





Библиотека сайта rus-linux.net
SQLAlchemy
Глава 20 из книги "Архитектура приложений с открытым исходным кодом", том 2.Оригинал: SQLAlchemy
Автор: Michael Bayer
Перевод: А. Панин
20.9. Рабочая единица
Метод flush объекта Session реализован в рамках отдельного модуля с именем unitofwork. Как упоминалось ранее, процесс сохранения данных, скорее всего, является наиболее сложной функцией, реализованной в SQLAlchemy.
Задачей рабочей рабочей единицы является перемещение данных из всех ожидающих обработки объектов, присутствующих в коллекции определенного объекта Session в базу данных с очисткой коллекций новых (new), устаревших (dirty) и удаленных (deleted) объектов, обрабатываемых объектом Session. После завершения этой работы находящиеся в памяти данные состояния объекта Session и данные текущей транзакции будут совпадать. Основной трудностью является установление корректной последовательности операций сохранения данных и последующее их выполнение в нужном порядке. Эта задача включает в себя создание списка запросов INSERT, UPDATE и DELETE, включая те запросы, которые были созданы в результате выполнения каскада операций, направленных на удаление или перемещение соответствующих строк; проверку того, что запросы UPDATE содержат только те столбцы, которые были действительно изменены; выполнение операций "синхронизации", в ходе которых будут скопированы данные состояния столбцов с первичными ключами в столбцы с ссылающимися на них внешними ключами в момент, когда заново сгенерированные идентификаторы в форме первичных ключей станут доступны; проверку того, что запросы INSERT используются в том же порядке, в каком объекты с ними были добавлены в коллекцию объекта Session, причем они должны использоваться настолько эффективно, насколько это возможно; а также проверку того, что запросы UPDATE и DELETE используются в корректном порядке для сокращения вероятности блокировок.
История
Реализация рабочей единицы была начата в форме запутанной системы из структур, возможности которой расширялись бессистемно в каждом отдельном случае; процесс ее разработки может сравниваться с процессом поиска выхода из леса без карты. Ранние ошибки и недостатки функций устранялись путем внесения специфических исправлений и, несмотря на улучшение ситуации после нескольких рефакторингов до версии 0.5, в версии 0.6 модуль рабочей единицы со стабилизированным, хорошо изученным и к тому времени снабженным сотнями тестов кодом должен был быть полностью переработан. После многих недель формирования нового подхода, в рамках которого должны были быть описаны стандартные структуры данных, сам процесс переписывания кода для использования этой новой модели занял всего несколько дней, так как к тому времени идея новой модели была понятна разработчикам. Фактически процесс разработки был значительно упрощен благодаря тому, что принцип работы новой реализации должен был тщательно сопоставляться и приводиться к принципу работы существующей версии. Этот процесс продемонстрировал, что несмотря на то, насколько первая реализация чего-либо является непродуманной, она все же очень ценна, так как является рабочей моделью. Кроме того, он демонстрирует, что полная переработка подсистемы не только допустима, но и является неотъемлемой частью процесса разработки сложных в реализации программных компонентов.
Топологическая сортировка
Ключевой парадигмой, использованной при создании рабочей единицы, является формирование полного списка действий для последующего выполнения в рамках структуры данных, причем каждый элемент этого списка будет представлять отдельный шаг; в области шаблонов проектирования этому подходу соответствует шаблон команд (command pattern). Позднее серии "команд" в рамках этой структуры данных располагаются в специфической последовательности с помощью топологической сортировки (topological sort). Топологическая сортировка представляет собой процесс, в ходе которого происходит сортировка элементов списка путем их частичного упорядочивания (partial ordering), т.е., в этом случае только определенные элементы списка должны быть расположены перед остальными. Рисунок 20.14 иллюстрирует описанный процесс топологической сортировки.
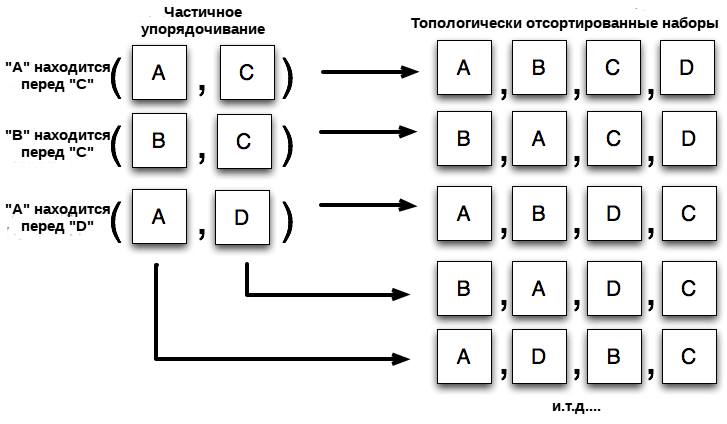
Рисунок 20.14: Топологическая сортировка
Рабочая единица выполняет частичное упорядочивание тех команд сохранения данных, которые должны предшествовать всем остальным. После того, как команды топологически отсортированы, они будут по очереди выполнены. Определение того, какие команды должны предшествовать другим командам, в основном осуществляется путем обнаружения результата выполнения функции relationship, которая связывает два объекта Mapper - в общем случае один объект Mapper рассматривается как зависящий от другого объекта, так как функция relationship устанавливает зависимость одного объекта Mapper от внешнего ключа другого объекта. Существуют похожие правила для установления таблиц соответствия между множествами объектов с обоих сторон, но в данном случае мы будем рассматривать случай использования отношений один ко многим/многие к одному. Зависимости от внешних ключей разрешаются последовательно для предотвращения появления нарушений в области ограничений без необходимости присвоения ограничениям метки "отложенное". Но, что не менее важно, сортировка позволяет использовать первичные ключи, которые генерируются на многих платформах только непосредственно в ходе выполнения запроса INSERT, путем извлечения их из набора результирующих данных только что выполненного запроса INSERT и вставки в список параметров зависимого запроса для добавления строки. В случае удаления строк данная сортировка производится в обратном порядке - зависимые строки удаляются до того, как происходит удаление строк, от которых они зависят, так как эти строки не будут доступны без наличия внешних ключей, ссылающихся на них.
Рабочая единица реализует систему, в рамках которой топологическая сортировка выполняется на двух различных уровнях, выделяемых на основе структуры имеющихся зависимостей. На первом уровне шаги сохранения данных распределяются между "корзинами" на основе зависимостей между объектами отображения таким образом, что полные "корзины" объектов соответствуют определенному классу. На втором уровне вообще не происходит разделения или происходит разделение одной или нескольких "корзин" на небольшие последовательности объектов с целью обработки случаев использования циклических ссылок или ссылающихся самих на себя таблиц. Рисунок 20.15 иллюстрирует "корзины", сгенерированные для вставки набора объектов User, с последующей вставкой набора объектов Address, причем на промежуточном шаге должно быть осуществлено копирование только что сгенерированных значений первичных ключей для объектов User в столбец внешних ключей с именем user_id для каждого из объектов Address.
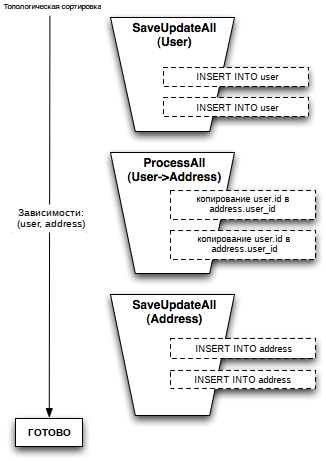
Рисунок 20.15: Организация объектов на основе объектов отображения
В ситуации, когда используется сортировка на основе объектов отображения, любое количество объектов User и Address может быть сохранено без увеличения сложности шагов или изменения количества "зависимостей", которые должны быть рассмотрены.
На втором уровне сортировки шаги сохранения данных организуются на основе прямых зависимостей между отдельными объектами в рамках области действия одного объекта отображения. Простейшим примером возникновения такой ситуации является таблица, которая содержит внешний ключ, ссылающийся на себя; а также определенная строка, которая должна быть вставлена в таблицу перед другой строкой, ссылающейся на эту строку. Другим примером является набор таблиц с циклическими ссылками (reference cycle): таблица A ссылается на таблицу B, которая в свою очередь ссылается на таблицу A. В этом случае некоторые объекты таблицы A должны быть вставлены перед другими объектами для того, чтобы также имелась возможность вставки объектов в таблицы B и C. Ссылающаяся сама на себя таблица является частным случаем циклической ссылки.
Для установления того, какие операции могут остаться в сформированных на основе объектов Mapper корзинах, а также того, какие корзины будут разделены на большие наборы команд для объектов, по отношению к набору зависимостей между объектами отображения применяется алгоритм определения циклических зависимостей, который является модифицированной версией алгоритма определения циклических зависимостей из блога Guido Van Rossum. Те корзины, в которых обнаружены циклические зависимости, впоследствии разделяются на операции, выполняемые по отношению к объектам, и добавляются в коллекцию разделенных на основе объектов отображения корзин путем добавления новых зависимостей от объектов из корзин, разделенных на основе объектов, в объекты из корзин, разделенных на основе объектов отображения. Рисунок 20.16 иллюстрирует процесс разделения корзины для объектов User на отдельные команды объектов путем использования функции relationship для указания на зависимость объекта User от своего атрибута contact.
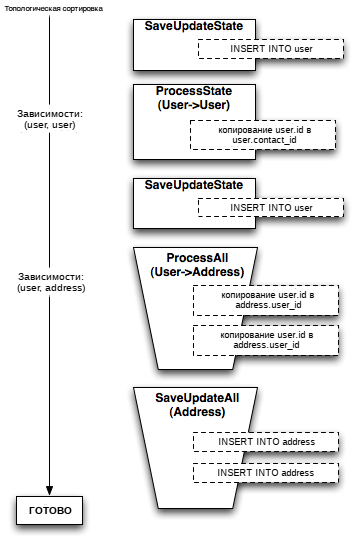
Рисунок 20.16: Преобразование циклических ссылок в отдельные шаги процесса
Обоснованием применения структуры корзин является возможность упорядочивания стандартных запросов настолько, насколько это возможно, путем сокращения числа шагов, выполняемых с использованием функций языка Python, а также возможность осуществления более эффективных взаимодействий с реализацией DBAPI, которые иногда позволяют выполнить тысячи запросов в рамках вызова одного метода на уровне языка Python. Более сложный метод определения индивидуальных зависимостей для объектов используется лишь в случае существования циклических ссылок между объектами отображения, но этот метод используется исключительно в тех частях графа объектов, где он требуется.
20.10. Заключение
С самого начала работы над SQLAlchemy перед разработчиками были поставлены значительные задачи, причем главной целью разработки было создание программного продукта для работы с базами данных, обладающего настолько большим набором возможностей и являющегося настолько гибким, насколько это возможно. Это задача была выполнена в ходе работы над поддержкой реляционных баз данных, так как было понятно, что всеобъемлющая и проработанная поддержка реляционных баз данных является основной задачей; и даже сейчас масштабы данной работы являются гораздо большими, чем казалось ранее.
Основывающийся на компонентах подход был предназначен для извлечения возможной пользы из каждой области возможностей путем предоставления множества различных элементов, которые приложения могли использовать по отдельности или комбинировать. Эту систему было интересно создавать, поддерживать и внедрять.
Для разработки был осознанно выбран медленный курс, основывающийся на предположении о том, что методичная, всесторонняя проработка основных функций в конечном итоге окажется более удачной, нежели быстрая реализация функций без должной проработки. Потребовалось много времени для того, чтобы система SQLAlchemy стала последовательной и хорошо документированной с точки зрения пользователя, но в ходе процесса разработки архитектура проекта всегда была на шаг впереди, что в некоторых случаях приводило к проявлению эффекта "машины времени", при котором функции могли добавляться до того, как пользователи запрашивали их.
Язык программирования Python был надежной основой (если быть немного привередливым, то можно отметить, в частности, область производительности). Последовательность и в значительной степени открытая модель времени выполнения позволили лучше реализовать в рамках SQLAlchemy те возможности, которые предоставлялись аналогичными программными продуктами, разработанными с использованием других языков программирования.
Участники проекта SQLAlchemy надеются, что язык программирования Python получит еще большее распространение в таком широком спектре областей и на таком большом количестве предприятий, как это возможно, а также на то, что масштабы использования реляционных баз данных останутся значительными и будут расширяться. Целью проекта SQLAlchemy является демонстрация того, что реляционные базы данных, язык программирования Python и хорошо продуманные объектные модели являются очень ценными инструментами разработчиков.
Вернуться к началу статьи.