рабочего набора, размер которого равен 5,6M (вспомните преимущество 2-канальной ассоциативной кэш-памяти размером в 16 МБ над версией с прямым отображением). Но можно с уверенностью сказать, что при такой нагрузке преимущество кэш-памяти размером в 32 МБ будет несущественным. Однако кто сказал, что рабочий набор должен оставаться неизменным? С течением времени рабочие нагрузки растут и то же самое должно касаться размера кэш-памяти. Когда покупаются машины и принимается решение, за какой размер кэш-памяти требуется заплатить, стоит измерить размер рабочего набора. Почему это важно, можно увидеть на рис. 3.10.
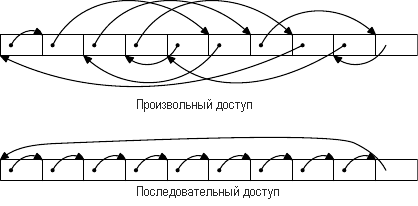
Рис.3.9: Размещение памяти, используемой при тестировании
Запускается два типа тестов. В первом тесте элементы обрабатываются
последовательно. В тестовой программе используется указатель n, но
элементы массива связаны друг с другом, так что они обходятся в том порядке, в котором они находятся в памяти. Этот вариант показан в нижней части рис.3.9. Есть одна обратная ссылка, идущая от последнего элемента. Во втором тесте (верхняя часть рисунка) элементы массива обходятся в произвольном порядке. В обоих случаях элементы массива образуют циклический односвязный список.
| Назад | Оглавление | Вперед |