





Библиотека сайта rus-linux.net
DjVu: Краткое техническое введение
Yann LeCun http://yann.lecun.com/
Léon Bottou http://www.research.att.com/~leonb
Patrick Haffner http://www.research.att.com/~haffner
Иван Зенков zenkov@linux-online.ru
Методика сжатия и программная платформа для публикации сканированных и цифровых документов, а также высококачественного изображения в сети Интернет.
Примечание:
Всё, что идёт ниже написано как раз самими авторами и взято мной с официального сайта DjVuLibre. Давайте вы всё это почитаете, а потом мы уже более подробно всё рассмотрим. В принципе то, что написали Yann, Léon и Patrick уже правда, но она требует некоторых пояснений.
Несмотря на растущую важность Интернета, большая часть знаний в виде культурного и образовательного материала уже существующего сегодня, всё ещё доступна лишь в бумажной форме. Внедрение данного информационного богатства в цифровую область, в схожем с оригиналом виде, с лёгким доступом и поиском, является основным шагом к созданию Всемирной Интернет Библиотеки.
DjVu (произносится как "дэжа вю") это технология сжатия, файловый формат и универсальная платформа специально спроектированная для создания цифровых библиотек на основе печатного, сканированного или цифрового материала. Так например для сканированного документа, размер DjVu файла обычно в 3-10 раз меньше чем чёрно-белый TIFF или PDF и в 5-10 чем цветной JPEG.
Обычная страница из книги, журнала или древней рукописи отсканированная в цвете и 300dpi содержит порядка 8 миллионов пикселей и занимает 24MB в несжатом виде. Традиционные технологии сжатия такие как JPEG обладают следующими минусами:
- Типичные размеры JPEG файла на страницу находятся в рамках между 400KB и 2MB в лучшем качестве, что является абсолютно непригодным для удалённого доступа.
- Острые грани (в символьных структурах) - причина многочисленных потраченных впустую бит и/или неприятных артефактов.
- Большие изображения очень медленно рендрятся, требуя объёмный буфер памяти для распаковки в клиенте, а ещё их проблематично увеличить или распечатать в существующих браузерах.
- Текст обычно не отделяется от изображения и по этому не может быть подвергнут OCR, индексированию и поиску.
- Ничего не сделано для многостраничных документов, потому приходиться формировать изображения в контейнерный формат типа PDF, ещё больше теряя в эффективности.
DjVu избавляет от этих проблем обрабатывая двутональные документы, низкоцветовые (индексированные) изображения, изображения с непрерывным спектром тонов (фотографии и т.д), сканированные цветные и чёрно-белые документы, цифровые документы (например в Postscript или формате PDF).
Двутональные документы закодированы методом JB2 который формирует сжатую библиотеку из повторяемых форм в документе (например символов) и кодирует их место появление на каждой странице. Низкоцветовые изображения сжаты аналогичным путём, с добавлением цветовой палитры и цветового индекса для каждой формы. Изображения с непрерывным спектром тонов сжаты прогрессивным "wavelet-based" методом IW44, равным JPEG-2000 в отношении шумового коэффициента, но чей декодер/рендер более эффективен, занимает меньше памяти и оптимизирован для более быстрой работы (в 3 раза быстрей чем быстрый режим JPEG-2000). Внутренние кодеры обширно используют новый бинарный адаптивный арифметический кодер, названный "Z-coder".
Цветной отсканированный документ разбивается на передний и фоновый план. Передний план содержит текст, линии и кривые сжатые как двутональное или низкоцветовое изображение с максимальным разрешением (используется JB2), сохраняя резкость и удобочитаемость текста. Фоновый план содержит изображения и бумажные текстуры сжатые в уменьшенном разрешении с IW44. Фоновый план, находясь под приоритетными компонентами, сглаживается для уменьшения размера. Сегментатор переднего и фонового плана сначала обнаруживает объекты резко противопоставленные их окружению и затем классифицирует их в передний или фоновый план используя несколько критериев, типа их цветовой однородности, геометрии и веса.
Цифровые PDF и PostScript документы превращаются в список команд рисования нижнего уровня, используя популярный инструментарий GhostScript. Далее этот список транслируется в список форм которые впоследствии классифицируются в передний или фоновый слой используя эвристический анализ. Затем слои сжимаются как сканированные документы.
Двутональные DjVu документы обычно занимают 5-30KB на страницу в 300dpi, что в 3-8 раз меньше чем Group 4 (используемый в Fax машинах, в TIFF файлах и в PDF). Низкоцветовые изображения, например иконки, обычно в 2 раза меньше чем GIF, но могут быть и в 10 раз меньше если содержат много текста. Фотографии в 2 раза меньше чем JPEG и схожи по размеру с JPEG-2000 в быстром режиме для SNR. Интересный аспект "wavelet" кодер-декодера IW44 - то, что он позволяет оперативную декомпрессию/рендеринг области видимой в окне на экрана дисплея (и не больше), если например пользователь увеличивает какие-то фрагменты и балуется с панорамированием. Это позволяет сохранять изображения в сжатой форме в оперативной памяти клиентской машины и отображать больше изображения без требования чрезмерных объёмов памяти. Сканированные цветные и чёрно-белые документы в DjVu обычно занимают 30-100KB на страницу в 300dpi, что в 5-10 раз меньше чем JPEG и около 2-3 раз меньше чем MRC/T.44 или TIFF/FX. Цифровые документы с большим объёмом текста обычно в 1-3 меньше чем PDF или сжатый gzip'ом PostScript в 300dpi, но могут быть и значительно меньше если документ содержит изображения.
DjVu документы могут быть отображены через вэб браузер с помощью очень маленького plug-in'а (доступного для всех основных платформ). Всё в дизайне DjVu было оптимизировано чтобы уменьшить задержку между решением пользователя рассмотреть страницу и её отображением на экране. Многопоточная программная архитектура с умным кэшированием позволяет индивидуальным компонентам документа быть загруженными и преддекодированными по требованию. Страницы загруженные по требованию, дают произвольный доступ без предшествующей загрузки полного документа. Компоненты страницы (передний план, фоновые куски) загружаются последовательно и рендрятся отдельным потоком как только загрузка считается завершённой. Всё это даёт прогрессивный рендеринг и улучшает качество изображения. Страница, которая следует за страницей, в настоящее время отображаемой, предзагружена, преддекодирована и кэширована, посредством чего автоматически уменьшается задержка между перелистыванием страниц. Просмотрщик DjVu файлов обладает своим "независимым" графическим интерфейсом пользователя который позволяет быстро изменять масштаб изображения, панорамирование и зеркальное отражение страницы одним кликом мыши или нажатием клавиши на клавиатуре.
Передний слой может быть подвергнут OCR, а результат внедрён назад в файл DjVu как доступный для поиска уровень "скрытого текста". Существует и соответствующий инструментарий для извлечения такого текста и перевода его в ряд форматов, которые включают каждое слово с координатами его ограничивающего прямоугольника на странице. Форматы также включают структуру документа (страницы, столбцы, параграфы, строки, слова). Гиперссылки, аннотации, эскизы страниц и другие метаданные тоже могут быть внедрены в документы DjVu.
Полнотекстовый поиск на стороне сервера можно легко обеспечить, используя свободные инструментальные средства индексации и несколько скриптов на Perl. Существуют большие DjVu-библиотеки с полнотекстовым поиском доступные через Интернет, такие как "NIPS Proceedings" (http://nips.djvuzone.org, 13 томов, 14,000 страниц в 400dpi, 191MB), "Century Dictionnary" (http://www.century-dictionary.com, 12 томов, свыше 10,000 страниц, 500,000 определений, 22 миллиона поисковых слов, 850MB) наряду с несколькими национальными библиотечными коллекциями и собраниями от коммерческих провайдеров во всём мире. На данный момент в Интернете DjVu используют тысячи пользователей для публикации и обмена отсканированными документами. Список выборочных сайтов использующих DjVu, доступен здесь.
DjVu может рассматриваться как основная открытая платформа для обмена документами так как библиотека DjVu, включая многопоточный декодер/рендер, кодер IW44, кодер палеттизированного изображения, а также кодеры простых двутональных и цветных документов теперь являются свободным программным обеспечением доступным под GNU GPL и могут быть использованы как платформа для разработки новых кодеков, схем сегментации, механизмов передачи данных, интерфейсов просмотрщика и систем контент-анализа.
- Бумаги, примеры, тесты и цели доступы на http://www.djvuzone.org.
- Исходные коды доступы на http://djvu.sourceforge.net.
- Plug-in'ы, компрессоры, SDK и коммерческое программное обеспечение может быть найдено на http://www.djvu.com.
- Сервера которые способны конвертировать почти любой формат в DjVu доступы на http://openlib.djvuzone.org, http://bib2web.djvuzone.org и http://any2djvu.djvuzone.org.
Примечание:
Ну, а теперь как я и обещал пойдёт моя отсебятина.
Для начала наверное было бы неплохо рассказать как я собственно познакомился с этим форматом. Ведь не часто случается, чтобы человек целенаправленно искал какой-то там новый формат. Если он конечно не чокнутый программист помешенный на идеи превратить какой-нибудь обычный GQview в чудо природы мира viewer'ов. Ну разумеется я не чокнутый и судьба GQview меня почти не волнует, я больше как-то читать люблю. Короче я искал книгу, причём точно по какому-то C и о чудо нашёл. Google рулит несказанно, но поиска по DjVu в нём нет, за-то есть поиск по PDF, таким образом я и наткнулся на нечто. Это была огромная библиотека (около 2.4GB) с новыми (2002-2003 гг.) и классическими книгами по физике, математике, программированию и что любопытно большая часть была в каком-то компактном формате, под названием DjVu. То есть уже видел, в смысле переводится как "уже видел", но к тому моменту я о нём ещё не знал. Сделав лёгкое движение рукой в направлении всё того же Google я нашёл проект DjVuLibre и о счастье он оказался свободен, в смысле не отвергнут дамой, а под GPL. Тут то всё и завертелось.
В Gentoo (это у меня дистрибутив такой), в Portage оказалось таки это чудо (в смысле DjVuLibre) и уже через полчаса я его старательно изучал. После этого самого изучения и некоторых экспериментов с кодированием, декодированием (а DjVuLibre это как раз таки и есть набор различного свободного софта по работе с форматом DjVu) я отложил до лучших времён, то есть сегодняшнего дня, несколько воспоминаний и сделал пару долгоживущих выводов. Для начала самое важное и возможно то, что вы уже поняли. DjVu как формат состоит как бы из целых четырёх технологий сжатия:
- DjVuPhoto (то есть IW44): это как вы уже наверное поняли как раз таки сжатие с потерей качества. Потери ощутимые и артефакты присутствуют, правда здесь главное найти золотую середину в настройках и тогда действительно можно получить изображение в несколько раз меньшее чем аналог в JPEG, да и опять же не забывайте про такие вещи как zooming, быструю загрузку (помните сжатое изображение в RAM?) всякое там разное сглаживание. Короче красота одна.
- DjVuBitonal (это JB2): здесь красота разумеется уже другая, красота жёстких линий, китайских иероглифов и индексированного изображения. Как раз это-то нам и нужно ведь именно так и выглядят наши умные заумные книжки. Как правило в тех, что читаю я, чаще всего встречаются символы и схемы. И всё это удаётся сжать до невероятных размеров. Здесь выигрыш у PDF огромный. Опять же OCR, но о нём особо сказать нечего, английский работает прекрасно, больше никаких языков нет. Большой облом. Да и поторопился я с ним, на очереди...
- DjVuDocument: а вот это вообще очень любопытно и по идеи об OCR я бы должен заикнуться здесь. Выглядит всё следующим образом. Сам документ действительно делится на передний и задний слой. Передний как несложно догадаться JB2, а задний IW44. Позже я покажу как всё это выглядит.
- BZZ: это обычное подобие bz2 для "скрытого текста", очень полезная вещь, додумались же умные люди, просто диву даёшься.
Теперь немного подробней попытаюсь технологию рассмотреть или хотя бы наглядно показать. Вот пример того самого замечательного DjVuPhoto, точней даже не пример, а так пузомерка на глаз. Возьмём красивую девочку, чтоб вы знали она весит около 176KB, что вполне нормально для JPEG файла, но слишком много для DjVu. Эта же самая картинка в DjVu уместилась всего в 80KB и это был не придел, просто мне надоело играться с опциями и я решил оставить всё как есть (хотя легко получал экземпляры и в 40KB). Ну и разумеется нет никаких отличий в качестве.
{kind=link}


Первая фотка выше сделана GIMP'ом с GQview, но не думаю, что это играет какую-то роль. Вторая фотка, ручка всё той же леди, только на этот раз в DjVu и снята соответственно с DjVu Viewer всё тем же GIMP'ом. Разумеется, чтобы избежать несоответствия здесь вы видите чистой воды PNG изображения, без какой бы то ни было индексации.
Как говорится найдите десять отличий, но я надеюсь, что вы мне верите на слово, а иначе зачем я всё это пишу? Ну дак вот на слово, а слово моё гласит, что DjVu действительно меньше JPEG и точка. Причём чем больше и качественней изображение тем больше будет различие размеров, тем меньше будет DjVu и больше JPEG. Ешё один очень любопытный факт, DjVu действительно очень быстро грузиться, даже если изображение огромное. Намного быстрей всё того же JPEG и прочих известных мне форматов, часто даже HTML файл грузится дольше чем DjVu.
Ну да ладно с IW44 кажется разобрались или хотя бы поняли для чего он нужен и в какой области его следует использовать. На очереди у нас теперь JB2, то есть чёрное и белое. На самом деле с DjVuBitonal у DjVuLibre не всё так гладко. Инструментария явно маловато, а тот, что уже создан позволяет лишь то малое, что вообще можно провернуть. Остаётся надеяться на коммерческий софт и бесплатные сервисы, речь о которых ещё пойдёт ниже. Вообще JB2 следует использовать действительно по большей части для книг и здесь он мне кажется вообще незаменимым. Этакий удар между ног PDF, куда приятнее чем какие-то там IW44 и JPEG.

Вот например DjVu документ в 300dpi (а на самом деле книга Фредерика Брукса "Мифический Человеко-месяц") созданный мной из PDF файла. При этом как видно на скриншоте качество не испортилось и даже ссылки не потеряли функциональность (жаль курсор не видно, я его как раз на ссылку навёл). Ведь помните, чего только в этот DjVu нельзя запихать в том числе и гиперссылки, о чём уже говорилось многим выше.
Ещё очень любопытное чудо в виде DjVuDocument которое бы мне вам хотелось показать наглядно на примере карты Ирака.
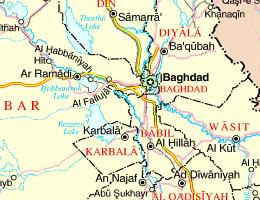
Именно так выглядит обычный Багдад на обычной карте Ирака, в необычном DjVuDocument файле. Что собственно необычного? Ну мы же с вами проходили, помните? Передний план, фоновый план, а вот как это выглядит на деле.
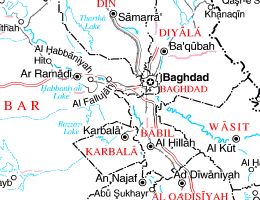
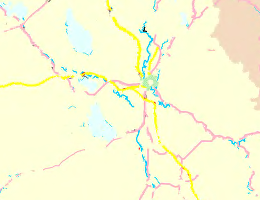
Несложно догадаться где передний, а где фоновый. Передний (первое изображение) сжат JB2 и содержит всё основное, фоновый (второе изображение) сжат IW44 и ничего важного не содержит. Более того, если вы обратили внимание он очень сильно сглажен/сжат, в общем то сделано это специально, для уменьшения размера. На обычном изображении где передний план накладывается на фоновый, данное сглаживание/сжатие не очень то и бросается в глаза, а вот если бы его не было, размер файла вырос бы в два, а то и три раза. Более того обратите внимание как DjVu самостоятельно определил где у изображения важные детали, а где второстепенные. Все эти его хваленные анализы действительно работают, чёрт побери, да ещё как работают. Ни одного названия, или даже символа не уехало на фоновый план. Это просто праздник какой-то.
Остался только BZZ, но о нём особенно нечего сказать, за тем лишь исключением, что в роли "скрытого текста" может выступать и зачастую выступает XML в UTF. Вы же понимаете, что это даёт в перспективе.
Вот в общем то и всё. Чем это самое "всё" смотреть вы наверное уже поняли. В поставку DjVuLibre включён не только plug-in для всех популярных браузеров, всех основных платформ, но и замечательный viewer, а точней программа a la Acrobat Reader и действительно, функциональность практически идентична, а то и на порядок выше благодаря QT. Смотрится шикарно, управление простое, интерфейс приятный, ну может разве иконки немного кривые, ну дак я надеюсь избавятся от них в новых версиях, что-нибудь красивое нарисуют.
Ну, а теперь вас наверное волнует вопрос где бы достать много интересных книг и красивых картинок в этом самом DjVu? Ответ, да нигде вы их не достанете. Нет какие-то коллекции конечно есть, но что-то интересное вы вряд ли найдёте. Вроде бы где-то Гамлета видел отсканированного с книги 19-го века, но не думаю, что вас это особо заинтересует. Что же делать? Выход есть и заключён он в тех самых бесплатных сервисах о которых я ещё обещал рассказать. Причём действительно полезен один из них, это http://any2djvu.djvuzone.org. Он создан для перевода ряда форматов (практически все графические, PDF, PS и т.д.) в DjVu. На этом можно было бы и остановиться если не одно, но. Там есть очень любопытная опция позволяющая не загружать файл на сервер, а скачать файл туда же. То есть например имеем мы увесистый PDF файл (как правило они меньше 3MB не весят), а точней URL на него. Заходим на any2djvu, указываем URL, сервер его скачивает, конвертирует и в нужном нам качестве создаёт DjVu (как правило раза в 3 меньше чем PDF), после чего мы этот маленький DjVu файлик уже самостоятельно скачиваем с any2djvu. Хотите пример из жизни? Вот здесь находятся два огромных PDF файла, они так огромны поскольку состоят из отсканированных страниц. Боюсь соврать, но их вес что-то около 20MB, дак вот any2djvu их быстренько себе скачает (у них там я так понимаю нет проблем ни с трафиком не с оптоволокном) и выдаст нам DjVu файлики по 2-3MB каждый. После этого, согласитесь наша задача значительно облегчена, мы сэкономили свой трафик и своё время (в случае если трафик не имеет значения). Тоже самое можно делать и с изображением. Так например на http://www.deviantart.com/ очень много больших и увесистых картинок, а с any2djvu мы не только уменьшим размер, но ещё и значительно увеличим скорость загрузки. Помните я говорил, что DjVu грузиться гораздо быстрей и надёжней чем JPEG, дак вот у вас будет возможность убедиться в этом лично. Хотите какую-то ещё реальную область применения DjVu? Ну например если у вас большая коллекция порнографии, мы можете уменьшить её объём процентов этак на шестьдесят, используя только программу c44 (входящую в комплект DjVuLibre). А вы думали бесполезная это штука, а она вон сколько пользны принести может.
Ну и напоследок проблема 2000 точней DjVu vs. JPEG-2000. Я уже не знаю насколько это справедливо, я пока ещё не знаком с JPEG-2000, но мне кажется, что это несколько разные вещи. DjVu это скорей конкурент различным извращениям от Adobe, универсальный формат для различной документации, как рукописной так и печатной. Но именно сейчас мне ясно лишь одно, это невероятная вещь заслуживающая должного внимания как со стороны новых разработчиков (GPL NOW!), так и со стороны пользователей. Используя и разрабатывая современные форматы сегодня, мы открываем дверь в завтрашний день и пусть он будет для нас счастливым. Чёрт аж скупая слеза покатилась...
Copyright 2004, Иван Зенков
Данный документ (кроме отдельно указанных частей, переводного текста и др.) распространяется в соответствии с GNU Free Documentation License опубликованной Free Software Foundation и изготовлен в полном соответствии со стандартами w3 консорциума.
Все торговые марки, названия и логотипы использованные или упомянутые в этом документе, принадлежат своим владельцам.
Остальные мои статьи можно найти на моей страничке на сайте Rus-Linux.net