





Библиотека сайта rus-linux.net
Архитектура приложений с открытым исходным кодом. Том 1. Глава 4. Berkeley DB
Оригинал: "Berkeley DB"Авторы: Margo Seltzer and Keith Bostic
Дата публикации: 2012 г.
Перевод: Н.Ромоданов
Дата перевода: октябрь 2012 г.
4.2. Обзор архитектуры
В этом разделе мы рассмотрим архитектуру библиотеки Berkeley DB, причем начнем с LIBTP и укажем ключевые аспекты ее эволюции.
На рис.4.1, который взят из оригинальной статьи Зельцер и Олсона, показана первоначальная архитектура LIBTP, а на рис.4.2 приведена архитектура Berkeley DB 2.0.
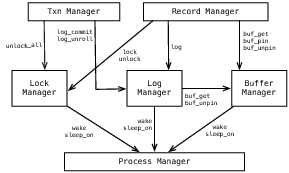
Рис.4.1: Архитектура прототипной системы LIBTP
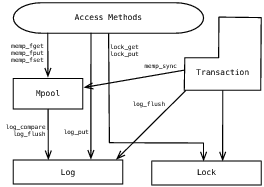
Рис.4.2: Архитектура Berkeley DB-2.0, которую предполагалось реализовать
Единственным существенным различием между реализацией LIBTP и архитектурой Berkeley DB 2.0 было удаление менеджера процессов. Вместо того, чтобы использовать синхронизацию на уровне подсистемы, в LIBTP требовалось, чтобы каждый поток управления регистрировал себя в библиотеке, а затем синхронизировался с отдельными потоками / процессами. Как будет рассказано в разделе 4.4, первоначальная архитектура, возможно, была для нас более предпочтительной.
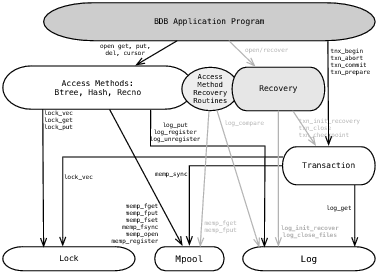
Рис.4.3: Архитектура Berkeley DB 2.0.6, которая была фактически реализована
Различие между проектом и фактической реализацией архитектуры DB-2.0.6, приведенной на рис.4.3, иллюстрирует реальность реализации надежного менеджера восстановлений. Подсистема восстановления показана серым цветом. В ее состав входят как инфраструктура драйверов, находящаяся в блоке «Recovery» («Восстановление»), так и и набор процедур redo и undo, осуществляющих восстановление после операций, выполняемых методами доступа. Они представлены в овале с надписью «Аccess method recovery routines» («Процедуры восстановления действий, выполняемых методами доступа»). В Berkeley DB 2.0 есть единая схема, используемая при восстановлении, в отличие от жестко закодированных процедур журналирования и восстановления для конкретных методов доступа, что было сделано в LIBTP. Такая универсальная схема также позволила создать более богатый интерфейс между различными модулями.
На рис.4.4 проиллюстрирована архитектура Berkeley DB-5.0.21. Цифры на диаграмме указывают интерфейсы API, перечисленные в таблице 4.1. Хотя первоначальная архитектура все еще просматривается, в нынешней архитектуре видно ее развитие благодаря тому, что добавлены новые модули, проведена декомпозиция старых модулей (например, модуль log был преобразован в модули log и dbreg), а также существенно увеличено количество межмодульных API.
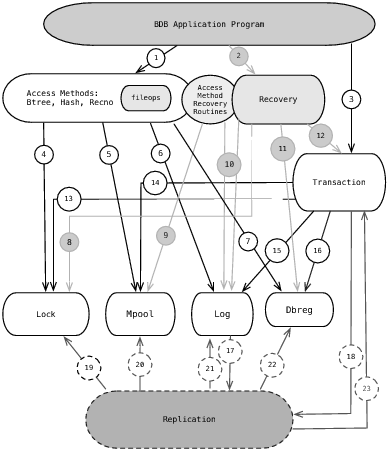
Рис.4.4: Архитектура Berkeley DB-5.0.21
Таблица 4.1: Интерфейсы API в Berkeley DB 5.0.21
| Интерфейсы API для приложений | ||||
|---|---|---|---|---|
| 1. Операции обработки DBP | 2. Восстановление DB_ENV | 3. Транзакционные интерфейсы API | ||
| open | open(… DB_RECOVER …) | DB_ENV->txn_begin | ||
| get | DB_TXN->abort | |||
| put | DB_TXN->commit | |||
| del | DB_TXN->prepare | |||
| cursor | ||||
| Интерфейсы API, используемые в методах доступа | ||||
| 4. Into Lock | 5. Into Mpool | 6. Into Log | 7. Into Dbreg | |
| __lock_downgrade | __memp_nameop | __log_print_record | __dbreg_setup | |
| __lock_vec | __memp_fget | __dbreg_net_id | ||
| __lock_get | __memp_fput | __dbreg_revoke | ||
| __lock_put | __memp_fset | __dbreg_teardown | ||
| __memp_fsync | __dbreg_close_id | |||
| __memp_fopen | __dbreg_log_id | |||
| __memp_fclose | ||||
| __memp_ftruncate | ||||
| __memp_extend_freelist | ||||
| Интерфейсы API процесса восстановления | ||||
| 8. Into Lock | 9. Into Mpool | 10. Into Log | 11. Into Dbreg | 12. Into Txn |
| __lock_getlocker | __memp_fget | __log_compare | __dbreg_close_files | __txn_getckp |
| __lock_get_list | __memp_fput | __log_open | __dbreg_mark_restored | __txn_checkpoint |
| __memp_fset | __log_earliest | __dbreg_init_recover | __txn_reset | |
| __memp_nameop | __log_backup | __txn_recycle_id | ||
| __log_cursor | __txn_findlastckp | |||
| __log_vtruncate | __txn_ckp_read | |||
| Интерфейсы API, используемые модулем транзакций | ||||
| 13. Into Lock | 14. Into Mpool | 15. Into Log | 16. Into Dbreg | |
| __lock_vec | __memp_sync | __log_cursor | __dbreg_invalidate_files | |
| __lock_downgrade | __memp_nameop | __log_current_lsn | __dbreg_close_files | |
| __dbreg_log_files | ||||
| Интерфейс API Into системы репликации | ||||
| 17. From Log | 18. From Txn | |||
| __rep_send_message | __rep_lease_check | |||
| __rep_bulk_message | __rep_txn_applied | |||
| __rep_send_message | ||||
| Интерфейс API From системы репликации | ||||
| 19. Into Lock | 20. Into Mpool | 21. Into Log | 22. Into Dbreg | 23. Into Txn |
| __lock_vec | __memp_fclose | __log_get_stable_lsn | __dbreg_mark_restored | __txn_recycle_id |
| __lock_get | __memp_fget | __log_cursor | __dbreg_invalidate_files | __txn_begin |
| __lock_id | __memp_fput | __log_newfile | __dbreg_close_files | __txn_recover |
| __memp_fsync | __log_flush | __txn_getckp | ||
| __log_rep_put | __txn_updateckp | |||
| __log_zero | ||||
| __log_vtruncate | ||||
Таблица 4.1: Интерфейсы API в Berkeley DB 5.0.21
Спустя более десяти лет эволюции, десятков коммерческих релизов, а также добавления сотен новых функций мы видим, что архитектура стала существенно более сложной, чем ее предшественница. Ключевые моменты, которые необходимо отметить, следующие: во-первых, репликация добавила в систему совершенно новый слой, но это сделано аккуратно, так что взаимодействие с остальной частью системы осуществляется через те же самые API, что и исторически сложившийся код. Во-вторых, модуль log был разделен на модули log и dbreg (регистрация базы данных). Этот вопрос будет более подробно рассмотрен в разделе 4.8. В-третьих, для того, чтобы в приложениях не было коллизий с именами наших функций, мы поместили все межмодульные вызовы в пространство имен, в котором в именах используется предваряющий символ подчеркивания. Мы обсудим этот вопрос в Шестом уроке конструирования.
В-четвертых, сейчас интерфейс API подсистемы журналирования базируется на использовании курсоров (это не интерфейс API log_get, он заменен интерфейсом API log_cursor). Исторически сложилось так, что Berkeley DB никогда в любой момент времени не использовалось более одного потока чтения или записи журнала, поэтому в библиотеке имелось только одно понятие текущего указателя поиска в журнале. С точки зрения абстрагирования это никогда не считалось хорошим решением, но при наичии репликации оно стало неприемлемым. Точно также, как в интерфейсе приложений API поддерживается итерация с использованием курсоров, так и в журнале теперь итерация выполняется с применением курсоров. В-пятых, модуль fileop, входящий в состав модулей доступа, обеспечивает в транзакционно защищенной базе данных поддержку операций создания, удаления и переименования. Нам потребовалось много попыток с тем, чтобы сделать реализацию приемлемой (она еще не так аккуратна, как этого бы хотелось), а после переделок ее в течение длительного времени мы выделили ее в отдельный модуль.
Второй урок конструирования
Программный проект является просто одним из нескольких способов, которые заставляют вас подумать о всей проблеме в целом прежде, чем вы ее пытаетесь решить. Опытные программисты для этого используют различные методики: некоторые пишут первую версию и выбрасывают ее, некоторые пишут множество страниц руководств или проектной документации, другие заполняют некоторый шаблон, в котором каждое требование определяется, назначается определенной функции или комментируется. Например, в Berkeley DB, мы прежде, чем писать какой-либо код, создавали полный набор справочных страниц в стиле Unix для всех методов доступа и для всех компонентов, лежащих в их основе. Вне зависимости от используемой методики, трудно ясно разобраться в архитектуре программы после того, как начинается отладка кода, не говоря уже о том, что трудно делать крупные изменения в архитектуре, при которых часто зря пропадают усилия, ранее затраченные на отладку. Создание архитектуры программы требует другого склада ума, отличающегося от того, который нужен при отладке кода, и архитектура, которая у вас есть к моменту, когда вы начинаете отладку, как правило, именно та, которую вы реализовали в конкретной версии.
Почему вся архитектура библиотека транзакций собрана из компонентов, а не заточена на один из вариантов предполагаемого использования? На этот вопрос есть три ответа. Во-первых, это повышает дисциплину проектирования. Во-вторых, без четко определенных границ в коде сложные программные пакеты неизбежно выродятся в груду кода, который невозможно будет поддерживать. В-третьих, вы никогда не можете предвидеть все способы использования клиентами вашего программного обеспечения; если вы предоставите пользователям больше возможностей, позволив им получать доступ к компонентам, они будут пользоваться ими так, как вы никогда на это не рассчитывали.
В следующих разделах мы рассмотрим все компоненты Berkeley DB, разберемся, что они делают и как они вписываются в общую картину.
| Назад | К оглавлению книги | Вперед |