





Библиотека сайта rus-linux.net
Масштабируемая Веб-архитектура и распределенные системы
Глава 1 из книги "Архитектура приложений с открытым исходным кодом", том 2.
Оригинал: "Scalable Web Architecture and Distributed Systems",
глава из книги "The Architecture
of Open Source Applications" том 2.
Автор: Кейт Мэтсудейра,
Перевод: © jedi-to-be. Коррекция:
Anastasiaf15,
sunshine_lass,
Amaliya,
fireball,
Goudron.
Перевод впервые был опубликован на сайте Хабрахабр
Избыточность
Чтобы элегантно справится с отказом, у веб-архитектуры должна быть избыточность ее служб и данных. Например, в случае наличия лишь одной копии файла, хранившегося на единственном сервере, потеря этого сервера будет означать потерю и файла. Вряд ли подобную ситуацию можно положительно охарактеризовать, и обычно ее можно избежать путем создания множественных или резервных копии.Этот тот же принцип применим и к службам. От отказа единственного узла можно защититься, если предусмотреть неотъемлемую часть функциональности для приложения, гарантирующую одновременную работу его нескольких копий или версий.
Создание избыточности в системе позволяет избавиться от слабых мест и обеспечить резервную или избыточную функциональность на случай нештатной ситуации. Например, в случае наличия двух экземпляров одной и той же службы, работающей в "продакшн", и один из них выходит из строя полностью или частично, система может преодолеть отказ за счет переключения на исправный экземпляр.
Переключение может происходить автоматически или потребовать ручного вмешательства..
Другая ключевая роль избыточности службы - создание архитектуры, не предусматривающей разделения ресурсов. С этой архитектурой каждый узел в состоянии работать самостоятельно и, более того, в отсутствие центрального <мозга>, управляющего состояниями или координирующего действия других узлов. Она способствует масштабируемости, так как добавление новых узлов не требует специальных условий или знаний. И что наиболее важно, в этих системах не найдется никакой критически уязвимой точки отказа, что делает их намного более эластичными к отказу..
Например, в нашем приложении сервера изображения, все изображения имели бы избыточные копии где-нибудь в другой части аппаратных средств (идеально - с различным географическим местоположением в случае такой катастрофы, как землетрясение или пожар в центре обработки данных), и службы получения доступа к изображениям будут избыточны, при том, что все они потенциально будут обслуживать запросы. (См. рисунок 1.3.)
Забегая вперед, балансировщики нагрузки - отличный способ сделать это возможным, но подробнее об этом ниже.
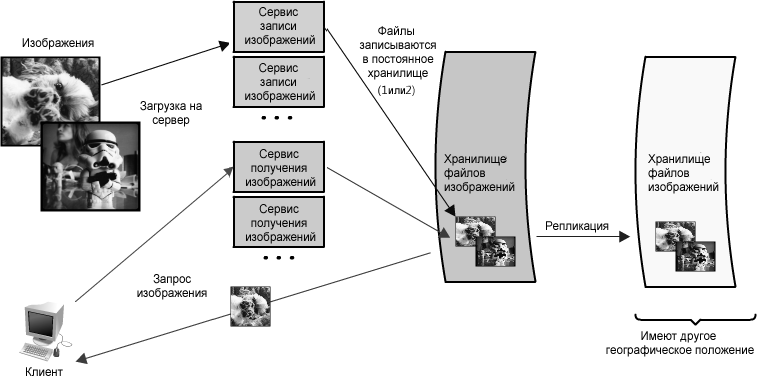
Рисунок 1.3: Приложение хостинга изображений с избыточностью
Сегментирование
Наборы данных могут быть настолько большими, что их невозможно будет разместить на одном сервере. Может также случиться, что вычислительные операции потребуют слишком больших компьютерных ресурсов, уменьшая производительность и делая необходимым увеличение мощности. В любом случае у вас есть два варианта: вертикальное или горизонтальное масштабирование.Вертикальное масштабирование предполагает добавление большего количества ресурсов к отдельному серверу. Так, для очень большого набора данных это означало бы добавление большего количества (или большего объема) жестких дисков, и таким образом весь набор данных мог бы разместиться на одном сервере. В случае вычислительных операций это означало бы перемещение вычислений в более крупный сервер с более быстрым ЦП или большим количеством памяти. В любом случае, вертикальное масштабирование выполняется для того, чтобы сделать отдельный ресурс вычислительной системы способным к дополнительной обработке данных.
Горизонтальное масштабирование, с другой стороны, предполагает добавление большего количества узлов. В случае большого набора данных это означало бы добавление второго сервера для хранения части всего объема данных, а для вычислительного ресурса это означало бы разделение работы или загрузки через некоторые дополнительные узлы. Чтобы в полной мере воспользоваться потенциалом горизонтального масштабирования, его необходимо реализовать как внутренний принцип разработки архитектуры системы. В противном случае изменение и выделение контекста, необходимого для горизонтального масштабирования может оказаться проблематичным.
Наиболее распространенным методом горизонтального масштабирования считается разделение служб на сегменты или модули. Их можно распределить таким образом, что каждый логический набор функциональности будет работать отдельно. Это можно сделать по географическими границами, или другим критериям таким, как платящие и не платящие пользователи. Преимущество этих схем состоит в том, что они предоставляют услугу или хранилище данных с расширенной функциональностью.
В нашем примере сервера изображения, возможно, что единственный файловый сервер, используемый для хранения изображения, можно заменить множеством файловых серверов, при этом каждый из них будет содержать свой собственный уникальный набор изображений. (См. рисунок 1.4.) Такая архитектура позволит системе заполнять каждый файловый сервер изображениями, добавляя дополнительные серверы, по мере заполнения дискового пространства. Дизайн потребует схемы именования, которая свяжет имя файла изображения с содержащим его сервером. Имя изображения может быть сформировано из консистентной схемы хеширования, привязанной к серверам. Или альтернативно, каждое изображение может иметь инкрементный идентификатор, что позволит службе доставки при запросе изображения обработать только диапазон идентификаторов, привязанных к каждому серверу (в качестве индекса).

Рисунок 1.4: Приложение хостинга изображений с избыточностью и сегментированием
Конечно, есть трудности в распределении данных или функциональности на множество серверов. Один из ключевых вопросов - местоположение данных; в распределенных системах, чем ближе данные к месту проведения операций или точке вычисления, тем лучше производительность системы. Следовательно, распределение данных на множество серверов потенциально проблематично, так как в любой момент, когда эти данные могут понадобиться, появляется риск того, что их может не оказаться по месту требования, серверу придется выполнить затратную выборку необходимой информации по сети.
Другая потенциальная проблема возникает в форме несогласованности (неконсистетности). Когда различные сервисы выполняют считывание и запись на совместно используемом ресурсе, потенциально другой службе или хранилище данных, существует возможность возникновения условий "состязания" - где некоторые данные считаются обновленными до актуального состояния, но в реальности их считывание происходит до момента актуализации - и таком случае данные неконсистентны. Например, в сценарии хостинга изображений, состояние состязания могло бы возникнуть в случае, если бы один клиент отправил запрос обновления изображения собаки с изменением заголовка "Собака" на "Гизмо", в тот момент, когда другой клиент считывал изображение. В такой ситуации неясно, какой именно заголовок, "Собака" или "Гизмо", был бы получен вторым клиентом..
Есть, конечно, некоторые препятствия, связанные с сегментированием данных, но сегментирование позволяет выделять каждую из проблем из других: по данным, по загрузке, по образцам использования, и т.д. в управляемые блоки. Это может помочь с масштабируемостью и управляемостью, но риск все равно присутствует. Есть много способов уменьшения риска и обработки сбоев; однако, в интересах краткости они не охвачены в этой главе. Если Вы хотите получить больше информации по данной теме, вам следует взглянуть на блог-пост по отказоустойчивости и мониторингу.
Далее: Структурные компоненты быстрого и масштабируемого доступа к данным