





Библиотека сайта rus-linux.net
Система обмена сообщениями ZeroMQ
Глава 24 из книги "Архитектура приложений с открытым исходным кодом", том 2.Оригинал: "ZeroMQ".
Автор: Martin Sústrik, перевод: Н.Ромоданов
24.6. Пакетная обработка
Как уже было упомянуто, огромное количество системных вызовов в системе обмена сообщениями может привести к возникновению узких мест по производительности. На самом деле, проблема гораздо более общая. Возникают очень нетривиальные потери производительности, связанные с обходом стека вызовов и, следовательно, при создании высокопроизводительных приложений разумно настолько, насколько это возможно, избегать выполнение обхода стека вызовов.
Рассмотрим рис.24.4. Чтобы отправить четыре сообщения, вы должны четыре раза пройти весь сетевой стек целиком (т.е. ØMQ, glibc, границу пользовательского пространства/пространства ядра, реализацию TCP, реализацию IP, слой Ethernet, сам NIC и снова вернуться).
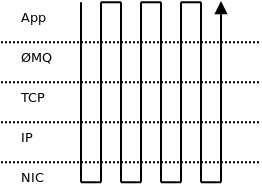
Рис.24.4: Отправка четырех сообщений
Тем не менее, если вы решите объединить эти четыре сообщения в один пакет, то потребуется только один обход стека (рис. 24.5). Влияние на пропускную способность сообщений может быть огромным: до двух порядков, особенно если сообщения маленькие и сотни таких сообщений можно упаковывать в один пакет.
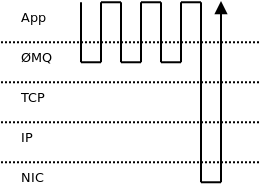
Рис.24.5: Пакетная обработка сообщений
С другой стороны, пакетная обработка может иметь негативное влияние на задержку. Возьмем, например, хорошо известный алгоритм Нэйгла (Nagle), который реализован в TCP. Он задерживает исходящие сообщения в течение определенного количества времени и объединяет все накопленные данные в одном пакете. Очевидно, что полная задержка первого сообщения в пакете гораздо больше, чем задержка последнего. Поэтому обычно, чтобы в приложениях снизить задержку, алгоритм Нэйгла отключается. Обычно отключается даже пакетная обработка на всех уровнях стека (например, возможность объединения прерываний NIC).
Но опять же, отсутствие пакетной обработки не означает больших перемещений по стеку и не приводит к низкой пропускной способности сообщений. Мы, кажется, столкнулись с дилеммой между пропускной способностью и задержкой.
Библиотека ØMQ пытается обеспечить сравнительно низкие задержки в сочетании с высокой пропускной способностью за счет использования следующей стратегии: когда поток сообщений небольшой и не превышает пропускную способность сетевого стека, ØMQ отключает всю пакетную обработку с тем, чтобы улучшить задержку. Компромисс здесь в несколько большем использовании ЦП - мы все еще должны часто проходить через стек. Однако в большинстве случаев это не является проблемой.
Когда скорость сообщений превышает пропускную способность сетевого стека, сообщения должны быть поставлены в очередь и храниться в памяти до тех пор, пока стек не будет готов принять их. Очередь означает, что задержка будет расти. Если сообщение находится в очереди одну секунду, то полная задержка будет равна, по меньшей мере, одну секунду. Что еще хуже, поскольку размер очереди растет, задержка будет постепенно увеличиваться. Если размер очереди не ограничен, то задержка может быть больше любого заранее заданного предела.
Было обнаружено, что даже если сетевой стек настроен на минимально возможную задержку (выключен алгоритм Нэйгла, выключено объединение прерываний NIC и т.д.) задержка все еще может быть достаточно большой из-за эффекта очереди, описанного выше.
В такой ситуации имеет смысл агрессивно начинать использование пакетной обработки. Нет ничего, чтобы можно было потерять, поскольку в любом случае задержка и так уже высока. С другой стороны, агрессивные использование пакетной обработки увеличивает пропускную способность и может убрать из очереди ожидающие сообщения, что в свою очередь означает, что задержка будет постепенно падать поскольку задержка из-за очереди уменьшается. Как только в очереди станет мало сообщений, пакетная обработка может быть отключена для еще большего снижения задержки.
Еще одно наблюдение состоит в том, что пакетная обработка должна выполняться только на самом верхнем уровне. Если сообщения группируются там, нижние слои так или иначе не имеют никакого отношения к пакетной обработке, поскольку все алгоритмы пакетной обработки ничего не делают, кроме как вводят дополнительную задержку.
Усвоенный урок: Длят ого, чтобы в асинхронной системе получить оптимальную пропускную способность в сочетании с оптимальным временем ответа, выключите все алгоритмы пакетной обработки на низких уровнях стека и включите пакетную обработку на самом верхнем уровне. Пакетная обработка требуется только тогда, когда новые данные прибывают быстрее, чем они могут быть обработаны.
24.7. Общий обзор архитектуры
До этого момента мы сосредоточили внимание на общих принципах, которые делают библиотеку ØMQ быстрой. Теперь мы взглянем на реальную архитектура системы (рис. 24.6).
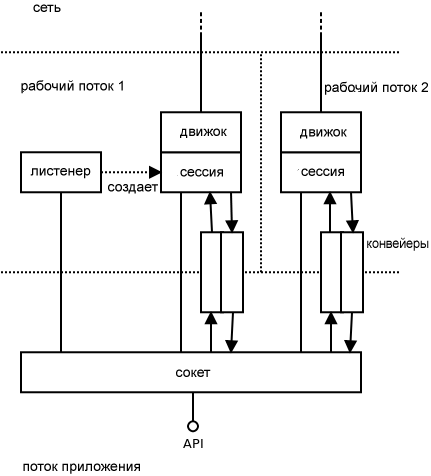
Рис.24.6: Архитектура ØMQ
Пользователь взаимодействует с ØMQ с использованием так называемых «сокетов». Они очень похожи на сокеты TCP, основное отличие в том, что каждый сокет может обрабатывать соединения с несколькими абонентами, что немного похоже на то, как это делают несвязанные сокеты UDP.
Объект сокета живет в потоке пользователя (смотрите обсуждение потоковых моделей в следующем разделе). Кроме этого, ØMQ работает в нескольких рабочих потоках, которые обрабатывают асинхронную часть соединения: чтение данных из сети, помещение сообщений в очередь, прием поступающих соединений и т.д.
Существуют различные объекты, находящиеся в рабочих потоках. Каждый из этих объектов принадлежит точно только одному родительскому объекту (принадлежность на диаграмме обозначается простой сплошной линией). Родительский объект может находиться в потоке, отличном от потока потомка. Большинство объектов принадлежат непосредственно сокетам; однако, есть несколько случаев, когда объект находится в собственности объекта, который принадлежит сокету. Все, что мы получаем, это дерево объектов, причем по одному такому дереву на сокет. Дерево используется в ходе завершения работы с сокетами; работа ни с одним из объектов не может быть завершена прежде, чем будет завершена работа со всеми его потомками. Таким образом, мы можем гарантировать, что процесс завершения будет работать так, как ожидается, например, ожидающие исходящие сообщения будут отправлены в сеть до завершения процесса отправки.
Грубо говоря, есть два вида асинхронных объектов; есть объекты, которые не участвуют в передаче сообщений, и есть объекты, которые участвуют. Объекты первого вида связаны главным образом с управлением соединением. Например, объект слушателя TCP (листенер) прослушивает входящие соединения TCP и создает объекты движка/сеанса для каждого нового соединения. Аналогичным образом объект коннектора TCP (соединение) пытается подключиться к пиру TCP и, в случае успеха, создает объект движка/сеанса для управления подключением. Если соединение было разорвано, то объект коннектора пытается восстановить его (реконнектор).
Объекты второго вида представляют собой объекты, которые непосредственно участвуют в передаче данных. Эти объекты состоят из двух частей: сессионный объект (session object) отвечает за взаимодействие с сокетом ØMQ, а объект движка (engine object) отвечает за связь с сетью. Имеется только один вид сессионного объекта, но для каждого протокола, который поддерживается в ØMQ, имеются различные типы объектов движков. Т.е., у нас есть движки TCP, движки IPC (межпроцессное взаимодействие), движки PGM (надежный мультикастовый протокол — смотрите RFC 3208) и др. Набор движков можно расширять - в будущем мы можем выбрать для реализации, скажем, движок WebSocket или движок SCTP.
Сессии являются сеансами обмена сообщениями с сокетами. Есть два направления для передачи сообщений и каждое направление обрабатывается при помощи конвейерного объекта. Каждый конвейер является в своей основе очередью без блокировок, оптимизированной для быстрого прохождения сообщений между потоками.
Наконец, есть объект контекста (о нем рассказывалось в предыдущих разделах, но он не показан на рисунке), в котором хранится глобальное состояние и он доступен всем сокетам и всем асинхронным объектам.
Далее: 24.8. Модель распараллеливания