





Библиотека сайта rus-linux.net
Шагомер в реальном мире
Оригинал: A Pedometer in the Real World
Автор: Dessy Daskalov
Дата публикации: July 12, 2016
Перевод: Н.Ромоданов
Дата перевода: январь 2017 г.
Перевод главы 16 из книги "500 Lines or Less", которая представляет собой четвертый том серии "Архитектура приложений с открытым исходным кодом".
Creative Commons
Перевод был сделан в соответствие с лицензией . С русским вариантом лицензии можно ознакомиться .
Деси (Dessy) является инженером по профессии, предпринимателем по призванию, и разработчиком в сердце. Она в настоящее время - технический директор и соучредитель компании Nudge Rewards. когда она вместе со своей командой не занята сборкой программного продукта, ее можно найти среди тех, кто обучает других кодированию, посещает или проводит технические мероприятия в Торонто, а в интернете ее можно найти по ссылкам dessydaskalov.com и @dess_e.
Идеальный мир
На многих разработчиков программ то, что они помнят, что их обучение было удовольствием жизни в очень идеальном мире. Нас учили решать четко определенные задачи в идеализированных предметных областях.
После этого мы были брошены в реальный мир, со всеми его сложностями и проблемами. Весь беспорядок реального мира делает его еще более захватывающим. Когда вы можете решить проблему реальной жизни со всеми ее причудами, то вы можете создать программу, которая действительно помогает людям.
В этой главе мы рассмотрим проблему, которая, на первый взгляд, выглядит просто и очень быстро становится сложной, когда образуется смесь из реального мира и реальных людей.
Мы будем вместе создавать базовое приложение — шагомер или педометр. Мы начнем с обсуждения теории, стоящей за работой шагомера, выбора алгоритма подсчета шагов без рассмотрения его реализации в коде. Затем, мы реализуем наше решение в коде. И, наконец, мы добавим в наш код веб-слой с тем, чтобы у нас для работы с приложением был дружественный пользовательский интерфейс.
Итак, давайте засучим рукава и приготовимся распутывать реальные проблемы.
Теория работы шагомера
Рост возможностей мобильных устройств привел к тенденции собирать все больше и больше данных о нашей повседневной жизни. Одни из данных, которые собирают многие, это количество шагов, которые они сделали в течение определенного периода времени. Эти данные могут быть использованы для того, чтобы следить за состоянием здоровья, готовиться к спортивным мероприятиям, либо просто знать количество пройденных шагов для тех из нас, кто просто одержим сбором и анализом данных. Шаги можно пересчитать с помощью шагомера, который в качестве входных данных часто использует данные поступающие из аппаратно реализованного акселерометра.
Что такое акселерометр?
Акселерометр представляет собой часть оборудования, с помощью которого измеряется ускорение по осям x, y и z. Многие носят с собой акселерометр всюду, где они ходят, так как он встроен в практически все смартфоны, которые в настоящее время есть на рынке. Оси x, y и z задаются относительно телефона.
Акселерометр возвращает сигнал о положении устройства в 3-мерном пространстве. Сигнал представляет собой набор точек данных, записанных в течение некоторого времени. Каждый компонент сигнала представляет собой временной ряд, отражающих ускорение устройства по осям x, y или z. Каждая точка временного ряда является ускорением устройства в конкретном направлении в определенный момент времени. Ускорение измеряется в единицах силы g или просто в g. Один g равен m/s2, усредненному ускорению силы тяжести на Земле.
На рис.16.1. показан пример сигнала, поступающего от акселерометра в в виде трех временных рядов.
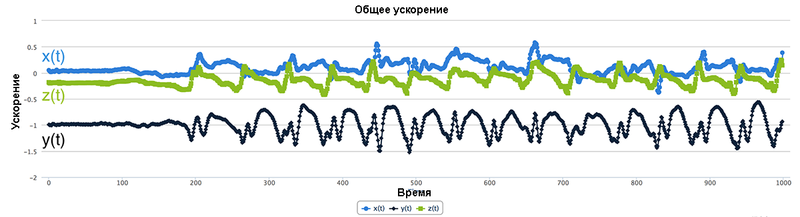
Рис.16.1. Пример сигнала, поступающего от акселерометра
Частота дискретизации акселерометра (sampling rate), на которую он может быть откалиброван, определяет количество измерений, осуществляемых в секунду. Например, акселерометр с частотой дискретизации 100 возвращает каждую секунду 100 точек данных для каждого временного ряда x, y и z.
Давайте поговорим о ходьбе
Когда человек ходит, они на каждом шаге слегка подпрыгивает. Просто посмотрите верхнюю часть головы человека, как он от вас уходит. Их голова, туловище и бедра синхронно движутся в сглаженном прыжке. Хотя эти прыжки не очень большие, только один или два сантиметра, они являются самыми явными, самыми постоянными и самыми узнаваемыми частями сигнала акселерометра идущего человека.
Человек на каждом шагу перемещается вверх и вниз в вертикальном направлении. Если вы идете по земле (или по другому шарообразному предмету большой массы, плавающему в космическом пространстве), то перемещения, как правило, осуществляются в том же самом направлении, в котором действует сила тяжести.
Мы будем считать шаги с помощью акселерометра путем подсчета отскока вверх и вниз. Поскольку телефон может вращаться в любом направлении, мы будем использовать силу тяжести для того, чтобы знать, какое направление будет считаться вниз. Шагомер может подсчитывать шаги путем подсчета количества скачков в направлении действия силы тяжести.
Давайте посмотрим на человека, идущего со смартфоном, имеющем акселерометр и лежащем в кармане его рубашки (рис.16.2).
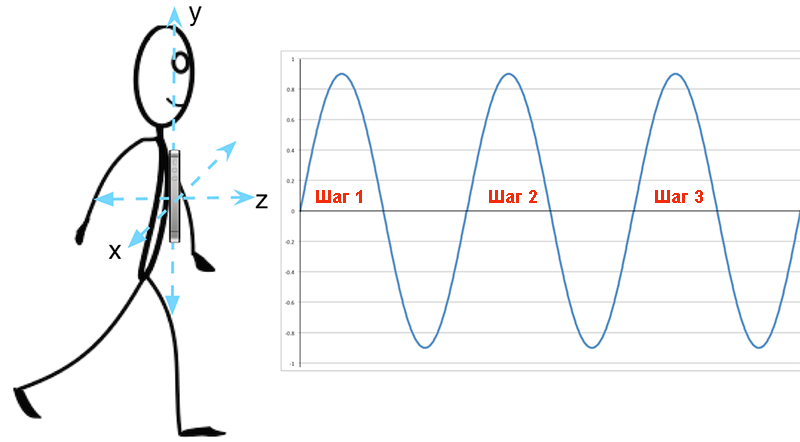
Рис.16.2. Идущий человек
Для простоты мы будем считать, что человек:
- идет в направлении z;
- подпрыгивает на каждом шагу в направлении y и
- на протяжении всей прогулки не меняет ориентацию телефона.
В нашем идеальном мире ускорение от прыжка на каждом шаге будет формировать идеальную синусоиду в направлении у. Каждый пик синусоиды соответствует точно одному шагу.
Подсчет шагов становится подсчетом этих идеальных пиков.
Ах, радости совершенного мира, с которыми мы можем в даже поэкспериментировать в статьях, таких как эта. Не волнуйтесь, все, о чем мы говорим, немного более хаотичное и намного более захватывающее. Давайте добавим в наш мир чуть больше реальности.
Даже в идеальном мире есть фундаментальные силы природы
Сила тяжести вызывает ускорение в направлении действия силы тяжести, которое мы называем гравитационным ускорением. Это ускорение является уникальным, поскольку оно присутствует всегда и в рамках настоящей главы мы считаем его постоянным и равным 9,8 м/сек2.
Предположим, что смартфон лежит на столе экраном вверх. В этой ориентации, наша система координат такова, что отрицательное направление по оси z является именно тем, в котором действует сила тяжести. Гравитация будет тянуть наш телефон в отрицательном направлении оси z, так что наш акселерометром, даже когда он совершенно неподвижен, будет записывать ускорение 9,8 м/сек2 по оси z в отрицательном направлении. Данные акселерометра, поступающие с нашего телефона в этой ориентации, показаны на рис.16.3.
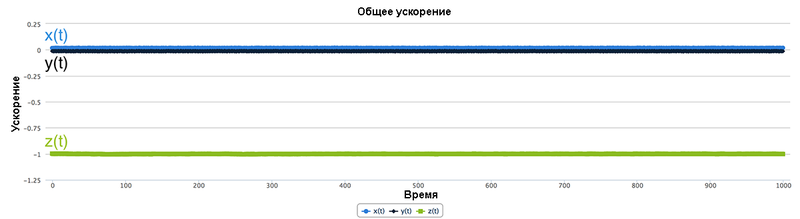
Рис.16.3. Пример данных акселерометра в состоянии покоя
Заметьте, что x(t) и y(t) остаются константами со значением 0, а z(t) константой, равной -1 g. Наш акселерометр записывает все значения ускорения, в том числе и гравитационное ускорение.
В каждом временном ряду измеряется общее ускорение для конкретной ориентации. Общее ускорение является суммой ускорения пользователя и гравитационного ускорения.
Ускорением пользователя является ускорением устройства из-за движения пользователя и равно константе 0 в случае, когда телефон недвижим. Тем не менее, когда пользователь перемещается с устройством, ускорение пользователя редко бывает постоянным, поскольку человека трудно двигаться с постоянным ускорением.
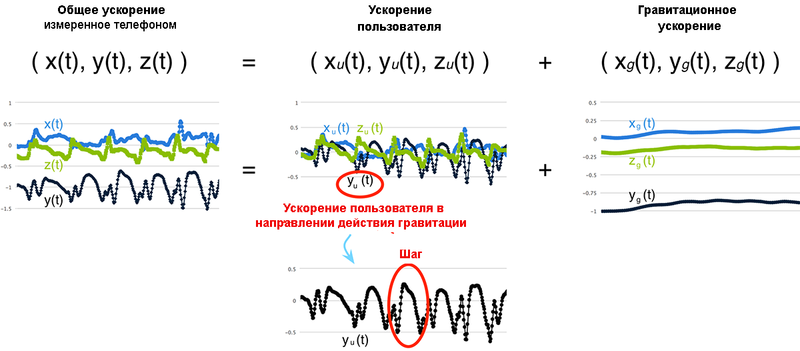
Рис.16.4. Составляющие сигналов
Чтобы подсчитать шаги, нам нужно знать о перемещения, осуществляемых пользователем в направлении действия силы тяжести. Это означает, что нам в трехмерном сигнале ускорения интересен одномерный временной ряд, который описывает ускорение пользователя в направлении действия силы тяжести (рис.16.4).
В нашем простом примере, гравитационное ускорение равно 0 для составляющих x(t) и z(t) и равно константе 9,8 м/сек2 для компоненты y(t). Поэтому на нашем графике общего ускорения флуктуация значений x(t) и z(t) происходит около 0, а значения y(t) около -1 g. На нашем ускорения пользователя мы замечаем, что поскольку мы удалили гравитационное ускорение, все три временных ряда колеблются около 0. Обратим внимание на очевидные пики yu(t). Они связаны отскоками при каждом шаге! На нашем последнем графике гравитационное ускорение yg(t) постоянно и равно -1 g, а xg(t) и zg(t) являются постоянными, равными 0.
Итак, в нашем примере, 1-мерное ускорение пользователя, фиксируемое по направлению действия гравитации и которое нам интересно, будет yu(t). Хотя yu(t) выглядит не столь гладко, как наша идеальная синусоида, мы можем идентифицировать пики, и использовать эти пики для подсчета шагов. Все пока идет нормально. Теперь, давайте добавим в наш мир еще больше реальности.
Люди - сложные существа
А что делать, если человек носит телефон в сумке на плече, и телефон будет находиться в еще более неустойчивом состоянии? И, что еще хуже, а если телефон переворачивается во время прогулки так, как это показано на рис.16.5?
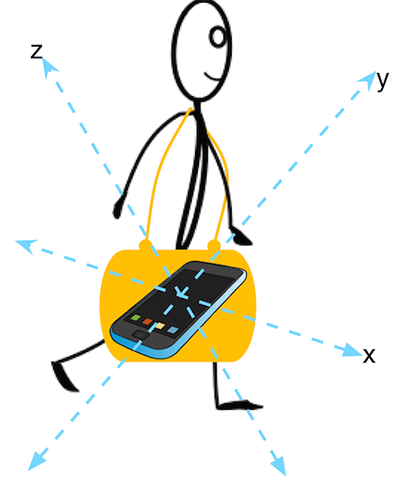
Рис.16.5. Более сложный вариант движения
Интересно. Теперь все три наших компонента имеют ненулевое гравитационное ускорение, поэтому ускорение пользователя в направлении действия силы тяжести теперь распределено по всем трем временным рядам. Для того, чтобы определить ускорение пользователя в направлении действия силы тяжести, мы сначала должны определить, в каком направлении эта сила тяжести действует. Чтобы сделать это, мы должны разбить общее ускорение в каждом из трех временных рядов на временные ряды ускорения пользователя и временные ряды гравитационного ускорения (рис.16.6).

Рис.16.6. Более сложные компоненты сигналов
Тогда можно в каждом компоненте выделить ту часть ускорения пользователя, которая действует в направлении действия силы тяжести, и мы получим только ускорение пользователя.
Давайте ниже мы сформулируем это в виде двух отдельных этапов:
- Разделяем полное ускорение на ускорение пользователя и гравитационное ускорение.
- Выделяем ускорение пользователя, которое действует в направлении действия силы тяжести.
Мы рассмотрим каждый из этих этапов по-отдельности.
1. Разделяем полное ускорение на ускорение пользователя и гравитационное ускорение
Для того, чтобы разделить временной ряд общего ускорения, на временной ряд ускорения пользователя и временной ряд гравитационного ускорения, мы можем использовать инструмент, который называется фильтром (filter).
Низкочастотный и высокочастотный фильтры
Фильтр представляет собой инструмент, используемый при обработке сигналов для того, чтобы из сигнала удалять нежелательные компоненты.
Фильтр низких частот или низкочастотный фильтр (low-pass filter) пропускает через себя низкочастотные сигналы через, а сигналы, которые выше установленного порога, ослабляет. И наоборот, фильтр верхних частот или высокочастотный фильтр (high-pass filter) позволяет проходить высокочастотным сигналам и ослабляет сигналы, которые ниже установленного порога. Если в качестве аналогии перейти к музыке, то низкочастотный фильтр может устранить высокие ноты, а фильтр верхних частот может устранить басы.
В нашем случае, частота, измеряемая в герцах, указывает на то, как быстро из меняется ускорение. Постоянное ускорение имеет частоту в 0 Гц, а при изменении ускорения частота будет ненулевой. Это означает, что наше постоянное гравитационное ускорение равно сигналу с частотой в 0 Гц, а ускорение пользователь таковым не является.
Для каждого компонента, мы можем пропустить временной ряд общего ускорения через низкочастотный фильтр, и у нас останется только временной ряд гравитационного ускорения. Затем мы можем вычесть гравитационное ускорение из общего ускорения, и у нас будут временные ряды ускорения пользователя (рис.16.7).
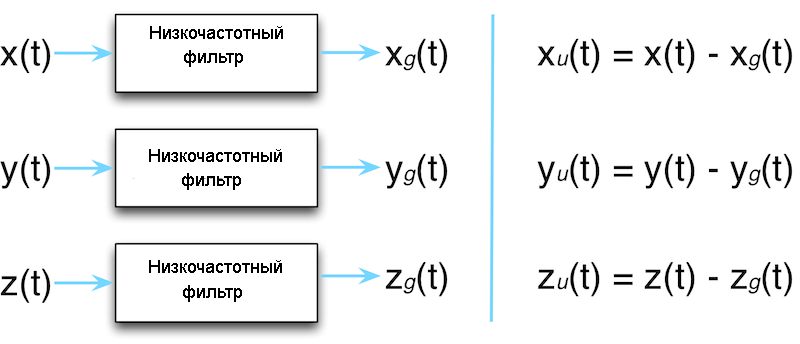
Рис.16.7. Низкочастотный фильтр
Существуют многочисленные разновидности фильтров. Тот, который мы будем пользоваться, называется фильтром с бесконечной импульсной характеристикой (an infinite impulse response filter - IIR). Мы выбрали фильтр IIR из-за его низких накладных расходов и простоты его реализации. Фильтр IIR, который мы выбрали, реализован согласно следующей формулы:
outputi=α0(inputiβ0+inputi−1β1+inputi−2β2−outputi−1α1−outputi−2α2)
Разработка и создание цифровых фильтров выходит за рамки данной главы, однако здесь имеет смысл привести очень короткое пояснение. Это хорошо изученная, увлекательная тема, с многочисленными практическими приложениями. Можно разработать цифровой фильтр, который будет удалять любую частоту или диапазон заданных частот. Значения α и β, указанные в формуле, являются коэффициентами, с помощью устанавливается частота среза фильтра и диапазон частот, которые мы хотим сохранить.
Мы хотим удалить все частоты за исключением частот нашего постоянного гравитационного ускорения и поэтому мы выбрали коэффициенты, которые ослабляют частоты выше 0,2 Гц. Обратите внимание на то, что мы установили наш порог немного выше 0 Гц. Хотя сила тяжести в действительности создает реальное ускорение, равное 0 Гц, в нашем реальном несовершенном мире используются реальные несовершенные акселерометры и, поэтому, мы оставляем возможность небольшой погрешности в измерениях.
Реализация фильтра низких частот
Давайте для нашего предыдущего примера реализуем фильтр нижних частот, используя. Мы будем выделять:
- x(t) из xg(t) и xu(t),
- y(t) из yg(t) и yu(t), а также
- z(t) из zg(t) и zu(t).
Мы проинициализируем первые два значения гравитационного ускорения значением 0, поэтому формула с заданными начальными значениями будет выглядеть следующим образом.
xg(0)=xg(1)=yg(0)=yg(1)=zg(0)=zg(1)=0
Тогда мы для каждого временного ряда реализуем формулу фильтра.
xg(t)=α0(x(t)β0+x(t−1)β1+x(t−2)β2−xg(t−1)α1−xg(t−2)α2) yg(t)=α0(y(t)β0+y(t−1)β1+y(t−2)β2−yg(t−1)α1−yg(t−2)α2) zg(t)=α0(z(t)β0+z(t−1)β1+z(t−2)β2−zg(t−1)α1−zg(t−2)α2)
Результирующие временные ряды после фильтрации нижних частот показаны на рис.16.8.
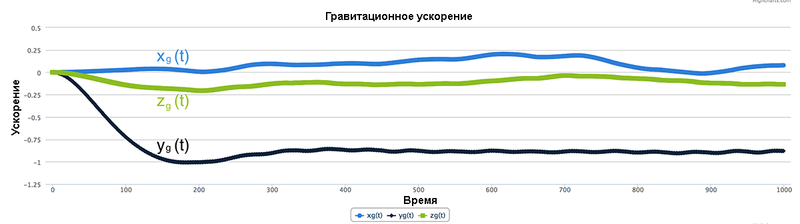
Рис.16.8. Гравитационное ускорение
Значения xg(t) и zg(t) колеблются около 0, а значение yg(t) очень быстро снижается до −1g. Начальное значение 0 для yg(t) задано при инициализации формулы.
Теперь для того, чтобы вычислить ускорение пользователя, мы можем вычесть гравитационное ускорение из нашего общего ускорения:
xu(t)=x(t)−xg(t) yu(t)=y(t)−yg(t) zu(t)=z(t)−zg(t)
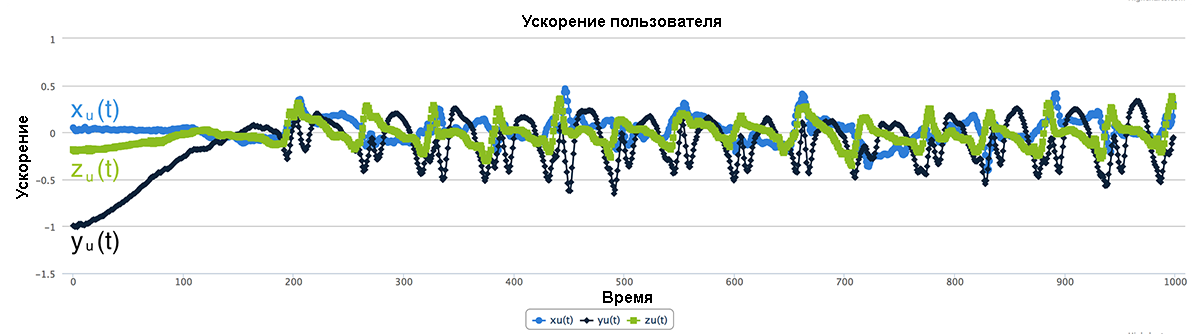
Рис.16.9. Разделение ускорения (увеличить)
2. Выделяем ускорение пользователя, действующее в направлении действия силы тяжести
Движения пользователя присутствуют во всех компонентах xu(t), yu(t) и zu(t), а не только в движениях в направлении действия силы тяжести. Здесь наша цель заключается в переходе к 1-мерному временному ряду, представляющего ускорение пользователя в направлении действия силы тяжести. Этот ряд будет включать в себя части ускорения пользователя в каждом из направлений.
Давайте перейдем к достижению этой цели. Во-первых, немного основ линейной алгебры. До настоящей математики еще далеко!
Cкалярное произведение векторов
При работе с координатами вы не продвинетесь слишком далеко, если не обратитесь к скалярному произведению векторов (dot product) — одному из основных инструментов, используемых при сравнении величины и направления координат x, y и z.
Скалярное произведение переносит нас из 3-мерного пространства в 1-мерное пространство (рис.16.10). Когда мы получаем скалярное произведение от двух временных рядов, ускорения пользователя и ускорения силы тяжести, оба из которых представлены в 3-мерном пространстве, у нас останемся один временной ряд в 1-мерном пространстве, представляющей собой часть ускорения пользователя, действующей в направлении действия силы тяжести. Мы условно назовем этот новый временной ряд как a(t), т. к. все важные временные ряды заслуживают иметь собственное имя.

Рис.16.10. Cкалярное произведение векторов
Реализация скалярного произведения
Мы можем реализовать скалярное произведение для нашего предыдущего примера при помощи формулы a(t)=xu(t)xg(t)+yu(t)yg(t)+zu(t)zg(t), которая даст нам значение a(t) в 1-мерном пространстве (рис.16.11).
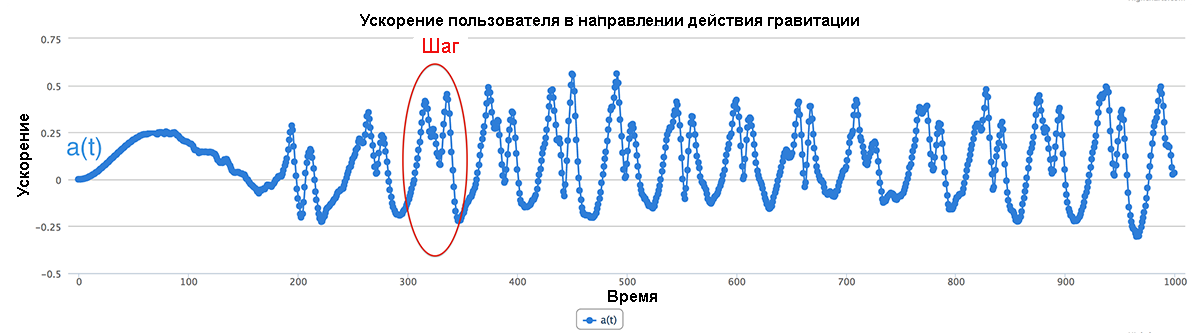
Рис.16.11. Реализация скалярного произведения векторов (увеличить)
Теперь мы можем визуально определить отдельные шаги в a(t). Скалярное произведение является очень мощным, но одновременно достаточно простым и красивым инструментом.
Решения для реального мира
Мы видели, как наша, казалось бы, простая задача, быстро стала более сложной, когда мы окунулись в проблемы реального мира и реальных людей. Тем не менее, мы гораздо ближе приблизились к подсчету шагов и видим, что a(t) начинает все больше напоминать нашу идеальную синусоиду. Но, только "своеобразную, своего сорта" синусоиду. Нам все еще нужно сделать наш замусоренный временной ряд a(t) более гладким. У временного ряда a(t) в его текущем состоянии имеется четыре основные проблемы (рис.16.12). Давайте рассмотрим каждуюиз них.
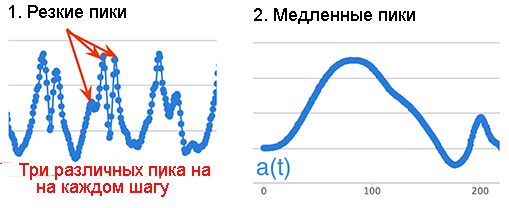
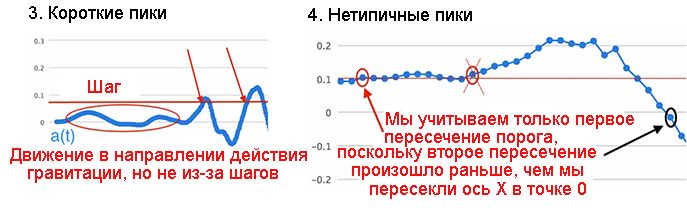
Рис.16.12. Резкие скачки, медленное изменение, короткие участки, неровности
1. Резкие пики
Временной ряд a(t) очень "нервный", поскольку как телефон с каждым шагом может покачиваться и добавляет к нашему временному ряду высокочастотную составляющую. Это нервозность называется шумом. Изучив многочисленные наборы данных, мы пришли к выводу, что ускорение при каждом шаге может иметь максимальную частоту, равною 5 Гц. Для того, чтобы удалить шум, мы можем использовать фильтр нижних частот IIR, выбирая значения α и β так, чтобы ослабить все сигналы, частота которых выше 5 Гц.
2. Медленные пики
При частоте дискретизации 100, медленный пик, отображаемый в a(t), длится 1,5 секунды, что слишком медленно, чтобы быть шагом. При изучении достаточного количества образцов данных мы пришли к выводу, что самый длительный шаг, который мы можем сделать, соответствует частоте 1 Гц. Медленные ускорения, которые обусловлены низкочастотной составляющей, мы можем опять же удалить с помощью фильтра верхних частот IIR, установив значения α и β так, чтобы убрать все сигналы ниже 1 Гц.
3. Короткие пики
Когда человек пользуется приложением или звонит по телефону, акселерометр регистрирует небольшие движения в направлении действия силы тяжести, отражая их в наших временных рядах в виде коротких пиков. Мы можем устранить эти кратковременные пики, установив минимальный порог и считая шаги только тогда, когда значение a(t) превысит этот порог в положительном направлении.
4. Неровные пики
Наш шагомер должен подходить для многих людей и различных вариантов прогулок, поэтому мы устанавливали минимальные и максимальные частоты шагов после того, как проанализировали выборки данных для большого количества людей и для многих вариантов прогулок. Это означает, что иногда мы можем отфильтровывать данных чуть больше или чуть меньше, чем надо. Хотя, в основном, у нас будут достаточно сглаженные пики, мы можем иногда получать пики с "ухабами". На рис.16.12 показано увеличенного изображение одного такого пика.
Когда такая болтанка происходит возле порога срабатывания, мы при анализе единственного пика добавить слишком много шагов. Для решения этой проблемы мы будем использовать метод, называемый гистерезис. Гистерезис представляет собой зависимость выходных данных от прошлых входных данных. Мы можем посчитывать пересечение порога в положительном направлении и пересечение нулевого значения в отрицательном направлении. Т.е. мы подсчитываем только шаги, когда пересечение порога происходит после пересечения нулевого значения, и, тем самым, мы обеспечиваем, что каждый подсчитывается только один раз.
Пики, которые самые правильные

Рис.16.13. Преобразованные пики
С учетом этих четырех сценариев мы сумели привести наш зашумленный временной ряд a(t) достаточно близко к нашей идеальной синусоиде (рис.16.13), которая позволяет нам считать шаги.
Резюме
Проблема, на первый взгляд, выглядела просто. Тем не менее, реальный мир и реальные люди стали причиной нескольких проблем на нашем пути. Давайте подведем итоги решения этих проблем:
- Мы начали с рассмотрения общего ускорения (x(t),y(t),z(t)).
- Мы использовали фильтр низких часто для того, чтобы разделить общее ускорение на ускорении пользователя и гравитационное ускорение, (xu(t),yu(t),zu(t)) и (xg(t),yg(t),zg(t)), соответственно.
- Мы использовали скалярное произведение (xu(t),yu(t),zu(t)) и (xg(t),yg(t),zg(t)) для того, чтобы получить составляющую ускорения пользователя a(t), действующую в направлении действия силы тяжести.
- Мы снова использовали фильтр низких частот для того, чтобы удалить высокочастотную составляющую из a(t), т. е. удалили шум.
- Мы использовали фильтр верхних частот, чтобы удалить низкочастотную составляющую из a(t), т. е. удалили медленные пики.
- Мы установили порог для того, чтобы игнорировать короткие пики.
- Мы использовали гистерезис для того, чтобы избежать шагов двойного подсчета шагом в случае неровных пиков.
Если бы мы, как разработчики программного обеспечения, обучались на курсах или работали в академической среде, то нам бы могли дать идеальные данные и попросили написать код для подсчета шагов по этим данным. Несмотря на то, что, возможно, это не было бы то, что мы могли бы применить в реальной ситуации. Мы видели, что в действительности, когда движение человека смешивается с действием силы тяжести, проблема становится немного более сложным. Мы воспользовались математическими инструментами для решения возникшей сложности и сумели решить реальные проблемы. Пришло время перевести наше решение в код.
Погрузимся в код
Наша цель в этой главе заключается в том, чтобы создать веб-приложение на языке Ruby, которое принимает данные акселерометра, анализирует их структуру, обрабатывает данные и оценивает полученный результат и возвращает значения количества пройденных шагов, пройденного расстояния и потраченного на это время.
Предварительная работа
Наше решение требует, чтобы мы отфильтровывали временные ряды несколько раз. Вместо того, чтобы разбрасывать код, осуществляющий фильтрацию, по всей нашей программе, имеет смысл создать класс, который будет осуществлять фильтрацию, и если нам когда-нибудь понадобится его улучшить или изменить, то все, что нам потребуется изменить, будет один класс. Эта стратегия называется разделение задач (separation of concerns), принцип, широко используемый при проектировании, который помогает разбивать программы на отдельные части, где каждая часть имеет одно главное назначение. Это отличный прием, позволяющий писать чистый поддерживаемый код, который можно будет легко расширять. На протяжении всей главы мы будем возвращаться к этому принципу несколько раз.
Давайте перейдем к коду фильтрации, который находится, что логично, в классе Filter.
class Filter
COEFFICIENTS_LOW_0_HZ = {
alpha: [1, -1.979133761292768, 0.979521463540373],
beta: [0.000086384997973502, 0.000172769995947004, 0.000086384997973502]
}
COEFFICIENTS_LOW_5_HZ = {
alpha: [1, -1.80898117793047, 0.827224480562408],
beta: [0.095465967120306, -0.172688631608676, 0.095465967120306]
}
COEFFICIENTS_HIGH_1_HZ = {
alpha: [1, -1.905384612118461, 0.910092542787947],
beta: [0.953986986993339, -1.907503180919730, 0.953986986993339]
}
def self.low_0_hz(data)
filter(data, COEFFICIENTS_LOW_0_HZ)
end
def self.low_5_hz(data)
filter(data, COEFFICIENTS_LOW_5_HZ)
end
def self.high_1_hz(data)
filter(data, COEFFICIENTS_HIGH_1_HZ)
end
private
def self.filter(data, coefficients)
filtered_data = [0,0]
(2..data.length-1).each do |i|
filtered_data << coefficients[:alpha][0] *
(data[i] * coefficients[:beta][0] +
data[i-1] * coefficients[:beta][1] +
data[i-2] * coefficients[:beta][2] -
filtered_data[i-1] * coefficients[:alpha][1] -
filtered_data[i-2] * coefficients[:alpha][2])
end
filtered_data
end
end
В любое время, когда в нашей программе нужно будет фильтровать временные ряды, мы можем вызвать один из методов класса Filter вместе с данными, которые нам нужно будет фильтровать:
- фильтр
low_0_hzиспользуется для фильтрации сигналов с помощью фильтра низких частот с порогом возле 0 Гц - фильтр
low_5_hzиспользуется для фильтрации сигналов с помощью фильтра низких частот с порогом ниже 5 Гц - фильтр
high_1_hzиспользуется для фильтрации сигналов с помощью фильтра высоких частот с порогом выше 1 Гц
Каждый метод класса вызывает фильтр filter, в котором реализован фильтр IIR, и возвращает результат. Если мы в будущем захотим добавить больше фильтров, то нам потребуется изменить только этот один класс. Обратите внимание, что все магические числа определяются в самом начале кода. Это облегчает чтение и понимание кода нашего класса.
Форматы ввода
Наши входные данные поступают с мобильных устройств, таких как телефоны с системой Android и айфоны. У большинства мобильных телефонов, имеющихся сегодня на рынке, есть встроенные акселерометры, которые способны записывать общее ускорение. Давайте назовем формат входных данных, в котором записывается полное ускорение, форматом объединенных данных. Многие, но не все устройства могут также по отдельности записывать ускорение пользователя и ускорение силы тяжести. Давайте назовем этот формат форматом раздельных данных. Устройство, которое имеет возможность возвращать данные в формате раздельных данных, обязательно должно имеет возможность возвращать данные в формате объединенных данных. Но обратное не всегда верно. Некоторые устройства могут записывать данные только в объединенном формате. Входные данные в объединенном формате нужно будет пропустить через низкочастотный фильтр для того, чтобы превратить их в данных в раздельном формате.
Мы хотим, чтобы наша программа подходила для работы со всеми мобильными устройствами с акселерометров, имеющимися на рынке, так что мы должны принимать данные в обоих форматах. Давайте рассмотрим эти два формата, которые мы будем принимать по отдельности.
Формат объединенных данных
Данные в объединенном формате являются данными о полном ускорении, действующем по направлениям осей x, y и z в течение продолжительного времени. Значения x, y и z разделены запятой, и выборка за одну единицу времени отделяется от других выборок точкой с запятой.
x1,y1,z1;…xn,yn,zn;
Формат разделенных данных
Формат разделенных данных возвращает ускорение пользователя и гравитационное ускорение, действующие в направлении осей x, y и z в течение длительного времени. Значения ускорения пользователя отделяются от значений гравитационного ускорения с помощью символа вертикального отрезка.
xu1,yu1,zu1|xg1,yg1,zg1;…xun,yun,zun|xgn,ygn,zgn;
Есть несколько форматов данных, но нет стандартного формата
Работа с различными форматами ввода является обычной проблемой программирования. Если мы хотим, чтобы вся наша программа работала с обоими форматами, каждый фрагмент кода, который работает с данными, должен знать, как обрабатывать оба формата. Такой код может очень быстро стать непонятным особенно, если добавляется третий (или четвертый, или пятый, или сотый) формат ввода.
Стандартный формат
Самый правильный способ с этим нам справиться - взять наши оба формата и как можно быстрее преобразовать их в стандартный формат с тем, чтобы оставшаяся часть программы работала с этим новым стандартным форматом. Наше решение требует, чтобы мы работали с ускорением пользователя и гравитационным ускорением по отдельности, так что наш стандартный формат данных потребуется разделить на два ускорения (рис.16.14).

Рис.16.14. Стандартный формат
Наш стандартный формат позволяет хранить временные ряды, поскольку каждый элемент данных представляет собой ускорение в определенный момент времени. Мы определяем формат как массив массивов из массивов (прим.пер. - тройная вложенность массивов). Давайте заглянем внутрь.
- Первый массив является просто оболочкой для хранения всех данные.
- Второй набор массивов содержит один массив для каждой полученной выборки данных. Если наша частота дискретизации равна 100 и мы выбираем данные в течение 10 секунд, то у нас в этом втором множестве массивов будет 100 * 10 или 1000 массивов.
- Третий набор массивов является парой массивов, вложенных во второй набор массивов. В обоих хранятся данные об ускорении, действующей в направлениях осей x, y и z; первое, представляющее ускорение пользователя, а второе — гравитационное ускорение.
Конвейер
На вход в нашу систему будут поступать данные из акселерометра, информация о прогуливающемся пользователе (пол, шага и т.д.), а также информация о самом процессе ходьбы (частота дискретизации, фактически сделанные шаги, и т.д.). Наша система будет обрабатывать входящие сигналы и будет выдавать рассчитанное количество шагов, разницу между фактическим и рассчитанным количеством шагов, пройденное расстояние, и прошедшее время. Весь процесс от входа до выхода можно рассматривать в виде конвейера (рис.16.15).
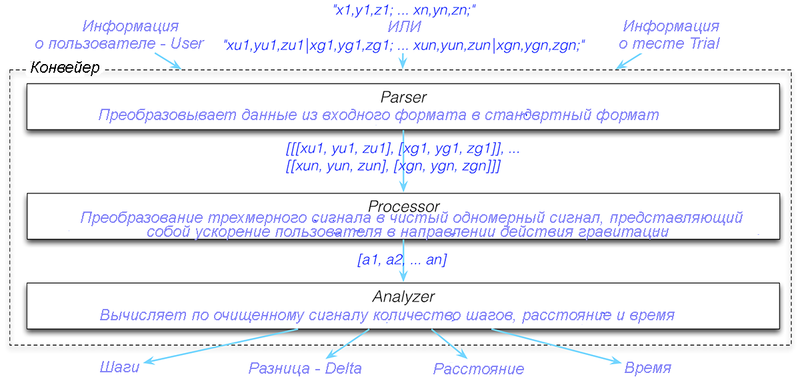
Рис.16.15. Конвейер
Исходя из стиля разделения проблем, мы будем писать код по отдельности для каждого отдельно взятого компонента конвейера — для анализатора структуры, для блока обработки данных и блока анализа данных.
Анализ структуры
Учитывая, что мы хотим, чтобы наши данные были в стандартном формате, как можно раньше, имеет смысл в качестве первого компонента нашего конвейера написать анализатор, который позволил бы нам взять два наших известных входных формата и конвертировать их в стандартный выходной формат. Наш стандартный формат разделяется на ускорение пользователя и гравитационное ускорение, а это значит, что если наши данные в объединенном формате, наш анализатор должен будет сначала пропустить их через низкочастотный фильтр для того, чтобы преобразовать их в стандартный формат.
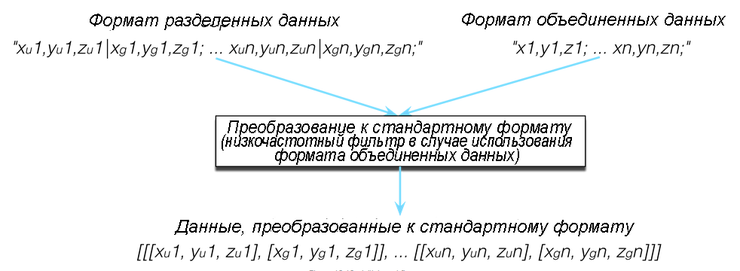
Рис.16.16. Исходный поток управления
В будущем, если мы когда-нибудь придется добавить еще один формат ввода, единственный код, который нам для этого придется изменить, это будет этот анализатор. Давайте еще раз поделим проблемы и создадим класс Parser, который будет выполнять синтаксический анализ входных данных.
class Parser
attr_reader :parsed_data
def self.run(data)
parser = Parser.new(data)
parser.parse
parser
end
def initialize(data)
@data = data
end
def parse
@parsed_data = @data.to_s.split(';').map { |x| x.split('|') }
.map { |x| x.map { |x| x.split(',').map(&:to_f) } }
unless @parsed_data.map { |x| x.map(&:length).uniq }.uniq == [[3]]
raise 'Bad Input. Ensure data is properly formatted.'
end
if @parsed_data.first.count == 1
filtered_accl = @parsed_data.map(&:flatten).transpose.map do |total_accl|
grav = Filter.low_0_hz(total_accl)
user = total_accl.zip(grav).map { |a, b| a - b }
[user, grav]
end
@parsed_data = @parsed_data.length.times.map do |i|
user = filtered_accl.map(&:first).map { |elem| elem[i] }
grav = filtered_accl.map(&:last).map { |elem| elem[i] }
[user, grav]
end
end
end
end
В классе Parser есть метод запуска run и а также код инициализации. Этот шаблон мы будем использовать несколько раз, так что его стоит обсудить. Инициализацию, как правило, следует использовать для создания объекта, и это код не должен делать слишком много работы. Код инициализации класса Parser просто принимает данные в объединенном или разделенном формате и сохраняет их в переменной экземпляра @data. Метод экземпляра parse использует переменную @data внутри экземпляра и выполняет всю тяжелую работу по анализу данных и созданию результата в стандартном формате в переменной @parsed_data. В нашем случае, мы никогда не должны создавать экземпляр класса Parser без необходимости немедленно вызова метода parse. Поэтому мы в класс добавим удобный метод run, который создает экземпляр класса Parser, вызовет в нем метод parse и возвратит экземпляр объекта. Теперь мы, зная что экземпляр объекта Parser с переменной @parsed_data уже подготовлены, можем передать наши входные данные в метод run.
Давайте посмотрим на наш метод parse , выполняющий сложную работу. Первым шагом в этом процессе — взять строковые данные и преобразовать их в числовые данные, что дает нам массивы данных с тремя уровнями вложенности. Звучит знакомо? Следующее, что мы делаем, это убеждаемся, что формат именно такой, как и ожидалось. Если у нас в внутреннем массиве нет ровно три элементов, то мы сгенерируем исключение. В противном случае, мы продолжим.
Обратите на данном этапе внимание на различие двух форматов данных в переменной @parsed_data. В объединенном формате в ней будет храниться ровно один массив:
[[[x1,y1,z1]],…[[xn,yn,zn]]
В раздельном формате в ней будет ровно два массива:
[[[x1u,y1u,z1u],[x1g,y1g,z1g]],...[[xnu,ynu,znu],[xng,yng,zng]]]
Желательно, чтобы после этой операции раздельный формат сразу стал нашим стандартным форматом. Удивительно. Однако, если данные объединяются (или, что тоже самое, имеют ровно один массив, когда раздельный формат будет иметь два массива), то обработка выполняется с помощью двух циклов. Первый цикл разделяет общее ускорение на гравитационное ускорение и ускорение пользователя, для этого используется фильтр Filter с порогом :low_0_hz, а второй цикл преобразует данные в стандартный формат.
Независимо от того, были ли у нас вначале данные в объединенном или разделенном формате, метод parse возвращает нам переменную @parsed_data, в которой данные находятся в стандартном формате. Стало гораздо легче!
Поскольку наша программа становится все более сложной, есть возможность ее улучшить и, чтобы сделать жизнь наших пользователей проще, выдавать исключения с конкретными сообщениями об ошибках. Это позволит им более оперативно отслеживать обычные проблемы, касающиеся формата вводимых данных.
Дальнейшая обработка данных
С учетом решения, которое мы выбрали, нам понадобится, чтобы прежде, чем мы сможем считать шаги, наш код сделал пару вещей с проанализированными нами данными:
- С помощью скалярного произведения изолировать движение в направлении действия силы тяжести.
- Удалить резкие (высокочастотные) и медленные (низкочастотные) пики с помощью фильтра нижних частот с последующим применением фильтра высоких частот.
Мы обработаем короткие и резкие пики с тем, чтобы они не мешали при подсчете шагов.
Теперь, когда у нас есть наши данные в стандартном формате, мы можем их обработать так, чтобы перейти их в состоянии, в котором мы можем их проанализировать и подсчитать шаги (рис.16.17).
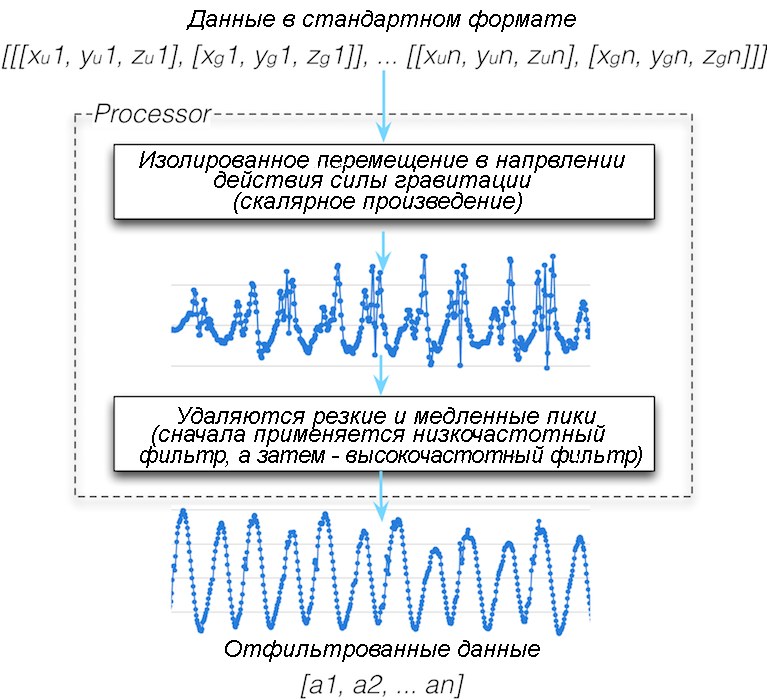
Рис.16.17. Обработка данных
Цель обработки — взять наши данные в стандартном формате и постепенно очищать их чтобы перевести их в состояние, которое как можно ближе к нашей идеальной синусоиде. Наши две операции обработки, скалярное произведение и фильтрация, совершенно различны, но обе предназначены для обработки наших данных, поэтому мы создадим один класс, который будет называться Processor.
class Processor
attr_reader :dot_product_data, :filtered_data
def self.run(data)
processor = Processor.new(data)
processor.dot_product
processor.filter
processor
end
def initialize(data)
@data = data
end
def dot_product
@dot_product_data = @data.map do |x|
x[0][0] * x[1][0] + x[0][1] * x[1][1] + x[0][2] * x[1][2]
end
end
def filter
@filtered_data = Filter.low_5_hz(@dot_product_data)
@filtered_data = Filter.high_1_hz(@filtered_data)
end
end
Опять же, мы видим паттерн методов run и initialize. Метод run непосредственно вызывает наши два метода dot_product и filter. Каждый метод выполняет одну из наших двух операций обработки. Метод dot_product изолирует движение в направлении действия силы тяжести, а метод filter применяет последовательно фильтр нижних частот и верхних частот фильтров с тем, чтобы удалить резкие и медленные пики.
Функциональные возможности шагомера
В случае, если имеются сведения о лице, которое пользуется шагомером, мы можем измерить больше, чем просто шаги. Наш шагомер измеряет пройденное расстояние и затраченное время, ну и, конечно, количество шагов.
Пройденное расстояние
Мобильный шагомером обычно пользуется один человек. Расстояние, пройденное во время прогулки, рассчитывается путем умножения количества шагов на длину шага человека. Если длина шага неизвестна, то мы можем воспользоваться дополнительной информацией о пользователе, например, о его поле и приблизительном его росте. Давайте создадим класс User, в котором будет инкапсулирована такая информация.
class User
GENDER = ['male', 'female']
MULTIPLIERS = {'female' => 0.413, 'male' => 0.415}
AVERAGES = {'female' => 70.0, 'male' => 78.0}
attr_reader :gender, :height, :stride
def initialize(gender = nil, height = nil, stride = nil)
@gender = gender.to_s.downcase unless gender.to_s.empty?
@height = Float(height) unless height.to_s.empty?
@stride = Float(stride) unless stride.to_s.empty?
raise 'Invalid gender' if @gender && !GENDER.include?(@gender)
raise 'Invalid height' if @height && (@height <= 0)
raise 'Invalid stride' if @stride && (@stride <= 0)
@stride ||= calculate_stride
end
private
def calculate_stride
if gender && height
MULTIPLIERS[@gender] * height
elsif height
height * (MULTIPLIERS.values.reduce(:+) / MULTIPLIERS.size)
elsif gender
AVERAGES[gender]
else
AVERAGES.values.reduce(:+) / AVERAGES.size
end
end
end
В верхней части нашего класса, мы определяем константы с тем, чтобы повсюду в коде жестко не записывать эти магические цифры и строки. Для целей данной дискуссии давайте предположим, что значения для MULTIPLIERS и AVERAGES были определены по выборке большого размера, учитывающей различных людей.
Наш код инициализации в качестве дополнительных аргументов получает значения gender (пол), height (рост) и stride (размер шага). Если в код инициализации переданы эти дополнительные параметры, то они будут запомнены в соответствующих переменных. Для недопустимых значений будут выданы исключения.
Даже тогда, когда представлены все необязательные параметры, параметр stride (размер шага) будет иметь преимущество. Если всех данных нет, то с помощью метода calculate_stride (вычислить шаг) определяется наиболее точная возможная длина шага пользователя. Это делается с помощью инструкций if:
- Наиболее точный способ расчета длины шага – использовать рост человека и множителя, зависящего от пола, при условии, что у нас есть правильные значения пола и роста.
- Высота человека является лучшим показателем для вычисления шага, чем множитель, зависящий от пола. Если у нас есть значение роста, но нет значения пола, мы можем умножить рост на среднее из двух значений, указанных в MULTIPLIERS.
- Если все, что у нас есть, это значение пола, мы можем использовать среднюю длину шага, которая есть в переменной AVERAGES.
- Наконец, если у нас нет ничего, мы можем взять среднее из двух значений из переменной AVERAGES и использовать его в качестве значения нашего шага.
Обратите внимание, что чем ниже мы двигаемся по этому списку, тем менее точным становится значение длины шага. В любом случае в нашем классе User длина шага определяется как можно точнее.
Затраченное время
Время, затраченное на прогулку, измеряется путем деления количества данных в @parsed_data в Processor на частоту дискретизации вашего устройства, если вам она известна. Поскольку частота дискретизации связана больше с самой прогулкой, чем с пользователем, и класс User, на самом деле, не должен быть осведомлен о частоте дискретизации, так что наступило время, чтобы создать очень небольшой класс Trial (тест):
class Trial
attr_reader :name, :rate, :steps
def initialize(name, rate = nil, steps = nil)
@name = name.to_s.delete(' ')
@rate = Integer(rate.to_s) unless rate.to_s.empty?
@steps = Integer(steps.to_s) unless steps.to_s.empty?
raise 'Invalid name' if @name.empty?
raise 'Invalid rate' if @rate && (@rate <= 0)
raise 'Invalid steps' if @steps && (@steps < 0)
end
end
Все атрибуты, которые читаются в классе Trial, указываются в инициализационной части с помощью следующих параметров:
name— имени конкретного теста, которое помогает нам отличать друг от друга различные тестыrateявляется частотой дискретизации акселерометра во время тестаstepsиспользуется для задания числа фактически сделанных шагов, так что мы можем записать разницу между фактически сделанными шагами, которые указал пользователь, и теми, которые подсчитала наша программа.
Так же, как и в нашем классе User, некоторая информация не является обязательной. У нас есть возможность ввода данных о тесте в случае, если они у нас есть. Если у нас нет этих данных, программа не будет вычислять дополнительные результаты, например, время путешествия. Еще одно сходство с нашим классом User состоит в защите от недопустимых значений.
Количество шагов
Пришло время реализовать с помощью кода нашу стратегию подсчета шагов. Итак, у нас есть класс Processor, содержащий отфильтрованные данные @filtered_data, которые являются нашим очищенным временным рядом, представляющем ускорение пользователя в направлении действия силы тяжести. У нас также есть классы, которые дают нам всю необходимую информацию о пользователе и тесте. То, что мы пропустили, это то, как проанализировать @filtered_data с использованием информации из классов User и Trial и подсчитать количество шагов, измерить пройденное расстояние и измерить затраченное время.
Часть нашей программы, выполняющая анализ, отличается от манипуляции с данными в Processor, и отличается от сбора и агрегирования информации в классах User и Trial. Давайте создадим новый класс Analyzer чтобы в нем выполнять анализ данных.
class Analyzer
THRESHOLD = 0.09
attr_reader :steps, :delta, :distance, :time
def self.run(data, user, trial)
analyzer = Analyzer.new(data, user, trial)
analyzer.measure_steps
analyzer.measure_delta
analyzer.measure_distance
analyzer.measure_time
analyzer
end
def initialize(data, user, trial)
@data = data
@user = user
@trial = trial
end
def measure_steps
@steps = 0
count_steps = true
@data.each_with_index do |data, i|
if (data >= THRESHOLD) && (@data[i-1] < THRESHOLD)
next unless count_steps
@steps += 1
count_steps = false
end
count_steps = true if (data < 0) && (@data[i-1] >= 0)
end
end
def measure_delta
@delta = @steps - @trial.steps if @trial.steps
end
def measure_distance
@distance = @user.stride * @steps
end
def measure_time
@time = @data.count/@trial.rate if @trial.rate
end
end
Первое, что мы делаем в коде Analyzer, это определяем константу THRESHOLD (порог), которую мы будем использовать для того, чтобы избежать подсчета в качестве шагов кратковременных пиков. Для наших обсуждений давайте предположим, что мы проанализировали множество наборов разнообразных данных и определили пороговое значение, которое подошло для наибольшего количества этих наборов данных. Порог может, в конце концов, быть динамическим и изменяться для различных пользователей в зависимости от результата сравнения вычисленного количества шагов и фактического количества шагов, которое они сделали; алгоритм обучения, если хотите.
Наш код инициализации из Analyzer берет параметр data и экземпляры классов User и Trial, и устанавливает значения для переменных экземпляров @data, @user и @trial в передаваемых параметрах. Метод run вызывает методы measure_steps, measure_delta, measure_distance и measure_time. Давайте рассмотрим каждый метод.
Метод measure_steps
Наконец то! Та часть, которая подсчитывает шаги в нашем приложении подсчета шагов. Первое, что мы делаем в методе measure_steps, это инициализируем следующие две переменные:
- переменная
@stepsиспользуется для подсчета количества шагов - переменная
count_stepsиспользуется для реализации гистерезиса с тем, чтобы определить, позволяем ли мы в определенный момент времени подсчитывать шаги.
Затем мы перебираем данные из @processor.filtered_data. Если текущее значение больше или равно значению THRESHOLD, а предыдущее значение было меньше, чем значение THRESHOLD, то мы переходим порог в положительном направлении, которое может указывать на шаг. В случае, если переменная count_steps равна значению false, что указывает на то, что мы уже подсчитывали шаг для этого пика, то с помощью инструкции unless мы переходим к следующему элементу данных. Если это не так, то мы увеличиваем значение переменной @steps на 1, и устанавливаем значение переменной count_steps равным false с тем, чтобы больше не добавлять шаги для этого пика. Затем, как только наши временные ряды пересекают ось х в отрицательном направлении, инструкция if устанавливает значение переменной count_steps равным true и мы переходим к следующему пику.
Это и есть та часть нашей программы, которая подсчитывает количество шагов! Наш класс Processor выполнил большой объем работы для того, чтобы очистить временные ряды и удалить частоты, которые приведут к подсчету ложных шагов, поэтому наша реализация подсчета шагов совсем не сложная.
Стоит отметить, что весь временной ряд для всего путешествия мы храним в памяти. Мы тестировали приложение в течение коротких промежутков времени, так что в настоящее время это не является проблемой, но в конце концов, мы хотели бы анализировать длительные прогулки с большими объемами данных. В идеале мы хотели бы обрабатывать был поток данных и хранить в памяти только очень небольшие порции временных рядов. С учетом этого мы должны положить работу с тем, чтобы обеспечить, чтобы нам была нужна только текущая точку данных и точка данных, которая была перед текущей. Кроме того, мы с помощью логической переменной реализовали гистерезис, так что нам не потребуется возвращаться назад по временным рядам с тем, чтобы гарантировать, что мы уже пересекли ось х в точке 0.
Есть тонкий баланс между вероятным подсчетом в будущем количества итераций и усложнением решения для всех мыслимых вариантов, которые могут когда-либо случиться. В данном случае разумно предположить, что вероятность того, что в ближайшем будущем нам придется обрабатывать длительные пешие прогулки, довольно низка.
Метод measure_delta
Если при пробном испытании у нас будет реальное количество пройденных шаги, то метод measure_delta возвратит разницу между расчетными и фактическими шагами.
Метод measure_distance
Расстояние измеряется путем умножения размера шага нашего пользователя на количество шагов. Поскольку расстояние зависит от количества шагов, то прежде, чем вызывать метод measure_distance, должен быть вызван метод measure_steps.
Метод measure_time
Пока у нас есть частота дискретизации, время рассчитывается путем деления общего количества имеющихся значений в выборке данных в filtered_data на частоту дискретизации. И, следовательно, время исчисляется в секундах.
Объединяем все вместе с помощью конвейера
Хотя наши классы Parser, Processor и Analyzer полезны, когда они работают по-отдельности, будет определенно лучше, если они будут работать вместе. Наша программа будет для их совместного запуска использовать конвейер, который мы ввели ранее. Поскольку нам придется часто обращаться к конвейеру, мы создадим класс Pipeline, с помощью которого будем запускать такой конвейер.
class Pipeline
attr_reader :data, :user, :trial, :parser, :processor, :analyzer
def self.run(data, user, trial)
pipeline = Pipeline.new(data, user, trial)
pipeline.feed
pipeline
end
def initialize(data, user, trial)
@data = data
@user = user
@trial = trial
end
def feed
@parser = Parser.run(@data)
@processor = Processor.run(@parser.parsed_data)
@analyzer = Analyzer.run(@processor.filtered_data, @user, @trial)
end
end
Мы используем уже знакомый шаблон run и подаем в класс Pipeline данные из акселерометра, а также экземпляры классов User и Trial. В методе feed реализован конвейер, который запускает класс Parser для работы с данными акселерометра, затем использует полученные данные для запуска класса Processor, наконец, запускает класс Analyzer для обработки отфильтрованных данных. В классе Pipeline есть переменные @parser, @processor и @analyzer для храненияы экземпляров соответствующих классов, так что в программе есть доступ к информации из этих объектов, которую можно отображать в нашем приложении.
Добавляем дружественный интерфейс
Мы сумели преодолеть большую и трудоемкую часть нашей программы. Далее, мы создадим веб-приложение для представления данных в формате, который удобен для восприятия пользователем. В веб-приложении, естественно, обработка данных отделена от представления данных. Давайте посмотрим на наше приложение с точки зрения удобства пользователя, а не сточки зрения разработки кода.
Пользовательский сценарий
Когда пользователь впервые входит в приложение, перейдя по ссылке /uploads, он видит таблицу с имеющимися данными и форму. Через которую он может загрузить новые данные, выданные акселерометром, а также информацию тесте и о пользователе (рис.16.18).

Рис.16.18. Общий вид
После ввода данных через форму, они сохраняются в файловой системе, анализируются, обрабатываются и анализируются на предмет количества пройденных шагов, а затем управление снова возвращается на ссылку /uploads, но уже с новой записью в таблице.
Если нажать на кнопку Detail (Детализация), то пользователь может для каждой записи может получить следующее предоставление данных, показанное на рис.16.19.
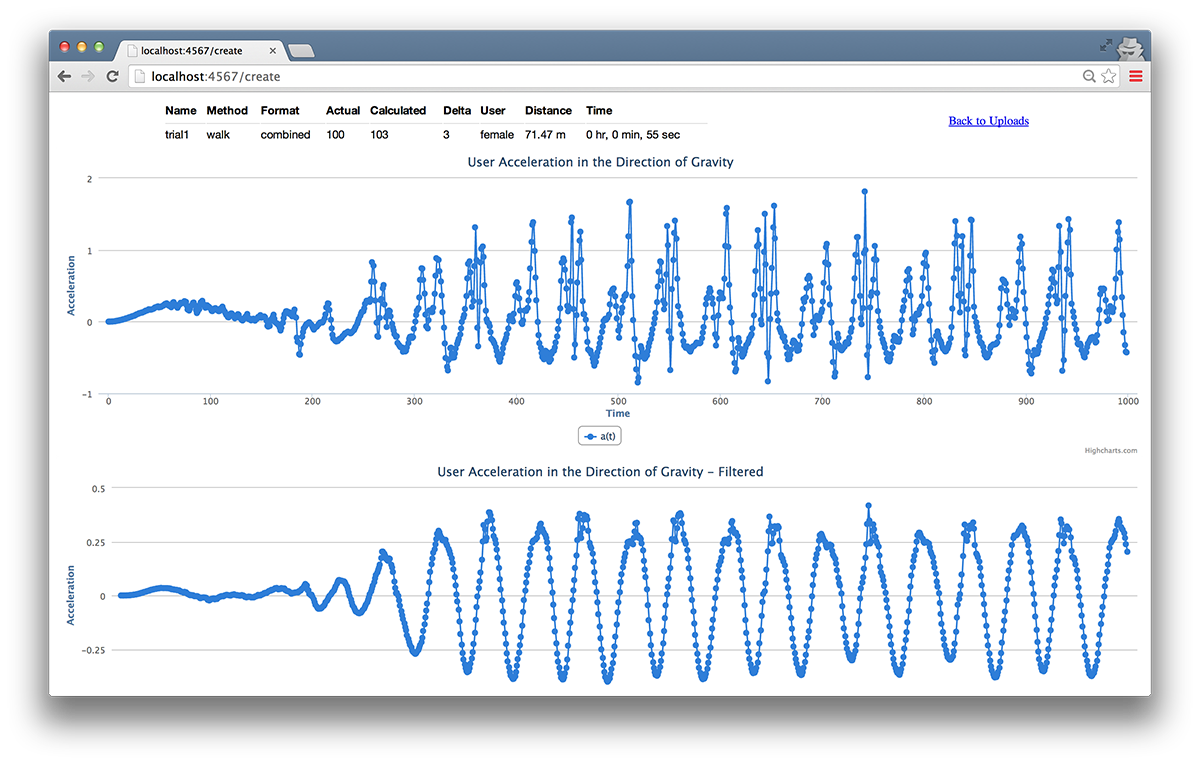
Рис.16.19. Детализация (увеличить)
Представленная информация включает в себя значения, вводимые пользователем через форму загрузки, значения, рассчитанные по нашей программе, а также графики временных рядов, над которыми выполняется операция скалярного произведения и снова следующая фильтрации. Пользователь может вернуться на страницу, если он нажмет на ссылку Back to Uploads (Обратно на страницу загрузки данных)
Давайте посмотрим на то, что в техническом плане будут означать для нас изложенные выше функциональные возможности. Нам понадобятся два основных компонента, которых у нас еще нет:
- Способ хранения и извлечения данных, которые вводит пользователь.
- Веб-приложение с базовым интерфейсом.
Давайте рассмотрим каждый из этих двух требований.
1. Сохранение и извлечение данных
Наше приложение должно сохранять входные данные в файловой системе и извлекать их оттуда. Мы создадим класс Upload, который это будет делать. Поскольку это класс имеет дело только с файловой системой и не относится непосредственно к реализации шагомера, мы, чтобы сократить изложение, не будем о нем рассказывать, но обсудим его основные функциональные возможности. В нашем классе Upload есть три метода для доступа к файловой системе и поиска в ней данных, причем все из них возвращают один или несколько экземпляров класса Upload:
- метод
createполучает файл и информацию о пользователе и о проведенном тесте. Он сохраняет файл в файловой системе и создает имя файла, в котором содержатся данные о пользователе и о тесте. Переменные экземпляров@file_path,@userи@trialпозволяют получить доступ к пути к файлу, объекту user и объектуtrial, соответственно. - метод
findполучает путь к файлу и возвращает экземпляр классаUpload. - метод
allвозвращает массив экземпляровUpload, по одному экземпляру для каждого файла данных акселерометра, загруженных в файловой системе.
Распределение задач при загрузке данных
Еще раз мы благоразумно разделили проблемы в нашей программе. Весь код, связанный с хранением и поиском данных, содержится в классе Upload. По мере роста нашего приложения, мы, вероятно, захотим использовать базу данных, а не сохранять все данные в файловой системе. Когда для этого придет время, все, что нам нужно сделать, это изменить класс Upload. Это позволит нам выполнить рефакторинг просто и ясно.
В будущем, мы можем сохранять объекты User и Trial в базе данных. Тогда методы create, find и all, которые есть в классе Upload и имею отношение к объектам User и Trial, также будут изменены. Это означает, что мы, вероятно, создадим отдельный класс, который будет определять механизмы хранения и поиска данных в целом, а каждый из наших классов User, Trial и Upload будет наследоваться от этого класса. Мы могли бы, в конечном итоге, добавить к этому классу вспомогательные методы запросов, и наследовать их оттуда.
2. Сборка веб приложения
Веб-приложения создавались много раз, так что мы переложим всю важную работу на плечи сообщества, создавшего открытый исходный код, и воспользуемся существующим фреймворком, который сделает за нас всю скучную работу. Это именно фреймворк Sinatra. Согласно документации фреймворк Sinatra является "языком DSL для быстрого создания веб-приложений на языке Ruby". Отлично.
Наш веб-приложение, должно будет отвечать на запросы HTTP, поэтому нам понадобится файл, в котором для каждой комбинации метода HTTP и адреса URL будет определен маршрут запроса и связанный с ним блок кода. Давайте назовем этот файл pedometer.rb.
get '/uploads' do
@error = "A #{params[:error]} error has occurred." if params[:error]
@pipelines = Upload.all.inject([]) do |a, upload|
a << Pipeline.run(File.read(upload.file_path), upload.user, upload.trial)
a
end
erb :uploads
end
get '/upload/*' do |file_path|
upload = Upload.find(file_path)
@pipeline = Pipeline.run(File.read(file_path), upload.user, upload.trial)
erb :upload
end
post '/create' do
begin
Upload.create(params[:data][:tempfile], params[:user], params[:trial])
redirect '/uploads'
rescue Exception => e
redirect '/uploads?error=creation'
end
end
Файл pedometer.r позволяет нашему приложению отвечать на запросы HTTP для каждого из наших маршрутов. Блок кода для каждого из маршрутов либо извлекает данные из файловой системы, либо сохраняет их в файловой системе с помощью с помощью класса Upload, а затем выполняет рендеринг или перенаправление. На наших страницах будут непосредственно использоваться экземпляры переменных. На страницах приложения просто отображаются наши данные, поэтому мы не будем приводить здесь их код.
Давайте по-отдельности рассмотрим каждый из маршрутов, указанный в файле pedometer.rb.
Запрос GET /uploads
Переход по адресу http://localhost:4567/uploads отправляет запрос HTTP GET нашему приложению и вызывается код get '/uploads'. Код запускает конвейер для всех закачек данных в файловую систему и выполняет рендеринг страницы, на которой отображается список всех загруженных данных и форма для загрузки новых данных. Если в параметре будет ошибка, то будет создана строка с сообщением об ошибке.
Запрос GET /upload/*
Если нажать на ссылку Detail, указанную для каждого закачанного набора данных, то будет послан запрос HTTP GET и указан маршрут /upload. Будет запущен конвейер и выполнен рендеринг страницы upload, в том числе будут перерисованы графики, созданные с помощью библиотеки JavaScript, которая называется HighCharts.
Запрос POST /create
Наш последний маршрут с запросом HTTP-POST - /create, вызывается, когда пользователь отправляет заполненную форму на странице загрузок uploads. Блок кода создает новый экземпляр класса Upload, используя для этого хэш-значение для params, закачивает введенное значение и выполняете перенаправление обратно на /uploads. Если в процессе создания объектов возникает ошибка, то при перенаправлении на /uploads добавляется параметр ошибки для того, чтобы пользователь мог знать, что что-то пошло не так, как надо.
Полностью функциональное приложение
Вуаля! Мы построили полностью функциональное приложение, имеющее практическую ценность.
Реальный мир ставит перед нами сложные задачи. Программное обеспечение является уникальным средством, способным решать эти проблемы в различных масштабах с минимально затрачиваемыми ресурсами. Как разработчики программного обеспечения, мы можем создавать положительные изменения в наших домах, наших общинах и нашем мире. Наше образование, академическое или иное, вероятно, вооружает нас навыками решения проблем, позволяющее написать код, решающих отдельные четко определенные проблемы. Когда мы работаем и оттачиваем наше ремесло, мы расширяем наши возможности, позволяющие решать практические задачи со всеми сложными реалиями нашего мира. Я надеюсь, что эта глава дала вам вкус превращения реальной проблемы в маленькие задачи, решаемые на практике, и написания красивого, чистого и расширяемого код, предназначенного для создания решения.
Вот такое решение интересной задачи в бесконечно сложном и интересном мире.