





Библиотека сайта rus-linux.net
Библиотека Warp
Глава 11 из книги "Производительность приложений с открытым исходным кодом".
Оригинал: Warp
Авторы: Kazu Yamamoto, Michael Snoyman, Andreas Voellmy
Дата публикации: 2013 г.
Перевод: Н.Ромоданов
Дата перевода: февраль 2014 г.
Warp является высокопроизводительной библиотекой для серверов HTTP, которая написана на языке Haskell, чисто функциональном языке программирования. На базе Warp реализованы Yesod - фреймворк веб-приложений и mighty - HTTP-сервер. Согласно нашему бенчмарку пропускной способности сервер mighty сравним по производительности с сервером nginx. В настоящей статье будет рассказано об архитектуре Warp и о том, как мы достигли высокой производительности. Библиотека Warp может работать на многих платформах, в том числе на Linux, вариантах BSD, Mac OS и Windows. Однако для простоты изложения мы в данной статье будем говорить только о системе Linux.
Сетевое программирование на языке Haskell
Некоторые считают, что функциональные языки программирования медленны или непрактичны. Однако, насколько нам известно, в языке Haskell предлагается почти идеальный подход для сетевого программирования. Это объясняется тем, что в компиляторе Glasgow Haskell Compiler (GHC), который является флагманом для языка Haskell, поддерживаются легковесные и надежные пользовательские потоки (иногда называемые зелеными потоками). В этом разделе мы кратко рассмотрим некоторые известные подходы сетевого программирования на серверной стороне и сравним их с сетевым программированием в языке Haskell. Мы покажем, что в языке Haskell предлагается такое сочетание приемов программирования и показателей производительности, которые недоступны при других подходах: удобные абстракции языка Haskell позволяют программистам писать четкий и простой код, а сложный компилятор GHC и многоядерная система времени выполнения создают программы для многоядерной среды, которые выполняются почти также, как современные сетевые программы, создаваемые вручную.
Нативные потоки
В традиционных серверах используется технология, называемая программированием потоков. В такой архитектуре, каждое соединение обрабатывается при помощи отдельного процесса или нативного потока (иногда называемым потоком операционной системы).
Такая архитектура может быть дополнительно сегментирована с использованием механизма, предназначенного для создания процессов или нативных потоков. Когда используется пул потоков, то заранее создаются несколько процессов или нативных потоков. Примером этого является режим prefork в сервере Apache. Либо каждый раз, когда устанавливается соединения, порождается процесс или нативный поток. Это проиллюстрировано на рис.11.1.

Рис.11.1: Нативные потоки
Преимущество такой архитектуры в том, что она позволяет разработчикам писать ясный код. В частности, использование потоков позволяет в коде следовать простому и хорошо знакомому порядку выполнения программ и использовать простые вызовы процедур для получения входных данных или выдачи выходных данных. Кроме того, поскольку в ядре операционной системы происходит назначение процессов или нативных потоков для имеющихся в наличии ядер, мы можем балансировать использование ядер. Его недостатком является то, что между ядром операционной системы и процессами или нативными потоками происходит большое количество переключений контекста , что ведет к снижению производительности.
Архитектура с событийным управлением
Недавняя тенденция в мире высокопроизводительных серверов выражается в том, чтобы пользоваться преимуществами программированием с событийным управлением. В такой архитектуре несколько соединений обрабатываются при помощи одного процесса (рис.11.2). Примером веб-сервера, использующего такую эту архитектуру, является сервер lighttpd.
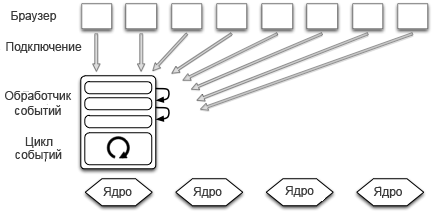
Рис.11.2: Архитектура с событийным управлением
Поскольку нет необходимости переключать процессы, переключений контекста будет немного и, тем самым, повышается производительность. Это главное преимущество такой архитектуры.
С другой стороны, такая архитектура существенно осложняет сетевую программу. В частности, в этой архитектуре поток управления программой преобразуется таким образом, что общим выполнением программы управляет цикл обработки событий. Поэтому программисты должны преобразовывать свою программу в набор обработчиков событий, каждое из которых выполняется по отдельности без блокировки кода. Это ограничение не позволяет программистам выполнять ввод/вывод с помощью вызовы процедур; вместо них должны быть использованы более сложные асинхронные методы. По той же самой причине больше не применяются обычные методы обработки исключений.
По одному процессу на каждое ядро
Многим пришла в идея для того, чтобы использовать N ядер, создать N процессов, управляемых событиями (рис. 11.3). Каждый процесс называется рабочим процессом (worker). Рабочие процессы должны совместно использовать порт сервиса (прим.пер.: разделять между собой использование порта сервиса). Совместное использование порта можно достичь с помощью технологии prefork.
В традиционном программировании процесса после того, как создается соединение, происходит разветвление процесса. В противоположность этому, разветвление процесса при использовании технологии prefork происходить еще создание новых соединений. Несмотря на одинаковое название, этот метод не следует путать с режимом prefork в сервере Apache.
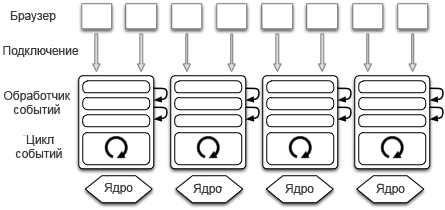
Рис.11.3: По одному процессу на каждое ядро
Одним из веб-серверов, в которых используется эта архитектура, является сервер nginx. В пакете Node.js в прошлом использовалась архитектура с событийным управлением, но в последнее время в нем также реализована технология prefork. Преимущество этой архитектуры в том, что она использует все ядра и производительность повышается. Тем не менее, в связи с тем, что есть зависимость от обработчиков и функций обратного вызова, вопрос, связанный с программами, имеющими плохо понятный код, не решен.
Пользовательские потоки
Для того, чтобы помочь решить вопрос с ясностью кода, можно использовать пользовательские потоки компилятора GHC. В частности, мы обрабатываем каждое соединение HTTP в новом пользовательском потоке. Этот поток программируется в традиционном стиле, в котором используются вызовы ввода/вывода с логической блокировкой. Это делает программу ясной и простой, тогда как вся сложность обработки неблокирующего ввода/вывода и диспетчеризации многоядерной работы возлагается на компилятор GHC.
Если заглянуть по капот, то видно, что компилятор GHC выполняет мультиплексирование пользовательских потоков на небольшое число нативных потоков. В систему реального времени компилятора GHC входит планировщик многоядерных потоков, который может с маленькими затратами осуществлять переключение пользовательских потоков, поскольку он это делает без привлечения каких-либо контекстных переключателей операционной системы.
Пользовательские потоки компилятора GHC являются легковесными; современные компьютеры могут без всяких задержек запускать 100000 пользовательских потоков. Они являются надежными, перехватываются даже асинхронные исключения (эта возможность используется обработчиком тайм-аутов, что описано в разделах «Архитектура библиотеки Warp» и «Таймеры дескрипторов файлов»). Кроме того, в планировщике есть алгоритм многоядерной балансировки нагрузки, который помогает использовать потенциал всех доступных ядер.
Когда пользовательский поток выполняет операцию ввода/вывода с логической блокировкой, например, принимает или передает данные в сокет, то, на самом деле, выполняется неблокирующий вызов. Если операция успешна, то поток сразу же продолжает работать без привлечения менеджера ввода/вывода или планировщика потоков. Если вызов будет блокирован, то поток вместо этого выполняет регистрацию соответствующего события вместе с компонентом менеджера ввода/вывода системы времени выполнения, а затем сообщает планировщику о том, что он находится в ожидании. Независимо от этого, поток менеджера ввода/вывода следит за событиями и уведомляет потоки, когда происходят события, которые потоки ожидают, заставляя их заново перепланировать их собственное исполнение. Все это происходит прозрачно для пользовательского потока без всяких усилий с его стороны программиста, использующего язык Haskell.
В языке Haskell, большая часть вычисления является недеструктивными. Это означает, что почти все функции потокобезопасные. Компилятор GHC использует выделение данных в качестве места и момента, безопасного для переключения контекста пользовательских потоков. Из-за функционального стиля программирования, новые данные создаются часто и известно, что такое выделение данных происходит достаточно регулярно с тем, чтобы его было достаточно для переключения контекста.
Хотя в прошлом в некоторых языках были пользовательские потоки, в настоящее время эти языки не применяются, т.к. потоки в них не были ни легковесными, ни надежными. Обратите внимание, что в некоторых языках предлагались сопрограммы уровня библиотек, но это не были потоки с вытесняющими приоритетами. Отметим также, что в Erlang и в Go предлагаются легковесные процессы и легковесные go-процедуры, соответственно.
На момент написания статьи, в mighty для того, чтобы с целью задейсвовать больше количество ядер, использовалась технология prefork разветвления процессов. (В Warp нет такой функциональной возможности). На рис.11.4 проиллюстрировано такое распределение в контексте веб-сервера с технологией prefork, записанной на языке Haskell, в котором каждое подключение браузера обрабатывается в отдельном пользовательском потоке, а каждый нативный поток в процессе, работающем в ядре процессора, выполняет работу для нескольких подключений.

Рис.11.4: Пользовательские потоки с одним процессом на каждое ядро
Мы обнаружили, что компонент менеджера ввода/вывода системы времени выполнения компилятора GHC сам имеет по производительности узкие места. Чтобы решить эту проблему, мы разработали менеджер параллельного ввода/вывода (parallel I/O manager), в котором для каждого ядра используются таблицы регистрации событий и мониторы событий, что значительно улучшает многоядерное масштабирование. Программа на языке Haskell с менеджером параллельного ввода/вывода выполняется как один процесс, а многочисленные менеджеры ввода/вывода для того, чтобы использовать много ядер, выполняются как нативные потоки (рис. 11.5). Любой пользовательский поток может быть выполнен на любом из ядер.

Рис.11.5: Пользовательские потоки в одном процессе
Компилятор GHC версии 7.8, в который добавлен менеджер параллельного ввода/вывода, будет выпущен осенью 2013 года. При наличии компилятора GHC версии 7.8 библиотека Warp сама может использовать эту архитектуру без каких-либо модификаций, а в сервере mighty не потребуется пользоваться технологией prefork.
Продолжение статьи: Архитектура библиотеки Warp.