





Библиотека сайта rus-linux.net
Компилятор Glasgow Haskell
Глава 5 из книги "Архитектура приложений с открытым исходным кодом", том 2.Оригинал: The Glasgow Haskell Compiler
Авторы: Simon Marlow и Simon Peyton-Jones
Перевод: Н.Ромоданов
Компиляция кода на языке Haskell
Как и в большинстве компиляторов, компиляция файла с исходным кода на языке Haskell выполняется как последовательность фаз, причем результат работы каждой фазы передается на вход следующей фазы. Общая структура различных фаз показана на рис.5.2.
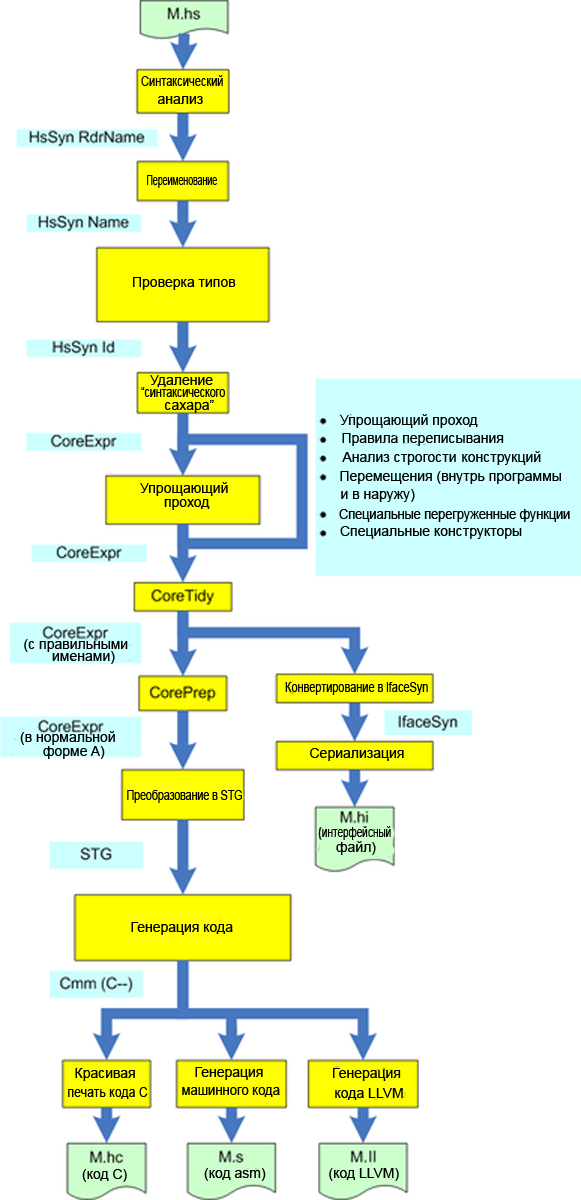
Рис.5.2: Фазы работы компилятора (картинка кликабельна)
Синтаксический разбор
Мы начинаем в традиционном стиле с синтаксического разбора, при котором в качестве входного берется файл с исходным кодом на языке Haskell, а на выходе создается абстрактный синтаксис. В компиляторе GHC тип данных абстрактного синтаксиса HsSyn параметризуется при помощи типов идентификаторов, которые в нем есть, с тем, чтобы для некоторого типа идентификаторов t дерево абстрактного синтаксиса имело тип HsSyn t. Это позволяет добавлять дополнительную информацию к идентификаторам по мере того, как программа проходит через различные фазы компилятора, и одновременно повторно использовать один и тот же тип деревьев абстрактного синтаксиса.
Результатом выполнения синтаксического разбора является абстрактное синтаксическое дерево, в котором идентификаторы являются простыми строками, которые мы называем RdrName. Таким образом, абстрактный синтаксис, создаваемый парсером, имеет тип HsSyn RdrName.
В компиляторе GHC используются инструментальные модули Alex и Happy для генерации кода при лексическом и синтаксическом анализе, соответственно, которые являются аналогами инструментальных средств lex и yacc для языка C.
Парсер компилятора GHC является чисто функциональным. В действительности, интерфейс API из библиотека GHC предоставляет чистую функцию, называемую parser, которая берет строку String (и некоторые другие данные) и возвращает либо разобранный абстрактный синтаксис, либо сообщение об ошибке.
Переименование
Переименование является процессом разрешения (присвоения новых имен — прим.пер.) всех идентификаторов, имеющихся в исходном коде языка Haskell, в полностью квалифицированные имена, одновременного определения того, выходят ли идентификаторы за область своей видимости, и, если это имеет место, создания соответствующих пометок об ошибках.
В языке Haskell можно в модуле повторно экспортировать идентификатор, который импортируется из другого модуля. Например, предположим, что в модуле A определяется функцию с именем f, а в модуле B импортируется модуль A и повторно экспортируется f. Теперь, если модуль C импортирует модуль B, он может ссылаться на f по имени B.f, хотя первоначально f было определено в модуле A. Это полезный способ работы с пространством имен; он означает, что библиотеку можно использовать в любом месте внутри структуры модулей, где вы пожелаете, и, при этом, предоставлять понятный и аккуратный интерфейс API через несколько интерфейсных модулей, в которые повторно экспортируют идентификаторы из внутренних модулей.
Однако компилятор для того, чтобы знать, чему соответствует каждое имя в исходном коде, должен во всем этом разобраться. Мы строго различаем сущности (entities), т. е. «сами предметы» (в нашем примере, A.f), и имена, с помощью которых можно обращаться к сущностям (например, B.f). В любом конкретном месте в исходном коде, в области видимости есть набор сущностей, и для каждой из них может быть известно одно или несколько различных имен. Задача блока переименования заключается в замене каждого из имен в внутреннем представлении кода, имеющегося в компиляторе, на ссылку на конкретную сущность. Иногда имя может ссылаться на несколько сущностей; само по себе это не является ошибкой, но если имя действительно используется, то блок переименования установит флаг ошибки неоднозначности и отвергнет программу.
При переименовании в качестве входа берется абстрактный синтаксис Haskell (HsSyn ,RdrName), а на выходе получают (HsSyn Name). Здесь Name является ссылкой на конкретную сущность.
Разрешение имен является основной работой блока переименования, но он также выполняет множество других задач: анализ функций и установка флага ошибки в случае, если у функций не совпадает количество аргументов; преобразование инфиксным выражений согласно приоритету выполнения операций; выявление объявлений-дубликатов; генерация предупреждений о неиспользуемых идентификаторах, и так далее.
Проверка типов
Проверкой типов, как можно было бы предположить, является процесс проверки того, что программа на языке Haskell является корректной с точки зрения используемых типов. Если программа проходит проверку типов, то ее работа гарантированно не закончится крахом во время выполнения. Термин «крах» здесь имеет формальное определение, которое включает в себя сбой работы аппаратных средств, например, «ошибка сегментации», но не включает в себя такие ситуации, как ошибки сопоставления с образцом. Гарантия того, что работа программы не закончится крахом, может быть нарушена использованием определенных небезопасных функций языка, например, использованием интерфейса доступа к внешним функциям Foreign Function Interface.
В качестве входных данных блока проверки типа берется HsSyn Name (исходный код на языке Haskell с полностью квалифицированными именами), а на выходе получают HsSyn Id. Идентификатор Id является именем Name с дополнительной информацией: в частности типом. На самом деле, синтаксические конструкции языка Haskell, создаваемые блоком проверки типов, сопровождаются полным набором информации, касающейся типов: для каждого идентификатора указывается его собственный тип данных, а также есть вся информация, достаточная для преобразования подвыражений любых типов (например, это может использоваться в оболочках IDE).
На практике, проверка типов и переименование могут чередоваться, т.к. из-за использованию шаблонов языка Haskell во время выполнения происходит генерация кода, для которого необходимы переименование и проверка типов.
Сокращение синтаксического разнообразия языка и язык Core
Язык Haskell является довольно большим языком, в котором есть много различных синтаксических форм. Его назначение быть легким для тех, кто на нем читает и пишет; в нем присутствует широкий спектр синтаксических конструкций, которые дают программисту большую гибкость в выборе наиболее подходящей конструкцией для конкретной ситуации. Однако эта гибкость означает, что часто для одного и того же кода есть несколько способов записи; например, выражение if по смыслу идентично выражению case с вариантами True и False, а сложная нотация списков может быть преобразована в обращения к функциям map, filter и concat. В действительности, в определении языка Haskell указывается, как все эти конструкции переводятся в более простые конструкций; конструкций, в которые можно выполнить преобразование без всякого, так называемого, «синтаксического сахара».
Для компилятора гораздо проще, если весь синтаксический сахар удален, поскольку при последующих проходах оптимизации, которые необходимо использовать с программой на языке Haskell, работа будет происходить с языком меньшего размера. Поэтому процесс сокращения синтаксического разнообразия языка удаляет весь синтаксический сахар, переводя полный синтаксис языка Haskell в гораздо меньший язык, который мы называем базовым языком. Мы позже поговорим подробно о базовом языке Core.
Оптимизация
Теперь, когда программа представлена в виде базового языка Core, начинается процесс оптимизации. Одна из самых сильных сторон компилятора GHC состоит в оптимизации, в ходе которой убираются слои абстракции и вся эта работа происходит на уровне базового языка Core. Язык Core является крошечным функциональным языком, но это чрезвычайно гибкое средство для выполнения оптимизаций, начиная с самого высокого уровня, например, проверки строгости конструкций, и до самого низкого уровня, например, сокращения числа действий.
Each of the optimisation passes takes Core and produces Core. The main pass here is called the Simplifier, whose job it is to perform a large collection of correctness-preserving transformations, with the goal of producing a more efficient program. Some of these transformations are simple and obvious, such as eliminating dead code or reducing a case expression when the value being scrutinised is known, and some are more involved, such as function inlining and applying rewrite rules (discussed later).
При каждой оптимизации берется язык Core и создается язык Core. При этом главный проход называется упрощающим (Simplifier), работа которого заключается в применении большого набора преобразований, не нарушающих правильность программы, с целью получения более эффективной программы. Некоторые из этих преобразований просты и очевидны, например, устранение недоступного кода или сокращение выражения case после тщательного исследования значения, а некоторые — более сложные, например, подстановка функций непосредственно в код и применение правил грамматического вывода (будут рассмотрены ниже).
Упрощающий подход обычно выполняется между другими проходами оптимизация, которых насчитывается до шести; какие проходы на самом деле работают и в каком порядке, зависит от уровня оптимизации, который выбирает пользователь.
Генерация кода
После того, как будет оптимизирована программа Core, начинается процесс генерации кода. После нескольких административных проходов, код преобразуется программу одного из следующих двух видов: либо он превращается в байт-код для исполнения интерактивным интерпретатором, либо он передается в генератор кода для последующего перевода в машинный код.
Генератор кода сначала преобразует программу Core в язык, называемый STG, который, по существу, представляет собой аннотированный вариант Core с дополнительной информацией, которая необходима генератору кода. Затем STG транслируется в Cmm, низкоуровневый императивный язык с явным использованием стека. С этого момента преобразование кода может пойти по одному из следующих трех вариантов:
- Генерация нативного кода: В компиляторе GHC есть простые генераторы кода для нескольких вариантов архитектуры процессоров. Этот вариант выполняется быстро и создается код, который подходит для большинства случаев.
- Генерация кода LLVM:
Cmmпреобразуется в код на языке LLVM и передается компилятору LLVM. В этом варианте в некоторых случаях может создаваться значительно лучший код, хотя на это требуется больше времени, чем генератору нативного кода. - Генерация кода на языке C: Компилятор GHC может создавать код на обычном языке C. Этот вариант существенно более медленный, чем два предыдущих варианта, но он может быть полезен при портировании компилятора GHC на новые платформы.
Продолжение статьи: Ключевые проектные решения