Библиотека сайта rus-linux.net
Ошибка базы данных: Table 'a111530_forumnew.rlf1_users' doesn't exist
Что каждый программист должен знать о памяти. Виртуальная память
Оригинал: What every programmer should know about memoryАвтор: Ulrich Drepper
Дата публикации: 09.10.2007
Перевод: Капустин С.В.
Дата перевода: 19.03.2009
Подсистема виртуальной памяти процессора реализует виртуальное адресное пространство для каждого процесса. Это позволяет каждому процессу думать, что он один в системе. Детальное описание преимуществ виртуальной памяти можно найти где угодно и здесь мы не будем его повторять. Вместо этого в этом разделе мы сосредоточимся на актуальных деталях реализации подсистемы виртуальной памяти и связанных с этим издержках.
Виртуальное адресное пространство реализовано блоком управления памяти (MMU - Memory Management Unit) процессора. Операционная система должна заполнить структуры данных таблицы страниц, но большинство процессоров делают остальную часть работы сами. Это на самом деле довольно сложный механизм. Наилучший способ понять его - это изучить структуры данных, используемые для описания виртуального адресного пространства.
Исходной информацией для преобразования адресов, выполняемого MMU, является виртуальный адрес. Обычно существует немного, если есть вообще, ограничений на его значение. Виртуальные адреса - это 32-битные значения в 32-битных системах и 64-битные значения в 64-битных системах. В некоторых системах, например в x86 и x86-64, используемый адрес включает еще один уровень переадресации: эти архитектуры используют сегменты, которые просто задают смещение, добавляемое к каждому логическому адресу. Мы можем игнорировать эту часть генерации адресов, она тривиальна и это не то о чем должен заботиться программист, думающий о производительности работы с памятью. (Ограничения сегментов в x86 влияют на производительность, но это уже другая история.)
4.1 Простейшее преобразование адресов
Интересная часть - преобразование виртуального адреса в физический. MMU может преобразовывать адрес постранично. Также как со строками процессорного кэша, виртуальный адрес разделяется на части. Эти части используются как индексы различных таблиц, которые в свою очередь используются для построения окончательного физического адреса. Для простейшей модели мы имеем только один уровень таблиц.
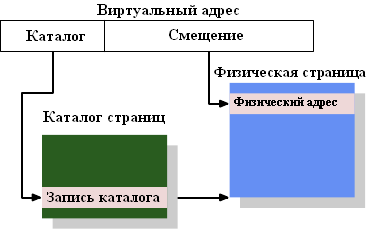
Рисунок 4.1: Одноуровневое преобразование адресов
Рисунок 4.1 показывает, как используются различные части виртуального адреса. Старшие разряды используются для выбора записи в каталоге страниц. Каждая запись в этом каталоге может быть индивидуально установлена операционной системой. Запись каталога страниц определяет адрес физической страницы памяти. На одну физическую страницу могут указывать несколько записей каталога страниц. Полный физический адрес ячейки памяти определяется как комбинация адреса страницы из каталога страниц с младшими битами виртуального адреса. Запись каталога страниц также содержит некоторую дополнительную информацию о странице, такую как разрешения на доступ.
Структура данных каталога страниц хранится в памяти. Операционная система должна выделить непрерывный участок памяти и сохранить базовый адрес этого участка в специальном регистре. Подходящие биты виртуального адреса затем используются как индекс каталога страниц, который является массивом записей каталога.
Конкретным примером может служить модель, используемая для страниц размером 4Мб на x86 машинах. Часть "смещение" виртуального адреса имеет размер 22 бита, как раз достаточный для адресации каждого байта в странице размером 4Мб. Оставшиеся 10 бит виртуального адреса выбирают одну из 1024 записей каталога страниц. Каждая запись содержит 10 бит базового адреса страницы размером 4Мб, что вместе со "смещением" дает полный 32-битный адрес.
4.2 Многоуровневые таблицы страниц
Страницы размером 4Мб не являются нормой. Они бы расходовали много лишней памяти, так как многие операции, которые выполняет операционная система, требуют выравнивания страниц памяти. Со страницами размером 4Кб (норма для 32-битных машин и все еще часто для 64-битных) часть виртуального адреса "смещение" имеет размер всего 12 бит. Это оставляет 20 бит для выбора из каталога страниц. Таблица с 220 записями непрактична. Даже если каждая запись будет размером всего 4 байта, размер таблицы будет 4Мб. Тогда большая часть физической памяти системы будет отдана на таблицы страниц, так как каждый процесс может иметь свою таблицу страниц.
Решение состоит в использовании нескольких уровней таблицы страниц. Они могут представлять огромный разреженный каталог страниц, где неиспользуемые регионы не требуют выделения памяти. Следовательно, представление намного более компактное и есть возможность для многих процессов в памяти иметь каталоги страниц без существенного влияния на производительность.
Сегодня наиболее сложные структуры таблиц страниц содержат 4 уровня. Рисунок 4.2 показывает схему такой структуры.
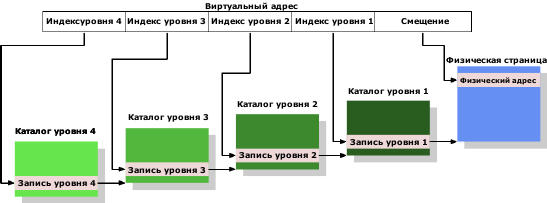
Рисунок 4.2: 4-уровневое преобразование адресов
Виртуальный адрес в этом примере разбит, по крайней мере, на 5 частей. 4 части являются индексами различных каталогов. Для ссылок на каталог 4-го уровня используется специальный регистр процессора. Содержимое каталога на уровнях с 4 по 2 - это ссылки на каталог уровня ниже на единицу. Если запись каталога помечена как пустая, она очевидно не должна указывать на низлежащий каталог. За счет этого достигается разреженность и компактность дерева таблиц страниц. Записи каталога уровня 1 - это часть физического адреса плюс дополнительные данные как, например, разрешения на доступ.
Чтобы определить физический адрес, соответствующий виртуальному адресу, процессор сначала определяет адрес наивысшего уровня в каталоге. Этот адрес обычно хранится в регистре. Затем процессор берет часть виртуального адреса, соответствующую индексу этого каталога, и использует этот индекс, чтобы выбрать подходящую запись. Эта запись - адрес следующего каталога, который проиндексирован с помощью следующей части виртуального адреса. Этот процесс продолжается, пока не достигнет каталога уровня 1, где значение записи каталога - это старшие разряды физического адреса. Младшие разряды физического адреса берутся из битов "смещения" виртуального адреса. Этот процесс называется прогулкой по дереву страниц. Некоторые процессоры (как x86 и x86-64) выполняют эту операцию аппаратно, другие прибегают к помощи операционной системы.
Каждому запущенному в системе процессу, возможно, понадобится собственное дерево таблиц страниц. Частичное разделение деревьев возможно, но это скорее исключение. Следовательно, для производительности и масштабируемости предпочтительно, чтобы память, отведенная под деревья таблиц страниц, была как можно меньше. Идеальный случай для этого, если используемая память расположена компактно в виртуальном адресном пространстве; какие именно физические адреса используются - значения не имеет. Маленькая программа может обойтись использованием на уровнях 2,3,4 только по одному каталогу и несколькими каталогами на уровне 1. На x86-64 со страницами размера 4Кб и 512 записями в каталоге это позволяет адресовать 2Мб с помощью 4-х каталогов (по одному на каждом уровне). 1Гб непрерывной памяти может быть адресован, используя по одному каталогу на уровнях со 2-го по 4-й и 512 каталогов на уровне 1.
Однако предполагать, что вся память может быть выделена одним куском, будет слишком большим упрощением. Из соображений гибкости области стека и кучи процесса в большинстве случаев выделяются на противоположных концах адресного пространства. Это позволяет каждой области при необходимости расти так как только возможно. Это означает, что скорее всего, будет 2 каталога на уровне 2 и соответственно больше каталогов на низлежащем уровне.
Но даже этот случай не всегда имеет место на практике. Из соображений безопасности различные части исполняемого процесса (код, данные, куча, стек, разделяемые библиотеки) отображаются на случайно выбранные (рандомизированные) адреса (см. [1]). Рандомизации подвергается относительное расположение разных частей, из этого следует, что используемые участки памяти могут быть в любой части виртуального адресного пространства. Если рандомизировать только несколько битов адреса, можно ограничить область, в которой находятся используемые участки виртуального адресного пространства; но, конечно, в большинстве случаев невозможно ограничить процесс использованием только одного или двух каталогов на уровнях 2 и 3.
Если производительность намного важнее безопасности, рандомизация может быть отключена. Тогда операционная система обычно, по крайней мере, загружает все исполняемые библиотеки в виртуальную память одним непрерывным куском.
4.3 Оптимизация доступа к таблицам страниц
Все структуры данных таблиц страниц хранятся в основной памяти, там операционная система создает и обновляет страницы. При создании процесса или изменении таблицы страниц оповещается процессор. Таблицы страниц, используемые для преобразования любого виртуального адреса в физический адрес методом прогулки по дереву таблиц страниц, описаны выше. Более того, показано, что в процессе нахождения адреса используется, по крайней мере, один каталог на каждом уровне преобразования адреса. Это требует до четырех обращений к памяти (за одно обращение к работающему процессу), что конечно медленно. Можно обращаться с записями каталогов таблиц как с обычными данными и кэшировать их в L1d, L2 и т. д., но все равно это будет медленно.
С ранних дней применения виртуальной памяти разработчики процессоров используют другую оптимизацию. Простое вычисление может показать, что только хранение записей каталогов таблиц в L1d и в более высоком кэше приведет к ужасным результатам. Вычисление каждого абсолютного адреса потребует многочисленного обращения к L1d в соответствии с глубиной таблицы страниц. Эти обращения не могут быть распараллелены, так как они зависят от результатов предыдущего поиска. Это одно потребует, по крайней мере, 12 циклов на машине с четырьмя уровнями таблиц страниц. Добавьте к этому вероятность непопадания в L1d, и никакой конвейер команд не сможет скрыть результат. Дополнительные обращения к L1d также расходуют драгоценную пропускную способность кэша.
Вместо кэширования записей таблицы каталогов кэшируется всё вычисление адреса физической страницы. Такое кэширование работает по той же причине, по какой работает кэширование данных и кода. Так как часть виртуального адреса "смещение" не участвует в вычислении адреса физической страницы, только оставшаяся часть виртуального адреса используется как тег кэша. В зависимости от размера страницы это означает, что сотни или даже тысячи инструкций или объектов данных разделяют один и тот же тег и, следовательно, префикс физического адреса.
Кэш, в котором хранятся вычисленные значения, называется "буфер ассоциативного преобразования адресов" (TLB - Translation Look-Aside Buffer). Обычно это маленький кэш, так как он должен быть очень быстрым. Современные процессоры имеют многоуровневые TLB кэши. Также как и для обычного кэша, чем больше номер кэша, тем он больше и медленнее. Часто маленький размер L1TLB задается преднамеренно, для того, чтобы сделать кэш полностью ассоциативным с политикой удаления страниц, которые дольше всего не использовались (LRU - least recently used). В настоящее время размеры таких кэшей увеличиваются, и они перестают быть ассоциативными. Как результат, может получиться, что при добавлении новой записи исключается не самая старая запись.
Как отмечалось ранее, тэг, используемый для доступа к TLB, - это часть виртуального адреса. Если тэг найден в кэше, окончательное значение физического адреса вычисляется добавлением смещения внутри страницы, взятым из виртуального адреса, к кэшированному значению. Это очень быстрый процесс. Он должен быть таким, так как физический адрес должен быть доступен любой инструкции, использующей абсолютные адреса, и в некоторых случаях запросам к L2, которые используют физический адрес как индекс. Если запрос к TLB заканчивается неудачей, процессор должен выполнить алгоритм прогулки по дереву таблиц страниц, что может быть довольно затратно.
Предварительная выборка кода или данных программно или аппаратно может повлечь предварительную выборку записей в TLB, если адрес находится на другой странице. Этого нельзя допускать для аппаратной предварительной выборки, так как это может инициировать ошибочные прогулки по таблицам страниц. Программисты, следовательно, не должны полагаться на аппаратную предварительную выборку для предварительной выборки записей в TLB. Это должно быть сделано явно, используя инструкции предварительной выборки. Кэши TLB, также как и кэши данных и кода, могут появляться на нескольких уровнях. Также как кэш данных, TLB обычно появляется в двух разновидностях: TLB для кода (ITLB - instruction TLB) и TLB для данных (DTLB - data TLB). TLB с более большими номерами, такие как L2TLB, обычно объединены, как и в случае с обычным кэшем.
4.3.1 Пояснения к использованию TLB
TLB - это глобальный ресурс ядра процессора. Все потоки и процессы, выполняемые в ядре, используют один TLB. Так как преобразование виртуального адреса в физический зависит от того, какое загружено дерево таблиц страниц, процессор не может слепо продолжать использовать кэшированные записи, если таблица страниц поменялась. Каждый процесс имеет своё дерево таблиц страниц (но не потоки одного процесса), также как и ядро ОС и монитор виртуальной машины (Virtual Machine Monitor, VMM), если таковой имеется. Также возможно изменение конфигурации адресного пространства процесса. Есть два подхода к решению этой проблемы:
- TLB очищается при каждом изменении дерева таблиц страниц.
- В тэги TLB добавляется информация так, чтобы можно было однозначно определить, на какое дерево таблиц страниц ссылается тэг.
В первом случае TLB очищается при каждом переключении контекста. Так как в большинстве ОС переключение с одного потока/процесса на другой требует выполнения некоторого кода ядра ОС, очищение TLB происходит при входе и выходе из адресного пространства ядра ОС. На виртуализованных системах это случается также, когда ядро ОС вызывает VMM, и по пути назад. Если ядро ОС и/или VMM не обязано использовать виртуальный адрес, или может использовать тот же виртуальный адрес, что и процесс или ядро, которое сделало вызов системы/VMM, TLB очищается только если покидая ядро ОС или VMM процессор начинает выполнение другого процесса или ядра.
Очищение TLB эффективно, но затратно. Например, когда ядро ОС выполняет системный вызов, его код может быть ограничен несколькими тысячами инструкций, которые затрагивают небольшое количество новых страниц (или одну огромную страницу, в случае использования Linux на некоторых архитектурах). Это заставит поменять ровно столько записей TLB, сколько новых страниц использовано. Для архитектуры Intel Core2, которая имеет 128 записей ITLB и 256 ITLB, полное очищение означает, что более 100 и 200 записей соответственно будут удалены без необходимости делать это. Когда система вернется к этому процессу снова, эти записи могут понадобиться, но их уже не будет. То же самое верно для часто используемого кода ядра ОС или VMM. При каждом входе в ядро ОС TLB придется заполнять заново, хотя таблицы страниц для ядра ОС или VMM обычно не изменяются и, следовательно, в теории, могут храниться очень долгое время. Это также объясняет, почему кэши TLB в современных процессорах не такие большие: программы, скорее всего, не будут работать настолько долго, чтобы заполнить все эти записи.
Этот факт, конечно, не ускользнул от разработчиков процессоров. Одно из возможных решений - использовать выборочное удаление записей для оптимизации очищения кэша. Например, если код и данные ядра ОС попадают в некоторый диапазон адресов, то из TLB удаляются только страницы из этого диапазона. Это требует только сравнения тэгов и, следовательно, не очень затратно. Этот метод также полезен в случае, когда изменяется только часть адресного пространства, например через вызов munmap.
Намного лучшим решением будет расширить тэг, используемый для доступа к TLB. Если к части виртуального адреса будет добавлен уникальный идентификатор дерева таблиц страниц (например адресного пространства процесса), то TLB можно будет полностью не очищать. Ядро ОС, VMM, и процессы могут иметь уникальные идентификаторы. Единственная трудность здесь это то, что количество бит, доступных для тэга TLB жестко ограничено, тогда как число адресных пространств нет. Это значит, что некоторые идентификаторы придется переназначать. Когда такое происходит, TLB должен быть частично очищен (если это возможно). Все записи с переназначенным идентификатором должны быть удалены, но их, скорее всего, будет очень мало.
Это расширение тэгов TLB имеет общее преимущество когда в системе запущено много процессов. Если объем памяти (и, следовательно, количество записей TLB) для каждого процесса ограничен, то велика вероятность того, что последние по времени использования записи TLB для процесса будут все ещё в TLB, когда они понадобятся. И ещё два дополнительных преимущества:
- Специальные адресные пространства, такие как у ядра ОС и VMM, часто
используются только на короткое время, после чего управление обычно передается адресному пространству, которое инициировало вызов. Без тэгов было бы выполнено два очищения TLB. С тэгами преобразование адресов вызывающего адресного пространства сохраняется и, так как адресные пространства ядра ОС и VMM не часто изменяют записи TLB, преобразования адресов предыдущих системных вызовов и т.д. могут быть снова использованы.
- При переключении между потоками одного процесса очищение TLB не нужно вообще. Без расширенных тэгов TLB, вход в ядро ОС уничтожит записи в TLB первого потока.
На некоторых процессорах такие расширенные тэги уже стали появляться. AMD представило 1-битное расширение тэга на платформе аппаратной виртуализации Pacifica. Этот 1-битный идентификатор адресного пространства (ASID - Address Space ID) используется в контексте виртуализации, чтобы отличать адресное пространство VMM от адресных пространств гостевых операционных систем. Это позволяет ОС избежать удаления из TLB записей гостевой операционной системы каждый раз, когда управление передается VMM (например, при ошибке страницы) или записей VMM, когда управление возвращается гостевой операционной системе. Эта архитектура позволит использовать больше бит в будущем. Другие наиболее распространенные процессоры, скорее всего, также будут поддерживать это свойство.
4.3.1 Влияние на производительность TLB
Есть пара факторов, которые влияют на производительность TLB. Первый - это размер страниц. Очевидно, что чем больше страница, тем больше попадает в неё инструкций или объектов данных. Таким образом, больший размер страницы сокращает общее число необходимых преобразований адресов, что означает, что можно обойтись меньшим числом записей в кэше TLB. Большинство архитектур позволяют использовать разные размеры страниц. Некоторые размеры могут быть использованы одновременно. Например, процессоры 86/x86-64 имеют нормальный размер страницы 4Кб, но могут также использовать страницы размером 4Мб и 2Мб соответственно. IA-64 и PowerPC позволяют использовать в качестве базового размера страницы значение 64Кб.
Однако использование страниц большого размера несет в себе и некоторые проблемы. Область памяти, используемая для большой страницы, должна располагаться в памяти одним непрерывным куском. Если увеличить размер блока при администрировании физической памяти до размера страницы виртуальной памяти, то потери памяти будут расти. Все виды операций с памятью (например загрузка исполняемого кода) требуют выравнивания границ страниц. Это означает, что в среднем при каждом выделении памяти будет теряться половина размера страницы физической памяти. Эти потери легко могут накапливаться, что задает ограничение сверху на размер блока физической памяти.
Определенно можно сказать, что будет непрактично увеличивать размер блока до 2Мб на x86-64, чтобы получить большие страницы. Это слишком большой размер. Но это в свою очередь означает, что каждая большая страница должна состоять их множества маленьких страниц. Все эти страницы должны располагаться рядом в физической памяти. Выделение 2Мб непрерывной физической памяти может быть сложной задачей при размере блока 4Кб. Для этого требуется найти свободное пространство из 512 страниц, расположенных рядом. Это может быть очень сложно (или даже невозможно) после того как система работает некоторое время и физическая память фрагментирована.
На Linux, следовательно, нужно выделить эти большие страницы во время старта системы, используя специальную файловую систему hugetlbfs. Фиксированное количество физических страниц будут зарезервированы исключительно для использования в качестве больших виртуальных страниц. Это связывает ресурсы, которые могут вообще остаться неиспользованными. Их к тому же ограниченное количество - чтобы его увеличить потребуется перезагрузка. Но все равно это выход в ситуации, когда производительность на первом месте, ресурсов хватает, а долгая загрузка не страшна. Примером могут служить серверы баз данных.
Увеличение минимального размера виртуальной страницы (как альтернатива опциональному использованию больших страниц) тоже имеет свои проблемы. Операции, связанные с распределением памяти (например загрузка приложения), должны быть согласованы с этим размером страниц. Выделение памяти меньшего размера невозможно. Расположение различных частей исполняемого файла для большинства архитектур фиксировано. Если размер страницы увеличен больше того предела, на который ориентировались при компиляции исполняемого файла или библиотеки, загрузка будет невозможна. Важно держать это ограничение в голове. Рисунок 4.3 показывает, как можно определить требования к выравниванию по виду файла формата ELF. Это закодировано в его заголовке.
$ eu-readelf -l /bin/ls Program Headers: Type Offset VirtAddr PhysAddr FileSiz MemSiz Flg Align ... LOAD 0x000000 0x0000000000400000 0x0000000000400000 0x0132ac 0x0132ac R E 0x200000 LOAD 0x0132b0 0x00000000006132b0 0x00000000006132b0 0x001a71 0x001a71 RW 0x200000 ...
Рисунок 4.3: Заголовок ELF, указывающий на требования к выравниванию
В этом примере бинарника на x86-64 значение выравнивания 0x200000 = 2,097,152 = 2Мб соответствует максимальному размеру страницы, поддерживаемому процессором.
Есть второй эффект от использования страниц большего размера - число уровней дерева таблиц страниц сокращается. Так как часть виртуального адреса, соответствующая смещению внутри страницы возрастает, остается не так много бит, которые требуется распределить по каталогам страниц. Это означает, что в случае отсутствия нужной записи в TLB, количество необходимой работы сократится.
Кроме использования большого размера страниц, возможно сократить необходимое количество записей TLB, перемещая данные, которые используются одновременно, на меньшее количество страниц. Это похоже на некоторые оптимизации кэша, о которых упоминалось ранее. Только теперь выравнивание большего размера. Учитывая, что количество записей TLB довольно мало, это может быть очень важной оптимизацией.
4.4 Значение виртуализации
Витруализация образов ОС становится все более распространенной. Это означает, что к картинке добавляется ещё один уровень работы с памятью. Виртуализация процессов (в основном jail) или контейнеры ОС не попадают в эту категорию, так как задействована только одна ОС. Такие технологии как Xen или KVM позволяют использовать ( с помощью или без помощи процессора) независимые образы ОС. В этих случаях есть только одно приложение, которое напрямую управляет доступом к физической памяти.
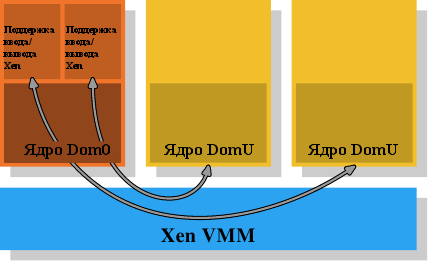
Рисунок 4.4: Модель виртуализации Xen
В случае Xen таким приложением является Xen VMM. Хотя VMM не реализует управление большой частью аппаратного обеспечения само. На более ранних системах (и на первом релизе Xen VMM) все аппаратное обеспечение, кроме процессора и памяти управлялось привилегированным доменом Dom0. Сейчас это в основном такое же ядро, как непривилегированные ядра DomU, и, когда речь идет об управлении памятью, они не различаются. Важно здесь то, что VMM выделяет физическую память для ядер Dom0 и DomU, которые реализуют обычное управление памятью, как если бы они работали непосредственно на процессоре.
Чтобы было реализовано разделение доменов, которое требуется для полной виртуализации, процессы управления памятью в ядрах Dom0 и DomU не имеют неограниченного доступа к физической памяти. VMM в XEN распределяет память не путем выдачи отдельных физических страниц и предоставления гостевой ОС права управлять адресацией; тогда не было бы никакой защиты от неисправных и вредоносных гостевых доменов. Вместо этого VMM создает для каждого гостевого домена его собственное дерево таблиц страниц и выделяет память, используя эти структуры. Преимущество такого способа в том, что доступ к административной информации дерева таблиц страниц можно контролировать. Если код не имеет соответствующих привилегий, он не сможет ничего сделать.
Этот контроль доступа применяется в виртуализации Xen независимо от того, какая используется виртуализация - аппаратная (или полная) или паравиртуализация. Гостевые домены строят деревья таблиц страниц для каждого процесса способом, который намеренно сделан практически идентичным для аппаратной и паравиртуализации. Всякий раз, когда гостевая ОС модифицирует таблицу страниц, вызывается VMM. VMM затем использует обновленную информацию из гостевого домена, чтобы обновить свои собственные теневые таблицы страниц. Это как раз те таблицы страниц, которые используются аппаратным обеспечением. Очевидно, что этот процесс довольно затратен: каждая модификация дерева таблиц страниц требует вызова VMM. Изменения в выделении памяти недешевы и без виртуализации, теперь они ещё затратнее.
Дополнительная стоимость может быть действительно высока, принимая во внимание, что сами по себе переходы из гостевой ОС в VMM и обратно имеют высокую стоимость. Вот почему процессоры стали получать дополнительную функциональность, позволяющую избежать создания теневых таблиц страниц. Это не только увеличивает скорость, но и сокращает количество памяти, потребляемой VMM. У Intel есть технология Extended Page Tables (EPTs), у AMD технология Nested Page Tables (NPTs). В обеих технологиях гостевые ОС создают виртуальный физический адрес. Затем адрес должен быть преобразован, используя для каждого домена своё EPT/NPT дерево, в настоящий физический адрес. Это позволяет работать с памятью на скорости, близкой к невиртуализованному случаю, так как большинство записей VMM для работы с памятью удалено. Это также снижает количество памяти, потребляемой VMM, так как теперь нужно поддерживать только одно дерево таблиц страниц на каждый домен (а не на каждый процесс).
Результаты дополнительного преобразования адресов также хранятся в TLB. Это означает, что TLB хранит не виртуальный физический адрес, а полный результат поиска. Как уже было сказано, технология компании AMD Pacifica использует ASID для каждой записи, чтобы избежать очищения TLB. Количество бит для ASID равно 1 в первоначальном релизе технологии, этого как раз достаточно, чтобы отличать VMM и гостевые ОС. Intel использует идентификаторы виртуального процессора (VPIDs - virtual processor IDs), которые служат той же цели, только их больше. VPID закреплен за каждым гостевым доменом и, следовательно, также не может быть использован для разделения процессов и предотвращения очищения TLB на этом уровне.
Одна из проблем виртуализации операционных систем - это количество работы, необходимое для модификации каждого адресного пространства. Есть, однако, еще одна проблема, присущая виртуализации, основанной на VMM: неизбежно использование двух уровней работы с памятью. Но работа с памятью тяжела (особенно если принять во внимание такие усложнения как NUMA, см. главу 5). Подход Xen, основанный на использовании отдельного VMM, затрудняет оптимальную (и даже просто хорошую) работу с памятью, так как все сложности управления памятью, включая такие "тривиальные" вещи, как поиск областей памяти, должны дублироваться в VMM. Операционные системы сами имеют зрелую и оптимизированную систему работы с памятью, хотелось бы избежать её дублирования.
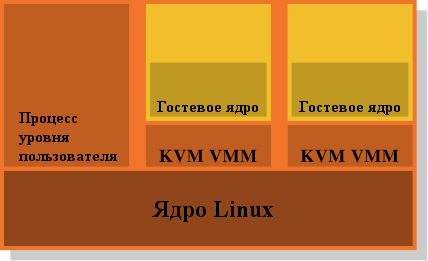
Рисунок 4.5: Модель виртуализации KVM
Вот почему доведение модели VMM/Dom0 до её логического завершения представляется привлекательной альтернативой. Рисунок 4.5 показывает, как расширения ядра Linux KVM пытаются решить проблему. Здесь нет отдельного VMM, работающего с аппаратным обеспечением и управляющего всеми гостями. Вместо этого обычное ядро Linux берет на себя эту функциональность. Это означает, что полная и сложная функциональность ядра Linux используется для работы с памятью. Гостевые домены работают вместе с обычными процессами уровня пользователя в режиме, который разработчики называют "режим гостя". Функциональность виртуализации, полной или паравиртуализации, управляется другим процессом уровня пользователя - KVM VMM. Это просто ещё один процесс, который управляет гостевым доменом, с помощью специального устройства KVM, реализованного в ядре.
Преимущество этой модели над отдельным VMM модели Xen в том, что хотя при использовании гостевой ОС все равно работает два обработчика памяти, нужна всего одна реализация, а именно ядро Linux. Нет необходимости дублировать ту же функциональность в другом коде, таком как Xen VMM. Это приводит к меньшему количеству работы, ошибок и, возможно, к меньшим трениям между двумя обработчиками памяти, так как обработчик памяти в гостевой системе Linux делает те же предположения, что и обработчик памяти внешнего ядра Linux, которое работает непосредственно с аппаратным обеспечением.
Итак, программист должен иметь ввиду, что когда используется виртуализация, затраты на операции с памятью выше, чем без виртуализации. Любая оптимизация этой работы дает ещё большую отдачу в виртуализованном окружении. Разработчики процессоров со временем снизят эту разницу с помощью технологий, подобных EPT и NPT, но полностью она не исчезнет.
[1] Ulrich Drepper. Security Enhancements in Red Hat Enterprise Linux, 2004. URL http://people.redhat.com/drepper/nonselsec.pdf