





Библиотека сайта rus-linux.net
Puppet
Глава 18 из книги "Архитектура приложений с открытым исходным кодом", том 2.
Оригинал: Puppet
Автор: Luke Kanies
Перевод: А.Панин
18.2. Обзор архитектуры
Этот раздел в первую очередь посвящен описанию архитектуры реализации Puppet (т.е., описанию кода, который мы использовали для выполнения инструментом Puppet возложенных на него задач), но стоит также кратко обсудить архитектуру самого приложения (т.е., принцип взаимодействия его отдельных частей), ведь способ реализации приложения очень важен.
Инструмент Puppet был разработан для выполнения задач в двух режимах: в клиент/серверном режиме с центральным сервером и агентами, выполняющимися на отдельных узлах и в режиме без использования сервера, в котором отдельный процесс выполняет всю работу. Для достижения совместимости между этими режимами в рамках Puppet всегда использовался принцип внутренней сетевой прозрачности, поэтому при работе в двух режимах использовались одни и те же пути исполнения кода вне зависимости от того, осуществлялось ли взаимодействие посредством сети или нет. Для каждого исполняемого файла может быть установлен подходящий режим локального или удаленного доступа, но во всем остальном они будут вести себя идентично. Также следует отметить то, что вы можете использовать режим без сервера аналогично клиент-серверной конфигурации путем отправки файлов каждому клиенту и их последующего непосредственного разбора. В этом разделе будет описан клиент-серверный режим работы, так как он более прост для понимания ввиду рассмотрения отдельных компонентов, но следует помнить и о том, что информация из этого раздела также справедлива в случае работы в режиме без использования сервера.
Одно из определяющих архитектурных решений в рамках архитектуры приложения Puppet заключается в том, что клиенты не должны иметь доступ к модулям Puppet; вместо этого они должны получать спецификацию конфигурации, скомпилированную специально для них. Данный подход имеет множество достоинств: во-первых, вы будете следовать принципу снижения привилегий, в соответствии с которым каждый узел располагает только той информацией, которая предназначена для него (как он должен быть сконфигурирован), но не имеет доступа к информации о конфигурации других серверов. Во-вторых, вы можете полностью разделить операции и требования прав, необходимые для компиляции спецификации конфигурации (для этого может потребоваться доступ к централизованным хранилищам данных) и применения этой конфигурации. В-третьих, вы можете использовать отсоединенные узлы, на которых будет поддерживаться постоянная конфигурация без взаимодействия с центральным сервером, значит, конфигурация ваших серверов будет соответствовать спецификации даже в том случае, когда сервер прекратит работу и клиент отсоединится (как это происходит в случае мобильной установки или работы клиентов в "демилитаризованной зоне" сети (DMZ)).
- Процесс агента Puppet собирает информацию об узле, на котором он выполняется, и отправляет ее серверу.
- Система разбора данных использует эту системную информацию и располагающиеся на локальном диске модули Puppet для компиляции спецификации конфигурации для этого определенного узла, после чего возвращает ее агенту.
- Агент применяет полученную спецификацию конфигурации локально, таким образом изменяя локальное состояние узла, и заполняет отчет о результатах при содействии сервера.
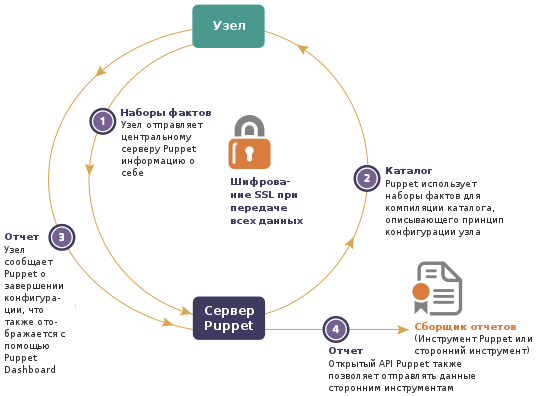
Рисунок 18.1: Потоки данных в Puppet
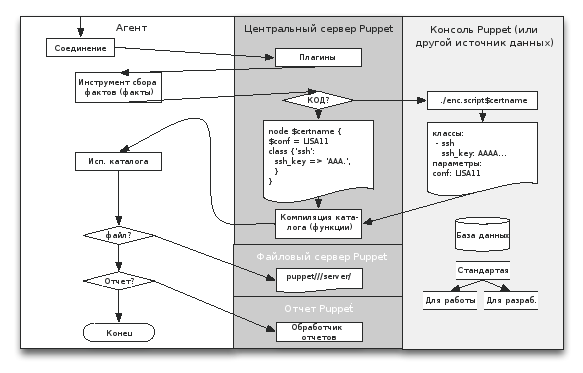
Рисунок 18.2: Управление потоком данных между процессами и компонентами Puppet
Таким образом, агент имеет доступ к информации о своей системе, ее конфигурации и каждому отчету, который он генерирует. Сервер располагает копиями всех этих данных и к тому же имеет доступ ко всем модулям Puppet и любым базам данных и службам, которые могут потребоваться для компиляции спецификации конфигурации.
Помимо всех компонентов, которые участвуют в формировании описанного потока данных и о которых мы поговорим позже, существует множество типов данных, используемых Puppet в ходе выполнения операций внутреннего взаимодействия. Эти типы данных являются критичными, так как с их помощью осуществляются все взаимодействия и они являются публично раскрываемыми типами данных, которые могут принимать или генерировать любые другие инструменты.
- Наборы фактов (Facts): Системные данные, собираемые на каждой машине и используемые для компиляции спецификаций конфигурации.
- Манифест (Manifest): Файлы, содержащие код Puppet и обычно объединяемые в рамках коллекций, называемых "модулями".
- Каталог (Catalog): Граф ресурсов заданного узла для управления и установления зависимостей между ними.
- Отчет (Report): Набор всех событий, генерируемых во время использования заданного каталога.
Помимо наборов фактов, манифестов, каталогов и отчетов, Puppet поддерживает типы данных для работы с файлами, сертификатами (которые он использует для аутентификации), а также некоторые другие.
Далее: Анализ компонентов