Библиотека сайта rus-linux.net
Что каждый программист должен знать о памяти. Часть 6: На что еще способны программисты
Оригинал: Memory part 6: More things programmers can doАвтор: Ulrich Drepper
Дата публикации: October 31, 2007
Перевод: М.Ульянов
Дата перевода: февраль 2010 г.
6.4 Многопотоковая оптимизация
Говоря о многопоточности, выделяют три разных аспекта использования кэша, на которые следует обращать внимание. Это:
- Параллельный доступ
- Атомарность
- Пропускная способность
Подобное деление справедливо и для многозадачных сценариев, но так как задачи (процессы) обычно выполняются независимо друг от друга, работу с ними не так легко оптимизировать. А возможные способы их оптимизации представляют собой лишь подмножество способов оптимизации многопотоковых сценариев. Поэтому мы будем рассматривать исключительно последние.
Под параллельным (совместным) доступом в нашем случае понимается организация работы с памятью для процессов, выполняющихся в несколько потоков. Одним из свойств потоков является тот факт, что они все используют одно и то же адресное пространство и потому могут получать доступ к одному и тому же участку памяти. В идеале каждый поток использует свою отдельную область памяти, при этом потоки почти не связаны между собой (разве что общими входами/выходами, к примеру). Если несколько потоков одновременно используют одни и те же данные, то необходимо согласование - тут в дело вступает атомарность. Наконец, доступные процессорам память и пропускная способность межпроцессорной шины ограничены типом используемой архитектуры. Ниже мы разберем все эти три аспекта по отдельности — хотя они, конечно же, тесно между собой связаны.
6.4.1 Оптимизация параллельного доступа
Итак, начнем. В данном разделе мы обсудим две различные проблемы, требующие по сути принципально противоположных подходов к оптимизации. Пусть многопотоковое приложение использует общие данные для нескольких потоков. Стандартная оптимизация кэша требует нахождения таких данных в одной кэш-строке, чтобы приложение было компактнее - таким образом максимизируя количество памяти, которое кэш сможет вместить в любой момент времени.
Однако с таким подходом возникает следующая проблема: чтобы несколько потоков могли производить запись в память, строки кэшей L1d соответствующих ядер должны иметь статус ‘E’ (Exclusive). Это означает, что появится множество RFO-запросов, в худшем случае - по запросу на каждую попытку записи. В результате обыкновенная процедура записи внезапно становится очень ресурсоемкой. К тому же, если речь идет об одной и той же области памяти, то тут необходима синхронизация (при этом могут помочь атомарные операции, о них поговорим в следующем разделе). Но проблема остается даже когда все потоки используют разные области памяти и предположительно не зависят друг от друга.
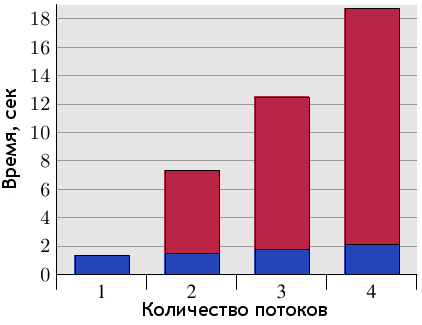
Рисунок 6.10: Задержки при параллельном доступе с использованием общей кэш-строки
Описанная проблема получила название ⌠ложного совместного доступа■. На рисунке 6.10 наглядно показано, чем он опасен. Тестовая программа (см. листинг в разделе 9.3) создает некоторое количество потоков, которые увеличивают значение, хранящееся в памяти, на единицу (500 миллионов раз). Измеряется время, прошедшее с момента запуска программы и до момента ее завершения после того, как последний поток закончит работу. Для теста используется машина с четырьмя процессорами P4, при этом каждый поток закреплен за своим процессором. Синим цветом показаны результаты, когда данные каждого потока обслуживались отдельными кэш-строками. Красный цвет демонстрирует задержки, полученные при использовании одной общей кэш-строки для данных всех потоков.
Результаты, показанные синим цветом (отдельные кэш-строки для каждого потока) в точности совпадают с тем, что обычно ожидается в таких случаях. Программа выполняется в несколько потоков, фактически без потерь. Кэш-строка каждого потока находится в кэше L1d соответствующего процессора и отсутствуют проблемы с пропускной способностью, поскольку нет необходимости считывать большие куски кода или данных (по сути, всё уже кэшировано). А полученное небольшое увеличение во времени объясняется наличием системного шума и, возможно, эффектом упреждающей выборки (ведь потоки используют последовательные кэш-строки).
Задержка в процентном соотношении вычисляется делением времени, потраченного с использованием общей кэш-строки, на время, потраченное с использованием индивидуальных кэш-строк для каждого потока, и составляет 390%, 734% и 1147% соответственно. Настолько большие числа могут поначалу удивить, но если разобраться, как в нашем случае взаимодействуют кэши, всё становится понятно. "Общая" строка выгружается из кэша текущего процессора сразу после окончания записи. И все процессоры, кроме того, в кэше которого на данный момент находится кэш-строка, простаивают и ничего не могут делать. Каждый дополнительный процессор попросту увеличивает время таких простоев.
Естественно, что подобного сценария необходимо избегать при программировании. И хотя в большинстве случаев проблему будет легко определить по огромным задержкам (профилирование как минимум локализует проблему в коде), тут есть свои подводные камни. Один из них - современное аппаратное обеспечение. На рисунке 6.11 показаны те же измерения, только сделанные на машине с одним четырехъядерным процессором (Intel Core 2 QX 6700). Даже с учетом наличия двух раздельных кэшей второго уровня (L2), тест не выявил никаких проблем. При неоднократном использовании одной и той же кэш-строки имеется небольшая задержка, но она не зависит от количества ядер. {Я никак не могу объяснить уменьшение данной задержки при использовании всех четырех ядер, но данный результат легко воспроизводится.} Конечно, при использовании более чем одного такого процессора мы бы получили результаты, схожие с показателями рисунка 6.10. Несмотря на то, что многоядерные процессоры распространяются все шире, многопроцессорные машины пока никуда не денутся, и потому важно корректно обрабатывать вышеприведенный сценарий. А это значит, что придется проверять код на реальных многопроцессорных машинах.
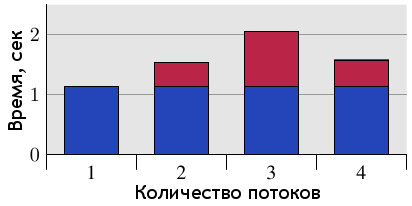
Рисунок 6.11: Задержки при использовании четырехъядерного процессора
Навскидку, простейшее решение проблемы "в лоб": хранить каждую переменную в отдельной строке кэша. И вот здесь проявляется конфликт с первоначально описанным вариантом оптимизации, а именно - ни о какой компактности приложения речи уже не идет, объем занимаемой памяти в кэше сильно увеличится. Это неприемлемо, так что необходимо искать более изящный вариант.
Чтобы его найти, необходимо определить, какие переменные используются только одним потоком в каждый момент времени, какие используются вообще только одним потоком, ну и можно выделить те, к которым нужен совместный доступ лишь временами. Для каждого из этих сценариев возможны самые различные решения. Простейший критерий разделения переменных - ответ на вопрос, происходит ли вообще запись в данную переменную во время работы и если да, то как часто.
Переменные, в которые никогда не происходит запись и которые инициализируются лишь однажды - по сути являются константами. Так как запросы RFO необходимы только для операций записи, то константы можно сделать общими (статус ‘S’). Они не требуют какого-то особого обращения, достаточно просто сгруппировать их вместе. Если корректно пометить нужные переменные как const, то toolchain сам отделит их от "нормальных" переменных и поместит в секции .rodata (данные только для чтения) или .data.rel.ro ("только для чтения" после перемещения). {секции, идентифицируемые по именам - это атомарные единицы, содержащие код и данные в файле ELF} Никаких других действий не потребуется. Если же по каким-то причинам переменные невозможно пометить как const, то на их размещение можно повлиять, объявив такие переменные в специальной секции.
При компоновке итогового исполняемого файла сначала собираются вместе секции с одинаковыми именами из всех входных файлов, затем эти секции располагаются в порядке, определяемом скриптом компоновщика. Это означает, что если все переменные, не помеченные как константы, но по сути являющиеся таковыми, объявлять в специальных (одинаково поименованных) секциях, то такие переменные окажутся сгруппированными вместе. Среди них не окажется переменной, в которую часто происходила бы запись. А выровняв первую переменную в такой секции нужным образом, можно гарантировать защищенность от ложного совместного доступа. Рассмотрим следующий небольшой пример:
int foo = 1;
int bar __attribute__((section(".data.ro"))) = 2;
int baz = 3;
int xyzzy __attribute__((section(".data.ro"))) = 4;
Будучи скомпилированным, такой входной файл определяет четыре переменные. Интересный момент заключается в том, что пары переменных foo и baz, bar и xyzzy соответственно будут сгруппированы вместе. Если бы не были определены атрибуты, компилятор расположил бы все четыре переменные в секции .data, причем в том порядке, в каком они определены в исходном коде. {Это не гарантируется ISO-стандартом для языка C, но тем не менее gcc работает именно так.} Наш же код расположит переменные bar и xyzzy в секции .data.ro. Имя секции, .data.ro, выбрано относительно произвольно. "Относительно" - ибо префикс .data. гарантирует, что компоновщик GNU поместит секцию вместе с другими секциями данных.
Этот же прием можно применить, чтобы выделить переменные "в основном для чтения", т.е. часто читаемые, но в которые редко происходит запись. Просто выберите другое имя секции. Но такое разделение имеет смысл лишь в некоторых случаях, например в ядре Linux.
Если переменная используется только внутри потока, можно использовать другой способ объявления. В этом случае можно и нужно использовать локальные переменные потока (см. [mytls]). Языки C и C++ в gcc позволяют определять переменные как принадлежащие потоку, используя ключевое слово __thread.
int foo = 1; __thread int bar = 2; int baz = 3; __thread int xyzzy = 4;
Переменные bar и xyzzy не будут помещены в обычном сегменте данных. Вместо этого, каждый поток имеет свою отдельную область для хранения таких переменных. Хранящиеся подобным образом переменные могут иметь статические инициализаторы. Все локальные переменные потока адресуемы другими потоками, но пока поток-владелец не передаст им указатель на свою переменную, они никак не смогут ее найти. Поскольку переменная является локальной в пределах данного потока, проблема ложного совместного доступа попросту отсутствует — если, конечно, не создать ее искусственно. Такое решение легко реализовать (всю работу делают компилятор и компоновщик), но и оно имеет свою цену. При создании потока, последнему необходимо инициализировать локальные переменные, а это требует и времени, и памяти. К тому же, адресация локальной переменной потока обычно более ресурсоемка, чем использование глобальных или автоматических переменных (в [mytls] объясняется, как происходит автоматическое снижение ресурсоемкости в случаях, когда это возможно).
Одним из недостатков использования локальной памяти потока (далее TLS = thread-local storage) является тот факт, что если переменная все-таки передается другому потоку, то текущее значение переменной в старом потоке недоступно для нового владельца. У него будет своя копия переменной, не связанная с оригиналом. Обычно это вообще не проблема, но если таки это важно, то передача переменной другому потоку потребует некоторой координации, для копирования текущего значения.
Второй недостаток посерьезней - возможна пустая трата ресурсов. Если переменную использует только один поток в каждый момент времени, все остальные потоки за это расплачиваются памятью. В случае, когда TLS-переменные не используются вообще, проблему решает отложенное ("ленивое") выделение памяти TLS (исключая локальную память в самом приложении). Но при использовании потоком всего одной переменной TLS в разделяемой библиотеке, будет выделена память и для всех остальных TLS-переменных этой библиотеки. При широком использовании переменных TLS это потенциально может вылиться в серьезную проблему.
В целом, можно дать следующие советы:
- Как минимум, разделяйте переменные "только для чтения" (после их инициализации) и "обычные" модифицируемые переменные. Можете также выделить переменные "в основном для чтения" в третью категорию.
- Группируйте модифицируемые переменные, используемые вместе, в структуру. Использование структуры - единственный способ гарантировать при использовании любой версии gcc, что области памяти для этих переменных находятся рядом друг с другом.
- Модифицируемые переменные, в которые часто происходит запись разными потоками, помещайте в отдельную кэш-строку. Место, которое останется в строке, можно заполнить незначащей информацией. В сочетании с шагом 2 это может оказаться отнюдь не столь расточительно, как кажется. Дополнив вышеприведенный пример и полагая, что
barиxyzzyдолжны использоваться вместе, получим следующий код:int foo = 1; int baz = 3; struct { struct al1 { int bar; int xyzzy; }; char pad[CLSIZE - sizeof(struct al1)]; } rwstruct __attribute__((aligned(CLSIZE))) = { { .bar = 2, .xyzzy = 4 } };Понадобятся небольшие исправления в коде (ссылки на
barпоменять наrwstruct.bar, сxyzzyаналогично), но не более того. Компилятор с компоновщиком доделают остальное. {В командной строке этот код необходимо компилировать с-fms-extensions.} - Если переменная используется множеством потоков, но каждый из потоков использует ее независимо от других, помещайте такую переменную в TLS.
6.4.2 Оптимизация работы с атомарными операциями
В ситуации, когда несколько потоков параллельно работают с одной и той же областью памяти, процессоры сами не предпринимают никаких действий и, соответственно, не гарантируют никаких определенных результатов. Это обдуманное и взвешенное решение, принятое с целью избежания затрат, лишних в 99,999% всех случаев. Например, пусть область памяти имеет статус ‘S’ и два потока параллельно пытаются увеличить значение, хранящееся в этой области, на единицу. Исполнительный конвейер не станет ждать, пока кэш-строка получит статус ‘E’, прежде чем считать старое значение. Вместо этого он сразу считывает текущее значение из кэша и, как только кэш-строка получает статус ‘E’, записывает новое значение обратно. Но результат может обмануть ожидания, если операции чтения кэша произойдут в двух потоках одновременно - тогда одно из увеличений будет потеряно.
Для предотвращения таких ситуаций в процессорах предусмотрены так называемые атомарные (неделимые) операции. Эти операции, например, никогда не станут считывать старое значение до тех пор, пока не станет ясно, что увеличение возможно осуществить как атомарное. Помимо ожидания остальных ядер и процессоров, некоторые процессоры даже предупреждают другие устройства материнской платы о таких операциях. Всё это замедляет работу с ними.
Наборы доступных атомарных операций различаются у разных производителей процессоров. Ранние процессоры RISC - где ‘R’ означает reduced, "сокращенный" (о наборе команд) - имели очень мало таких команд, иногда вообще лишь атомарные битовые set и test. {HP Parisc до сих пор только их и поддерживает...}. А на другом конце спектра у нас архитектуры x86 и x86-64 со множеством атомарных инструкций. Основные из них можно разделить на четыре класса:
Bit Test
Эти операции атомарно устанавливают либо сбрасывают бит и возвращают его предыдущее состояние.
Load Lock/Store Conditional (LL/SC) {Иногда предпочитают использовать ⌠linked■ вместо ⌠lock■, это не суть важно.}
Тут у нас сразу пара операций: специальная инструкция загрузки (считывания) используется для начала транзакции, а инструкция сохранения (записи) завершает ее, причем успешное завершение возможно только если во время выполнения не произошло никаких изменений в целевой области. Программа может повторять попытки при необходимости, в зависимости от результата операции сохранения.
Compare-and-Swap (CAS)
Троичная (тернарная) операция "Сравнение и замена" записывает значение (переданное как первый параметр) по адресу (второй параметр), только если текущее значение, хранящееся по этому адресу, равно третьему параметру.
Атомарные арифметические операции
Доступны исключительно на архитектурах x86 и x86-64, которые могут осуществлять арифметические и логические операции над памятью. Эти процессоры поддерживают также и неатомарные версии данных операций, чем не могут похвастаться архитектуры RISC. Поэтому неудивительно, что они так мало распространены.
Любая архитектура может поддерживать либо LL/SC, либо CAS - третьего не дано. Оба подхода по сути эквивалентны, и в равной степени одинаково позволяют реализовывать атомарные арифметические операции. Однако в наши дни чаще предпочитают CAS. Используя эту инструкцию, можно косвенно реализовать все остальные операции. Например, атомарное сложение:
int curval;
int newval;
do {
curval = var;
newval = curval + addend;
} while (CAS(&var, curval, newval));
Значение, возвращенное CAS, показывает, успешно завершилась операция или нет. Если нет (возвращено ненулевое значение), цикл запускается по новой, выполняется сложение и снова проверяется результат вызова CAS. И так до успешного финала. Стоит отметить, что адрес области памяти необходимо вычислять с помощью двух отдельных инструкций. {Операционный код CAS на x86 и x86-64 может пропустить загрузку значения во второй и последующих итерациях, но на той платформе мы вообще сможем всю операцию атомарного сложения записать проще, с использованием лишь одной инструкции.} В случае использования LL/SC код почти не отличается:
int curval;
int newval;
do {
curval = LL(var);
newval = curval + addend;
} while (SC(var, newval));
Здесь мы используем специальную инструкцию загрузки (LL), и при этом нам не нужно передавать в SC текущее значение в памяти, поскольку процессор сам следит, изменялось ли оно во время выполнения программы.
Ситуация сильно меняется в случае x86 и x86-64, поскольку расширяется количество доступных атомарных инструкций, и для получения наилучших результатов очень важно выбрать подходящую. На рисунке 6.12 показаны три различных способа реализации атомарной операции инкремента.
for (i = 0; i < N; ++i) __sync_add_and_fetch(&var,1);1. Произвести сложение и вернуть результат ("сложение с обменом")
for (i = 0; i < N; ++i) __sync_fetch_and_add(&var,1);2. Произвести сложение и вернуть старое значение ("сложение со считыванием")
for (i = 0; i < N; ++i) { long v, n; do { v = var; n = v + 1; } while (!__sync_bool_compare_and_swap(&var, v, n)); }3. Атомарная замена новым значением (с использованием CAS)
Рисунок 6.12: Циклический атомарный инкремент
На x86 и x86-64 после интерпретации во всех трех случаях получится разный код, в то время как на других архитектурах он будет идентичен. В скорости выполнения разница огромна. Следующая таблица демонстрирует, сколько времени заняло выполнение одного миллиона инкрементов четырьмя параллельными потоками. В коде использовались встроенные примитивы gcc (__sync_*).
1. Сложение с обменом 2. Сложение со считыванием 3. CAS 0.23s 0.21s 0.73s
Сравнив первые два числа, видим, что они близки: сложение со считыванием старого значения лишь чуть-чуть быстрее. Но важно здесь то, что мы видим в третьем, выделенном поле - время, затраченное на выполнение с использованием CAS. Оно гораздо больше. Тому есть несколько причин: 1. В коде присутствуют две отдельные операции по работе с памятью; 2. Сама по себе операция CAS более сложна и даже содержит условный переход; 3. Вся операция сложения находится во вложенном цикле на случай, если произойдут две параллельные попытки доступа и CAS вернет ошибку.
Читатель может спросить: "А зачем вообще использовать CAS, если код получается сложнее и длиннее?". Ответ - вся сложность обычно спрятана. Выше упоминалось, что CAS сейчас присутствует во всех интересных архитектурах, по сути служит инструментом унификации. И поэтому люди считают разумным реализовывать все атомарные операции именно через CAS. Это упрощает программы. Но как показывают цифры, это далеко не оптимально с точки зрения производительности. Решения, построенные на CAS, крайне неэффективно обращаются с памятью. Далее показаны алгоритмы выполнения всего лишь двух потоков, каждого на своем отдельном процессоре ("П"):
Поток #1 Поток #2 Статус кэша varv = var‘E’ на П1
n = v + 1
v = var‘S’ на П1+2
CAS(
var)
n = v + 1‘E’ на П1
CAS(
var)‘E’ на П2
Видим, что даже за такой небольшой период статус строки кэша меняется минимум три раза, два из которых - в результате запросов RFO. К тому же, CAS во втором потоке выдаст ошибку, и потоку придется повторить операцию с начала. А пока она будет выполняться, снова может произойти та же ситуация.
Напротив, если использовать атомарные арифметические операции, то считывание и запись данных в память, необходимые для выполнения сложения (или другого действия) будут выполняться процессором последовательно. Гарантируется, что параллельные запросы к строке кэша будут блокированы до окончания выполнения атомарной операции. И тогда каждая итерация цикла в примере приведет максимум к одному запросу RFO, не более того.
Всё это значит, что крайне важно работать на таком уровне абстракции, на котором можно использовать преимущества атомарных арифметических и логических операций. Не стоит повсюду использовать CAS в качестве механизма унификации.
Для большинства процессоров атомарные операции сами по себе всегда атомарны, неделимы. В случае, когда в атомарности нет необходимости, для ее избежания программисту придется изворачиваться, искать "окольные пути". Соответственно, это значит - больше кода, условные и безусловные переходы к прямому выполнению.
С x86 и x86-64 ситуация иная. Одни и те же инструкции можно использовать и как атомарные, и как "обычные". Чтобы сделать их атомарными, используется специальный префикс: lock. Такой подход позволяет не использовать атомарность, когда в ней нет необходимости - и таким образом избежать связанных с ней затрат. Это очень полезно при, например, написании кода общего пользования в библиотеке, ведь такой код всегда должен обеспечивать потоковую безопасность. Причем во время написания кода можно еще не знать, потребуется это или нет, а выбор будет делаться уже при работе программы. Трюк заключается в том, чтобы перепрыгнуть префикс lock, когда нужно, и прием этот реализуем для всех инструкций, с которыми процессоры x86 и x86-64 позволяют использовать данный префикс.
cmpl $0, multiple_threads
je 1f
lock
1: add $1, some_var
Если этот ассемблерный код кажется непонятным, не волнуйтесь. Все просто. Первая инструкция проверяет, равна ли переменная нулю. В данном случае ненулевое значение будет означать, что запущено более одного потока. При нулевом значении вторая инструкция осуществляет переход к метке 1. Иначе просто выполняется следующая инструкция. Вот и весь трюк. Если перехода не было, инструкция add выполняется с префиксом lock. Иначе - без него.
Добавление относительно дорогой (в смысле ресурсов) операции вроде условного перехода (дорогим он становится в случае, когда предсказание переходов дает сбой) может показаться непродуктивным шагом. И несомненно, иногда это так: если большую часть времени идет работа в несколько потоков, то производительность действительно упадет, особенно в случае частых ошибок механизма предсказания переходов. Но если ситуация противоположна и чаще всего выполняется только один поток, такой код будет выполняться значительно быстрее. Альтернативой конструкции if-then-else в обоих случаях может послужить дополнительный безусловный переход. Учитывая, что затраты ресурсов на атомарную операцию соизмеримы с затратами на 200 циклов, можно сказать, что использование такого трюка (или блока if-then-else) часто оправдывает себя, и этот прием стоит иметь в виду. К сожалению, его использование означает невозможность применения примитивов __sync_*, предоставляемых gcc.
6.4.3 Решаем проблемы с пропускной способностью
Использование множества потоков, корректно работающих с кэшем (т.е. исключающих попытки доступа к одной и той же кэш-строке разными ядрами, приводящие к конфликту), не гарантирует отсутствия других проблем. Полоса пропускания канала между процессором и памятью имеет ограниченную ширину, которая к тому же делится между всеми ядрами и гиперпотоками данного процессора. А в зависимости от архитектуры (пример - рисунок 2.1), несколько процессоров также могут иметь общую шину памяти или северного моста.
Ядра современных процессоров работают на таких частотах, что даже работая на максимальной скорости и в идеальных условиях, соединение с памятью не позволяет обслуживать без задержек все запросы считывания и записи. А теперь вдобавок к этому разделите всю полосу пропускания на количество ядер, гиперпотоков и процессоров с общим доступом к северному мосту, и станет ясно, почему многопоточность внезапно может привести к серьезным проблемам. Производительность программ, в теории очень эффективных, на практике может быть ограничена пропускной способностью памяти.
На рисунке 3.32 мы видели, что повышение скорости шины процессора очень помогает в таких случаях. Поэтому с ростом количества ядер в процессорах наблюдается и увеличение скорости системной шины. Однако этого часто недостаточно, особенно если программа использует большие рабочие множества и недостаточно оптимизирована. Поэтому программист должен быть всегда готов распознать проблемы, связанные с пропускной способностью.
Счетчики производительности современных процессоров позволяют следить за загрузкой системной шины. Например, событие NUS_BNR_DRV процессоров Core 2 подсчитывает количество холостых тактов ядра, произошедших по причине неготовности шины. Это показывает, что шина перегружена и операции считывания/записи в основную память выполняются медленнее обычного. Процессорами Core 2 поддерживаются и другие события, позволяющие подсчитывать различные показатели, например запросы RFO или общую загрузку шины. Последнее, например, будет кстати, если при разработке приложения потребуется исследовать возможность его масштабируемости. Ясно, что когда уровень загрузки шины уже близок к единице, возможности масштабирования минимальны.
Допустим, диагноз ясен - проблема с пропускной способностью. Для ее решения существует несколько способов. Иногда они взаимоисключают друг друга, так что, быть может, придется поэкспериментировать. Ну, например, одно из решений - купить более быстрый компьютер, если такой существует. Поскольку это означает рост скорости системной шины и модулей памяти, а также возможное увеличение объема локальной памяти процессора, то такой способ может помочь - да и действительно, чаще всего помогает. Однако, подобное может влететь в копеечку. Конечно, если проблемная программа будет использоваться лишь на одной машине (или на небольшом их количестве), то разовая трата на оборудование может оказаться меньше, чем затраты на переработку программы. Но в абсолютном большинстве случаев лучше таки переделать программу.
Оптимизировав программу во избежание промахов кэша, остается лишь одна возможность уменьшить загрузку полосы пропускания - правильно распределить потоки по доступным ядрам. По умолчанию, планировщик в ядре распределяет потоки в соответствии со своей политикой. Перемещение потока между ядрами по возможности избегается. Тем не менее, планировщик ведь ничего не знает о рабочей нагрузке. Да, он может собирать информацию о промахах кэша и прочем, но в большинстве случаев это малоэффективно.
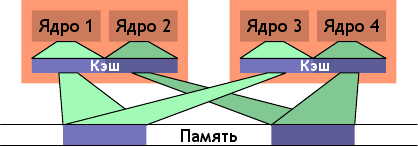
Рисунок 6.13: Нерациональное планирование
Один из вариантов, приводящих к большой загрузке шины - когда два потока выполняются на разных процессорах (или ядрах с разделенным кэшем), но используют при этом один и тот же набор данных. Такая ситуация показана на рисунке 6.13. Ядра 1 и 3 используют одни и те же данные (указатели доступа и области памяти показаны одним цветом). Аналогично для ядер 2 и 4. Но потоки распределены по разным процессорам. То есть каждый набор данных необходимо будет считать из памяти дважды. Эту ситуацию можно исправить.

Рисунок 6.14: Рациональное планирование
На рисунке 6.14 показано, как оно должно выглядеть в идеале. Общий размер используемого кэша уменьшен, так как пары ядер 1 + 2 и ядер 3 + 4 работают каждая со своим набором данных. Соответственно, наборы данных придется считать из памяти всего по разу.
Простой пример, конечно, но данный принцип действительно применим во многих ситуациях. Как упоминалось выше, планировщик в ядре не вникает в суть использования данных, поэтому на плечи программиста ложится задача - гарантировать эффективность планирования. Есть не так уж много интерфейсов ядра, с помощью которых можно выполнить это требование. Фактически, способ только один: использовать привязку потоков.
Под привязкой потоков понимается назначение потока одному или нескольким ядрам. И тогда, если планировщику будет необходимо решить, где запускать поток, он будет выбирать только из этих заданных ядер. Даже если другие ядра свободны, они не будут рассматриваться вообще. Это может показаться недостатком, но ведь всему есть своя цена. Если слишком много потоков привязано к конкретному набору ядер, то другие ядра будут частенько простаивать, и исправить такую ситуацию можно только поменяв привязку. По умолчанию привязка отсутствует, то есть потоки могут выполняться на любом ядре.
Интерфейсы, использующиеся для запросов о привязке и ее изменений, описаны ниже.
#define _GNU_SOURCE #include <sched.h> int sched_setaffinity(pid_t pid, size_t size, const cpu_set_t *cpuset); int sched_getaffinity(pid_t pid, size_t size, cpu_set_t *cpuset);
Эти два интерфейса используются в однопоточном коде. Аргумент pid определяет, привязку какого процесса следует установить или изменить. Естественно, для вызова необходимы соответствующие привилегии. Второй и третий параметры определяют битовую маску для ядер. Первая функция требует заполненную битовую маску для того, чтобы установить привязку. Вторая - заполняет битовую маску информацией о распределении (привязке) выбранного потока. Оба интерфейса объявлены в заголовочном файле <sched.h>.
В том же файле объявлен тип cpu_set_t, а с ним и соответствующие макросы для управления и использования объектов данного типа.
#define _GNU_SOURCE #include <sched.h> #define CPU_SETSIZE #define CPU_SET(cpu, cpusetp) #define CPU_CLR(cpu, cpusetp) #define CPU_ZERO(cpusetp) #define CPU_ISSET(cpu, cpusetp) #define CPU_COUNT(cpusetp)
Константа CPU_SETSIZE определяет максимальное количество процессоров, которое может быть представлено в структуре данных. Следующая тройка макросов используется для управления объектами cpu_set_t. CPU_ZERO инициализирует объект, а оставшаяся пара используется соответственно для включения во множество и исключения из него отдельных ядер либо процессоров. CPU_ISSET проверяет, входит ли процессор во множество, а CPU_COUNT возвращает текущее их количество во множестве. Максимальное число процессоров в cpu_set_t, установленное по умолчанию, вполне достаточно для работы. Но со временем, несомненно, этого станет мало, и придется вносить правки. В процессе написания программы всегда необходимо помнить об этом ограничении. Вышеприведенные макросы удобны, но, в соответствии с описанием cpu_set_t, управляют размером множества лишь косвенно. Для более динамичного управления следует использовать расширенный набор макросов:
#define _GNU_SOURCE #include <sched.h> #define CPU_SET_S(cpu, setsize, cpusetp) #define CPU_CLR_S(cpu, setsize, cpusetp) #define CPU_ZERO_S(setsize, cpusetp) #define CPU_ISSET_S(cpu, setsize, cpusetp) #define CPU_COUNT_S(setsize, cpusetp)
Эти интерфейсы принимают размер множества (массива) в виде дополнительного параметра. Для работы с динамическими массивами процессоров используется следующая тройка макросов:
#define _GNU_SOURCE #include <sched.h> #define CPU_ALLOC_SIZE(count) #define CPU_ALLOC(count) #define CPU_FREE(cpuset)
CPU_ALLOC_SIZE возвращает число байтов, которое необходимо выделить структуре cpu_set_t, могущей обработать количество процессоров, указанное в count. Для собственно выделения такого блока используется CPU_ALLOC. Память, выделенная подобным образом, освобождается через CPU_FREE. Скорее всего, внутри этих функций используются malloc и free, но это далеко не обязательно.
Над множествами процессоров определены также следующие операции:
#define _GNU_SOURCE #include <sched.h> #define CPU_EQUAL(cpuset1, cpuset2) #define CPU_AND(destset, cpuset1, cpuset2) #define CPU_OR(destset, cpuset1, cpuset2) #define CPU_XOR(destset, cpuset1, cpuset2) #define CPU_EQUAL_S(setsize, cpuset1, cpuset2) #define CPU_AND_S(setsize, destset, cpuset1, cpuset2) #define CPU_OR_S(setsize, destset, cpuset1, cpuset2) #define CPU_XOR_S(setsize, destset, cpuset1, cpuset2)
Имеем две группы по четыре макроса. Они могут сравнивать пары множеств, а также производить логические операции И, ИЛИ, исключающее ИЛИ (XOR). Это пригодится при использовании некоторых функций libNUMA (см. раздел 12).
Процесс может определить, на каком процессоре он в данный момент выполняется, используя интерфейс sched_getcpu:
#define _GNU_SOURCE #include <sched.h> int sched_getcpu(void);
Как результат возвращается номер процессора в массиве. В связи с самой природой планирования, этот номер не всегда 100% верен. Есть вероятность, что поток был перемещен на другой процессор между моментом возвращения результата и моментом возвращения потока на уровень пользователя. Программы всегда должны принимать эту вероятность во внимание. В любом случае, гораздо важнее само множество процессоров, на которых потоку разрешено выполняться. Его можно получить, используя sched_getaffinity. Множество привязки наследуется дочерними потоками и процессами. Но неизменность данного множества во время жизненного цикла потока ничем не гарантируется. Маска привязки может быть установлена извне (см. параметр pid в прототипах выше); к тому же Linux поддерживает горячую замену процессоров, а это значит, что процессор может исчезнуть из системы — и, таким образом, из множества привязки.
В соответствии с требованиями POSIX, в многопоточных программах отдельные потоки официально не имеют своего отдельного PID, и поэтому вышеуказанные две функции использовать не получится. Вместо них в <pthread.h> объявлено четыре других интерфейса:
#define _GNU_SOURCE
#include <pthread.h>
int pthread_setaffinity_np(pthread_t th, size_t size,
const cpu_set_t *cpuset);
int pthread_getaffinity_np(pthread_t th, size_t size, cpu_set_t *cpuset);
int pthread_attr_setaffinity_np(pthread_attr_t *at,
size_t size, const cpu_set_t *cpuset);
int pthread_attr_getaffinity_np(pthread_attr_t *at, size_t size,
cpu_set_t *cpuset);
Первые два интерфейса - по сути те же две функции, с которыми мы уже знакомы, за исключением того, что они принимают дескриптор (HANDLE) потока вместо идентификатора процесса (PID). Это позволяет адресовать отдельные потоки в процессе, а также означает, что данные интерфейсы никак не могут быть использованы из другого процесса, они предназначены строго для внутрипроцессного использования. Далее, третий и четвертый интерфейсы принимают атрибут потока. Атрибуты используются при создании нового потока. Устанавливая атрибут, мы можем прямо при запуске потока определить его множество привязки. Выбор целевых процессоров на таком раннем этапе во многом выгоднее выбора уже в процессе работы потока, и особенно это преимущество заметно при выделении памяти (см. NUMA в разделе 6.5).
Кстати, в программировании NUMA интерфейсы привязки также играют большую роль. Скоро мы к этому вернемся.
Пока что мы говорили только о той ситуации, когда рабочие множества двух потоков совпадают, и поэтому имеет смысл выполнение обоих потоков на одном ядре. Но бывают и противоположные случаи. Если два потока работают с совсем разными наборами данных, то их выполнение на одном ядре наоборот может стать проблемой. Во-первых, оба потока будут сражаться за один кэш, мешая друг другу эффективно его использовать. Во-вторых, оба набора данных должны находиться в одном и том же кэше, что фактически означает увеличение количества данных для загрузки, и в итоге доступная пропускная способность урезается вдвое.
Решение - привязать потоки таким образом, чтоы они не могли выполняться вместе на одном ядре. Это противоположность случаю, описанному прежде. И поэтому прежде чем что-то менять, необходимо полностью разобраться в ситуации, которую взялся оптимизировать.
Оптимизация работы с кэшем ради увеличения пропускной способности на деле является аспектом программирования NUMA, о нем пойдет речь в следующем разделе. Чтобы убедиться в справедливости этого утверждения, необходимо свои представления о таком понятии, как ⌠память■ в NUMA, распространить на кэш. И чем больше уровней имеет кэш-память, тем актуальнее становится такой подход. И именно в связи с этим решения по многопроцессорному планированию можно найти во вспомогательных библиотеках NUMA; взятые оттуда примеры по определению масок привязки без применения хардкодинга или углубления в файловую систему /sys находятся в разделе 12.
6.5 Программирование NUMA
Итак, все, что было сказано об оптимизации работы с кэшем, применимо и к программированию NUMA. Но дальше начинаются отличия. В дело вступает такой факт, как разные затраты при доступе к разным областям адресного пространства. С однородным доступом к памяти мы можем оптимизацией добиться уменьшения ошибок отсутствия страниц (см. раздел 7.5), и на этом все. Все создаваемые страницы памяти одинаковы.
Совсем иначе с NUMA. Затраты на доступ зависят от адресуемой страницы, и это еще больше увеличивает важность оптимизации расположения страниц памяти. Использования архитектуры неоднородного доступа к памяти (именно так расшифровывается NUMA) не избежать на большинстве многопроцессорных машин, поскольку и Intel с CSI (на x86, x86-64 и IA-64), и AMD (на Opteron) используют именно ее. Правда, с увеличением числа ядер на отдельно взятом процессоре количество используемых многопроцессорных машин резко уменьшится (исключение составят дата-центры и ведомства с крайне высокими требованиями к ЦПУ). Для абсолютного большинства домашних машин будет достаточно одного процессора и, соответственно, не будет проблем, связанных с NUMA. Но это: а) не означает, что программисты могут игнорировать архитектуру NUMA и б) не означает исчезновения характерных для этой архитектуры проблем.
Ведь если задуматься, что общего NUMA имеет с другими архитектурами, можно легко увидеть, что это в точности концепция процессорной кэш-памяти. Два потока на ядрах с общим кэшем будут выполнены быстрее, чем потоки на ядрах с кэшем раздельным. За примерами далеко ходить не надо:
- ранние двухъядерные процессоры не имели общего кэша L2.
- процессоры Core 2 QX 6700 и QX 6800 от Intel, к примеру, имеют четыре ядра и два раздельных кэша L2.
- как недавно упоминалось, рост числа ядер на одном чипе и стремление к объединению кэшей в итоге приводят к увеличению количества уровней кэша.
Кэши формируют свою собственную иерархическую структуру, что повышает важность зависимости между разделением (или наоборот) кэшей и распределением потоков по ядрам. Такое положение дел фактически не отличается от проблем, стоящих перед NUMА, и в этом данные концепции едины. Вот почему даже тем людям, кто заинтересован исключительно в однопроцессорных машинах, следует прочесть данный раздел.
В разделе 5.3 мы увидели, что ядро Linux может дать нам много полезной - и нужной - информации для программирования NUMA. Однако, собрать эту информацию не так уж легко. Текущая версия Linux-библиотеки NUMA абсолютно непригодна для такой цели. На данный момент автор работает над новой, гораздо более удобной версией.
Существующая библиотека NUMA, libnuma, являющаяся частью пакета numactl, не дает доступа к информации об архитектуре системы. Все, что она делает - собирает в одной упаковке доступные системные вызовы и предоставляет удобные интерфейсы для часто применяемых операций. Итак, на сегодняшний день в Linux доступны следующие системные вызовы:
mbindВыборочная привязка указанных страниц памяти к узлам.
set_mempolicyУстановить политику выделения памяти по умолчанию.
get_mempolicyЗапросить информацию о политике выделения памяти по умолчанию.
migrate_pagesПереместить все страницы процесса с данного множества узлов на другое множество.
move_pagesПереместить выбранные страницы на указанный узел либо запросить адреса текущих узлов (т.е. на которых на данный момент находятся выбранные страницы).
Эти интерфейсы объявлены в заголовочном файле <numaif.h>, поставляемом с библиотекой libnuma. Но прежде чем углубиться в детали, необходимо понять саму концепцию политик выделения памяти.
6.5.1 Политика выделения памяти
Основная идея, лежащая в основе определения политик памяти - позволить уже написанному коду достаточно успешно функционировать в среде NUMA без серьезных модификаций. Политика наследуется дочерними процессами, поэтому возможно использование numactl. Помимо прочих возможностей, данный инструмент позволяет запустить программу с определенной политикой.
Ядром Linux поддерживаются следующие политики:
MPOL_BINDПамять выделяется только из указанного множества узлов. Если это невозможно, память не выделяется.
MPOL_PREFERREDПамять выделяется предпочтительно из указанного множества узлов. Если это невозможно, используется память других узлов.
MPOL_INTERLEAVEПамять выделяется в равной степени поочередно из определенных узлов. Узлы определяются либо смещением в области виртуальной памяти (для политик VMA), либо независимым счетчиком в случае политик задач.
MPOL_DEFAULTИспользовать способ выделения, применяемый по умолчанию для данной области.
Может показаться, что политики в этом списке определяются рекурсивно. Это верно только наполовину. На деле, политики выделения памяти образуют иерархическую структуру (см. рисунок 6.15).

Рисунок 6.15: Иерархическая структура политик выделения памяти
Если адрес принадлежит виртуальной памяти, то применяется соответствующая политика VMA. Для сегментов памяти общего доступа также применяется своя особая политика. Когда такие "специальные" политики для данного адреса отсутствуют, используется политика задач. Ну а если и последняя не назначена, то остается системная политика по умолчанию.
В качестве системной политики по умолчанию используется выделение памяти, локальной по отношению к запрашивающему потоку, и не определено никаких политик задач и виртуальной памяти. Для многопоточного процесса локальным узлом считается его ⌠домашний■ узел - тот, на котором был запущен процесс первоначально. Вышеперечисленные системные вызовы могут быть использованы для выбора нужных политик, что мы далее и рассмотрим.
6.5.2 Установка политик
Вызов set_mempolicy можно использовать, чтобы установить политику задач для текущего потока (поток, с точки зрения ядра, является задачей), причем устанавливается она только и исключительно для него, а не для всего процесса.
#include <numaif.h>
long set_mempolicy(int mode,
unsigned long *nodemask,
unsigned long maxnode);
Параметр mode может принимать одно из значений констант, представленных в предыдущем разделе. nodemask определяет необходимые узлы памяти, а maxnode - число этих узлов (т.е. битов) в nodemask. При использовании MPOL_DEFAULT параметр nodemask игнорируется. Если при использовании MPOL_PREFERRED в качестве nodemask передается пустой указатель, то выбирается локальный узел. Иначе MPOL_PREFERRED использует наименьший номер узла в соответствующем битовом множестве nodemask.
Установка политики никак не влияет на уже выделенную память, и страницы автоматически никуда не перемещаются. Политика повлиет только на последующие выделения памяти. Обратите внимание на различия между выделением памяти и резервированием адресного пространства: область адресного пространства, установленная с использованием mmap, обычно автоматически не выделяется. При первой операции чтения или записи произойдет выделение соответствующей страницы. Поэтому если политика изменится в какой-то момент между попытками доступа к разным страницам одной и той же области адресного пространства, или если политика позволяет выделение памяти из разных узлов, то однородное на вид адресное пространство может оказаться разбросанным по разным узлам памяти.
6.5.3 Свопинг и политики выделения памяти
Когда заканчивается физическая память, системе приходится выгружать чистые страницы и загружать в файл подкачки грязные (измененные). При загрузке страниц информация об узлах памяти стирается, это особенность реализации свопинга в Linux. Это означает, что когда страница снова задействуется, узел для нее будет выбран с нуля. Скорее всего, будет выбран узел, ближайший к соответствующему процессору, и наверняка это будет уже не тот узел, который использовался первоначально.
Такая смена привязки означает, что информацию о привязке к узлу нельзя хранить в свойствах страницы, ибо привязка со временем поменяется. Для страниц совместного доступа это также справедливо, поскольку будут происходить запросы от процессов (см. описание mbind ниже). Да и само ядро может переместить страницы, если на узле заканчивается память, а на соседних узлах есть свободное место.
Из вышесказанного следует, что любая информация о привязке узлов, полученная на пользовательском уровне, может оставаться верной лишь в течение короткого промежутка времени. Такая информация - скорее подсказка, чем абсолютная истина. Когда нужны достоверные данные, следует использовать интерфейс get_mempolicy (см. раздел 6.5.5)
6.5.4 Политика VMA
Чтобы установить политику VMA для определенного диапазона адресов, нужно использовать следующий интерфейс:
#include <numaif.h>
long mbind(void *start, unsigned long len,
int mode,
unsigned long *nodemask,
unsigned long maxnode,
unsigned flags);
В результате регистрируется новая политика VMA для диапазона [start, start + len). Поскольку память оперирует страницами, начальный адрес должен быть выровнен по границе страницы, а значение len округлено до размера следующей страницы.
Уже знакомый нам параметр mode так же определяет политику, значение нужно выбрать из списка в разделе 6.5.1. Аналогично с set_mempolicy, параметр nodemask используется не всеми политиками. Тут ничего не изменилось.
Семантика интерфейса mbind определяется значением параметра flags. По умолчанию, если flags равен нулю, данный системный вызов просто устанавливает политику VMA для указанного диапазона адресов. Уже существующие привязки и соответствия не затрагиваются. Если этого не достаточно, можно использовать один из трех доступных на сегодня флагов для изменения поведения. Флаги могут использоваться как по отдельности, так и вместе:
MPOL_MF_STRICTВызов
mbindзавершится неудачей в случае если не все страницы находятся на узлах, определенных черезnodemask. При использовании данного флага совместно сMPOL_MF_MOVEи/или сMPOL_MF_MOVEALLвызов завершится неудачей, если хоть одна страница не может быть перемещена.MPOL_MF_MOVEЯдро попытается переместить любую страницу адресного пространства, находящуюся на узле, не указанном в
nodemask. По умолчанию перемещаются только страницы, используемые таблицами страниц исключительно текущего процесса.MPOL_MF_MOVEALLДанный флаг похож на
MPOL_MF_MOVE, но в отличие от последнего, ядро попытается переместить все страницы, а не только используемые исключительно текущим процессом. Это приводит к последствиям для всей системы, поскольку влияет на доступ других процессов (которые могут иметь разных владельцев) к данным страницам. Поэтому для выполнения операции необходимы соответствующие привилегии (в частности,CAP_NICE).
Обратите внимание, что поддержка MPOL_MF_MOVE и MPOL_MF_MOVEALL была добавлена только в ядре Linux 2.6.16.
Вызов mbind без флагов наиболее полезен, когда нужно определить политику для только что зарезервированного адресного диапазона, прежде чем будут выделены какие-либо страницы.
void *p = mmap(NULL, len, PROT_READ|PROT_WRITE, MAP_ANON, -1, 0); if (p != MAP_FAILED) mbind(p, len, mode, nodemask, maxnode, 0);
Данный код резервирует диапазон адресного пространства в len байт и устанавливает политику mode в отношении узлов памяти nodemask. Если в mmap не использовался флаг MAP_POPULATE, то к моменту вызова mbind не было выделено никакой памяти и поэтому новая политика без проблем будет применена ко всем страницам в указанной области адресного пространства.
Флаг MPOL_MF_STRICT может быть использован для определения, присутствуют ли в адресном диапазоне страницы, находящиеся на узлах, не указанных в nodemask. Никаких изменений не производится. Если все страницы "на своих местах" - то есть находятся на указанных узлах, политика VMA для области адресного пространства успешно меняется на mode.
В случае, если требуется ребалансировка памяти, может появиться необходимость в перемещении страниц с одного узла на другой. Для этого вызывается mbind с флагом MPOL_MF_MOVE, причем перемещению могут быть подвергнуты только страницы, используемые исключительно текущим процессом. Если теми же данными пользуются другие потоки или процессы, то такие страницы переместить с помощью даннного флага невозможно.
Пусть функции mbind переданы сразу два флага, MPOL_MF_STRICT и MPOL_MF_MOVE. Тогда ядро попытается переместить все страницы, находящиеся "не на тех" узлах. В случае невозможности такой операции вызов закончится неудачей. Такой способ можно применять для поиска узла (или множества узлов), способного вместить все страницы. Прежде чем подходящий узел будет найдет, понадобится сделать несколько вызовов подряд.
Использование MPOL_MF_MOVEALL оправдано только если выполнение текущего процесса - основное предназначение компьютера. Причина тому - при использовании данного флага перемещаются даже те страницы, которые хранятся сразу в нескольких таблицах страниц, и такое поведение негативно отразится на других процессах. Так что данный флаг следует применять с осторожностью.
6.5.5 Запросы информации об узлах
Интерфейс get_mempolicy можно использовать для запросов различной информации об указанном адресе.
#include <numaif.h>
long get_mempolicy(int *policy,
const unsigned long *nmask,
unsigned long maxnode,
void *addr, int flags);
Когда get_mempolicy вызывается без установленных флагов в параметре flags, информация об используемой политике для адреса addr сохраняется в слове, на которое указывает policy и в битовой маске узлов, на которую указывает nmask. Если addr попадает в область адресного пространства, для которой установлена политика VMA, то возвращается информация о данной политике. Иначе возвращается информация о политике задач либо - при необходимости - о системной политике по умолчанию.
Если установлен флаг MPOL_F_NODE и addr обслуживается политикой MPOL_INTERLEAVE, то в слово, на которое указывает policy, записывается номер узла, на котором произойдет следующее выделение памяти. Эта информация впоследствии может быть использована для привязки потока, который будет выполняться на "свежевыделенной" памяти, что позволит минимизировать расходы на достижение "соседства", особенно если поток еще только предстоит создать.
Флаг MPOL_F_ADDR применяется для получения еще одного типа информации. При его установке, в слово, на которое указывает policy, записывается номер узла, на котором была выделена память для страницы, содержащей addr. Эту информацию можно использовать для принятия решений о возможном перемещении страниц; для выбора потока, который сможет работать с данной областью наиболее эффективно, и для многих других целей.
Процессор (а с ним и узел памяти), на котором выполняется поток, меняется гораздо чаще, чем выделенная для потока память. Перемещение страниц памяти происходит только в крайних случаях или в случае явных запросов на данное действие. Поток может быть назначен другому процессору в результате ребалансировки загрузок ЦПУ. В связи с этим, информация о текущем процессоре и узле быстро утрачивает актуальность. Но тем не менее, планировщик будет стараться держать поток на одном и том же процессоре, может даже на одном и том же ядре, для минимизации потерь производительности, связанных с понятием "холодного кэша". Следовательно, следить за информацией о текущем процессоре и узле может быть полезно, но все-таки нельзя забывать о том, что данная информация может измениться в любой момент.
Для запросов информации об узлах данного диапазона виртуального адресного пространства libNUMA предоставляет два интерфейса:
#include <libNUMA.h>
int NUMA_mem_get_node_idx(void *addr);
int NUMA_mem_get_node_mask(void *addr,
size_t size,
size_t __destsize,
memnode_set_t *dest);
NUMA_mem_get_node_mask устанавливает в dest биты всех узлов памяти, на которых выделены (или будут выделены) страницы диапазона [addr, addr+size) в соответствии с установленной для данной области политикой. А NUMA_mem_get_node_idx лишь обращается к адресу addr и возвращает номер узла памяти, на котором выделен (либо будет выделен) данный адрес. Эти интерфейсы использовать проще, чем get_mempolicy, и в общем случае, пожалуй, следует как раз их и применять.
Процессор, используемый потоком на данный момент, можно узнать, используя sched_getcpu (см. раздел 6.4.3). Основываясь на полученной информации, программа сможет определить узлы памяти, локальные по отоношению к процессору, используя интерфейс libNUMA NUMA_cpu_to_memnode:
#include <libNUMA.h>
int NUMA_cpu_to_memnode(size_t cpusetsize,
const cpu_set_t *cpuset,
size_t memnodesize,
memnode_set_t *
memnodeset);
Вызов этой функции установит (во множестве узлов памяти, на которое указывает четвертый параметр) все биты, соответствующие узлам памяти, локальным по отношению к процессорам во множестве, на которое указывает второй параметр. Так же как и сведения о процессоре, данная информация будет актуальна лишь до того момента, пока не изменится конфигурация машины (например, будут удалены либо добавлены процессоры)
Биты в объектах memnode_set_t могут быть использованы в вызовах низкоуровневых функций вроде get_mempolicy. Хотя в целом удобнее использовать другие функции libNUMA. Обратное отображение можно выполнить через:
#include <libNUMA.h>
int NUMA_memnode_to_cpu(size_t memnodesize,
const memnode_set_t *
memnodeset,
size_t cpusetsize,
cpu_set_t *cpuset);
Множество битов в итоговом cpuset определяет процессоры, локальные по отношению к узлам памяти в соответствующем битовом множестве memnodeset. В случае обоих интерфейсов программист должен помнить о том, что со временем данные сведения меняются (особенно при использовании горячей замены ЦПУ). Часто во входящем множестве установлены все биты. Казалось бы, бессмысленно, но нет: таким образом можно получить весь набор доступных процессоров, который затем можно передать в sched_getaffinity и NUMA_cpu_to_memnode, чтобы определить, к каким узлам памяти поток вообще может иметь прямой доступ.
6.5.6 Наборы ЦПУ и узлов памяти
Подгонка кода под определенные среды - SMP и NUMA - путем использования описанных интерфейсов может оказаться задачей непомерно дорогой, а то и невозможной вовсе, если недоступны исходники. К тому же, системный администратор может ограничить ресурсы, доступные для использования пользователям и/или процессам. Для таких ситуаций ядро Linux поддерживает так называемые наборы ЦПУ (CPU sets). Название немного обманчиво, поскольку включает в себя не только процессоры, но и узлы памяти. К тому же, наборы ЦПУ не имеют ничего общего с типом данных cpu_set_t.
На данный момент интерфейсом к наборам ЦПУ служит специальная виртуальная файловая система. Обычно по умолчанию она не смонтирована (по крайней мере, на сегодня это именно так). Исправить этот недочет можно, используя
mount -t cpuset none /dev/cpuset
Естественно, точка монтирования /dev/cpuset должна уже существовать. Внутри этой директории находится описание корневого (root) набора ЦПУ. Поначалу он включает в себя все процессоры и узлы памяти. Файл cpus там же показывает процессоры, находящиеся на данный момент в наборе, файл mems показывает узлы памяти и файл tasks - процессы.
Для создания нового набора достаточно просто создать новую директорию в любом месте иерархии. Созданный набор унаследует все настройки от родителя, и затем их можно поменять, записывая новые значения в псевдофайлы cpus и mems в новой директории.
Если процесс принадлежит набору ЦПУ, то настройки процессоров и узлов памяти используются в качестве битовых масок привязки к процессорам и политики выделения памяти соответственно. Это означает, что программа не может выбрать никаких других процессоров, кроме прописанных в файле cpus "своего" набора ЦПУ (т.е. в файле tasks которого находится данный процесс). Аналогично для узлов памяти и файла mems.
Программа будет функционировать без ошибок, если только битовые маски не окажутся пустыми, и поэтому наборы ЦПУ фактически невидимы для управляющей программы. Этот подход особенно эффективен на больших машинах с огромным количеством ЦПУ и/или узлов памяти. Перемещение процесса на другой набор ЦПУ заключается лишь в записи его идентификатора в файл the tasks соответствующего набора, вот и вся сложность.
Директории наборов ЦПУ содержат и другие файлы, которые используются для указания различных особенностей конкретного набора - например, для определения поведения при нехватке памяти или для определения исключительного доступа к процессорам и узлам памяти. Заинтересованный читатель может обратиться за подробностями к файлу Documentation/cpusets.txt в дереве исходников ядра.
6.5.7 Явные оптимизации NUMA
Никакая локальная память и никакие правила привязки не помогут, если все потоки на всех узлах требуют доступа к одним и тем же областям памяти. Конечно, можно попросту ограничить количество потоков числом, которое поддерживают процессоры, напрямую соединенные с узлом памяти. Но при этом теряются преимущества многопроцессорных машин с архитектурой NUMA, а значит - не вариант.
Если данные, о которых идет речь, доступны только для чтения, есть простое решение: тиражирование. Раздаем каждому узлу по своей копии данных и исчезает вся необходимость в межузловых попытках доступа. Код, реализующий идею, может выглядеть так:
void *local_data(void) {
static void *data[NNODES];
int node =
NUMA_memnode_self_current_idx();
if (node == -1)
/* Cannot get node, pick one. */
node = 0;
if (data[node] == NULL)
data[node] = allocate_data();
return data[node];
}
void worker(void) {
void *data = local_data();
for (...)
compute using data
}
Функция worker начинает работу с получения указателя на локальную копию данных (для этого происходит вызов local_data). Затем выполняется цикл, использующий полученный указатель. Функция local_data хранит список уже распределенных копий данных. В каждой системе число узлов данных ограничено, поэтому и размер массива указателей на копии данных для каждого узла также ограничен. Взятая из libNUMA функция NUMA_memnode_system_count возвращает как раз это число. Если указатель для текущего узла, определяемый вызовом NUMA_memnode_self_current_idx, не существует, создается новая копия.
Важно понять, что не случится ничего страшного, если потоки после системного вызова sched_getcpu будут назначены другому процессору, находящемуся на другом узле памяти. Это просто означает, что при использовании переменной data в функции worker будет происходить доступ к памяти другого узла. Программа замедлится до следующего вычисления data, но не более. Ядро никогда не будет зазря ребалансировать очереди процессорных запросов, и если это произошло, значит тому была уважительная причина и подобное в ближайшем будущем не повторится.
Все усложняется, если данные, за которые идет конкуренция, предназначены не только для чтения, но и для записи. Тиражирование в данном случае не сработает. В зависимости от конкретной ситуации возможны различные решения.
Например, если данная область памяти используется для сбора результатов, можно сначала создать отдельные области в каждом узле памяти, где происходит сбор локальных результатов. А затем, когда эта работа закончена, все такие локальные области объединяются для получения общего результата. Данный прием работает и в случае, если работа на деле никогда не останавливается, но необходимы промежуточные результаты. Требование такого подхода - должно отсутствовать последействие, то есть текущие результаты не должны зависеть от прошлых результатов.
Хотя, конечно же, всегда лучше иметь прямой доступ к области памяти для записи. Если количество попыток доступа к данной области значительно, то стоит заставить ядро переместить эти страницы памяти на локальный узел. Такой шаг оправдает себя, если число попыток доступа действительно велико и операции записи на разные узлы не происходят параллельно. Только не забывайте, что ядро не может творить чудеса: перемещение страниц включает недешевую операцию копирования, и потому кой-какую цену придется заплатить.
6.5.8 Используем всю полосу пропускания
Цифры на рисунке 5.4 демонстрируют, что доступ к удаленной памяти напрямую ("мимо кэша", т.е. при работе без использования кэша) не особо медленнее доступа к локальной памяти. Это означает, что программа может освободить полосу пропускания к локальной памяти, записывая данные, которые уже не придется считывать, в удаленную память (локальную для другого процессора). Полоса пропускания канала к модулям DRAM и полоса пропускания внутреннего соединения обычно независимы, и поэтому параллельное их использование может повысить общую производительность.
Возможно это на практике или нет, зависит от множества факторов. Необходимо быть уверенным, что запись действительно идет мимо кэша, иначе замедление, связанное с удаленным доступом, будет очень даже ощутимо. Другая проблема возникает, если удаленному узлу самому нужен свой канал памяти полностью. Такая вероятность есть, и она должна быть подробно исследована перед применением предложенного подхода. В теории, несомненно, использование всей доступной процессору полосы пропускания может дать положительный эффект. Например, процессор Opteron семейства 10h может быть напрямую соединен с четырьмя другими процессорами, и использование всей этой увеличенной полосы, дополненное соответствующей предвыборкой (особенно prefetchw), просто обязано улучшить производительность. Если, конечно, система уже работает на полную мощность и не имеет других узких мест.
Замечания и предложения по переводу принимаются по адресу michael@right-net.ru. М.Ульянов.