





Библиотека сайта rus-linux.net
Простой веб-сервер
Оригинал: A Simple Web Server
Автор: Greg Wilson
Дата публикации: 25 February 2016
Перевод: Н.Ромоданов
Дата перевода: май 2016 г.
Глава 22 из предварительной версии книги "500 Lines or Less", которая входит в серию "Архитектура приложений с открытым исходным кодом", том 4.
Creative Commons
Перевод сделан в соответствие с лицензией . С русским вариантом лицензии можно ознакомиться .
Сегодня мы представляем семнадцатую главу предварительной публикации нашего нового сборника «500 строк или меньше». Глава написана Грегом Уилсоном ().
В этой главе мы начнем с написания наипростейшего веб-сервера, который можно себе представить, а затем постепенно будем расширять его с тем, чтобы он мог поддерживать более богатые возможности и более сложные функции. По ходу дела мы узнаем о том, как следует писать программы, которые должны быть устойчивыми к изменениям.
Как и обычно, если вы обнаружите ошибки, о которых, как вы считаете, стоит сообщить, пожалуйста, сделайте запись на .
Приятного чтения!
Это предварительная публикация главы из сборника , четвертой книги из серии книг . Пожалуйста, сообщайте в нашем о любых проблемах, которые вы обнаружите при чтении этой главы. Следите в или в за объявлениями о предварительных публикациях новых глав и окончательной публикацией.
Грег Уилсон является основателем Software Carpentry, ускоренного курса повышения вычислительных навыков, предназначенного для ученых и инженеров. Он в течение 30 лет работал в промышленности и научных кругах, а также является автором и редактором нескольких книг по вычислительной технике, в том числе книги Beautiful Code, получившей премию 2008 Jolt Award, а также первых двух томов сборника Архитектура приложений с открытым исходным кодом. Грег в 1993 году получил в Университете Эдинбурга докторскую степень в области компьютерных наук.
Введение
Мировая сеть в течение последних двух десятилетий изменила до неузнаваемости общество, но ее ядро изменилось мало. Большинство систем по-прежнему следуют правилам, которые Тим Бернерс-Ли (Tim Berners-Lee) предложил четверть века назад. В частности, большинство веб-серверов по-прежнему обрабатывают те же самые виды сообщений, которые они обрабатывали тогда, и таким же самым образом.
В этой главе мы рассмотрим, как это делается. И одновременно мы изучим, каким образом разработчики могут создавать программы с тем, чтобы их не надо было переписывать при добавлении новых функций.
Основные сведения
Практически каждая программа в сети работает в соответствие с семейством стандартов передачи данных, которые называются протоколом Internet Protocol (IP). Протокол, которого мы здесь коснемся, является протокол управления передачей данных Transmission Control Protocol (TCP/IP), который делает связь между компьютерами похожей на чтение и запись файлов.
Программы, использующие адреса IP, взаимодействую друг с другом через сокеты. Каждый сокет является оконечным устройством канала связи типа «точка-точка» точно так же, как телефон является оконечным устройством телефонного канала связи. Сокет определяется адресом IP, которым идентифицируется конкретный компьютер, и номером порта на этой машине. Адрес IP состоит из четырех 8-разрядных чисел, таких как 174.136.14.108, система доменных имен (DNS) сопоставляет эти цифры символическим именам, например, aosabook.org, которые людям легче запоминать.
Номер порта представляет собой число в диапазоне 0-65535, которое однозначно идентифицирует сокет на хост-машине. Если адрес IP аналогичен телефонному номеру компании, то номер порта аналогичен добавочному номеру. Порты 0-1023 зарезервированы для использования операционной системой; оставшиеся порты может использовать любая программа.
Протокол Hypertext Transfer Protocol (HTTP) описывает один из способов, которым программы могут обмениваться данными поверх протокола IP. Протокол HTTP намеренно простой: клиент через сокет-соединение отправляет запрос с указанием того, что он хочет получить, а сервер, в ответ, посылает некоторые данные. Данные могут быть скопированы из файла на диске, динамически сгенерированы программой, или частично взяты из файла и частично сгенерированы.

Рис.1. Цикл HTTP
Самая важное, что запрос HTTP является просто текстом: его можно создать или проанализировать с помощью любой программы. Для того, чтобы запрос был правильным в тексте должны быть фрагменты, показанные на рис.2.
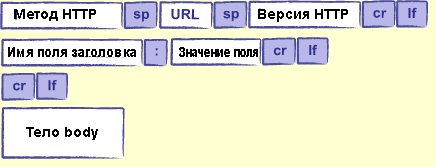
Рис.2. Запрос по протоколу HTTP
Методом HTTP почти всегда будет либо "GET" (получить информацию) или "POST" (отправка данных из формы или загрузка файлов). В URL указывается, что клиент хочет; это часто будет путь к файлу на диске, например, /research/experiments.html, но (и это самое важное) что делать с ним, полностью решает сервер. Версия HTTP обычно "HTTP / 1.0" или "HTTP / 1.1"; различия между ними для нас не имеют значения.
Заголовки HTTP являются парами ключ/значение; три примера показано ниже:
Accept: text/html Accept-Language: en, fr If-Modified-Since: 16-May-2005
В отличие от ключей в хэш-таблице, ключи в HTTP заголовках могут появляться любое количество раз. Это позволяет в запросе делать специфические вещи, например, указывать, что можно принять несколько типов содержимого.
И, наконец, телом запроса являются любые дополнительные данные, связанные с запросом. Этот механизм используется при передаче данных с помощью веб-формы, при загрузке файлов, и так далее. Чтобы обозначить конец заголовков, между последним заголовком и началом тела должна быть пустая строка.
Один из заголовков, который имеет название Content-Length, сообщает серверу, сколько ожидается прочитать байтов в теле запроса.
Ответы HTTP форматируются точно также, как и запросы HTTP (рис.3):
Рис.3. Ответ по протоколу HTTP
Версия (version), заголовки (headers), и тело (body) сообщения всегда имеют один и тот же формат и смысл. Код состояния (status code) является числом, указывающим, что произошло, когда запрос обрабатывался: 200 означает "все работало", 404 означает "не найдено", а другие коды имеют другие значения. Фраза статуса (status phrase) повторяет эту информацию в удобочитаемом виде, например, "OK" или "не найдено".
В данной главе нам нужно знать еще две особенности, касающиеся HTTP.
Во-первых, запрос не имеет состояния (stateless): каждый запрос обрабатывается по-отдельности, а сервер ничего не помнит между одним запросом и в следующем. Если приложение хочет отслеживать что-то вроде идентификации пользователя, то оно должно делать это самостоятельно.
Обычный это делается с помощью куки (cookie), являющийся короткой строкой символов, которую сервер отправляет клиенту, а клиент позже возвращает на сервер. Когда пользователь выполняет какую-то функцию, которая требует сохранить состояние в течение нескольких запросов, сервер создает новые куки, сохраняет их его в базе данных, и отправляет копию в браузер. Каждый раз, когда браузер отправляет куки обратно, сервер использует его для поиска информации о том, что делает пользователь.
Второе, что мы должны знать о HTTP, это то, что адрес URL может быть дополнен параметрами для того, чтобы передать больше информации. Например, если мы используем поисковую систему, мы должны указать наш запрос для поиска. Мы могли бы добавить его в URL, но все, что мы должны сделать, это добавить параметры в URL. Мы делаем это, добавив '?' в URL с последующими парами 'ключ = значение', разделяемые символом '&'. Например, в URL http://www.google.ca?q=Python делается запрос Google найти страницы, связанные с языком Python: ключ является 'q', а значением - 'Python'. Более длинный запрос - http://www.google.ca/search?q=Python&client=Firefox - говорит Google, что мы используем Firefox, и так далее. Мы можем передать любые параметры, которые мы хотим, но опять же, это дело приложения, работающего на веб-сайте, решить, на какие из них обращать внимание, и как их интерпретировать.
Конечно, поскольку '?' и '&' являются специальными символами, то должен быть способ, позволяющий избавляться от них. Стандарт кодирования адреса URL представляет специальные символы с использованием символа %, за которым следует 2-значный код, а пробел заменяется символом '+'. Таким образом, чтобы Google выполнил запрос "grade = A+" (с пробелами), мы будем использовать URL http://www.google.ca/search?q=grade+%3D+A%2B.
Открытие сокетов, создание запросов HTTP и разбора ответов является утомительным делом, поэтому для того, чтобы сделать большую часть этой работы , обычно используют библиотеки. Python поставляется с такой библиотекой, которая называется urllib2 (поскольку она заменяет более раннюю библиотеку, которая называлась urllib), но она выдает очень много данных, о которых большинство из нас не хотят знать. Более простой в использовании альтернативой библиотеки urllib2 является библиотека Requests. Ниже приведен пример, в котором она используется для загрузки страницы с сайта книг AOSA:
import requests
response = requests.get('http://aosabook.org/en/500L/web-server/testpage.html')
print 'status code:', response.status_code
print 'content length:', response.headers['content-length']
print response.text
status code: 200
content length: 61
<html>
<body>
<p>Test page.<<p>
</body>
</html>
request.get отправляет запрос HTTP GET на сервер и возвращает объект, содержащий ответ. Поле status_code этого объекта является кодом состояния ответа; в его поле content_length указывается число байтов данных в ответа, а в поле text находятся фактические данные (в данном случае, страница HTML).
Hello, Web
Мы не готовы написать свой первый простой веб-сервер. Основная идея проста:
- Подождать, пока кто-нибудь подключится к нашему серверу и отправит запрос HTTP;
- Проанализировать запрос;
- Выяснить, что запрашивается;
- Найти эти данные (или создать их динамически);
- Отформатировать данные в виде HTML; и
- отправить их обратно.
Шаги 1, 2 и 6 являются одинаковыми для всех приложений, поэтому в стандартной библиотеке Python есть модуль под названием BaseHTTPServer, который выполняет для нас эти шаги. Мы просто должны позаботиться о шагах 3-5, которые мы выполним в маленькой программе, приводимой ниже:
import BaseHTTPServer
class RequestHandler(BaseHTTPServer.BaseHTTPRequestHandler):
'''Handle HTTP requests by returning a fixed 'page'.'''
# Страница, отсылаемая обратно
Page = '''\
<html>
<body>
<p>Hello, web!</p>
</body>
</html>
'''
# Обработка запроса GET.
def do_GET(self):
self.send_response(200)
self.send_header("Content-Type", "text/html")
self.send_header("Content-Length", str(len(self.Page)))
self.end_headers()
self.wfile.write(self.Page)
#----------------------------------------------------------------------
if __name__ == '__main__':
serverAddress = ('', 8080)
server = BaseHTTPServer.HTTPServer(serverAddress, RequestHandler)
server.serve_forever()
Библиотечный класс BaseHTTPRequestHandler анализирует входящий запрос HTTP и анализирует, какой метод доступа в нем используется. Если это метод GET, то класс вызывает метод с именем do_GET. Наш класс RequestHandler переопределяет этот метод для того, чтобы динамически генерировать простую страницу: текст хранится в переменной Page уровня класса и его мы посылаем обратно клиенту после отправки кода ответа 200; в заголовке Content-Type клиенту сообщается о том, что наши данные нужно интерпретировать как HTML, и о длине страницы. При вызове метода end_headers вставляется пустая строка, которая отделяет наши заголовки от самой страницы.
Но класс RequestHandler это еще не вся история: нам еще нужны три последние строки для для того, чтобы в действительности запустить работающий сервер. В первой из этих строк в виде кортежа указывается адрес сервера: пустая строка означает "запуск на данной машине", а 8080 - порт. Затем мы создаем экземпляр BaseHTTPServer с этим адресом и именем нашего класса обработчика запросов в качестве параметров, а затем указываем, чтобы он работал вечно (что на практике означает до тех пор, пока мы не уничтожим его с помощью Control-C).
Если запускаете эту программу из командной строки, то она ничего на дисплей не выдает:
$ python server.py
Но если мы затем в нашем браузере перейдем на адрес http://localhost:8080, мы увидим в нем следующее:
Hello, web!
и это в вашей оболочке:
127.0.0.1 - - [24/Feb/2014 10:26:28] "GET / HTTP/1.1" 200 - 127.0.0.1 - - [24/Feb/2014 10:26:28] "GET /favicon.ico HTTP/1.1" 200 -
Первая строка достаточно простая: поскольку мы не запрашивали конкретный файл, наш браузер сделал запрос для '/' (корневого каталога набра каталогов и подкаталогов, которые обслуживаются сервером). Вторая строка появляется из-за того, что наш браузер автоматически посылает второй запрос файла изображения с названием /favicon.ico, которое будет отображаться в виде значка в адресной строке, если оно существует.
Отображаем значения запроса
Давайте изменим наш веб-сервер так, чтобы можно было отображать некоторые значения, включаемые в запрос HTTP. Во время отладки мы будем делать это довольно часто, так что мы сейчас также можем попрактиковаться. Для того, чтобы наш код был чистым, мы будем разделять создание страницы и ее отправку:
class RequestHandler(BaseHTTPServer.BaseHTTPRequestHandler):
# ...шаблон страницы...
def do_GET(self):
page = self.create_page()
self.send_page(page)
def create_page(self):
# ...заполняем...
def send_page(self, page):
# ...заполняем...
Метод send_page у на почти такой же, как был раньше:
def send_page(self, page):
self.send_response(200)
self.send_header("Content-type", "text/html")
self.send_header("Content-Length", str(len(page)))
self.end_headers()
self.wfile.write(page)
Шаблон для страницы, которую мы хотим отображать, это просто строка, содержащая таблицу HTML с некоторыми ячейками, которые должны быть заполнены:
Page = '''\
<html>
<body>
<table>
<tr> <td>Header</td> <td>Value</td> </tr>
<tr> <td>Date and time</td> <td>{date_time}</td> </tr>
<tr> <td>Client host</td> <td>{client_host}</td> </tr>
<tr> <td>Client port</td> <td>{client_port}s</td> </tr>
<tr> <td>Command</td> <td>{command}</td> </tr>
<tr> <td>Path</td> <td>{path}</td> </tr>
</table>
</body>
</html>
'''
и метод, который выполняет это заполнение:
def create_page(self):
values = {
'date_time' : self.date_time_string(),
'client_host' : self.client_address[0],
'client_port' : self.client_address[1],
'command' : self.command,
'path' : self.path
}
page = self.Page.format(**values)
return page
Основная часть программы не меняется: как и прежде, создается экземпляр класса HTTPServer с адресом и данным обработчиком запроса в качестве параметров, а затем начинается бесконечное обслуживание запросов. Если мы его запустим и отправим запрос из браузера по адресу http://localhost:8080/something.html, мы получаем:
Date and time Mon, 24 Feb 2014 17:17:12 GMT Client host 127.0.0.1 Client port 54548 Command GET Path /something.html
Обратите внимание на то, что мы не получаем ошибку 404 несмотря на то, что в файле на диске страница something.html не существует. Это потому, что веб-сервер является просто программой и может делать все, что захочет, когда он получает запрос: отправить обратно файл, указанный в предыдущем запросе, обработать страницу Википедии, выбранную случайным образом, или то, что мы в нем запрограммируем.
Обрабатываем статические страницы
Очевидным следующим шагом должна стать обработка страниц с диска вместо того, чтобы их генерировать на лету. Мы начнем с переписывания do_GET:
def do_GET(self):
try:
# Значение, которое точно будет запрашиваться.
full_path = os.getcwd() + self.path
# Этого нет...
if not os.path.exists(full_path):
raise ServerException("'{0}' not found".format(self.path))
# ...iэто файл...
elif os.path.isfile(full_path):
self.handle_file(full_path)
# ...это то, что нре обрпабатывается.
else:
raise ServerException("Unknown object '{0}'".format(self.path))
# Ошибки обработки.
except Exception as msg:
self.handle_error(/msg)
В этом методе предполагается, что он может обрабатывать любые файлы, лежащие в корневом каталоге, в котором работает сервер (который можно получить с помощью os.getcwd), и в его подкаталогах. Сервер, для того, чтобы получить доступ к файлу, который нужен пользователю, комбинирует название файла и путь доступа, указываемый в URL (который библиотека автоматически помещает в переменную self.path, и который всегда начинается с ведущего слеша '/').
Если такого пути не существует, или если он указывает не на файл, метод выдает сообщение об ошибке, генерируя и обрабатывая исключение. Но если путь указывает на файл, то вызывается метод-хелпер с именем handle_file, который читает файл и возвращает его содержимое. Этот метод просто читает файл и использует наш существующий метод send_content для того, чтобы отправить его содержимое обратно клиенту:
def handle_file(self, full_path):
try:
with open(full_path, 'rb') as reader:
content = reader.read()
self.send_content(content)
except IOError as msg:
msg = "'{0}' cannot be read: {1}".format(/self.path, msg)
self.handle_error(/msg)
Обратите внимание, что мы открываем файл в двоичном режиме - символ 'b' в 'rb', поэтому Python не будет пытаться "помочь" нам путем изменения последовательности байтов, которые выглядят как окончания строк Windows. Отметим также, что в реальной жизни чтение всего файла в память, когда он обрабатывается, будет плохим решением, поскольку файл может содержать несколько гигабайт видеоданных. Обработка подобной ситуации выходит за рамки данной главы.
Чтобы завершить этот класс, нам нужно написать метод, который будет обрабатывать ошибки, и шаблон страницы Сообщения об ошибках:
Error_Page = """\
<html>
<body>
<h1>Error accessing {path}</h1>
<p>{msg}</p>
</body>
</html>
"""
def handle_error(/self, msg):
content = self.Error_Page.format(/path=self.path, msg=msg)
self.send_content(content)
Эта программа работает, но только если мыне будем слишком к ней приглядываться. Проблема заключается в том, что она всегда возвращает код состояния 200, даже в тех случаях, когда запрашиваемая страница не существует. Да, в этом случае обратно отправляется страница, содержащая сообщение об ошибке, но поскольку наш браузер не может читать по-английски, он не знает, что запрос на самом деле не выполнен. Для того, чтобы это понять, нам нужно изменить handle_error и send_content следующим образом:
# Обработка неизвестных объектов.
def handle_error(/self, msg):
content = self.Error_Page.format(/path=self.path, msg=msg)
self.send_content(content, 404)
# Отсылка актуального содержимого.
def send_content(self, content, status=200):
self.send_response(status)
self.send_header("Content-type", "text/html")
self.send_header("Content-Length", str(len(content)))
self.end_headers()
self.wfile.write(content)
Обратите внимание, что мы не устанавливаем исключение ServerException, когда файл не может быть найден, но вместо этого генерируем страницу ошибки. Исключение ServerException предназначено для сигнализации о внутренней ошибке в коде сервера, то есть, то, что мы где-то ошиблись. С другой стороны, страница ошибки, создаваемая handle_error, выдается в случае, когда пользователь получил что-то неправильное, то есть, послал нам URL файла, которого не существует [1].
Показываем содержимое каталогов
В качестве следующего шага мы могли бы научить веб-сервер отображать список содержимого каталога в случае, если путь в URL указывает на каталог, а не на файл. Мы могли бы даже пойти еще на шаг дальше и проверять, есть ли в том же каталоге файл index.html для отображения, и показать список содержимого каталога только в том случае, если этого файла нет.
Но реализовывать эти правила в методе do_GET было бы ошибкой, поскольку в результате метод был бы длинным клубком с инструкциями if, управляющими особым поведением метода. Правильным решение - возвратиться на шаг назад и решать общую проблему, выясняя, что делать с URL. Ниже приведен переписанный метод do_GET:
def do_GET(self):
try:
# Выясняем, что точно запрашивается.
self.full_path = os.getcwd() + self.path
# Выясняем, как обрабатывать.
for case in self.Cases:
handler = case()
if handler.test(self):
handler.act(self)
break
# Обработка ошибок.
except Exception as msg:
self.handle_error(/msg)
Первый шаг точно такой же: Выяснить полный путь к тому, что запрашивается. После этого, все тоже самое, хотя код выглядит совсем иначе. Вместо кучи встроенных проверок данная версия перебирает множество случаев, сохраненных в списке. Каждый случай является объектом с двумя методами: test, который поверяет, можно ли запрос обработать, и act, который на самом деле предпринимает какие-то действия. Как только мы находим подходящий вариант, мы позволяем выполнить обработку и выйти из цикла.
Следующие три случая воспроизводят поведение нашего предыдущего сервера:
class case_no_file(object):
'''Файл или каталог не существует.'''
def test(self, handler):
return not os.path.exists(handler.full_path)
def act(self, handler):
raise ServerException("'{0}' not found".format(handler.path))
class case_existing_file(object):
'''Файл существует.'''
def test(self, handler):
return os.path.isfile(handler.full_path)
def act(self, handler):
handler.handle_file(handler.full_path)
class case_always_fail(object):
'''Базовый вариант в случае, если ничего другого не работает.'''
def test(self, handler):
return True
def act(self, handler):
raise ServerException("Unknown object '{0}'".format(handler.path))
и вот как мы строим список обработчиков в верхней части класса RequestHandler:
class RequestHandler(BaseHTTPServer.BaseHTTPRequestHandler):
'''
Если запрашиваемый путь указывает на файл, то обрабатывается файл.
Если что-нибудь не так, то создается станица с сообщением об ошибке.
'''
Cases = [case_no_file(),
case_existing_file(),
case_always_fail()]
...все остальное, как и прежде...
Теперь видно, что это сделало наш сервер стал более сложным: файл увеличился с 74 до 99 строк, и есть дополнительный уровень косвенности без каких-либо новых функциональных возможностей. Удобство такого решения будет видно, когда мы вернемся к задаче, с которой началась эта глава, и попытаемся научить наш сервер обрабатывать в каталоге страницу index.html, если она имеется, и выдавать содержимое каталога, если такой страницы нет. Обработчик для первого случая будет следующим:
class case_directory_index_file(object):
'''Serve index.html page for a directory.'''
def index_path(self, handler):
return os.path.join(handler.full_path, 'index.html')
def test(self, handler):
return os.path.isdir(handler.full_path) and \
os.path.isfile(self.index_path(handler))
def act(self, handler):
handler.handle_file(self.index_path(handler))
Здесь вспомогательный метод index_path строит путь к файлу index.html; когда этот метод помещается в обработчик, то это предотвращает возникновение беспорядка в основном классе RequestHandler. Метод test проверяет, указывает ли путь на каталог, в котором есть страница index.html, а метод act просто обращается к основному обработчику запросов для обработки этой страницы.
Единственное изменение, которое необходимо сделать в RequestHandler для включения этой логики, это объект case_directory_index_file к нашему списку Cases:
Cases = [case_no_file(),
case_existing_file(),
case_directory_index_file(),
case_always_fail()]
А как насчет каталогов, которые не содержат страницы index.html? Проверка точно такая же со специально вставленным оператором not, но что можно сказать о методе act? Что он должен делать?
class case_directory_no_index_file(object):
'''Обработка списка содержимого каталога, в котором нет страницы index.html.'''
def index_path(self, handler):
return os.path.join(handler.full_path, 'index.html')
def test(self, handler):
return os.path.isdir(handler.full_path) and \
not os.path.isfile(self.index_path(handler))
def act(self, handler):
???
Кажется, мы загнали себя в угол. По логике вещей, метод act должен создавать и возвращать список каталогов, но наш существующий код этого не допускает: в RequestHandler.do_GET вызывается метод act, но не предполагается, что будет возвращено значение о оно должно быть обработано. На данный момент, давайте добавим метод в RequestHandler для генерации списка содержимого каталога и вызовем его из метода act нашего обработчика ситуаций:
class case_directory_no_index_file(object):
'''Обработка списка содержимого каталога, в котором нет страницы index.html.'''
# ...index_path и test как было показано выше...
def act(self, handler):
handler.list_dir(handler.full_path)
class RequestHandler(BaseHTTPServer.BaseHTTPRequestHandler):
# ...all the other code...
# Как изображать список содержимого каталога.
Listing_Page = '''\
<html>
<body>
<ul>
{0}
</ul>
</body>
</html>
'''
def list_dir(self, full_path):
try:
entries = os.listdir(full_path)
bullets = ['<li>{0}</li>'.format(e) for e in entries if not e.startswith('.')]
page = self.Listing_Page.format('\n'.join(bullets))
self.send_content(page)
except OSError as msg:
msg = "'{0}' cannot be listed: {1}".format(/self.path, msg)
self.handle_error(/msg)
Протокол CGI
Конечно, большинство из нас не хотят редактировать исходный код веб-сервера для того, чтобы добавлять новые функциональные возможности. Чтобы оградить нас от этого, в серверах всегда поддерживается механизм, называемый Common Gateway Interface (CGI), который предоставляет в веб-сервере стандартный способ запуска внешней программы с тем, чтобы выполнить запрос.
Например, предположим, что мы хотим, чтобы сервер иметь возможность отображать местное время в HTML-странице. Мы можем сделать это в отдельной программе с помощью всего нескольких строк кода:
from datetime import datetime
print '''\
<html>
<body>
<p>Generated {0}</p>
</body>
</html>'''.format(datetime.now())
Для того, чтобы дать веб-серверу задание запустить эту программу для нас, мы добавим в обработчик следующий случай:
class case_cgi_file(object):
'''Something runnable.'''
def test(self, handler):
return os.path.isfile(handler.full_path) and \
handler.full_path.endswith('.py')
def act(self, handler):
handler.run_cgi(handler.full_path)
Проверка простая: действительно путь к файлу заканчивается на .py? Действие столь же просто: попросите RequestHandler запустить эту программу.
def run_cgi(self, full_path):
cmd = "python " + full_path
child_stdin, child_stdout = os.popen2(cmd)
child_stdin.close()
data = child_stdout.read()
child_stdout.close()
self.send_content(data)
Это очень небезопасно: если кто-то знает путь к файлу Python на нашем сервере, то мы просто позволим ему запустить этот файл, не заботясь о том, к каким данным он может получить доступ, может ли этот файл содержать бесконечный цикл, или что-нибудь еще [2].
Если отмести все второстепенное, то основная идея проста:
- Запуск программы в подпроцессе.
- Собрать все данные, которые подпроцесс отправляет в стандартный выходной поток.
- Отправка этих данных обратно клиенту, который сделал запрос.
Полный протокол CGI гораздо богаче, чем описано здесь; в частности он допускает наличие в URL параметров, которые сервер передает в выполняемую программу, но эти детали не влияют на общую архитектуру системы ...
... которая вновь становится довольно запутанной. В RequestHandler изначально был один метод, handle_file, для работы с контентом. Теперь мы добавили два специальных случая в виде list_dir и run_cgi. Эти три метода на самом деле находятся не там, где должны, поскольку они, прежде всего, используются в других местах.
Исправить это достаточно просто: создать родительский класс для всех наших обработчиков и переместить методы в этот класс, если (и только если) они общие для двух или более обработчиков. После завершения проеобразования класс RequestHandler выглядит следующим образом:
class RequestHandler(BaseHTTPServer.BaseHTTPRequestHandler):
Cases = [case_no_file(),
case_cgi_file(),
case_existing_file(),
case_directory_index_file(),
case_directory_no_index_file(),
case_always_fail()]
# Как отображается ошибка.
Error_Page = """\
<html>
<body>
<h1>Error accessing {path}</h1>
<p>{msg}</p>
</body>
</html>
"""
# Классификация и обработка запроса.
def do_GET(self):
try:
# Figure out what exactly is being requested.
self.full_path = os.getcwd() + self.path
# Figure out how to handle it.
for case in self.Cases:
if case.test(self):
case.act(self)
break
# Обработка ошибок.
except Exception as msg:
self.handle_error(msg)
# Обработка неизвестных объектов.
def handle_error(self, msg):
content = self.Error_Page.format(path=self.path, msg=msg)
self.send_content(content, 404)
# Отсылка актуального контента.
def send_content(self, content, status=200):
self.send_response(status)
self.send_header("Content-type", "text/html")
self.send_header("Content-Length", str(len(content)))
self.end_headers()
self.wfile.write(content)
Родительский класс для наших обработчиков:
class base_case(object):
'''Parent for case handlers.'''
def handle_file(self, handler, full_path):
try:
with open(full_path, 'rb') as reader:
content = reader.read()
handler.send_content(content)
except IOError as msg:
msg = "'{0}' cannot be read: {1}".format(full_path, msg)
handler.handle_error(msg)
def index_path(self, handler):
return os.path.join(handler.full_path, 'index.html')
def test(self, handler):
assert False, 'Not implemented.'
def act(self, handler):
assert False, 'Not implemented.'
Обработчик для существующего файла (случайным образом выбран в качестве примера):
class case_existing_file(base_case):
'''File exists.'''
def test(self, handler):
return os.path.isfile(handler.full_path)
def act(self, handler):
self.handle_file(handler, handler.full_path)
Обсуждение
Различие между нашим исходным кодом и реорганизованной версией отражает две важные идеи. Во-первых, класс следует рассматривать как набор соотвествующих сервисов. В RequestHandler и в base_case решения не принимаются или и действия не выполняются; они предоставляют инструментальные средства, которые могут использовать другие классы для того, чтобы принять решения или выполнить действия.
Во-вторых, возможность расширения: функциональные возможности нашего веб-сервера могут быть расширены либо путем написания внешней программы CGI, либо путем добавления класса обработчика. В последнем случае в RequestHandler требуется изменение одной строки (вставить обработчик в список Cases), но мы могли бы избавиться от этого, если бы был конфигурационный файл, который бы читал веб-сервер и в соотвествие с ним загружал классы обработчиков. В обоих случаях можно игнорировать большинство деталей нижнего уровня точно также, как авторы класса BaseHTTPRequestHandler позволили нам игнорировать детали обработки соединений с использованием сокетов и анализа запросов HTTP.
Эти идеи универсальны; посмотрите, можете ли вы найти возможность использовать их в своих собственных проектах.
- Мы собираемся в этой главе использовать
handle_errorнесколько раз, в том числе в нескольких случаях, когда код состояния 404 не подходит. По мере продолжения чтения постарайтесь подумать, как вы бы расширили эту программу таким образом, чтобы в каждом конкретном случае можно было легко указывать код статуса ответа. - В нашем коде также используется библиотечная функция
popen2, которая устарела и заменена возможностями модуляsubprocess. Тем не менее, функцияpopen2оказалась более подходящей для данного примера.
Дополнение
Перевод данной главы сделан по тексту преварительной публикации. 12 июля 2016 был выпущен и опубликован