





Библиотека сайта rus-linux.net
Библиотека Warp
Глава 11 из книги "Производительность приложений с открытым исходным кодом".
Оригинал: Warp
Авторы: Kazu Yamamoto, Michael Snoyman, Andreas Voellmy
Перевод: Н.Ромоданов
Дальнейшая работа
У нас есть несколько идей по улучшению проекта Warp в будущем, но здесь мы расскажем только о двух из них.
Выделение памяти
При получении и отсылки пакетов выделяются буферы памяти. Эти буферы выделяются как «подряд идущие» байтовые массивы, поэтому их можно передать в такие процедуры языка C, как recv() и send(). Несмотря на то, что в каждом системном вызове лучше всего получать или отправлять столько данных, сколько возможно, эти буферы имеют сравнительно умеренные размеры. К сожалению, метод компилятора GHC, который выделяет большие (больше 409 байтов в 64-битных машинах) подряд идущие массивы байтов, использует глобальную блокировку на этапе времени выполнения. Если в пользовательском потоке каждого ядра такие буферы выделяются часто, то такая блокировка при масштабировании в случае использования более 16 ядер может стать узким местом.
Мы провели первоначальное исследование того, как при генерации заголовка HTTP-ответа на производительность влияет выделения большого непрерывно идущего массива. Для этой цели в компиляторе GHC предоставляется функция eventlog, которая может записывать временные метки каждого события. Мы окружили функцию выделения памяти функцией записи пользовательского события. Затем мы откомпилировали mighty с этой вставкой и сделали записи в журнале событий. Полученный журнала событий выглядит следующим образом:
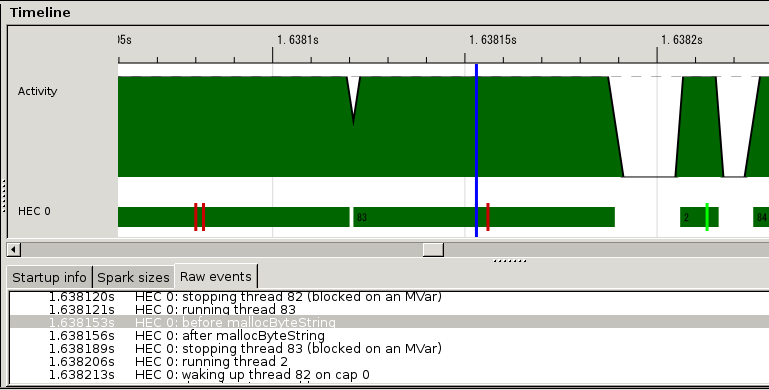
Рис.11.13: Журнал событий
Темно-красные полоски показывают событие, созданное нами. Поэтому, область, ограниченная с двух сторон двумя полосками, является временем, затрачиваемым на выделение памяти. Речь идет об 1/10 от времени сессии HTTP. Мы обсуждаем, как реализовать выделение памяти без блокировок.
Новая проблема Thundering Herd
Проблема thundering herd является достаточно известной проблемой. Предположим, что предварительно создаются процессы или нативные потоки, которые должны разделять сокет. Они вызывают функцию accept() на сокете. Когда создается соединение, то в старых реализациях Linux и FreeBSD проснутся все процессы или потоки. Соединение может получить только один из них, а остальные снова засыпают. Поскольку в результате происходит переключение многих контекстов, то мы сталкиваемся с проблемой производительности. Эта проблема называется проблемой thundering herd (проблема кричащего стада). В последних реализациях Linux и FreeBSD просыпается только один процесс или нативный поток, так что эта проблема ушла в прошлое.
В современных сетевых серверах наблюдается тенденция использовать семейство пулов epoll. Если рабочие потоки совместно используют слушающий сокет и они манипулируют с соединением через семейство пулов epoll, то снова возникает проблема thundering herd. Это связано с тем, что по соглашению в семействе пулов epoll уведомление отсылается всем процессам или нативным потокам. Этой новой проблеме thundering herd подвержены серверы nginx и mighty.
Менеджер параллельного ввода/вывода свободен от новой проблемы thundering herd.. В этой архитектуре, через семейство пулов epoll новое соединение получает только один менеджер ввода/вывода. А другие менеджеры ввода/вывода обрабатывают установленные соединения.
Заключение
Warp является универсальной серверной библиотекой, обеспечивающей эффективное HTTP-взаимодействие для широкого спектра практического применения. Чтобы достичь высокой производительности библиотеки, во многих случаях использовалась оптимизация, в том числе в сетевых коммуникациях, при управлении потоками и при анализе запросов.
Haskell оказался удивительным языком для написания подобного кода. Такие возможности, как неизменяемость данных по умолчанию упростили написание потокобезопасного кода и позволили избежать дополнительного копирования буферов. Многопоточность времени выполнения резко упростило написание кода, управляемого событиями. А мощные средства оптимизации, имеющиеся в компиляторе GHC, означали, что во многих случаях, мы могли писать код на высоком уровне и по-прежнему пользоваться преимуществами высокой производительности. Но при всей этой производительности размер нашего кода по-прежнему относительно крошечный (менее 1300 строк кода на момент написания статьи). Если вы ищете, на чем написать удобный в сопровождении, эффективный и параллельно работающий код, то нужно обратить внимание на язык Haskell.
Вернуться к началу статьи.