





Библиотека сайта rus-linux.net
Проект Graphite
Глава 7 из книги "Архитектура приложений с открытым исходным кодом", том 1.
Оригинал: Graphite,
глава из книги "The Architecture of Open Source Applications" том 1.
Автор: Chris Davis
Перевод: Н.Ромоданов
7.5. Очевидное узкое место
Как только мои пользователи начали создавать панели управления, у Graphite быстро появились проблемы с производительностью. Я проанализировал журналы веб-сервера с тем, чтобы увидеть, какие запросы тянут систему на дно. Абсолютно очевидно, что проблема была в запросе огромного количества графиков. Веб-приложение сильно загружало центральный процессор, постоянно рисуя графики. Я заметил, что было масса идентичных запросов и виной тому были панели управления.
Представьте себе, что у вас есть панель управления с десятью графиками, и страница обновляется каждую минуту. Каждый раз, когда пользователь открывает в браузере панель управления, Graphite должен обработать за минуту еще на 10 запросов больше. Это быстро становится затратным.
Простым решением было рисовать каждый график только один раз, а затем каждому пользователю отправлять его копию. Веб-фреймворк Django (на котором был построен проект Graphite) предоставляет замечательный механизм кэширования, в котором можно использовать различные серверные решения, например, memcached. Memcached [3] является, в сущности, хеш-таблицей, предоставляемой в виде сетевого сервиса. Клиентские приложения могут получать и устанавливать пары «ключ-значение» точно также, как и в обычной хеш-таблице. Главное преимущество в использовании memcached состоит в том, что результат затратного запроса (например, на визуализацию графика) может быть очень быстро запомнен и позднее может быть найден при обработке последующих запросов. Чтобы навсегда избежать ситуаций с возвратом устаревших графиков, memcached можно сконфигурировать таким образом, чтобы время хранения кэша истекало в течение очень короткого периода времени. Даже если это будет всего лишь несколько секунд, для Graphite это огромное облегчение, поскольку дублирующие запросы распространены очень сильно.
Другим типичным случаем, при котором создается большое количество запросов на визуализацию, является ситуация, когда пользователь настраивает параметры отображения и использует функции в конструкторе пользовательского интерфейса. Каждый раз, когда пользователь что-то изменяет, Graphite должен перерисовать график. В каждом запросе указываются одни и те же данные, поэтому имеет смысл в memcached также поместить данные, которые использовались для визуализации. Это позволяет пользовательскому интерфейсу продолжать реагировать на запросы пользователей, поскольку этап выборки данных пропускается.
7.6. Оптимизация ввода/вывода
Представьте себе, что у вас есть 60000 метрик, которые вы отправляете на ваш сервер Graphite, и для каждой из этих метрик есть одно значение точки данных в течение одной минуты. Вспомните, у каждой метрики в файловой системе есть свой собственный файл whisper. Это означает, что carbon должен каждую минуту выполнять по одной операции записи в 60000 различных файлов. Пока carbon может делать запись в один файл за миллисекунду, он будет справляться с ситуацией. Следующая ситуация отстоит от текущей не так уж далеко, но давайте предположим, что каждую минуту вы должны обновлять 600000 метрик, или ваши метрики обновляются каждую секунду, или, возможно, вы просто не можете себе позволить использовать достаточно быструю память. Независимо от ситуации, предположим, скорость поступающих значений точек данных превышает скорость операций записи, которую может поддерживать ваша память. Как справиться с такой ситуацией?
Большинство современных жёстких дисков имеет медленное время позиционирования [4], т.е. имеет большую задержку между выполнением операций ввода/вывода в двух различных местах на диске в сравнении с записью непрерывной последовательности данных. Это означает, что, чем больше мы делаем непрерывных записей, тем большую производительность мы получаем. Но если у нас тысячи файлов, в которые необходимо часто делать запись, и каждая запись очень мала (одно значение точки данных в whisper занимает всего 12 байтов), то жёсткие диски, несомненно, будут тратить большую часть времени на позиционирование.
Если исходить из условия, что скорость выполнения операций записи имеет сравнительно низкую планку, единственный способ сделать так, чтобы пропускная способность наших значений точек данных превышала эту планку, это записывать значения нескольких точек данных в одной операции записи. Это возможно, поскольку whisper записывает подряд идущие значения точек данных на диск непрерывно друг за другом. Поэтому я добавил в whisper функцию update_many, которая берет список значений точек данных для одной метрики и собирает значения подряд идущих точек данных в одну операцию записи. Даже хотя размер каждой записи становится больше, разница во времени записи десяти значений точек данных (120 байтов) в сравнении с записью значения одной точки данных (12 байтов) незначительна. Можно взять достаточно много значений точек данных прежде, чем размер каждой записи начнет вносить существенную задержку.
Затем я реализовал в carbon механизм буферизации данных. Каждое поступающее значение точки данных отображается в очереди, имеющей имя метрики, и, затем, помещается в эту очередь. Еще один поток циклически проходит по всем очередям и для каждой из них выбирает все значения точек данных и с помощью функции update_many записывает их в соответствующий файл whisper. Если вернуться к приведённому выше примеру, когда у нас есть 600000 метрик, обновляющихся каждую минуту, и наша память может справиться только с одной записью в миллисекунду, то в среднем в каждой очереди может быть приблизительно до 10 значений точек данных. Единственным ресурсом, которым мы за это платим, является память, которой хватает с избытком поскольку каждая точка данных занимает всего несколько байтов.
Эта стратегия позволяет динамически накапливать в буфере столько точек данных, сколько необходимо для поддержки скорости поступающих точек данных, которая может превышать скорость операций ввода/вывода и с которой может справиться ваша память. Хорошим преимуществом такого подхода является то, что он повышает степень устойчивости к временным замедлениям ввода/вывода. Если системе нужно выполнить другую работу по вводу/выводу, не связанную с Graphite, то, скорее всего, скорость операций записи уменьшится, что просто приведет к росту очередей в carbon. Чем больше очереди, тем больше размер записи. Поскольку общая пропускная способность значений точек данных равна скорости операций записи, умноженной на средний размер каждой записи, carbon способен держаться до тех пор, пока для очередей будет достаточно памяти. Механизм очередей в carbon изображён на рис.7.4.
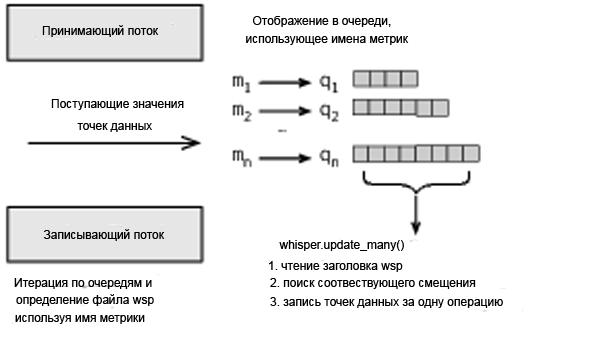
Рис.7.4: Механизм очередей в Carbon
Далее: Все это в режиме реального времени