





Библиотека сайта rus-linux.net
Библиотека matplotlib
Глава 11 из книги "Архитектура приложений с открытым исходным кодом", том 2.Оригинал: matplotlib
Автор: John Hunter, Michael Droettboom, перевод: А.Панин
11.7. Тестирование с целью поиска регрессий
Исторически библиотека matplotlib не содержала большого количества низкоуровневых модульных тестов. Время от времени при получении сообщений о серьезной ошибке сценарий для ее воспроизведения добавлялся в специально предназначенную для таких файлов директорию дерева исходного кода. Отсутствие автоматизированных тестов приводило к обычным для такой ситуации проблемам и, что особенно важно, к регрессиям в ранее работающих функциях. (Нам скорее всего не следует внушать вам идею о том, что автоматизированное тестирование является полезной возможностью.) Конечно же, при наличии такого большого объема кода и множества параметров конфигурации, а также взаимозаменяемых частей кода (т.е., систем вывода данных), становится спорным утверждение о том, что для тестирования будет достаточно исключительно низкоуровневых модульных тестов; мы наоборот считаем, что наиболее эффективным является тестирование всех частей кода, функционирующих взаимосвязанно.
С этой целью был разработан сценарий, генерирующий множество графиков, при построении которых используются различные функции библиотеки matplotlib, в особенности те, которые было достаточно сложно реализовать. Этот подход немного облегчил процесс установления того, что новое изменение привело к непреднамеренному нарушению работы функции приложения, но корректность изображений все еще приходилось проверять вручную. Так как данное тестирование требовало большого количества ручной работы, оно не производилось достаточно часто.
На втором этапе этот метод был автоматизирован. Используемый на данный момент сценарий тестирования библиотеки matplotlib генерирует множество графиков, но вместо требования ручной обработки, эти графики автоматически сравниваются с образцами изображений. Все тесты используют фреймворк тестирования nose, который упрощает генерацию отчетов о непройденных тестах.
Усложняющим работу обстоятельством является тот факт, что сравнение изображений не может быть точным. Незначительные изменения версий библиотеки вывода шрифтов Freetype могут быть причиной незначительных отличий в выводе текста на различных машинах. Этих отличий не достаточно для того, чтобы считать график "некорректным", но достаточно, чтобы обнаружить различие в ходе побитового сравнения. Вместо этого фреймворк тестирования создает гистограммы обоих изображений и рассчитывает на их основе среднеквадратичное отклонение. Если это отклонение превышает заданное пороговое значение, считается что на изображениях слишком много различий и тест завершается неудачей. При неудачах в ходе проведения тестов генерируются изображения отличий, которые указывают на то, где произошли изменения графика (обратитесь к Рисунку 11.9). После этого разработчик может решить, является ли это различие результатом намеренного изменения и обновить образец графика для соответствия новому варианту изображения, или изображение на самом деле не является корректным, что подразумевает поиск и исправление ошибки, вызвавшей изменение.
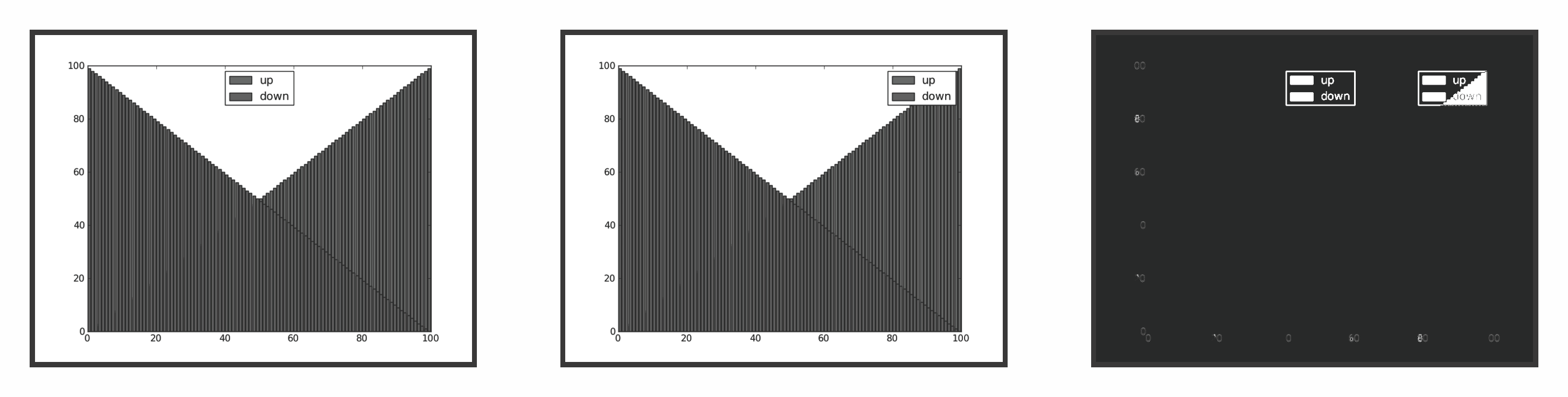
Рисунок 11.9: Сравнение изображений в ходе тестирования с целью поиска регрессий. Слева направо: a) Ожидаемое изображение, b) результат нарушения расположения легенды, c) различие между двумя изображениями.
Так как различные системы вывода данных могут содержать различные ошибки, фреймворк тестирования должен использовать множество систем вывода данных для каждого из графиков: PNG, PDF и SVG. В случае использования векторных форматов мы не сравниваем напрямую информацию из файлов, так как существует множество способов для отображения чего-либо с одинаковым результатом после преобразования в растровый формат. Системы вывода данных в векторный формат должны иметь полную свободу в плане изменения специфики своего вывода с целью повышения производительности без нарушения выполнения всех тестов. Следовательно, в случае систем для вывода данных в векторные форматы фреймворк тестирования в первую очередь преобразует файл в растровый формат с помощью стороннего инструмента (Ghostscript для PDF и Inkscape для SVG), после чего файл в растровом формате используется для сравнения.
Используя этот подход, нам удалось создать достаточно производительный фреймворк тестирования с нуля, причем это оказалось проще, чем разработка множества низкоуровневых модульных тестов. Все же, этот фреймворк не является идеальным; покрытие кода тестами не является полным, а также тратится большое количество времени для выполнения всех тестов. (Около 15 минут на системе с центральным процессором Intel Core 2 E6550 с тактовой частотой 2.23GHz.) Следовательно, некоторые регрессии все еще могут выпадать из области действия тестов, но все же общее качество релизов значительно улучшилось с момента реализации фреймворка тестирования.
Далее: Выученные уроки