





Библиотека сайта rus-linux.net
Масштабируемая Веб-архитектура и распределенные системы
Глава 1 из книги "Архитектура приложений с открытым исходным кодом", том 2.
Оригинал: "Scalable Web Architecture and Distributed Systems",
глава из книги "The Architecture
of Open Source Applications" том 2.
Автор: Кейт Мэтсудейра,
Перевод: © jedi-to-be. Коррекция:
Anastasiaf15,
sunshine_lass,
Amaliya,
fireball,
Goudron.
Перевод впервые был опубликован на сайте Хабрахабр
Прокси
На базовом уровне прокси-сервер - промежуточная часть аппаратных средств/программного обеспечения, которые получают запросы от клиентов и передают их к серверам источника бэкэнда. Как правило, прокси используются, чтобы фильтровать запросы, протоколировать запросы, или иногда преобразовывать запросы (добавляя/удаляя заголовки, шифруя/дешифруя или сжимая).

Рисунок 1.13 Прокси-сервер
Прокси также очень полезны при координировании запросов, поступающих от большого количества серверов, что дает возможность оптимизировать трафик запроса в масштабе всей системы. Один их способов использования прокси для ускорения доступа к данным заключается в объединении одинаковых или схожих запросов и передачи единого ответа клиентам запроса. Этот термин получил название сжатое перенаправление (collapsed forwarding).
Представим, что с нескольких узлов поступают запросы на одинаковые данные (назовем их littleB), но в кэше часть этих данных отсутствует. Если этот запрос направляется через прокси, то все запросы могут быть объединены в один, и в результате этой оптимизации littleB будет считан с диска только один раз. (См. рисунок 1.14) В этом случае придется немного пожертвовать скоростью, поскольку процесс обработки запросов и их объединения привести к несколько более длительным задержкам. Однако, при высокой нагрузке это напротив приведет к улучшению производительности, особенно в случае многократных запросов одинаковых данных. Стратегия функционирования прокси аналогична кэшу, но вместо хранения данных, он оптимизирует запросы или вызовы документам.
В LAN-прокси, например, клиенты не нуждаются в своем собственном IP-адресе, для соединения с Интернетом. Прокси объединяет запросы от клиентов на одинаковый контент. Однако это порождает двусмысленность, так как многие прокси являются также и кэшами (поскольку являются логичным местом для размещения кэша), но не все кэши работают как прокси.
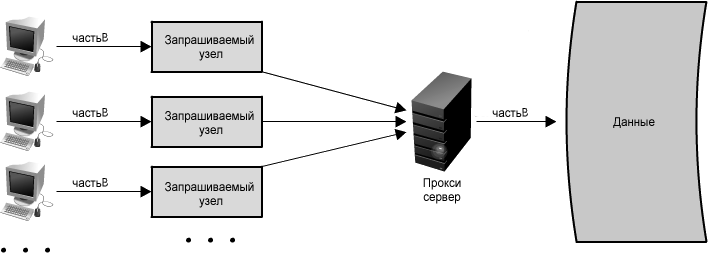
Рисунок 1.14: Использование прокси-сервера для комбинирования запросов
Еще одним отличный способ использования прокси состоит не просто в объединении запросов одинаковых данных, но также и частей данных, которые находятся пространственно близко друг к другу в хранилище источника (последовательно на диске). Использование такой стратегии максимизирует локальность данных для запросов, что может привести к сокращению задержки запроса. Например, если набор узлов запрашивает части B: часть-B1, часть-B2, и т.д., мы можем настроить наш прокси, чтобы он распознавал пространственное местоположение отдельных запросов, комбинируя их в единственный запрос и возвращаясь только bigB, значительно минимизируя чтения из источника данных. (См. рисунок 1.15) В случае доступа к целым терабайтам данных в произвольном порядке время реализации запроса может сильно отличаться. Так как прокси могут, по существу, сгруппировать несколько запросов в один, они особенно полезны в ситуациях с высокой нагрузкой или ограниченными возможностями кэширования.
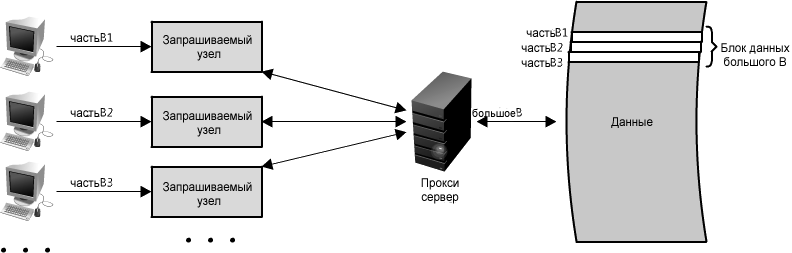
Рисунок 1.15: Использование прокси для комбинирования запросов на данные, находящихся пространственно близко друг к другу
Стоит отметить, что вы можете использовать прокси и кэши вместе, но обычно лучше помещать кэш перед прокси по той же причине, по которой лучше позволять более быстрым бегунам стартовать в марафоне с большим количеством участников. Это вызвано тем, что кэш использует данные из памяти, что очень быстро, и это не противоречит многократным запросам на тот же результат. Но если бы кэш был расположен с другой стороны прокси-сервера, то возникла бы дополнительная задержка для каждого запроса перед кэшем, что могло бы снизить производительность.
Если вы рассматриваете добавление прокси в ваши системы, то у вас есть много вариантов для выбора;
Squid и
Varnish прошли испытания временем и широко используются во многих производительных веб-сайтах. Эти решения для прокси предлагают множество вариантов оптимизации, чтобы выжать максимум из клиент-серверного обмена данными. Установка одного из них в режиме реверсивного прокси (описан ниже в разделе о балансирующей нагрузке) на уровне веб-сервера может значительно улучшить производительность веб-сервера, уменьшая объем работы для обработки входящих клиентских запросов.
Индексы
Использование индекса для получения быстрого доступа к вашим данным - известная стратегия для того, чтобы эффективно оптимизировать доступ к данным. Наиболее широкое применение индексирование находит в базах данных. Индекс делает взаимные уступки, используя издержки объемов хранения данных и снижая скорости операций <записи> (так как вы должны одновременно и записывать данные, и обновлять индекс), позволяя получить выигрыш в виде более быстрых операций <чтения>.
Вы можете также применить эту концепцию к более крупным хранилищам данных, точно так же, как и к реляционным наборам данных. Хитрость с индексами заключается в четком понимании того, как пользователи получают доступ к вашим данным. В случае если объемы наборов данных измеряются многими терабайтами, а полезной информации в них совсем немного (например, 1 Кбайт), использование индексов является необходимостью для оптимизации доступа к данным. Нахождение малой по размеру полезной информации в таком большом наборе данных может быть реальной проблемой, так как вы точно не сможете последовательно перебрать такое большое количество данных за любое разумное время. Кроме того, весьма вероятно, что такой большой набор данных распределен между несколькими (или многими!) физическими устройствами, и это означает, что вам необходимо каким-то образом найти правильное физическое местоположение нужных данных. Индексы - лучший способ сделать это.
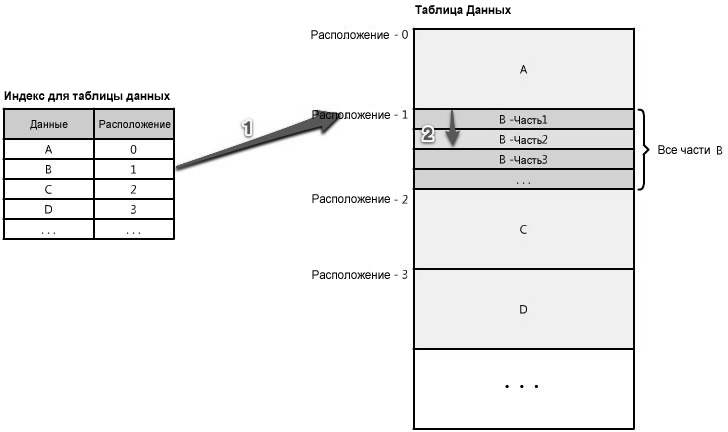
Рисунок 1.16: Индексы
Индекс может использоваться как оглавление, которое направляет вас к местоположению ваших данных. К примеру, скажем, вы ищете порцию данных, часть ©2 секции "B" - как вы узнаете, где ее найти? Если у вас есть индекс, отсортированный по типу данных - назовем данные "A", "B", "C" - он укажет вам расположение данных "B" в источнике. Тогда вы просто должны найти это расположение и считать ту часть "B", которая вам нужна. (См. рисунок 1.16)
Данные индексы часто хранятся в памяти или где-нибудь очень локально по отношению к входящему запросу клиента. Berkeley DB (BDB) и древовидные структуры данных, которые обычно используются, чтобы хранить данные в упорядоченных списках, идеально подходят для доступа с индексом.
Часто имеется много уровней индексов, которые служат картой, перемещая вас от одного местоположения к другому, и т.д., до тех пор пока вы не получите ту часть данных, которая вам необходима. (См. рисунок 1.17)
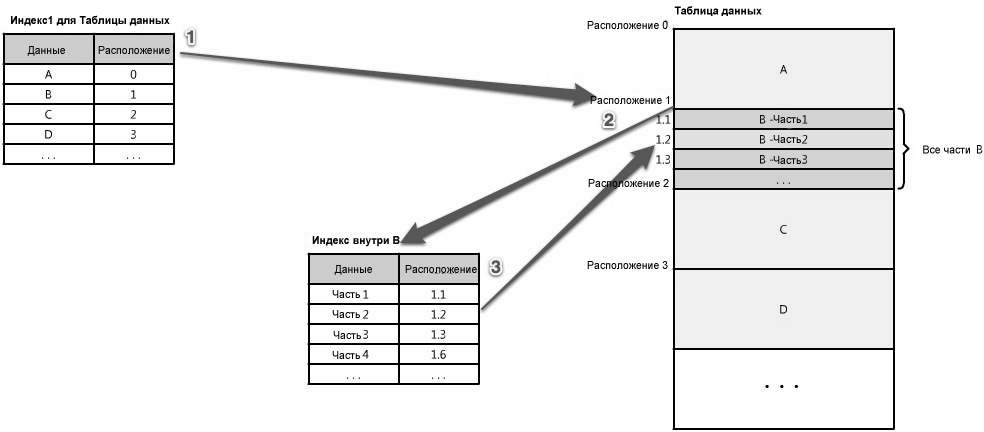
Рисунок 1.17: Многоуровневые индексы
Индексы могут также использоваться для создания нескольких других представлений тех же данных. Для больших наборов данных это - отличный способ определить различные фильтры и виды, не прибегая к созданию многих дополнительных копий данных.
Например, предположим, что система хостинга изображений, упомянутая выше, на самом деле размещает изображения книжных страниц, и сервис обеспечивает возможность клиентских запросов по тексту в этих изображениях, ища все текстовое содержимое по заданной теме также, как поисковые системы позволяют вам искать по HTML-содержимому. В этом случае все эти книжные изображения используют очень много серверов для хранения файлов, и нахождение одной страницы для представления пользователю может быть достаточно сложным. Изначально обратные индексы для запроса произвольных слов и наборов слов должны быть легкодоступными; тогда существует задача перемещения к точной странице и месту в этой книге и извлечения правильного изображения для результатов поиска. Таким образом, в этом случае инвертированный индекс отобразился бы на местоположении (таком как книга B), и затем B может содержать индекс со всеми словами, местоположениями и числом возникновений в каждой части.
Инвертированный индекс, который может отобразить Index1 в схеме выше, будет выглядеть примерно так: каждое слово или набор слов служат индексом для тех книг, которые их содержат.
| будучи удивительной | книга B, Книга C, Книга D |
| всегда | Книга C, Книга F |
| верьте | Книга B |
Промежуточный индекс будет выглядеть похоже, но будет содержать только слова, местоположение и информацию для книги B. Такая содержащая несколько уровней архитектура позволяет каждому из индексов занимать меньше места, чем, если бы вся эта информация была сохранена в один большой инвертированный индекс.
И это ключевой момент в крупномасштабных системах, потому что даже будучи сжатыми, эти индексы могут быть довольно большими и затратными для хранения. Предположим, что у нас есть много книг со всего мира в этой системе, - 100,000,000 (см. запись блога "Внутри Google Books")- и что каждая книга состоит только из 10 страниц (в целях упрощения расчетов) с 250 словами на одной странице: это суммарно дает нам 250 миллиардов слов. Если мы принимаем среднее число символов в слове за 5, и каждый символ закодируем 8 битами (или 1 байтом, даже при том, что некоторые символы на самом деле занимают 2 байта), потратив, таким образом, по 5 байтов на слово, то индекс, содержащий каждое слово только один раз, потребует хранилище емкостью более 1 терабайта. Таким образом, вы видите, что индексы, в которых есть еще и другая информация, такая, как наборы слов, местоположение данных и количества употреблений, могут расти в объемах очень быстро.
Создание таких промежуточных индексов и представление данных меньшими порциями делают проблему <больших данных> более простой в решении. Данные могут быть распределены на множестве серверов и в то же время быть быстродоступны. Индексы - краеугольный камень информационного поиска и база для сегодняшних современных поисковых систем. Конечно, этот раздел лишь в общем касается темы индексирования, и проведено множество исследований о том, как сделать индексы меньше, быстрее, содержащими больше информации (например, релевантность), и беспрепятственно обновляемыми. (Существуют некоторые проблемы с управляемостью конкурирующими условиями, а также с числом обновлений, требуемых для добавления новых данных или изменения существующих данных, особенно в случае, когда вовлечены релевантность или оценка).
Очень важна возможность быстро и легко найти ваши данные, и индексы - самый простой и эффективный инструмент для достижения этой цели.
Далее: Балансировщики нагрузки