





Библиотека сайта rus-linux.net
Экосистема NoSQL
Глава 13 из книги "Архитектура приложений с открытым исходным кодом", том 1.
Оригинал: The NoSQL Ecosystem
Автор: Adam Marcus
Перевод: А.Панин
13.4. Масштабирование с целью повышения производительности
Только что обсудив работу в условиях неполадок, давайте представим более приятную ситуацию: успешное функционирование системы! Если созданная вами система успешно функционирует, ваше хранилище данных станет одним из компонентов системы, который снизит производительность под нагрузкой. Простым и не самым элегантным решением этой проблемы является расширение возможностей (scale up) существующего оборудования: вы можете вложить больше средств в оперативную память и жесткие диски для обработки нагрузок с использованием единственной машины. После этого успешного шага денежные вливания в более дорогое аппаратное обеспечение станут невозможными. В таком случае вам придется копировать данные и распространять запросы между несколькими машинами для распределения нагрузки. Этот подход называется распределением возможностей (scale out) и оценивается с помощью степени горизонтального масштабирования (horizontal scalability) вашей системы.
Идеальной степенью горизонтального масштабирования является линейная масштабируемость (linear scalability), при достижении которой удвоение количества машин, задействованных в вашей системе хранения данных, удваивает количество запросов, которое система в состоянии обработать. Ключевым фактором для достижения такой степени горизонтального масштабирования является способ распределения данных между серверами. Фрагментация системы является действием, направленным на разделение нагрузки чтения и записи данных между множеством машин с целью распределения возможностей вашей системы хранения данных. Фрагментация системы является фундаментальным понятием в рамках архитектур многих систем, а именно: Cassandra, HBase, Voldemort и Riak, а недавно также MongoDB и Redis. Некоторые проекты, такие, как CouchDB созданы с учетом производительности отдельного сервера и не предоставляют встроенных решений для фрагментации системы, но сторонние проекты предоставляют программные компоненты для координации, позволяющие распределить нагрузку между независимыми установками этой системы на множестве машин.
Давайте рассмотрим несколько взаимозаменяемых терминов, с которыми вы можете столкнуться. Мы будем использовать термины фрагментация системы и разделение системы для обозначения аналогичных действий. Термины машина, сервер или узел относятся к какому-либо физическому компьютеру, хранящему часть разделенных данных. Наконец, кластер или кольцо относятся к группе машин, которые участвуют в работе вашей системы хранения данных.
Фрагментация системы подразумевает то, что ни одна машина не должна обрабатывать нагрузку, создаваемую операциями записи всего набора данных, а также ни одна машина не может ответить на запрос всего набора данных. Большинство систем NoSQL использует ключи и в моделях данных и в моделях запросов, при этом очень малое количество запросов осуществляет доступ ко всему набору данных в любом случае. Так как основной метод доступа к данным, хранящимся этими системами, связан с использованием ключей, фрагментация системы также обычно реализуется на основе ключей: с помощью некоторой функции, принимающей ключ в качестве исходных данных, устанавливается машина, на которой будет храниться пара ключ-значение. Мы рассмотрим два метода создания сопоставления ключ-машина: метод хэш-разделения и метод разделения на основе диапазонов.
13.4.1. Не фрагментируйте систему без необходимости
Фрагментация усложняет систему и, если это возможно, вы должны избегать ее. Давайте рассмотрим два способа масштабирования без фрагментации: копирование читаемых данных (read replicas) и кэширование (caching).
Копирование читаемых данныхМногие системы хранения данных принимают большее количество запросов на чтение данных, чем на их запись. Простым решением в данном случае является копирование данных на множество машин. Все запросы записи все также будут отправляться ведущему серверу. Запросы чтения же будут отправляться машинам, хранящим копии данных, обычно немного устаревших по отношению к данным на ведущем сервере.
Если вы уже копируете ваши данные для длительного хранения на множестве серверов и используете конфигурацию ведущих и ведомых серверов, что типично для систем Redis, CouchDB или MongoDB, ведомые машины для обслуживания запросов чтения могут взять на себя часть нагрузки ведущего сервера. Некоторые запросы, такие, как запросы для создания отчетов о ваших наборах данных, которые могут быть требовательны к ресурсам и обычно не нуждаются в обновленной с точностью до секунды копии данных, могут быть выполнены в отношении копий данных на ведомых серверах. Как правило, чем менее жесткие требования вы предъявляете к актуальности данных, тем большее количество работы вы можете перенести на ведомые серверы, тем самым повысив производительность запросов чтения данных.
КэшированиеКэширование наиболее популярных данных в вашей системе обычно работает на удивление хорошо. Система Memcached выделяет блоки памяти на множестве серверов для кэширования данных из вашего локального хранилища данных. Клиенты Memcached пользуются преимуществами нескольких приемов горизонтального масштабирования для разделения нагрузки между установками системы Memcached на различных серверах. Для добавления памяти в пул кэширования следует просто добавить другой узел с запущенной копией системы Memcached.
Так как система Memcached проектировалась для кэширования данных, она не так сложна в плане архитектуры, как решения для постоянного хранения данных, масштабируемые в зависимости от нагрузок. Перед рассмотрением более сложных решений подумайте о том, сможет ли кэширование поспособствовать решению ваших проблем с масштабированием. Кэширование не является исключительно временной мерой: компания Facebook использует систему Memcached для работы с объемами оперативной памяти в десятки терабайт!
Копирование читаемых данных и кэширование позволяют вам масштабировать высокие нагрузки, создаваемые запросами чтения данных. Однако, когда вы начнете повышать частоту использования операций записи и обновления ваших данных, вы будете также повышать нагрузку на ведущий сервер, хранящий все обновленные данные. В оставшейся части данного раздела мы рассмотрим техники фрагментации нагрузки, создаваемой операциями записи, с использованием множества серверов.
13.4.2. Фрагментация системы с помощью программ для координации запросов
Проект CouchDB развивается в направлении функционирования на единственном сервере. Два проекта, Lounge и BigCouch, упрощают операцию фрагментации нагрузок на систему CouchDB с помощью внешнего прокси-сервера, который работает как система предварительной обработки запросов, передаваемых функционирующим системам CouchDB. В данной архитектуре отдельные установки системы не подозревают о существовании друг друга. Программа координации распределяет запросы между отдельными установками системы CouchDB на основе ключей запрашиваемых документов.
Компания Twitter встроила механизмы фрагментации нагрузок и копирования данных с фреймворк для координации с названием Gizzard. Фреймворк Gizzard использует отдельные хранилища данных любых типов - вы можете использовать слой совместимости системами хранения данных SQL и NoSQL - и объединяет их в деревья любой глубины для разделения ключей на основе диапазонов ключей. Для снижения восприимчивости к неполадкам фреймворк Gizzard16 может быть настроен таким образом, что данные для одного и того же диапазона ключей будут копироваться на множество физических машин.
13.4.3. Последовательные хэш-кольца
Качественные хэш-функции распределяют набор ключей равномерно. Это делает их мощным инструментом для распределения пар ключ-значение между множеством серверов. В научной технической литературе подробно описана техника под названием "последовательное хэширование" (consistent hashing), которая впервые была применена для организации хранилищ данных в рамках систем с названием "распределенные хэш-таблицы" (distributed hash tables - DHTs). Системы NoSQL, построенные на принципах системы Dynamo от компании Amazon применяют данную технику распределения, а также она используется в системах Cassandra, Voldemort и Riak.
Хэш-кольца в примере

Рисунок 13.1: Кольцо распределенной хэш-таблицы
Последовательные хэш-кольца работают следующим образом. Представим, что мы используем хэш-функцию H, которая производит равномерное распределение ключей, ставя их в соответствие большим целочисленным значениям. Мы можем сформировать кольцо из чисел в диапазоне [1, L], которое замыкается и может указать на позицию числа, полученного с использованием функции H(ключ) mod L для какого-либо относительно большого целочисленного значения L. С помощью данной функции любой ключ будет поставлен в соответствие значению из диапазона [1, L]. Последовательное хэш-кольцо для серверов формируется путем получения уникального идентификатора каждого сервера (например, его IP-адреса) и применения к нему функции H. Вы можете интуитивно понять принцип работы данного алгоритма, обратившись к сформированному из пяти серверов (A-E) хэш-кольцу на Рисунке 13.1.
В данном случае мы выбираем значение L=1000. Давайте представим, что H(A) mod L = 7, H(B) mod L = 234, H(C) mod L = 447, H(D) mod L = 660 и H(E) mod L = 875. Теперь мы можем сказать, на каком сервере должен находиться ключ. Для этого мы поставим в соответствие всем ключам серверы, определяя, попадает ли ключ в диапазон значений, соответствующих каждому из серверов. Например, сервер A отвечает за хранение ключей, хэш-значения которых находятся в диапазоне [7, 233], а E отвечает за хранение ключей с хэш-значениями в диапазоне [875, 6] (этот диапазон пересекает значение 1000). Таким образом, если H('employee30') mod L = 899, то этот ключ будет храниться на сервере E, а если H('employee31') mod L = 234, то ключ будет храниться на сервере B.
Копирование для длительного хранения данных на множестве серверов осуществляется путем передачи ключей и значений из одного ассоциированного с сервером диапазона серверам, следующим далее в кольце. Например, при трехкратной репликации ключи, соответствующие диапазону [7, 233], будут храниться на серверах A, B и C. Если сервер A прекратит работу из-за неполадок, соседние серверы B и C примут на себя предназначенную для этого сервера нагрузку. Некоторые архитектуры предусматривают возможность временного копирования данных на сервер E и переноса на него нагрузки сервера A, после чего диапазон значений сервера E будет расширен для включения в него значений, раньше соответствующих серверу A.
Хотя хэширование и является статистически эффективным методом равномерного распределения пространства ключей, обычно требуется большое количество серверов для того, чтобы это распределение стало действительно равномерным. К сожалению, мы обычно начинаем работу с малого количества серверов, которые не идеально отделяются друг от друга с помощью данной хэш-функции. В нашем примере длина диапазона ключей сервера A равна 277 и в то же время длина диапазона ключей сервера E равна 132. Это обстоятельство ведет к неравномерной нагрузке на серверы. Также оно осложняет процесс переноса функций с одного сервера на другой в случае неполадок, так как соседний сервер может внезапно получить контроль над всем диапазоном вышедшего из строя сервера.
Для решения проблемы неравномерности диапазонов ключей многие системы, включая Riak, создают по нескольку "виртуальных" узлов на физической машине. Например, при наличии 4 виртуальных узлов сервер A будет функционировать как серверы A_1, A_2, A_3 и A_4. Каждый виртуальный узел использует для хэширования различные значения, увеличивая вероятность управления ключами, распределенными по различным частям пространства ключей. Система Voldemort использует аналогичный подход, при котором количество диапазонов значений настраивается вручную и обычно больше количества серверов, в результате каждый сервер получает несколько небольших диапазонов значений.
Система Cassandra не ставит в соответствие каждому серверу множество небольших диапазонов, что иногда приводит к неравномерному распределению диапазонов ключей. Для балансировки нагрузки в Cassandra используется асинхронный процесс, который динамически определяет расположение серверов на кольце в зависимости от нагрузки на них в течение прошедшего времени.
13.4.4. Распределение с использованием диапазонов
В случае применения техники распределения с использованием диапазонов для фрагментации нагрузки некоторые машины, обслуживающие вашу систему, хранят метаданные с указанием на то, какие серверы хранят те или иные диапазоны ключей. Эти метаданные используются для поиска расположения ключа и поиска диапазонов, соответствующих серверам. Аналогично подходу с использованием последовательных хэш-колец, при распределении с использованием диапазонов пространство ключей разделяется на диапазоны, причем каждый диапазон ключей управляется одной машиной и возможно копируется на другие. В отличие от подхода с использованием последовательных хэш-колец, два ключа, находящиеся друг рядом с другом после сортировки, скорее всего, окажутся в одном и том же диапазоне. Это обстоятельство уменьшает объем метаданных для поиска диапазонов, так как большие диапазоны могут быть представлены в сжатом виде с помощью маркеров [начало, конец].
С введением активного механизма учета записей о соответствии диапазонов серверам, подход разделения диапазонов позволяет более точно выполнять снижение нагрузки на и без того загруженные серверы. Если в определенном диапазоне ключей фиксируется более высокий, чем в других диапазонах трафик, менеджер нагрузок может уменьшить размер диапазона для сервера или снизить количество обслуживаемых сервером фрагментов данных. Появившаяся свобода активного управления нагрузками достигается за счет введения дополнительных архитектурных компонентов для мониторинга и маршрутизации запросов.
Подход системы BigTableДокументация системы BigTable компании Google описывает иерархическую технику распределения данных в объекты (tablets) с использованием диапазонов. Объект хранит диапазон ключей и значений строки в рамках семейства столбцов. Он осуществляет поддержку всех необходимых журналов и структур данных для ответов на запросы о ключах в соответствующем диапазоне. Серверы объектов обслуживают множество объектов в зависимости от рабочей загрузки каждого из них.
Размер каждого объекта поддерживается в пределах 100-200 MB. Так как объекты могут изменять размер, два небольших объекта для примыкающих диапазонов ключей могут быть объединены, а также объект большого размера может быть разделен на два объекта. Ведущий сервер анализирует размер объекта, загрузку и доступность сервера объектов. Ведущий сервер устанавливает какой сервер объектов обслуживает объекты в любой момент времени.
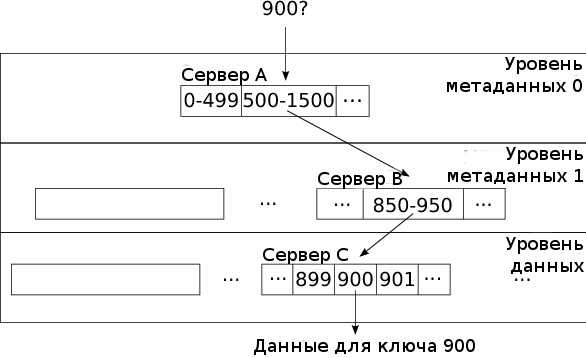
Рисунок 13.2: Распределение с использованием диапазонов системы на основе BigTable
Центральный сервер поддерживает соответствие объектов в таблице метаданных. Так как эти метаданные могут достигать больших объемов, таблица метаданных также использует фрагментацию в виде объектов, которые ставят в соответствие диапазоны ключей объектам и обозначают серверы объектов, ответственные за работу с этими диапазонами. Этот подход приводит необходимости преодоления трехслойной иерархической структуры для нахождения ключа на хранящем его сервере объектов, как показано на Рисунке 13.2.
Давайте рассмотрим пример. Клиент, ищущий ключ 900 отправляет запрос серверу A, который хранит объект для метаданных уровня 0. Этот объект идентифицирует объект метаданных уровня 1 на сервере B, содержащий диапазоны ключей 500-1500. Клиент отправляет запрос серверу B с ключом, который отвечает, что объект, содержащий ключи 850-950 найден в объекте на сервере C. Наконец, клиент отправляет запрос с требованием ключа на сервер C и получает данные строки в ответ. Объекты метаданных уровней 0 и 1 могут кэшироваться клиентом, который хочет избежать создания излишней нагрузки на серверы объектов ввиду отправки повторяющихся запросов. Документация системы BigTable указывает на то, что эта трехуровневая иерархическая структура может использовать для работы 261 байт полезного дискового пространства, создавая объекты размером в 128 MB.
Ведущий сервер является единой точкой отказа в рамках архитектуры BigTable, но он может временно прекращать работу, не влияя на запросы к серверам объектов. Если сервер объектов прекращает работу в момент обработки запросов объектов, ведущий сервер должен определить это и переназначить его объекты, при этом, запросы будут завершаться ошибкой в течение некоторого промежутка времени.
В общем случае для определения наличия и обработки неполадок машин документация BigTable рекомендует использовать Chubby, распределенную систему блокировок для управления принадлежностью к группам и доступностью сервера. Система ZooKeeper17 является реализацией Chubby с открытым исходным кодом и некоторые проекты на основе Hadoop используют ее для управления вторичными ведущими серверами и переназначения серверов объектов.
Проекты NoSQL, применяющие распределение с использованием диапазоновСистема HBase применяет иерархический подход для реализации системы распределения с использованием диапазонов BigTable. Данные объектов хранятся в распределенной файловой системе Hadoop (HDFS). Файловая система HDFS выполняет копирование данных и проверяет копии на наличие повреждений, оставляя для серверов объектов задачи по обработке запросов, обновлению структур хранилища и инициированию разделения и объединения объектов.
Система MongoDB использует технологию распределения данных с использованием диапазонов, аналогичную таковой в системе BigTable. Несколько конфигурационных узлов хранят и управляют таблицами перенаправлений, которые содержат информацию о том, какой из серверов хранения данных ответственен за какой из диапазонов ключей. Эти конфигурационные узлы синхронизируют данные с использованием протокола под названием "двухфазная передача" (two-phase commit) и работают в качестве гибридного решения, состоящего из ведущего сервера BigTable для указания диапазонов и системы Chubby для управления конфигурацией в условиях высокой доступности. Отдельные процессы маршрутизации, не использующие состояния, отслеживают последние запросы изменения конфигурации маршрутизации и осуществляют перенаправления запросов к соответствующим серверам хранилища данных для получения ключей. Серверы хранилища данных распределены в группы серверов копий данных для осуществления репликации.
Система Cassandra предоставляет сохраняющую последовательность систему распределения, используемую в том случае, если желательно разрешить быстрые сканирования диапазонов с доступом к ваших данных. Серверы системы Cassandra все также объединены в кольцо с использованием последовательного хэширования, но вместо хэширования пар ключ-значение и сопоставления полученного результата с кольцом для установления сервера, которому должны соответствовать эти данные, ключ просто ставится в соответствие серверу, который контролирует диапазон значений, содержавший ключ входил изначально. Например, ключи 20 и 21 оба будут поставлены в соответствие серверу A в нашем последовательном хэш-кольце на Рисунке 13.1, вместо хэширования и случайного распределения по кольцу.
Фреймворк Gizzard компании Twitter для управления распределенными и скопированными данными с использованием множества систем применяет распределение с использованием диапазонов для фрагментации данных. Маршрутизирующие серверы из иерархий любых глубин ставят диапазоны ключей в соответствие серверам, стоящим ниже их по иерархии. Эти серверы либо хранят данные для ключей в соответствующем им диапазоне, либо перенаправляют запросы маршрутизирующим серверам другого уровня. Репликация в данной модели реализуется с помощью отправки обновлений на множество машин для диапазона ключей. Серверы маршрутизации системы Gizzard обрабатывают ошибки записи способом, отличным от применяемых другими системами NoSQL. Система Gizzard требует, чтобы системные архитекторы сделали все обновления многократными (они могут выполняться дважды). В случае, когда узел хранилища не может выполнить запрос, узлы маршрутизации кэшируют и периодически отправляют обновления узлу до тех пор, пока он не подтвердит успешное завершение обновления данных.
13.4.5. Какую систему распределения данных следует использовать
Какую систему распределения данных предпочтительнее выбрать после рассмотрения подходов к фрагментации данных на основе хэшей и диапазонов? Это зависит от условий ее использования. Распределение с использованием диапазонов является очевидным выбором в случае частого сканирования ключей для доступа к данным. Так как вы читаете данные используя ключи, вы не будете осуществлять обращения к случайным узлам сети, усиливая тем самым загрузку на нее. Но если вам не требуется сканировать диапазоны данных, то какую схему их фрагментации следует использовать?
Разделение данных с использованием хэшей позволяет достичь разумной степени их распределения по узлам, а случайные диспропорции в распределении могут быть сглажены с помощью создания виртуальных узлов. В схеме распределения данных с помощью хэширования маршрутизация реализуется достаточно просто: в большей части случаев хэш-функция может выполняться клиентами для поиска необходимого сервера. В случае применения более сложных схем ребалансировки поиск необходимого сервера для ключа становится более сложной задачей.
Распределение с использованием диапазонов требует дополнительных затрат ресурсов на поддержку серверов маршрутизации и конфигурации, которые будут работать под большими нагрузками и станут центральными точками отказа в случае отсутствия относительно сложных схем обработки ошибок. Однако, при правильной настройке, данные, распределенные с использованием диапазонов, для балансировки нагрузки будут разделены на небольшие фрагменты, которые могут быть перемещены в другие диапазоны при высокой нагрузке на систему. В случае отключения сервера соответствующие ему диапазоны могут быть разделены между множеством других серверов вместо создания дополнительной нагрузки на его соседние серверы в период неработоспособности.
Продолжение статьи: 13.5. Согласованность данных.