





Библиотека сайта rus-linux.net
Архитектура Mercurial
Глава 12 из книги "Архитектура приложений с открытым исходным кодом", том 1.
Оригинал: "Mercurial".
Автор: Dirkjan Ochtman
Перевод: Vlad http://vlad8.com/
12.2. Структуры данных
Теперь, когда концепция направленного ациклического графа должна быть достаточно ясной, давайте рассмотрим как эти графы хранятся в Mercurial. Модель графа является центральной во внутреннем механизме Mercurial, в действительности мы используем несколько различных графов в хранилище репозитория на диске (а также в структуре кода в памяти). В этой секции объясняется, что это за структуры и как они взаимодействуют вместе.
12.2.1. Проблемы
До того, как мы окунемся в информацию о структурах данных, я бы хотел немного рассказать об окружении, в котором развивался Mercurial. Первое упоминание о Mercurial может быть найдено в сообщении, которое Мэтт Маколл отослал в список рассылки ядра Linux в апреле 2005 года. Это произошло вскоре после того, как было решено, что BitKeeper больше не может быть использован для развития ядра. Мэтт начал свое сообщение, обозначив некоторые цели: система должна быть простой, масштабируемой и эффективной.
В своем докладе «К лучшему управлению источниками данных: Revlog и Mercurial» в 2006 году Мэтт заявил, что современная система контроля версий должна работать с деревьями, состоящими из миллиона файлов, работать с миллионами изменений и масштабироваться между тысячами пользователей, создающими новые версии кода паралелльно в течение десятилетий. Исходя из этих целей он указал лимитирующие технологические факторы
- скорость: ЦПУ
- объем: дисковое пространство и память
- пропускная способность: память, LAN, диск и WAN
- скорость чтения диска
Скорость чтения диска и пропускная способность WAN являются сегодня ограничивающими факторами, и поэтому система должна быть оптимизирована с их учетом. В докладе также излагаются обычные сценарии или критерии для оценки производительности таких систем на уровне файлов:
- Компрессия хранилища: какая форма компрессии больше всего подходит для хранения истории файлов на диске? Какой алгоритм позволяет получить наилучшую производительность ввода/вывода, при этом не допуская того, чтобы процессор стал узким местом системы?
- Получение произвольных версий файлов: некоторые системы контроля версий хранят конкретную версию таким образом, что для того, чтобы воссоздать новую версию (с использованием информации об изменениях), будет необходимо прочитать большое количество более старых версий кода. Необходимо контролировать этот процесс, чтобы получение старых версий оставалось быстрым.
- Добавление версий файлов: мы регулярно добавляем новые версии. Мы не хотим перезаписывать старые версии каждый раз, когда мы добавляем новую, потому что это существенно замедлит процесс, когда версий станет достаточно много.
- Показ истории файлов: мы хотим иметь возможость просматривать историю всех изменений, которые происходили с конкретным файлом. Это также позволит делать аннотации (которые назывались blame в CVS, но были переименованы в annotate в более поздних системах, чтобы убрать негативный подтекст): просмотреть исходный вид каждой строки в файле до изменения.
В докладе также рассматриваются подобные сценарии на уровне проекта. Основными операциями на этот уровне являются получение версии, коммит изменений (создание новой версии), поиск изменений в рабочей копии. Последняя операция, в частности, может быть медленной для больших деревьев (для проектов типа Mozilla или NetBeans, каждый из которых использует Mercurial для контроля версий).
12.2.2. Быстрое хранение версий: Revlogs
Решение, которое нашел Мэтт для Mercurial, было названо revlog (сокрещенно от revision log – лог версий). Revlog — это способ эффективного хранения версий файлов (каждая из версий при этом содержит определенные изменения по сравнению с предыдущей). Такой способ должен быть эффективным с точки зрения времени доступа (то есть оптимизированным для поиска по диску) и занимаемого дискового пространства, учитывая обычные сценарии, описанные в предыдущей секции. Чтобы удовлетворить этим критериям, revlog представляет собой два файла на диске: индекс и файл данных.
Таблица 1: Формат записи Mercurial
6 байт | Смещение фрагмента |
2 байта | Флаги |
4 байта | Длина фрагмента |
4 байта | Длина в несжатом виде |
4 байта | Базовая версия |
4 байта | Связанная версия |
4 байта | Версия-предок 1 |
4 байта | Версия-предок 2 |
32 байта | Хэш |
Индекс состоит из записей фиксированной длины, содержимое которых описано в таблице 1. То, что записи имеют фиксированную длину, позволяет прямое (т.е. за постоянное время) обращение к версии по ее локальному номеру: мы можем просто прочитать файл индекса до определенной позиции (которая вычисляется как «длина записи в индексе умноженная на номер версии») для нахождения нужных данных. Разделение индекса и данных также означает, что мы можем быстро прочитать данные индекса без необходимости поиска по диску по всему файлу данных.
Смещение фрагмента и длина фрагмента указывают на фрагмент файла данных, который нужно прочитать, чтобы получить сжатые данные для данной версии. Интересно то, как определяется, когда нужно сохранить новую базовую версию. Это решение основывается на сравнении совокупного размера изменений и размера несжатой версии (данные сжимаются при помощи zlib, чтобы занимать на диске еще меньше места). Ограничивая таким образом размер цепочки изменений, мы точно знаем, что восстановление данных для конкретной версии не потребует чтения слишком большого количества информации об изменениях.
Поле «связанные версии» используется для того, чтобы зависящий revlog указывал на revlog более высокого уровня (подробнее об этом будет рассказано далее), родительские версии хранятся с указанием локального целочисленного номера версии. Опять же это делает простым поиск соответствующих данных через revlog. Хэш используется для хранения уникального идентификатора конкретного внесенного изменения. Мы используем 32 байта вместо 20 байт, требуемых для SHA1, для поддержки возможных изменений в будущем.
12.2.3. Три revlog
Основная структура данных истории хранится в revlog, на ее основе мы можем создать модель данных для нашей файловой структуры. Модель состоит из трех типов revlog: лог изменений, манифесты и файловый лог. Лог изменений содержит метаданные для каждой версии с указателем на манифест (то есть с идентификатором узла одной версии в манифесте). В свою очередь манифест представляет собой список имен файлов, каждому из которых сопоставлен идентификатор узла, указывающий на версию в файловом логе. В коде у нас созданы классы для лога изменений, манифеста и файлового лога, каждый из которых является потомком общего класса revlog, что понятно отражает обе концепции.
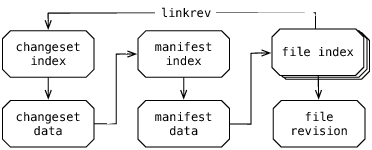
Рис.12.2: Структура лога
Версия лога изменений выглядит следующим образом:
0a773e3480fe58d62dcc67bd9f7380d6403e26fa Dirkjan Ochtman <dirkjan@ochtman.nl> 1276097267 -7200 mercurial/discovery.py discovery: fix description line
Эти данные вы получаете из слоя revlog; слой лога изменений превращает его в простой список значений. Первая строка содержит хэш манифеста, затем идет имя автора, дата и время (в форме метки времени Unix и смещения временной зоны), список затронутых файлов и сообщение с описанием. Здесь скрыта одна вещь: мы разрешаем добавление произвольных метаданных в лог изменений, и для того, чтобы сохранить обратную совместимость, эти данные идут после метки времени. Затем идет манифест:
.hgignore\x006d2dc16e96ab48b2fcca44f7e9f4b8c3289cb701 .hgsigs\x00de81f258b33189c609d299fd605e6c72182d7359 .hgtags\x00b174a4a4813ddd89c1d2f88878e05acc58263efa CONTRIBUTORS\x007c8afb9501740a450c549b4b1f002c803c45193a COPYING\x005ac863e17c7035f1d11828d848fb2ca450d89794 …
Это версия манифеста, на которую указывает изменение 0a773e (интерфейс пользователя Mercurial позволяет сокращать идентификатор до любого префикса, по которому можно однозначно идентифицировать данные). Это простой список всех файлов в дереве, один файл в каждой строке, где после имени файла идет нулевой байт, затем шестнадцатиричный идентификатор узла, который указывает на файловый лог данного файла. Директории в дереве представлены не отдельно, а просто подразумеваются за счет слэшей в путях. Помните, что изменения в манифесте хранятся в хранилище аналогично любому другому revlog, поэтому данная структура дает возможность легко слою revlog хранить только измененные файлы и их новые хэши для любой новой версии. Манифест обычно представлен структурой данных типа «таблица хэшированных значений» в коде Python, при этом имена файлов являются ключами, а узлы — значениями.
Третий тип revlog — это файловый лог. Файловые логи хранятся во внутренней папке Mercurial под названием store, при этом они называются практически также, как и файлы, которые они отслеживают. Имена немного кодируются, чтобы сохранить кроссплатформенность между основными операционными системами. Например, нам приходится иметь дело с зависимостью от регистра символов в названии файлов и папок на Windows и Mac OS X, неразрешенными именами файлов в Windows и различными кодировками, используемыми в разных файловых системах. Как вы можете себе представить, сделать надежной кроссплатформенную работу довольно сложно. С другой стороны содержимое версии файлового лога не настолько интересно: просто содержимое файла плюс некоторые дополнительные префиксы метаданных (которые мы используем для отслеживания копий файлов и файлов с тем же именем, помимо прочего).
Эта модель дает нам полный доступ к хранилищу данных в репозитории Mercurial, но она не всегда является очень удобной. В то время как реальная используемая модель ориентирована вертикально (один файловый лог на файл), разработчики Mercurial часто понимают, что им хотелось бы работать со всеми деталями из одной версии кода: они начинают с изменений из лога изменений и им нужен простой доступ к манифесту и файловому логу из той же версии. Позже был добавлен новый набор классов, по иерархии располагающийся поверх revlog. Так появились контексты.
Одним из преимуществ существующего способа создания отдельных revlog является очередность их создания. Сначала добавляется информация в файловый лог, затем в манифест, наконец, в лог изменений, поэтому данные в репозитории всегда в целостном состоянии. Любой процесс, начинающий читать лог изменений, может быть уверен в том, что все указатели на другие revlog валидны, это снимает множество проблем в этой области. Однако, в Mercurial есть несколько явных блокировок для предотвращения параллельного добавления данных в revlog двумя процессами.
12.2.4. Рабочая копия
Последняя важная структура данных называется dirstate. Dirstate по сути является представлением того, что находится в рабочей папке в каждый момент времени. Более того, в ней отслеживаются изменения того, какая версия кода была отправлена: это отправная точка для всех сравнений при помощи команд status или diff, кроме того она определяет родительскую версию (или версии) для следующих изменений, которые будет закоммичены. В dirstate будет создан набор из двух родителей каждый раз, когда будет применена команда merge с целью объединить одни изменения с другими.
Так как команды status и diff являются очень распространенными (они помогают отслеживать прогресс в том, что у вас есть сейчас по сравнению с предыдущими изменениями), dirstate также содержит кэш состояния рабочей копии с последнего раза, когда она была прочитана Mercurial. Отслеживание времени последней модификации и размеров файлов позволяет ускорить обход структуры файлов. Нам также неоходимо отслеживать состояние файла: был ли он добавлен, удален или объединен в рабочей директории. Это также позволит ускорить обход рабочей копии и упростит получение данной информации в момент коммита изменения.
Продолжение статьи: Механизм контроля версий.