





Библиотека сайта rus-linux.net
Распределенная файловая система Hadoop
Глава 8 из книги "Архитектура приложений с открытым исходным кодом", том 1.
Оригинал: The Hadoop Distributed File System
Авторы: Robert Chansler, Hairong Kuang, Sanjay Radia, Konstantin Shvachko, Suresh Srinivas
Дата публикации: 7 Июля 2012 г.
Перевод: А.Панин
Дата перевода: 8 Апреля 2013 г.
8.3. Операции ввода/вывода и управление копиями блоков
Конечно же, задачей файловой системы является хранение данных в файлах. Для понимания того, как эта задача реализуется файловой системой HDFS, нам следует рассмотреть процесс чтения и записи, а также процесс управления блоками данных.
8.3.1. Чтение и запись файлов
Приложение добавляет данные в файловую систему HDFS, создавая новый файл и записывая данные в него. После того, как файл закрывается, записанные байты не могут быть изменены или удалены, за исключением случаев, когда новые данные могут быть добавлены в файл после его повторного открытия для дополнения. Файловая система HDFS реализует модель, в рамках которой может функционировать один записывающий и множество читающих данные процессов.
Клиент HDFS, открывающий файл для записи, получает файл в свое полное распоряжение; ни один из других клиентов не сможет осуществить запись в этот файл. Записывающий данные клиент периодически подтверждает актуальность процесса модификации файла, отправляя сообщения о состоянии серверу метаданных. Когда файл закрывается, блокировка записи другими процессами снимается. Длительность блокировки записи другими процессами ограничивается мягким и жестким лимитами времени. До того, как мягкий лимит времени истекает, для записывающего данные процесса гарантируется эксклюзивный доступ к файлу. Если мягкий лимит времени истечет и клиент не закроет файл и не подтвердит блокировку с помощью сообщения о состоянии, блокировка может быть установлена для другого клиента. Если по истечении жесткого лимита времени (длительностью в один час) клиент не подтвердит блокировку, файловая система HDFS посчитает, что клиент завершил свою работу и автоматически закроет файл вместо клиента, устранив блокировку. Блокировка файла записывающим данные процессом не запрещает другим клиентам читать файл; файл может читаться параллельно множеством процессов.
В файловой системе HDFS файл состоит из блоков. Когда требуется новый блок, сервер метаданных резервирует блок с уникальным идентификатором и создает список серверов данных приложений для хранения копий блока. Серверы данных приложений формируют канал для передачи данных в порядке, который минимизирует общую дистанцию от клиента до наиболее удаленного сервера данных приложений. Байты передаются в канал в виде последовательности пакетов. Байты, которые приложение записывает в файл, в первую очередь подвергаются буферизации на стороне клиента. После заполнения буфера пакета (обычно размером в 64 КБ) данные передаются в канал. Следующий пакет может быть передан в канал перед приемом подтверждения доставки предыдущих пакетов. Количество не доставленных пакетов ограничивается размером окна для пакетов на стороне клиента.
После того, как все данные записаны в файл HDFS, файловая система не предоставляет никаких гарантий, что данные будут доступны новым процессам, открывающим файл для чтения, до момента его закрытия. Если пользовательскому приложению требуется гарантия того, что данные будут доступны для чтения, оно может явно выполнить операцию hflush. После этого текущий пакет немедленно отправляется в канал для передачи данных и операция hflush будет ожидать того момента, когда все серверы данных приложений, использующие канал, подтвердят успешный прием пакета. После этого все данные, записанные перед выполнением операции hflush, будут гарантированно доступны для чтения.
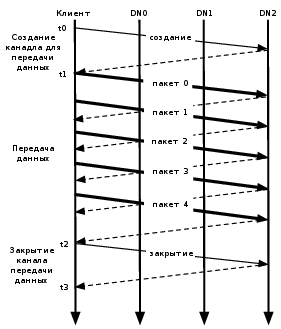
Рисунок 8.2: Состояние канала передачи данных во время записи блока
В случае отсутствия ошибок создание блока происходит в течение трех стадий, так, как показано на Рисунке 8.2, иллюстрирующем канал передачи данных из трех серверов данных приложений (DN) и блока из пяти пакетов. На рисунке с помощью жирных линий изображены пакеты данных, с помощью штриховых - сообщения для подтверждения передачи, а с помощью обычных линий - управляющие сообщения для создания и закрытия канала. Вертикальные линии отображают активность клиента и трех серверов данных приложений, причем время отсчитывается сверху вниз. В течение промежутка времени от t0 до t1 длится стадия создания канала для передачи данных. В интервале времени от t1 до t2 - стадия передачи данных, где t1 является временем отправки первого пакета, а t2 - время приема подтверждения доставки последнего пакета. В данном случае при передаче пакета 2 используется операция hflush. Указатель использования операции hflush передается с данными пакета и не используется в составе отдельной операции. Последний интервал времени от t2 до t3 соответствует стадии закрытия канала передачи данных для этого блока.
В кластере из тысяч серверов выходы из строя серверов (чаще всего из-за выхода из строя устройства хранения данных) случаются ежедневно. Копии блоков, хранящиеся на сервере данных приложений, могут быть повреждены из-за неисправностей оперативной памяти, диска или сети. Файловая система HDFS генерирует и хранит контрольные суммы для каждого из блоков данных файла HDFS. Контрольные суммы сверяются клиентом HDFS во время чтения файла для установления факта любого повреждения, вызванного клиентом и серверами данных приложений, либо сетью. Когда клиент создает файл HDFS, он вычисляет последовательность контрольных сумм для каждого блока и отправляет их серверу данных приложений вместе с данными. Сервер данных приложений сохраняет контрольные суммы в отдельном от блока данных файле метаданных. Когда HDFS читает файл, контрольные суммы каждого блока доставляются клиенту. Клиент вычисляет контрольную сумму принятых данных и проверяет, совпадают ли полученные контрольные суммы с рассчитанными. Если контрольные суммы не совпадают, клиент сообщает серверу метаданных о поврежденной копии блока, после чего принимает другую копию блока от другого сервера данных приложений.
Когда клиент открывает файл для чтения, он получает список блоков и данные о размещении каждой из копий блоков от сервера метаданных. Данные о размещении каждого блока расположены в зависимости от их дистанции от сервера, на котором осуществляется чтение. При чтении содержимого блока клиент в первую очередь пробует принять наиболее близко расположенную копию. Если попытка чтения не удается, клиент попытается прочитать следующую копию из последовательности. Чтение может завершиться неудачей в случае, если целевой сервер данных приложений не доступен, сервер больше не хранит копию блока или копия блока считается поврежденной после сравнения контрольных сумм.
Файловая система позволяет клиенту читать открытый для записи файл. При чтении открытого для записи файла длина последнего все еще записываемого блока неизвестна серверу метаданных. В этом случае клиент получает данные одной из копий для получения последнего значения размера перед началом чтения содержимого.
Архитектура системы ввода/вывода файловой системы HDFS особым образом оптимизирована для систем последовательной обработки, таких, как MapReduce, требующих высокой скорости передачи данных при последующих операциях чтения и записи. Продолжающиеся оптимизации должны улучшить время чтения/записи для приложений, требующих передачи данных в реальном времени или случайного доступа к данным.
8.3.2. Размещение блоков
При создании кластера большого размера использование плоской топологии для соединения серверов может оказаться непрактичным. Обычной практикой является установка серверов в множестве стоек. Серверы в стойке совместно используют свитч, а свитчи стоек соединены с помощью одного или нескольких центральных свитчей. Взаимодействие двух серверов из различных стоек происходит в результате преодоления данными множества свитчей. В большинстве случаев трафик между серверами из одной стойки превышает трафик между серверами из разных стоек. На Рисунке 8.3 изображен кластер, состоящий из двух стоек, каждая из которых содержит по три сервера.
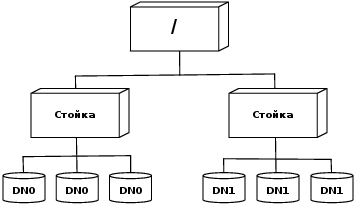
Рисунок 8.3. Топология кластера
Файловая система HDFS оценивает интенсивность трафика между двумя серверами на основании их удаления друг от друга. Удаление сервера от своего родительского сервера принимается за единицу отсчета. Расстояние между двумя серверами может быть рассчитано как сумма расстояний до их ближайших родительских серверов. Более короткое расстояние между двумя серверами подразумевает возможность повышения интенсивности трафика.
Файловая система позволяет администратору использовать сценарий, который будет возвращать информацию о принадлежности сервера к стойке на основе адреса этого сервера. Сервер метаданных является центральной точкой определения расположения стойки для каждого сервера данных приложений. Когда происходит регистрация сервера данных приложений сервером метаданных, данный сервер выполняет сценарий для определения принадлежности сервера данных приложений к конкретной стойке. Если такой сценарий не используется, сервер метаданных считает, что все серверы данных приложений расположены в одной стандартной стойке.
Размещение копий блоков является критичным параметром для надежности хранения данных и скорости чтения и записи файловой системы HDFS. Удачная политика размещения копий блоков должна улучшить надежность хранения данных, доступность данных и оптимизировать использование сети. На данный момент HDFS предоставляет интерфейс настройки политики размещения блоков, поэтому пользователи и исследователи могут экспериментировать и тестировать альтернативные политики, оптимальные для их приложений.
Стандартная политика размещения блоков HDFS является компромиссным решением, обеспечивающим баланс между минимизацией затрат ресурсов для записи данных и максимизацией доступности данных, надежности их хранения и общей скоростью чтения. При создании нового блока HDFS размещает первый блок на том сервере, на котором выполняется осуществляющий запись процесс. Вторая и третья копии располагаются на двух различных серверах в другой стойке. Остальные копии размещаются на случайных серверах с учетом условий, согласно которым на каждом сервере может располагаться не более одной копии блока и не более двух копий могут располагаться на серверах одной стойки, если это возможно. Выбор для размещения второй и третьей копии блока различных серверов обуславливает лучшее распространение копий блоков одного файла в пределах кластера. Если две первые копии блоков файла располагаются на серверах одной и той же стойки, то для любого файла две трети копий блока будут также располагаться на серверах одной стойки.
После того, как выбраны все целевые серверы, между ними организуется канал передачи данных с учетом их удаления от сервера с первой копией блока. Данные передаются всем серверам в заданной последовательности. Для чтения данных сервер метаданных в первую очередь проверяет, находится ли клиентский узел в рамках кластера. Если это условие выполняется, информация о расположении блоков, отсортированная по близости к узлу, на котором осуществляется чтение данных, передается клиенту. Чтение блока с серверов данных приложений осуществляется в этом же порядке.
Эта политика позволяет снизить интенсивность трафика между стойками и между узлами и в общем случае повысить скорость записи данных. Так как вероятность выхода из строя стойки значительно ниже вероятности выхода из строя сервера, эта политика не влияет на гарантии сохранности и доступности данных. В обычном случае использования трех копий данная политика позволяет снизить суммарную интенсивность трафика при чтении данных, так как блок располагается только на серверах из двух различных стоек вместо трех.
8.3.3. Управление репликацией
Сервер метаданных пытается убедиться в том, что каждый блок всегда имеет заданное количество копий. Он устанавливает факт недостатка копий или наличия излишних копий в момент доставки отчета о блоках от серверов данных приложений. В случаях, когда блок имеет лишние копии, сервер метаданных выбирает копию для удаления. Он предпочтет не сокращать количество стоек, на которых хранятся копии, а также предпочтет удалить копию с того сервера данных приложений, на котором наименьшее количество доступного дискового пространства. Целью данной политики является балансировка использования устройств хранения данных серверов данных приложений без снижения доступности блоков.
Когда количество копий блока становится недостаточным, он попадает в очередь приоритетной репликации. Блок только с одной копией имеет наивысший приоритет, а блок с несколькими копиями, составляющими более двух третьих необходимого объема репликации - низший. Программный поток, работающий в фоновом режиме, периодически сканирует начало очереди репликации для принятия решения о том, где размещать новые копии. Процесс репликации блоков использует простую политику размещения новых копий блоков. Если доступна одна копия блока, HDFS размещает следующую копию на сервере из другой стойки. В случае, когда блок имеет две доступных копии, если две существующие копии находятся на серверах одной стойки, третья копия создается на сервере из другой стойки; в противном случае третья копия размещается на другом сервере той же стойки, используемой существующей копией. В данном случае целью политики является снижение затрат ресурсов на создание новых копий.
Сервер метаданных также осуществляет контроль с целью недопущения размещения всех копий блока на серверах одной стойки. Если сервер метаданных устанавливает факт размещения всех копий блока на серверах одной стойки, он считает, что у блока недостаточно копий и создает копию блока на сервере из другой стойки, используя такую же политику размещения блоков, описанную выше. После того, как сервер метаданных получает уведомление о завершении создания копии, блок считается подвергнутым излишней репликации. Впоследствии сервер метаданных решает удалить старую копию, так как политика управления копиями предусматривает действия, не направленные на снижение количества серверов с копиями блоков в различных стойках.
8.3.4. Балансировщик
Стратегия размещения блоков файловой системы HDFS не учитывает использование дискового пространства серверами данных приложений. Она используется для запрета размещения новых, наиболее вероятно используемых, данных на небольшом множестве серверов данных приложений с большим количеством свободного дискового пространства. Следовательно, данные могут не всегда равномерно размещаться на серверах данных приложений. Дисбаланс также возникает при добавлении новых серверов в кластер.
Балансировщик является инструментом, позволяющим достигать равномерного использования дискового пространства серверами кластера HDFS. В качестве исходных данных используется пороговое значение, являющееся дробным числом из диапазона от 0 до 1. Кластер считается сбалансированным в том случае, когда степень использования диска каждого сервера данных приложений3 отличается от степени использования диска всеми серверами кластера4 не больше, чем на пороговое значение.
Данный инструмент функционирует в виде приложения, которое может быть запущено администратором кластера. Оно последовательно перемещает копии блоков с серверов данных приложений, на которых чрезмерно используется дисковое пространство, на сервера данных приложений, дисковое пространство которых не используется в достаточной мере. Единственным ключевым требованием к балансировщику является поддержание доступности данных. При выборе копии для перемещения и определении направления перемещения, балансировщик гарантирует, что данное решение не снизит количество копий блока и не уменьшит количество стоек, используемых серверами для хранения копий.
Балансировщик оптимизирует процесс перемещения данных, минимизируя копирование данных между серверами из различных стоек. Если балансировщик решает, что копия A должна быть перемещена на сервер в другой стойке и сервер из этой стойки уже содержит копию B этого же блока, будет использована копия B вместо копии A.
Параметр настройки ограничивает интенсивность трафика, генерируемого в ходе операций ребалансировки. Чем выше интенсивность трафика, тем быстрее кластер достигнет сбалансированного состояния, но это происходит в ущерб скорости работы приложений.
8.3.5. Сканер блоков
На каждом сервере данных приложений работает сканер блоков, который периодически сканирует хранящиеся на сервере копии блоков и проверяет соответствие данных блоков их сохраненным контрольным суммам. В течение каждого периода сканирования сканер блоков устанавливает допустимую интенсивность трафика для завершения процесса проверки блоков в течение заданного периода времени. Если клиент читает блок полностью и проверка его данных на соответствие контрольной сумме завершается успешно, он информирует об этом сервер данных приложений. После этого сервер данных приложений считает, что проверка блока прошла успешно.
Время проверки каждого блока сохраняется в журнале событий в понятном человеку формате. В любой момент времени в директории верхнего уровня сервера данных приложений хранится до двух файлов, являющихся используемым в данный момент и ранее журналами событий. Новые записи о времени проверки добавляются в используемый файл журнала событий. Соответственно, каждый сервер данных приложений хранит в памяти список копий блоков для сканирования, отсортированный по времени их последней проверки.
Всякий раз, когда читающий данные клиент или сканер блоков обнаруживает поврежденный блок, он оповещает об этом сервер метаданных. Сервер метаданных отмечает копию как поврежденную, но не планирует удаление этой копии незамедлительно. Вместо этого он начинает репликацию неповрежденной копии блока. Только тогда, когда количество неповрежденных копий блока достигает необходимого количества для данного блока, планируется удаление поврежденной копии. Целью этой политики является сохранение данных в течение такого долгого периода, как это возможно. Таким образом, даже если все копии блока будут повреждены, используемая политика позволит пользователю получить поврежденные данные копий.
8.3.6. Прекращение эксплуатации серверов данных приложений
Администратор кластера формирует список серверов, которые должны быть выведены из эксплуатации. Как только сервер помечен как выводимый из эксплуатации, он не будет использоваться для размещения новых копий блоков, но будет продолжать обслуживать запросы на чтение блоков. Сервер метаданных начнет планирование репликации блоков выводимого из эксплуатации сервера на другие серверы данных приложений. Как только сервер метаданных установит, что все блоки выводимого из эксплуатации сервера скопированы, сервер будет выведен из эксплуатации. После этого он может быть безопасно удален из кластера, что не приведет к риску снижения доступности данных.
8.3.7. Копирование данных между кластерами
При работе с большими наборами данных, перспективы копирования данных из кластера и в кластер HDFS приводят в уныние. Файловая система HDFS предоставляет инструмент под названием DistCp для копирования больших объемов данных внутри и вне кластера в параллельном режиме. Это задача системы MapReduce; каждый из процессов данной системы копирует часть исходных данных в целевую файловую систему. Фреймворк MapReduce автоматически производит планирование выполнения параллельных задач, обработку ошибок и восстановление работоспособности.
Далее: 8.4. Практическое использование файловой системы в компании Yahoo!