





Библиотека сайта rus-linux.net
Что каждый программист должен знать о памяти.
Часть 2: Кэш-память процессора
Оригинал: "Memory part 2: CPU caches"Автор: Ulrich Drepper
Дата публикации: October 1, 2007
Перевод: Н.Ромоданов
Дата перевода: апрель 2012 г.
| Назад | Оглавление | Вперед |
3.2 Как работает кэш-память высокого уровня
Чтобы понять, каковы затраты и экономия от использования кэш-памяти, мы должны объединить вместе знания об архитектуре машины и об оперативной памяти, взятые из раздела 2, со знаниями о структуре кэш-памяти, описанной в предыдущем разделе.
По умолчанию все данные, которые читаются или записываются ядрами процессора, хранятся в в кэш-памяти. Есть области памяти, которые кэшировать нельзя, но это то, о чем должны беспокоиться разработчики ОС; это невидно прикладному программисту. Есть также инструкции, которые позволяют программисту принудительно обходить определенную кэш-память. Это будет обсуждаться в разделе 6.
Если процессору требуется некоторое слово данных, то поиск сначала осуществляется в кэш-памяти. Очевидно, что в кэш-памяти не может находиться содержимое всей оперативной памяти (в противном случае, нам не нужна была бы кэш-память), но, поскольку кэшируются адреса всей памяти, каждая запись в кэш-памяти помечается тегом с адресом слова данных основной памяти. Таким образом, при запросе на чтение или запись адрес можно искать в кэш-памяти по совпадению тега. Адрес в этом контексте может быть виртуальным, либо физическим адресом - все зависит от реализации кэш-памяти.
Поскольку в дополнение к фактически используемой памяти под тег требуется еще место, неэффективно использовать слова в качестве средства поиска данных в кэш-памяти. Для 32-разрядных слов на машине с архитектурой x86 для самого тэга, возможно, потребуется 32 бита памяти или более. Кроме того, поскольку пространственная компактность является одним из принципов, на которых основывается использование кэш-памяти, было бы плохо не принимать это во внимание. Поскольку есть вероятность, что фрагменты памяти, расположенные по соседству, могут использоваться совместно, они должны загружаться в кэш память вместе. Вспомните также о том, что мы узнали в разделе 2.2.1: использование модулей оперативной памяти будет еще более эффективным, если в них перемещаются по рядам подряд сразу много слов данных, причем без подачи нового сигнала CAS и даже сигнала RAS. Таким образом, данные хранятся в кэш-памяти не в виде отдельных слов, а, наоборот, в виде "строк", состоящих из нескольких смежных слов. В ранних вариантах кэш-памяти длина этих строк была 32 байта, теперь нормой является 64 байта. Если ширина шины памяти равна 64 бита, то это значит, что передача одной кэш-строки осуществляется за 8 действий. В DDR этот режим транспортировки данных очень эффективен.
Когда содержимое памяти необходимо процессору, то вся кэш-строка загружается в кэш-память L1d. Адрес памяти для каждой кэш-строки вычисляется с помощью маскирования значения адреса, зависящего от размера кэш-строки. Для 64 байтовой кэш-строки это означает, что обнуляются младшие 6 битов. Эти биты используются как смещение в кэш-строке. Оставшиеся биты в некоторых случаях используется для поиска кэш-строки в кэш-памяти, а также в качестве тега. На практике значение адреса делится на три части. Для 32-битного адреса это может выглядеть следующим образом:

Если размер кэш-строки равен 2O, то младшие O битов будут использоваться как смещение в кэш-строке. Следующие S битов рассматриваются как "индекс кэш-набора" ("cache set"). Мы вскоре подробнее рассмотрим, почему для кэш-строк используются кэш-наборы, а не один непрерывный участок. На данный момент достаточно понимать, что есть 2S кэш-наборов, содержащих кэш-строки. В результате остается 32 - S - O = T битов, из которых формируется тег. Эти Т битов представляют собой значение, ассоциированное (связанное) с каждой отдельной кэш-строкой и используемое для того, чтобы можно было различать все алиасы {известно, что все кэш-строки с одинаковым значением части S адреса имеют один и тот же алиас}, которые кэшированы в одном и том же кэш-наборе. Биты S используются для адресации кэш-набора и их не нужно сохранять, поскольку они одинаковы для всех кэш-строк в одном кэш-наборе.
Когда инструкция модифицирует содержимое памяти, процессор должен, прежде всего, загрузить кэш-строку, поскольку инструкция не изменяет сразу всю кэш-строку (исключение из правила: запись с объединением так, как это описано в разделе 6.1). Таким образом, будет загружено содержимое кэш-строки, которое было до операции записи. В кэш-памяти нельзя хранить части кэш-строк. Кэш-строка, в которую была сделана запись и которая не была обратно записана в в основную память, называют "грязной" ("dirty"). Как только будет выполнена запись в память, флаг, указывающий на то, что строка грязная, сбрасывается.
Для того, чтобы в кэш-память можно было загрузить новые данные, почти всегда сначала необходимо освободить место. При удалении из кэш памяти L1d кэш-строка перемещается вниз — в кэш-память L2 (в которой используется тот же самый размер кэш-строки). Конечно, это означает, что в кэш-памяти L2 должно быть место. А это, в свою очередь, может быть причиной перемещения содержимого в кэш-память L3 и, в конце концов, в основную память. Каждое последующее выталкивание содержимого из кэш-памяти будет все более дорогостоящим. То, что здесь описано, является моделью эксклюзивной или исключающей кэш-памятью (exclusive cache), предпочтение которой отдается в современных процессорах AMD и VIA. В Intel реализуется инклюзивная или включающая кэш-память (inclusive caches) {Это обобщение не вполне корректно. Некоторые варианты кэш-памяти являются исключающими, а некоторые включающие варианты кэш-памяти имеют свойства исключающей кэш-памяти}, в котором каждая кэш-строка, имеющаяся в кэш-памяти L1d, также присутвует в кэш-памяти L2. Поэтому удаление из кэш-памяти L1d происходит гораздо быстрее. При достаточном размере кэш-памяти L2 накладные расходы, вызванные хранением содержимого в двух местах, будут минимальными, а при выталкивании содержимого из кеш-памяти дадут выигрыш. Возможным преимуществом исключающей кэш-памяти в том, что загрузка новой кэш-строки выполняется только в кэш-память L1d, а не в L2, что может происходить быстрее.
Процессоры сами управляют кэш-памятью, причем наиболее удобным для них образом и до тех пор, пока не изменится модель памяти, определяемая архитектурой процессора. Например, отлично, когда у процессора есть возможность совсем мало или вообще не использовать шину памяти и с упреждением записывать измененные кэш-строки обратно в основную память. Большое количество вариантов реализации кэш-памяти имеется для процессоров с архитектурой x86 и x86-64, причем как для процессоров различных производителей, так и для моделей одного и того же производителя.
В системах с симметричной многопроцессорной архитектурой (SMP) кэш-память отдельных процессоров не может работать независимо друг от друга. В любой момент времени все процессоры должны видеть одно и то же содержимое памяти. Поддержка такого единообразного содержимого памяти называется "когерентностью кэш-памяти". Если процессор видит свою собственную кэш-память и основную память, он не должен видеть содержимое грязных кэш-строк в других процессорах. Реализация прямого доступа к кэш-памяти одного процессора из другого процессора является чрезвычайно дорогой и чрезвычайно узкой по производительности. Вместо этого, процессоры просто узнают, когда другой процессор хочет прочитать или записать определенную кэш-строку.
Если обнаружен доступ на запись и у процессора в его кэш-памяти есть просто копия кэш-строки, то эта кэш-строка помечается как неверная. Будущие обращения к ней потребуют ее перезагрузки. Обратите внимание, что доступ на чтение из другого процессора не потребует помечать ее как неверную, так что вполне может быть сразу несколько чистых копий кэш-строки.
В более сложных случаях реализации кэш-памяти могут возникать другие ситуации. Если кэш-строка, которую хочет прочитать или в которую хочет сделать запись другой процессор, помечена в кэш-памяти первого процессора как грязная, то потребуется совсем другая последовательность действий. В этом случае содержимое основной памяти будет рассматриваться как устаревшее и вместо него процессор, делающий запрос, должен получить содержимое кэш-строки от первого процессора. Первый процессор с помощью перехвата обращения обнаруживает эту ситуацию и автоматически отправляет данные процессору, сделавшему запрос. Это действие выполняется в обход основной памяти, хотя в некоторых реализациях предполагается, контроллер памяти должен отследить такую прямую передачу данных и сохранить в основной памяти содержимое кэш-строки. Если обнаружен доступ на запись, то первый процессор должен пометить кэш-строку как неверную.
Со временем были разработаны несколько протоколов когерентности кэш-памяти. Самым важным является протокол MESI, который мы представим в разделе 3.3.4. Все это можно подытожить в виде нескольких простых правил:
- Грязные кэш-строки не присутствуют в кэш-памяти любого другого процессора.
- Чистые копии одной и той же кэш-строки могут находиться в кэш-памяти сколь угодно большого количества процессоров.
Если соблюдать эти правила, то процессоры могут эффективно использовать свою кэш-память даже в многопроцессорных системах. Все, что процессоры должны делать, это контролировать доступ друг-друга на запись и сравнить адреса с теми, что хранятся в их локальной кэш-памяти. В следующем разделе мы расскажем о деталях реализации и, в частности, о расходах на реализацию.
Наконец, мы должны иметь общее представление о расходах, связанных попаданиями и промахами, возникающими при использовании кэш-памяти. Ниже приведены цифры для процессора Intel Pentium M:
| Где | Циклы |
Регистр | <= 1 |
Кэш-память L1d | ~3 |
Кэш-память L2 | ~14 |
Основная память | ~240 |
Это фактическое время доступа, измеренное в циклах процессора. Интересно отметить, что для кэш-памяти L2, реализованной в виде микросхемы, основная часть (возможно, даже большая) времени доступа связана с передачей сигналов по проводникам. Это физическое ограничение, которое может только ухудшиться по мере увеличения размера кэш-памяти. Эти цифры могут улучшиться только при смене технологического процесса (например, в линейке Intel переход от технологии 60 нм для Merom на технологию 45 нм для Penryn).
Числа в таблице выглядят большими, но, к счастью, указанные расходы происходят не всегда при каждом попадании или промахе, связанными с кэш-памятью. Некоторые затраты могут быть скрытыми. Во всех современных процессорах используются внутренние конвейеры, в которых происходит декодирование и подготовка инструкций к исполнению и которые имеют различную длину. В случае, если передача значения осуществляется в регистр, то часть накладных расходов, связанных с памятью (или кэш-памятью), не будет. Если операция загрузки в память может быть запущена в конвейере на достаточно раннем этапе, то она может выполняться параллельно с другими операциями и общие затраты, связанные с загрузкой, могут оказаться скрытыми. Это часто случается в кэш-памяти L1d, а для некоторых процессоров с длинными конвейерами также и в кэш-памяти L2.
Есть много причин, из-за которых нельзя начинать чтение из памяти на достаточно раннем этапе. Это может быть просто отсутствие достаточного количества ресурсов, необходимых для доступа к памяти, или может так случиться, что окончательный адрес загрузки станет доступен позднее в виде результата выполнения другой команды. В этом случае расходы на загрузку (полностью) скрыть не удастся.
Когда выполняется операция записи, процессор не обязан ждать, пока значение будет надежно сохранено в памяти. Если значение, запоминаемое в памяти, не будет сказываться на выполнении следующих инструкций, то нет причин, которые бы мешали процессору продолжать выполнение дальше. Он может достаточно рано начать выполнение следующей команды. Если используются теневые регистры (shadow registers), в которых могут находиться значения, уже недоступные в обычном регистре, процессор даже может изменять значение, которое должно быть запомнено с помощью еще не полностью выполненной операции записи.
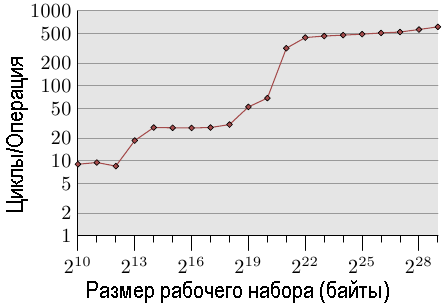
Рис.3.4: Время доступа для операций записи, выполняемых случайным образом
Иллюстрация влияния использования кэш-памяти приведена на рис.3.4. Далее мы расскажем о программе, которая генерирует данные; это простая имитация программы, случайным образом обращающаяся к некоторым областям памяти, которые можно переконфигурировать. Каждый элемент данных имеет фиксированный размер. Количество элементов зависит от размера выбранного рабочего набора. По оси Y указывается среднее число циклов процессора, необходимое для обработки одного элемента; обратите внимание, что шкала оси Y логарифмическая. В диаграммах подобного вида то же самое касается и оси X. Размер рабочего набора всегда указывается в виде степеней числа 2.
На графике показано три различных участка. Это не удивительно: в конкретном процессоре есть кэш-память L1d и L2 , но нет кэш-памяти L3. Исходя из некоторого опыта, мы можем сделать вывод, что размер кэш-памяти L1d равен 213 байтов, а размер кэш-памяти L2 равен 220 байтов. Если весь рабочий набор помещается в кэш-память L1d, то количество циклов на одну операцию для каждого элемента меньше 10. Как только он превышает размер кэш-памяти L1d, процессор будет загружать данные из кэш-памяти L2 и среднее время возрастет примерно до 28. Как только кэш-памяти L2 станет недостаточно, затрачиваемое время резко увеличится до 480 циклов и более. Это время, в течение которого большинству операций придется загружать данные из основной памяти. И хуже того: поскольку данные изменяются, грязные кэш-строки должны также записываться обратно в память.
Этот график должен стать достаточно побудительным мотивом для того, чтобы изучать те способы кодирования, которые помогают улучшить использование кэша. Здесь мы говорим не о каких-то нескольких ничтожных процентах; здесь речь идет об иногда возможных улучшениях на целые порядки. В разделе 6 мы рассмотрим способы, которые позволяют писать более эффективный код. В следующем разделе мы перейдем к подробностям реализации кэш-памяти процессоров. Знать об этом хорошо, но эти знания не являются необходимыми для изучения остальной части статьи. Так что этот раздел можно пропустить.
| Назад | Оглавление | Вперед |