Библиотека сайта rus-linux.net
Что каждый программист должен знать о памяти
Оригинал: What every programmer should know about memoryАвтор: Ulrich Drepper
Дата публикации: 21.09.2007
Перевод: Капустин С.В.
Дата перевода: 25.03.2009
В то время как ядра процессоров становятся быстрее и многочисленнее, ограничивающим фактором для большинства программ теперь, и будет еще некоторое время в будущем, является доступ к памяти. Разработчики аппаратного обеспечения внедряют все более изощренные технологии ускорения работы памяти, такие как кэши процессоров, но они не могут работать оптимально без некоторой помощи разработчика программного обеспечения. К несчастью, ни структура, ни стоимость использования подсистемы памяти компьютера или кэша процессора хорошо не осознается большинством разработчиков программного обеспечения. Эта статья объясняет структуру подсистемы памяти, используемую в современных массовых компьютерах, показывая, почему были разработаны процессорные кэши, как они работают, и что программа должна делать, чтобы добиться их оптимального использования.
1 Введение
Раньше компьютеры были намного проще. Различные компоненты системы, такие как процессор (ЦПУ), память, устройства хранения данных, сетевые интерфейсы, были разработаны вместе и, следовательно, были вполне сбалансированы по производительности. Например, память и сетевые интерфейсы были не (много) быстрее ЦПУ по пропускной способности.
Эта ситуация изменилась с тех пор как основная структура компьютеров стабилизировалась, и разработчики аппаратного обеспечения сконцентрировались на оптимизации отдельных подсистем. Неожиданно производительность некоторых подсистем отстала от других, и образовались так называемые "бутылочные горлышки". Это, прежде всего, относится к подсистемам хранения данных и памяти, которые из соображений стоимости улучшались медленнее по сравнению с другими компонентами.
Проблему отставания скорости устройств хранения данных решали в основном, используя программные технологии: операционная система хранит наиболее часто используемые (и те, что предположительно будут использованы) данные в основной памяти, которая обеспечивает скорость доступа на порядок больше, чем жесткий диск. И к самим устройствам хранения данных стали добавлять внутренний кэш, так что увеличение производительности достигалось без изменения операционной системы. {Изменения, однако, все равно необходимы, для того, чтобы гарантировать целостность данных.} Исходя из целей этой статьи, мы не будем далее углубляться в программную оптимизацию доступа к устройствам хранения данных.
В отличие от подсистемы хранения данных, устранение проблемы "бутылочного горлышка" для случая основной памяти оказалось более трудным делом, и почти все решения тут требуют изменений в аппаратном обеспечении. На сегодня эти изменения происходят в основном в следующих сферах:
- изменения в аппаратуре RAM (скорость и параллелизм);
- разработка контроллеров памяти;
- кэши ЦПУ;
- прямой доступ к памяти (DMA) для устройств.
Этот документ посвящен в основном кэшам ЦПУ и некоторым эффектам проектирования контроллеров памяти. В процессе исследования этих тем, мы рассмотрим прямой доступ к памяти (DMA) с целью его роли в общей картине. Однако начнем мы с обзора современного аппаратного обеспечения компьютеров. Это потребуется для понимания проблем и ограничений эффективного использования подсистемы памяти. Мы также расскажем о различных типах RAM и о том, почему различия все ещё существуют.
Этот документ ни в коем случае не претендует на полноту. Он ограничивается массовыми компьютерами и некоторым подмножеством их аппаратного обеспечения. Некоторые темы будут обсуждаться лишь настолько подробно, насколько это необходимо для целей этой статьи. Читателям рекомендуется найти более детальную документацию по таким темам.
Когда речь идет о деталях, специфичных для некоторой ОС, и используемых в ОС решениях, речь идет исключительно о Linux. О других ОС не будет дано никакой информации. У автора отсутствует интерес к обсуждению результатов, получающихся для других ОС. Если читатель считает, что он должен использовать другую ОС, он должен потребовать от её производителей написать подобный документ.
Последний комментарий перед началом. Текст содержит некоторое количество терминов "обычно" и других в кавычках. Технология, описываемая здесь, существует реальном мире во множестве вариаций, и эта статья описывает только наиболее распространенные версии. Нечасто бывает возможность делать утверждения, применимые абсолютно ко всем вариантам технологии, отсюда и кавычки.
1.1 Структура документа
Этот документ в основном для разработчиков программного обеспечения. Он не углубляется в технические детали так, чтобы быть полезным для читателей, ориентированных на аппаратное обеспечение. Но прежде, чем мы сможем перейти к практической информации для программистов, необходимый фундамент должен быть заложен.
Для этого вторая глава описывает технические детали памяти с произвольным доступом (RAM - random-access memory). Содержание главы полезно знать, но оно абсолютно не критично для понимания последующих глав. Соответствующие ссылки на эту главу даны в местах, где это требуется, так что нетерпеливый читатель может сначала пропустить большую часть главы.
Третья глава в деталях описывает поведение кэша ЦПУ. Чтобы текст был не таким сухим, используются рисунки. Эта глава существенно необходима для понимания остальной части документа. Глава 4 кратко описывает строение виртуальной памяти. Эта глава также необходима для остального.
Глава 5 описывает в деталях системы, построенные по технологии Non Uniform Memory Access (NUMA).
Глава 6 - это центральная глава всей статьи. Она собирает вместе информацию из предыдущих глав и дает программисту указания как писать код, работающий оптимально при разных ситуациях. Очень нетерпеливый читатель может начать чтение с этой главы и, если необходимо, возвращаться к предыдущим главам, чтобы освежить знания об используемых технологиях.
Глава 7 представляет инструменты, которые могут помочь программисту делать свою работу эффективнее. Даже при полном понимании технологии в сложных программных проектах бывает неочевидно, где кроются проблемы. Некоторые инструменты необходимы.
В главе 8 мы делаем обзор технологий, которые ожидаются в ближайшем будущем, или тех, которые неплохо было бы иметь.
1.2 Сообщения об ошибках
Автор намерен обновлять этот документ в случае обнаружения ошибок и при прогрессе технологий. Читатели, желающие сообщить об ошибках, могут сделать это при помощи электронной почты.
1.3 Благодарности
Хотел бы поблагодарить Джонрэя Фуллера и особенно Джонотана Корбета за участие в непосильной работе по приведению английского языка автора к более или менее общепринятой форме. Маркус Армбрустер предоставил много ценного материала о проблемах и упущениях текста.
1.4 Об этом документе
Заголовок этой статьи отдает дань классической статье Давида Голдберга "Что каждый программист должен знать об арифметике чисел с плавающей точкой". Эта статья все ещё не так широко известна, хотя каждый, кто садится за клавиатуру для серьезного программирования, должен её знать.
2 Современное массовое аппаратное обеспечение
Понимание устройства массового аппаратного обеспечения важно потому, что специализированное аппаратное обеспечение теряет свои позиции. Увеличение масштаба сейчас чаще достигается за счет горизонтального масштабирования, а не за счет вертикального. То есть сегодня проще использовать много небольших, соединенных вместе массовых компьютеров, чем несколько действительно больших очень быстрых (и дорогих) систем. Это так из-за того, что широко доступно недорогое и быстрое сетевое аппаратное обеспечение. Есть все ещё ситуации, когда применяются большие специализированные системы, и они все ещё предоставляют возможности для бизнеса, но в целом рынок почти целиком состоит из массового аппаратного обеспечения. На 2007 год Red Hat ожидает, что в будущем "стандартными строительными блоками" для большинства центров обработки данных будут компьютеры с числом процессоров до четырех, в каждом процессоре по четыре ядра, которые, в случае процессоров Intel будут использовать технологию гиперпоточности. {Гиперпоточность позволяет двум и более программам использовать одно ядро процессора с небольшим количеством дополнительного оборудования.} Это означает, что стандартная система в центре обработки данных будет иметь до 64 виртуальных процессоров. Машины большего размера будут поддерживаться, но четырехпроцессорные четырехъядерные системы представляются наиболее предпочтительными, и основная оптимизация будет направлена на эти машины.
В структуре массовых компьютеров существуют большие различия. Мы охватим более 90% таких компьютеров, концентрируясь на наиболее важных различиях. Имейте в виду, что технические детали меняются быстро, так что читатель должен принимать во внимание дату этой статьи.
Многие годы персональные компьютеры и небольшие серверы были построены на чипсете, состоящем из двух частей: Северный мост (Northbridge) и Южный мост (Southbridge). Рисунок 2.1 показывает эту структуру.

Рисунок 2.1: Структура с Северным и Южным мостом
Все ЦПУ (два в предыдущем примере, но может быть больше) соединены через системную шину (Front Side Bus, FSB) с Северным мостом. Северный мост содержит, кроме всего прочего, контроллер памяти, и его устройство определяет тип чипов RAM, используемых компьютером. Различные типы RAM, такие как DRAM, Rambus, и SDRAM, требуют различные контроллеры памяти.
Чтобы соединиться с другими системными устройствами Северный мост должен обмениваться данными с Южным мостом. Южный мост, часто именуемый мост ввода/вывода обменивается с устройствами через множество различных шин. Сегодня важное значение имеют шины PCI, PCI Express, SATA и USB, но также Южным мостом поддерживаются PATA, IEEE 1394, последовательные и параллельные порты. Более старые системы имеют слоты AGP, присоединенные к Северному мосту. Это делалось из соображений производительности и было связано с недостаточной скоростью обмена данными между Северным и Южным мостом. Однако сегодня слоты PCI-E присоединены к Южному мосту.
Из такой структуры системы вытекает несколько важных следствий:
- Все данные, которыми обмениваются ЦПУ друг с другом идут по той же шине, что используется для обмена данными с Северным мостом.
- Весь обмен данными с RAM проходит через Северный мост.
- У RAM имеется только один порт.
{Мы не обсуждаем многопортовую RAM в этом документе, так как она не применяется в персональных компьютерах, по крайней мере там, где программист имеет к ней доступ. Её можно найти в специализированнам аппаратном обеспечении, таком как сетевые маршрутизаторы, где очень важна скорость.}
- Обмен данными между ЦПУ и устройствами, присоединенными к Южному мосту, идет через Северный мост.
В этом дизайне можно сразу увидеть пару "бутылочных горлышек". Одно такое "бутылочное горлышко" возникает при доступе устройств к RAM. На заре эры персональных компьютеров весь обмен данными с устройствами по любому мосту шел через ЦПУ, негативно влияя на общую производительность системы. Чтобы этого избежать некоторые устройства получили возможность прямого доступа к памяти (DMA - direct memory access). DMA позволяет устройствам получать и сохранять данные в RAM с помощью Северного моста, не используя ЦПУ (и неизбежно влияя на его производительность). Сегодня все высокопроизводительные устройства, подключенные к любому мосту, могут использовать DMA. И хотя это очень сильно снижает загрузку ЦПУ, это создает конкуренцию за пропускную способность Северного моста, так как запросы DMA соревнуются с доступом ЦПУ к RAM. Эта проблема должна приниматься во внимание.
Второе "бутылочное горлышко" относится к шине от Северного моста к RAM. Точные детали устройства этой шины зависят от используемого типа памяти. На старых системах только одна шина ведет ко всем чипам RAM и параллельный доступ невозможен. Современные типы RAM требуют двух раздельных шин (или каналов, как они называются для DDR2, см. рисунок 2.8), что удваивает доступную пропускную способность. Северный мост распределяет доступ к памяти между каналами. Более новые технологии, (FB-DRAM, например) добавляют ещё больше каналов.
Имея в виду ограниченную пропускную способность, важно так составить расписание доступа к памяти, чтобы минимизировать задержки. Как мы увидим, процессоры намного быстрее и должны ждать доступа к памяти, несмотря на использование процессорных кэшей. Когда к памяти одновременно пытаются получить доступ множество процессоров, их ядер или потоков, ожидание становится ещё длиннее. Это также справедливо для операций DMA.
Кроме параллельного доступа к памяти есть и другие проблемы. Сами модели доступа к данным очень сильно влияют на производительность подсистемы памяти, особенно когда есть несколько каналов памяти. Модели доступа к данным RAM будут подробно обсуждаться в разделе 2.2.
На некоторых более дорогих системах Северный мост не содержит контроллера памяти. Вместо этого Северный мост может быть подключен к нескольким внешним контроллерам памяти (в следующем примере к четырем).

Рисунок 2.2: Северный мост с внешними контроллерами памяти
Преимущество такой архитектуры в том, что есть больше, чем одна шина памяти и, следовательно, общая пропускная способность больше. Также этот дизайн поддерживает больший объем памяти. При параллельном доступе к памяти задержка снижается за счет одновременного доступа к разным банкам. Это особенно верно, когда к Северному мосту подключено несколько процессоров, как на рисунке 2.2. Для такого дизайна первичное ограничение - это внутренняя пропускная способность Северного моста, феноменальная для этой архитектуры (от Intel). {Для полноты следует заметить, что такое расположение контроллеров памяти может быть использовано для других целей, таких как ⌠RAID памяти■, полезный при использовании памяти с возможностью горячей замены.}
Использование нескольких контроллеров памяти не единственный способ увеличить пропускную способность памяти. Другой популярный способ - это встраивать контроллеры памяти в ЦПУ и присоединять к каждому ЦПУ память. Эта модель популярна на системах с архитектурой SMP (symmetric multiprocessing), базирующихся на процессорах Opteron от AMD. Рисунок 2.3 показывает такую систему. У Intel, начиная с процессоров Nehalem, будет поддержка технологии Common System Interface (CSI). Это в основном тот же подход: встроенный контроллер памяти с возможностью локальной памяти для каждого процессора.

Рисунок 2.3: Встроенный контроллер памяти
В такой архитектуре количество банков памяти равно количеству процессоров. На четырехпроцессорной машине пропускная способность памяти будет в 4 раза больше и отпадет необходимость в сложном Северном мосте с огромной пропускной способностью. То, что контроллер памяти встроен в ЦПУ, также имеет ряд преимуществ, мы не будем сейчас в это углубляться.
Но у такой архитектуры есть и недостатки. Во-первых, так как по-прежнему вся память машины должна быть доступна для всех процессоров, память более не является однородной (отсюда и название - "архитектура с неоднородной памятью", NUMA - Non-Uniform Memory Architecture). Локальная память процессора доступна ему на обычной скорости. Ситуация меняется, когда нужно получить доступ к памяти, расположенной на другом процессоре. Тут приходится использовать соединения между процессорами. Чтобы получить доступ к памяти ЦПУ2 из ЦПУ1, нужно пройти по одному соединению. Чтобы получить доступ к памяти ЦПУ4 из ЦПУ1, нужно пройти по двум соединениям.
Каждый проход по соединению имеет соответствующую стоимость. Мы говорим о "факторах NUMA", когда описываем дополнительное время, необходимое, чтобы достичь удаленной памяти. Пример архитектуры на рисунке 2.3 имеет два уровня для каждого ЦПУ: ЦПУ, который находится рядом, и ЦПУ, который находится через два соединения. На более сложных машинах число уровней может быть значительно больше. Есть также архитектуры (например x445 у IBM x445 и Altix у SGI), где более одного типа соединения. ЦПУ организованы в узлы, и внутри узла время доступа к памяти может быть однородным или иметь небольшой фактор NUMA. Соединение между узлами может быть очень дорогим, с большим фактором NUMA.
Массовые машины с архитектурой NUMA существуют сегодня и, наверное, будут играть все большую роль в будущем. Ожидается, что с конца 2008 года все машины с технологией SMP будут использовать архитектуру NUMA. Ограничения этой архитектуры делают важной способность программы учитывать то, что она использует NUMA. В главе 5 мы еще обсудим архитектуры машин и некоторые технологии, которые ядро Linux предоставляет для программ.
Кроме технических деталей, описанных в оставшейся части этой главы есть несколько дополнительных факторов, влияющих на производительность RAM. Программное обеспечение не может на них влиять, поэтому в этом разделе они не описываются. Заинтересованный читатель может узнать о некоторых из них в разделе 2.1. Это нужно только для полноты картины и возможно будет полезно при принятии решения о приобретении компьютера.
Следующие две главы обсуждают детали устройства памяти на уровне выходов и протокол доступа между контроллером памяти и чипами DRAM. Программисты найдут эту информацию поучительной, так как эти детали объясняют, почему доступ к RAM работает так, как он работает. Это не обязательное знание и читатель, ищущий темы, более приближенные к повседневной жизни, может перейти к разделу 2.2.5.
2.1 Типы RAM
За прошедшие годы было много типов RAM, и каждый тип отличался, зачастую значительно, от другого. Старые типы сегодня интересны только историкам. Мы не будем исследовать их детали. Вместо этого мы сконцентрируемся на современных типах RAM. Мы пройдем только по поверхности, исследуя детали, видимые ядру ОС или разработчику программного обеспечения через характеристики производительности.
Первые интересные детали сосредоточены вокруг вопроса, почему существуют различные типы RAM на одной и той же машине. Более конкретно, почему существуют вместе статическая RAM (SRAM {В других контекстах SRAM может означать ⌠синхронная RAM■.}) и динамическая RAM (DRAM). Первая намного быстрее и предоставляет ту же функциональность. Почему не вся RAM на машине это SRAM? Ответ, как легко ожидать, в цене. SRAM намного дороже производить и использовать, чем DRAM. Оба этих фактора важны, важность второго возрастает все больше и больше. Чтобы понять эту разницу, мы посмотрим, как реализовано хранение единицы информации для SRAM и DRAM.
В оставшейся части этого раздела обсуждаются низкоуровневые детали реализации RAM. Будем вдаваться в детали ровно настолько, насколько это требуется. То есть будем обсуждать сигналы на "логическом уровне", а не на том уровне, на котором их рассматривают разработчики аппаратного обеспечения. Этот уровень для наших целей достаточен.
2.1.1 Статическая RAM

Рисунок 2.4: 6-транзисторная статическая RAM
Рисунок 2.4 показывает структуру 6-транзисторной ячейки SRAM. Ядро этой ячейки формируется четырьмя транзисторами от M1 до M4, которые формируют два перекрещенных инвертера. Они имеют два стабильных состояния, представляющих 0 и 1 соответственно. Состояние остается стабильным, пока подается напряжение Vdd.
Если нужно узнать состояние ячейки, на линию доступа к слову WL подается ток. Это немедленно делает состояние ячейки доступным на BL и BL. Если нужно записать новое состояние, сначала устанавливаются нужные значения на BL и BL и затем подается ток на WL. Так как внешние генераторы сильнее четырех транзисторов (от M1 до M4), это позволяет перезаписать старое состояние.
Более детальное описание того, как работают ячейки памяти можно найти в [1]. Для дальнейшего обсуждения важно отметить следующее:
- одна ячейка требует шесть транзисторов. Есть варианты с четырьмя транзисторами, но у них есть недостатки.
- поддержание состояния ячейки требует постоянного наличия напряжения.
- состояние ячейки становится доступным почти немедленно после подачи напряжения на WL. Сигнал настолько прямоугольный (быстро меняется между двумя двоичными состояниями) насколько таковыми являются все сигналы, управляемые транзисторами.
- состояние ячейки стабильное, циклы регенерации не требуются.
Есть другие формы SRAM, более медленные и экономичные, но они нам неинтересны, так как мы смотрим на быструю RAM. Эти медленные варианты интересны в основном из-за того, что они могут использоваться вместо динамической RAM, так как имеют более простой интерфейс.
2.1.1 Динамическая RAM
Динамическая RAM по своей структуре намного проще, чем статическая. Рисунок 2.5 показывает структуру типичной ячейки DRAM. Она состоит всего из одного транзистора и одного конденсатора. Огромная разница в сложности означает, конечно, что она и функционирует совсем по-другому.

Figure 2.5: 1-транзисторная динамическая RAM
Ячейка динамической RAM хранит своё состояние в конденсаторе C. Транзистор M служит для того, чтобы охранять доступ к состоянию. Чтобы прочитать состояние ячейки подается ток на линию доступа AL, это приводит к тому, что в зависимости от наличия заряда в конденсаторе на линии DL может появиться или не появиться ток. Чтобы записать данные в ячейку линия DL соответственно устанавливается, затем на AL подается ток на время, достаточное для зарядки или разрядки конденсатора.
Есть некоторые затруднения при реализации схемы работы динамической RAM. Использование конденсатора означает, что чтение ячейки разряжает конденсатор. Эта процедура не может повторяться до бесконечности, в некоторый момент конденсатор необходимо перезарядить. Еще хуже то, что для того, чтобы обеспечивать энергией огромное количество ячеек (сейчас на чипах 109 или больше ячеек) емкость конденсатора должна быть маленькой (на уровне фемтофарад или ниже). Полностью заряженный конденсатор содержит несколько десятков тысяч электронов. И хотя сопротивление конденсатора велико (пара тераОм), он самопроизвольно разряжается за короткое время. Эта проблема называется "утечки".
Из-за утечек ячейки DRAM нужно постоянно подзаряжать. Сейчас для большинства чипов DRAM эта подзарядка происходит каждые 64 миллисекунды. Во время цикла подзарядки доступ к памяти невозможен. В некоторых случаях это задерживает до 50% обращений к памяти (см. [2]).
Вторая проблема, возникающая из-за маленького заряда, это то, что информация, прочитанная из ячейки, не может быть сразу использована. Линия данных должна быть подключена к усилителю считывания, который должен определить, 0 это или 1, так как единицей может быть целый диапазон значений заряда.
Третья проблема, это то, что чтение ячейки истощает заряд конденсатора. Это означает, что после каждой операции чтения должна идти операция перезарядки конденсатора. Это делается автоматически направлением выхода из усилителя считывания обратно в конденсатор. Это означает, однако, что чтение требует дополнительной энергии и, что более важно, времени.
Четвертая проблема, это то, что зарядка и разрядка конденсатора не происходят мгновенно. Сигналы, получаемые усилителем считывания не прямоугольной формы, поэтому нужно использовать консервативную оценку времени, когда может быть использован результат чтения ячейки. Вот формулы зарядки и разрядки конденсатора:
![[Formulas]](/MyLDP/hard/memory/2/capcharg.png)
Это означает, что конденсатору нужно некоторое время (определяемое емкостью C и сопротивлением R), чтобы зарядиться или разрядиться. Это также означает, что ток, который может быть распознан усилителем считывания, появляется не сразу. Рисунок 2.6 показывает кривые зарядки и разрядки. Единицами измерения оси X служат единицы произведения емкости на сопротивление RC, которые являются единицами времени.

Рисунок 2.6: Время зарядки и разрядки конденсатора
В отличие от случая статической RAM, где результат чтения ячейки появляется немедленно после подачи тока на линию доступа слова, всегда проходит некоторое время пока конденсатор отдаст достаточное количество заряда. Эта задержка жестко ограничивает скорость DRAM.
Простой подход имеет и свои преимущества. Основное - это размер. Площадь на чипе, необходимая для одной ячейки DRAM во много раз меньше площади для ячейки SRAM. Ячейкам SRAM также необходимо отдельное питание для транзисторов, поддерживающих её состояние. Структура ячейки DRAM также позволяет располагать рядом друг с другом много ячеек, образующих матрицу.
В общем, значительная разница в стоимости побеждает. Везде, кроме специализированного аппаратного обеспечения (например, сетевых маршрутизаторов), мы вынуждены жить с основной памятью, основанной на DRAM. Это оказывает громадное влияние на работу программиста, что мы и обсудим далее в этой статье. Но сначала ещё несколько деталей об использовании DRAM.
2.1.3 Доступ к DRAM
Программа выбирает расположение данных в памяти, используя виртуальный адрес. Процессор преобразует его в физический адрес и, окончательно, контроллер памяти выбирает чип RAM, соответствующий этому адресу. Чтобы выбрать конкретную ячейку памяти на чипе RAM, передается физический адрес в форме некоторого количества адресных линий.
Было бы совершенно непрактично адресовать каждый участок памяти непосредственно из контроллера памяти: 4Гб RAM потребовали бы 232 адресных линий. Вместо этого адрес передается как двоичное число, используя меньшее количество адресных линий. В чипе DRAM этот адрес нужно, прежде всего, демультиплексировать. Демультиплексор с N адресными линиями будет иметь 2N выходов. Эти выходы будут использоваться для выбора ячейки памяти. Использование такого прямого подхода не является проблемой для чипов небольшого размера.
Но число ячеек растет, и этот подход больше не работает. Чип с емкостью 1Гбит (ненавижу эти десятичные префиксы из СИ. Для меня гигабит всегда будет 230, а не 109 бит.) потребовал бы 30 адресных линий и 230 линий выбора. Размер демультиплексора растет экспоненциально при росте числа входных линий, если мы не хотим жертвовать скоростью. Демультиплексор с 30 входными линиями занимает большую площадь на чипе и вдобавок очень сложен. Еще важнее то, что передать 30 импульсов по адресным линиям синхронно намного сложнее, чем, скажем, "всего" 15. Меньше линий придется в этом случае подгонять по длине так, чтобы сигнал доходил до конца по ним одновременно. {Современные типы DRAM такие, как DDR3, могут автоматически подгонять время, но есть пределы допустимых расхождений.}
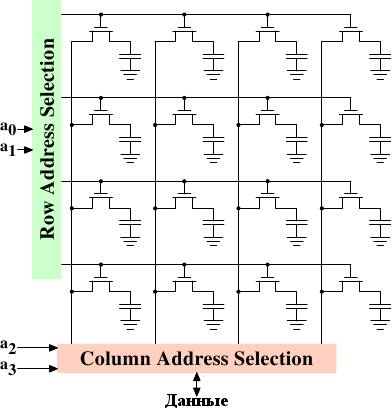
Рисунок 2.7: Схема динамической RAM
На рисунке 2.7 изображена упрощенная схема строения DRAM. Ячейки DRAM организованы в строки и колонки. Можно было бы расположить их в одной строке, но тогда потребовался бы огромный демультиплексор. А так мы можем обойтись одним мультиплексором и одним демультиплексором общим размером вполовину меньше. {Мультиплексоры и демультиплексоры эквивалентны, и мультиплексор здесь будет работать как демультиплексор при записи. Поэтому отныне мы будем их отождествлять.} Это огромная экономия со всех сторон. В этом примере адресные линии a0 и a1 через демультиплексор выбора адреса строки (RAS - row address selection) выбирают адресную линию целой строки ячеек. При чтении содержимое всех ячеек строки подается на мультиплексор выбора адреса колонки (CAS - column address selection) {линия над именами означает логическое отрицание}. На основе адреса, полученного по адресным линиям a2 и a3, содержимое одной из колонок подается на выход чипа DRAM. Это происходит параллельно на некотором количестве чипов DRAM, для того чтобы получить количество бит, соответствующее ширине шины данных.
При записи новое значение ячейки подается на шину данных и, когда ячейка выбрана через RAS и CAS, оно сохраняется в ячейке. Очень простой дизайн. Конечно, в реальности намного больше сложностей. При чтении нужно определить задержку, с которой данные поступают на шину данных, после подачи сигнала с адресом. Мы знаем из предыдущего раздела, что конденсаторы не отдают заряд мгновенно. Сигнал от ячеек такой слабый, что его нужно усиливать. При записи нужно определить, как долго должен подаваться сигнал с данными на шину, после того как выбраны адреса строк и колонок, чтобы успешно сохранить новое значение в ячейке (опять же конденсаторы не заряжаются мгновенно). Эти временные константы являются ключевыми для производительности чипа DRAM. Мы обсудим их в следующем разделе.
Ещё одна проблема масштабируемости состоит в том, что невозможно к каждому чипу подвести 30 адресных линий. Ножки чипа это драгоценный ресурс. К сожалению, данные по возможности должны передаваться параллельно (например, в 64 битных командах). Контроллер памяти должен уметь делать адресацию каждого модуля RAM (набора чипов RAM). Если по соображениям производительности требуется параллельный доступ к нескольким модулям RAM, и каждый модуль RAM требует свой набор из 30 или более адресных линий, тогда контроллеру памяти для 8 модулей RAM потребовалось бы более 240 ножек только для адресации.
Чтобы решить эту проблему, чипы DRAM уже давно мультиплексируют адреса самостоятельно. Это означает, что адрес передается двумя частями. Первая часть адресных бит (a0 и a1 в примере на рисунке 2.7) выбирает строку. Этот выбор остается активным, пока его не отменяют. Затем вторая часть, адресные биты a2 и a3, выбирает колонку. Ключевое отличие в том, что нужны только две внешние адресные линии. Ещё несколько линий будет необходимо для того, чтобы показывать, когда сигналы RAS и CAS готовы, но это небольшая плата за уменьшение числа адресных линий вдвое. Это мультиплексирование адресов само по себе, однако, создает некоторые проблемы. Мы обсудим их в разделе 2.2.
2.1.4 Выводы
Не беспокойтесь, если детали этого раздела покажутся вам неясными. Вот все важные вещи, которые нам понадобятся в дальнейшем:
- есть причины, почему не вся память является памятью типа SRAM
- чтобы использовать конкретную ячейку памяти, её нужно предварительно выбрать
- число адресных линий непосредственно влияет на стоимость контроллера памяти, материнской платы, модуля DRAM и чипа DRAM
- результаты операций чтения и записи доступны не сразу, а через некоторое время
В следующем разделе мы немного углубимся в детали процесса доступа к памяти DRAM. Мы не будем больше обсуждать детали доступа к SRAM, которая обычно адресуется напрямую. Так поступают для большей скорости и из-за небольшого размера SRAM. SRAM в настоящее время используется как встроенная в кэшах ЦПУ, а там размер соединений маленький и полностью под контролем разработчика ЦПУ. Кэши ЦПУ мы обсудим позже, но все, что мы должны знать, это то, что ячейки SRAM имеют определенную максимальную скорость, которая зависит от напряжения, приложенного к SRAM. Эта скорость может варьироваться от немного медленнее, чем ядро ЦПУ, до на один или два порядка медленнее.
2.2 Технические детали доступа к DRAM
В предыдущем разделе мы видели, что чипы DRAM мультиплексируют адреса, чтобы сэкономить ресурсы. Мы также видели, что доступ к ячейкам DRAM требует времени, так как конденсаторы в этих ячейках разряжаются таким образом, что не сразу выдают стабильный сигнал. Мы также видели, что ячейки DRAM необходимо подзаряжать. Теперь пришло время собрать это все вместе и посмотреть, как эти факторы определяют детали доступа к DRAM.
Мы сконцентрируемся на современной технологии, мы не будем обсуждать асинхронную DRAM и её варианты, так как они неактуальны. Читатели, заинтересованные этой темой, отсылаются к [2] и [3]. Мы также не будем говорить о Rambus DRAM (RDRAM), хотя эта технология и не является вышедшей из употребления. Просто она не используется широко в системной памяти. Мы сконцентрируемся исключительно на синхронной DRAM (SDRAM - Synchronous DRAM) и её последовательнице Double Data Rate DRAM (DDR).
Синхронная DRAM, как следует из её названия, работает по источнику времени. В контроллере памяти имеется тактовый генератор, частота которого определяет частоту системной шины (FSB - Front Side Bus) - интерфейс контроллера памяти, используемый чипами DRAM. Во время написания этого текста используются частоты 800МГц, 1066МГц, и даже 1333МГц, а частота 1600МГц анонсирована для следующего поколения. Это не означает, что частота шины действительно такая высокая. Вместо этого за один такт данные передаются два или четыре раза. Большие числа лучше продаются, поэтому производители рекламируют шину 200МГц с учетверенной скоростью передачи данных как шину с "эффективной" частотой 800МГц.
Сегодня для SDRAM одна порция передачи данных составляет 64 бит - 8 байт. Следовательно, скорость передачи данных для FSB это 8 байт умножить на эффективную частоту шины (6.4Гб/с для шины 200МГц с учетверенной скоростью передачи данных). Кажется, что это много, но это пиковая скорость, максимум, который невозможно превзойти. Как мы увидим, протокол обмена данными с модулем RAM предполагает наличие множества отрезков времени, когда никакие данные не передаются. Это как раз такие отрезки времени, которые мы должны научиться понимать и минимизировать, чтобы добиться наилучшей производительности.
2.2.1 Протокол доступа к чтению
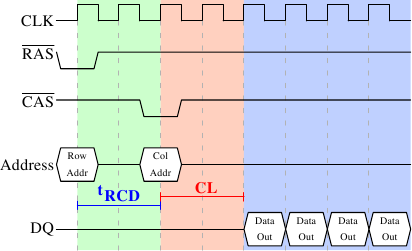
Рисунок 2.8: Временные диаграммы протокола доступа к чтению из SDRAM
Рисунок 2.8 показывает активность на некоторых выходах модуля DRAM, которую можно разделить на три фазы, которые на рисунке окрашены в разные цвета. Как обычно, время течет слева направо. Многие детали опущены. Здесь мы говорим только о тактовых импульсах шины, сигналах RAS и CAS и шинах адреса и данных. Цикл чтения начинается с того, что контроллер памяти посылает по адресной шине адрес строки и понижает уровень сигнала RAS. Все сигналы читаются во время повышения уровня сигнала тактового генератора (CLK), поэтому не имеет значения, что сигналы не совсем прямоугольной формы - лишь бы они были стабильны, когда их начнут читать. Установка адреса строки побуждает чип RAM фиксировать адресную строку.
Сигнал CAS может быть послан через tRCD (RAS-to-CAS Delay) тактов. Затем по адресной шине передается адрес колонки и понижается уровень сигнала CAS. Здесь мы видим как две части адреса (практически половинки) могут быть переданы по одной и той же адресной шине.
Наконец адресация закончена и можно передавать данные. Чипу RAM нужно некоторое время, чтобы подготовить это. Эта задержка обычно называется CAS Latency (CL). На рисунке 2.8 она равна 2. Она может быть выше или ниже, в зависимости от качества контроллера памяти, материнской платы и модуля DRAM. Она также может принимать половинные значения. При CL=2.5 первые данные начнут передаваться на первом понижении сигнала тактового генератора в синей области.
Со всеми этими приготовлениями было бы расточительно передавать только одно слово данных. Вот почему модули DRAM позволяют контроллеру памяти задавать количество передаваемых данных. Обычно выбор между 2, 4, или 8 словами. Это позволяет заполнить целые строки кэшей без новой последовательности RAS/CAS. Контроллер памяти может также послать сигнал CAS без нового выбора строки. Так можно считывать или записывать последовательно идущие адреса памяти значительно быстрее, из-за того, что не нужно посылать сигнал RAS и деактивировать строку (см. ниже). Контроллер памяти должен решать, хранить ли строку "открытой". Теоретически, если держать её все время открытой, то это может иметь отрицательные последствия в существующих приложениях (см. [2]). Когда посылать новый сигнал CAS - определяется свойством Command Rate модуля RAM (обычно обозначается как Tx, где x это значение такое как 1 или 2, оно будет равно 1 для высокопроизводительных модулей DRAM, которые принимают новые команды каждый цикл).
В этом примере SDRAM выдает одно слово за цикл. Это то, что может делать первое поколение. DDR может передавать два слова за цикл. Это сокращает время передачи, но не изменяет задержку. В принципе, DDR2 работает так же, хотя на практике это выглядит по-другому. Здесь нет необходимости углубляться в детали. Достаточно отметить, что DDR2 можно сделать быстрее, дешевле, более надежной и более энергоэффективной (см. [4] для более подробной информации).
2.2.2 Предварительная зарядка и активация
Рисунок 2.8 не покрывает полный цикл. Он показывает только часть полного цикла доступа к DRAM. Перед тем как можно будет послать новый сигнал RAS текущая выбранная строка должна быть деактивирована и новая строка должна быть заряжена. Мы можем сконцентрироваться здесь на случае, когда это делается явной командой. Есть улучшения протокола, которые, в некоторых случаях, позволяют обойтись без этого дополнительного шага. Однако задержка, вызванная зарядкой, все равно влияет на операцию.
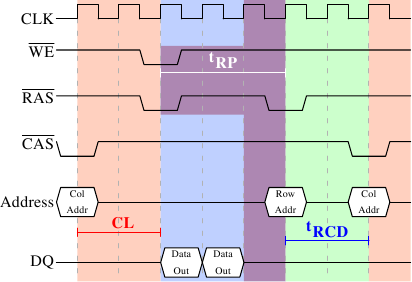
Рисунок 2.9: Предварительная зарядка и активация SDRAM
Рисунок 2.9 показывает активность, начинающуюся от одного сигнала CAS, и заканчивающуюся сигналом CAS для другой строки. Данные, затребованные первым сигналом CAS, появляются как и раньше через CL циклов. В этом примере затребованы два слова, на передачу которых SDRAM требуется два цикла. Можно представить себе четыре слова на чипе DDR.
Даже на модулях DRAM с command rate равным 1 команда на предварительную зарядку не может быть запущена сразу. Необходимо ждать пока передаются данные. В нашем случае это два цикла. Получается то же, что и CL, но это просто совпадение. Сигнал на предварительную зарядку не имеет специальной выделенной линии. Вместо этого на некоторых реализациях используется одновременное понижение уровней Write Enable (WE) и RAS. Эта комбинация не имеет смысла сама по себе (см. подробности кодирования в [5]).
После того, как команда на предварительную зарядку передана, нужно ждать tRP (Row Precharge time) циклов до того как строка может быть выбрана. На рисунке 2.9 большая часть этого времени (обозначенная фиолетовым цветом) пересекается с передачей данных (светло-синий). Это хорошо! Но tRP больше, чем время передачи данных, поэтому следующий сигнал RAS задерживается на один цикл.
Если бы мы продолжили ось времени в диаграмме, то обнаружили бы, что следующая передача данных начинается через 5 циклов после окончания текущей. Это значит, что шина данных используется только в двух циклах из семи. Умножьте это на скорость FSB, и теоретические 6.4Гб/с для шины частотой 800МГц превратятся в 1.8Гб/с. Это плохо, и этого следует избегать. Техники, описанные в главе 6, помогут увеличить эту скорость. Но программист должен для этого постараться.
Есть ещё одна временная константа для модулей SDRAM, которую мы не обсудили. На рисунке 2.9 команда на предварительную зарядку ограничена только временем передачи данных. Другое ограничение состоит в том, что модулю SDRAM необходимо время после сигнала RAS, прежде чем он сможет заряжать другую строку (это время обозначается tRAS). Это число обычно довольно высоко, в два или три раза больше значения tRP. Это проблема, если после сигнала RAS следует только один сигнал CAS и передача данных заканчивается через несколько циклов. Предположим, что на рисунке 2.9 первому сигналу CAS непосредственно предшествует сигнал RAS и tRAS равно 8 циклам. Тогда команду на предварительную зарядку нужно отложить на один цикл, так как сумма tRCD, CL, и tRP (т.к. оно больше, чем время передачи данных) составляет всего 7 циклов.
Модули DDR часто описываются, используя специальную нотацию: w-x-y-z-T. Например: 2-3-2-8-T1. Это означает:
w 2 CAS Latency (CL) x 3 RAS-to-CAS delay (tRCD) y 2 RAS Precharge (tRP) z 8 Active to Precharge delay (tRAS) T T1 Command Rate
Есть ещё множества временных констант, которые влияют на то, как должны даваться и исполняться команды. Но на практике этих пяти констант достаточно, чтобы определять производительность модуля.
Иногда полезно знать эту информацию об используемом компьютере, чтобы правильно интерпретировать определенные измерения. И определенно полезно знать эти детали, когда покупаешь компьютер, так как они, вместе со скоростями FSB и SDRAM, являются одними из важнейших факторов, определяющих производительность компьютера.
Склонный к приключениям читатель может также попытаться настроить систему. Иногда BIOS позволяет изменять некоторые или все из этих значений. У модулей SDRAM имеются программируемые регистры, где можно установить эти значения. Обычно BIOS выбирает наилучшее из значений по умолчанию. Если модуль RAM высокого качества, то может быть будет возможно уменьшить одну из задержек, не влияя на стабильность компьютера. Многочисленные оверклокерские сайты в Интернете предлагают уйму документации об этом. Делайте это на свой страх и риск, но не говорите потом, что вас не предупреждали.
2.2.3 Перезарядка
Наиболее часто упускаемая тема при рассмотрении доступа к DRAM это перезарядка. Как было показано в разделе 2.1.2, ячейки DRAM нужно постоянно освежать. И это не происходит незаметно для остальной части системы. Когда строка перезаряжается (единица измерения здесь строка (см. [5]) хотя в [2] и другой литературе утверждается иное), доступ к ней невозможен. Исследование в [2] показывает, что "удивительно, но организация перезарядки DRAM может драматически влиять на производительность".
Согласно спецификации JEDEC (Joint Electron Device Engineering Council), каждая ячейка DRAM должна перезаряжаться каждые 64мс. Если массив DRAM имеет 8192 строк, это означает, что контроллер памяти должен посылать команду на перезарядку в среднем каждые 7.8125 микросекунд (эти команды могут быть поставлены в очередь и поэтому на практике максимальный интервал между двумя из них может быть больше). Управлять расписанием команд на перезарядку является обязанностью контроллера памяти. Модуль DRAM помнит адрес последней перезаряженной строки и автоматически увеличивает счетчик адреса для каждой новой команды.
Программист мало может влиять на перезарядку и моменты времени, когда эти команды даются. Но важно иметь эту часть жизненного цикла DRAM в виду, когда интерпретируешь измерения. Если важное слово должно быть прочитано из строки, а строка в этот момент перезаряжается, процессор может быть в простое довольно большое время. Как долго длится зарядка, зависит от модуля DRAM.
2.2.4 Типы памяти
Стоит потратить немного времени на описание существующих типов памяти и их ближайших последователей. Мы начнем с SDR (Single Data Rate) SDRAM, так как они являются базисом для DDR (Double Data Rate) SDRAM. SDR были очень простыми. Скорость ячеек памяти и передачи данных была одинаковой.
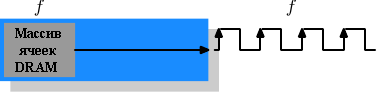
Рисунок 2.10: Операции SDR SDRAM
На рисунке 2.10 ячейка памяти DRAM может выдавать содержимое памяти с той же скоростью, с которой оно транспортируется по шине памяти. Если ячейка DRAM может работать на частоте 100МГц, то скорость передачи данных шиной будет 100Мб/с. Частота f для всех компонентов одинакова. Повышать пропускную способность чипа DRAM дорого, так как потребление энергии растет с ростом частоты. Учитывая огромное число массивов ячеек это невозможно дорого. {Энергопотребление = Динамическая емкость × Напряжение2 × Частота}. В действительности это ещё большая проблема, так как увеличение частоты также требует увеличения напряжения для поддержания стабильности системы. В DDR SDRAM (впоследствии называемая DDR1) пропускная способность была повышена без увеличения какой-либо из задействованных частот.
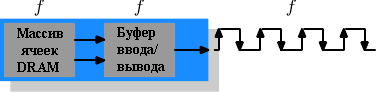
Рисунок 2.11: Операции DDR1 SDRAM
Различие между SDR и DDR1, как можно увидеть на рисунке 2.11 и понять из имени, в том, что за один цикл передается двойной объем данных. То есть чип DDR1 может передавать данные на увеличении и уменьшении уровня сигнала. Это иногда называют шиной с "двойной прокачкой". Чтобы сделать это возможным без увеличения частоты массива ячеек памяти применяется буфер. Буфер хранит по два бита на каждую линию данных. Для этого, в свою очередь требуется, чтобы массив ячеек на рисунке 2.7 имел шину данных из двух линий. Реализация этого тривиальна: нужно использовать одинаковый адрес колонки для двух ячеек DRAM и обращаться к ним параллельно. Изменения массива ячеек будут минимальными.
SDR DRAM были известны просто по их частоте (например, PC100 для 100МГц SDR). Чтобы улучшить звучание DDR1 DRAM маркетологи должны были изменить эту схему, так как частота не изменилась. Они приняли имя, которое содержит скорость передачи в байтах, которую поддерживает модуль DDR (он имеет шину шириной 64 бит):
100МГц × 64бит × 2 = 1600Мб/с
Следовательно, модуль DDR с частотой 100МГц называется PC1600. С 1600 > 100 все маркетинговые требования соблюдены - звучит намного лучше, хотя реальное улучшение только в два раза. {Я бы понял, если бы увеличили в два раза, а то получаются дутые числа.}
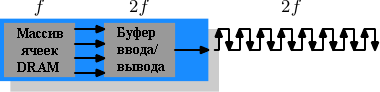
Рисунок 2.12: Операции DDR2 SDRAM
Чтобы получить от технологии ещё больше DDR2 включает ещё немного инноваций. Самое очевидное изменение, как можно видеть из рисунка 2.1 это удвоение частоты шины. Удвоение частоты означает удвоение пропускной способности. Так как удвоение частоты экономически неоправданно для массива ячеек, теперь требуется, чтобы буфер ввода/вывода получал по четыре бита за один цикл, которые он затем передает по шине. Это означает, что изменения в модуле DDR2 состоят в увеличении скорости буфера ввода/вывода DIMM. Это определенно возможно и не требует значительно больше энергии - это всего лишь один небольшой компонент, а не весь модуль. Имя, которое маркетологи придумали для DDR2, аналогично имени для DDR1, только в вычислении значения множитель два заменяется на четыре (теперь у нас шина с "четверной прокачкой"). Рисунок 2.13 показывает используемые сегодня имена модулей.
Частота
массиваЧастота
шиныСкорость
данныхИмя
(скорость)Имя
(FSB)133МГц 266МГц 4256Мб/с PC2-4200 DDR2-533 166МГц 333МГц 5312Мб/с PC2-5300 DDR2-667 200МГц 400МГц 6400Мб/с PC2-6400 DDR2-800 250МГц 500МГц 8000Мб/с PC2-8000 DDR2-1000 266МГц 533МГц 8512Мб/с PC2-8500 DDR2-1066 Рисунок 2.13: Имена модулей DDR2
В названии есть ещё один трюк. Скорость FSB, используемая ЦПУ, материнской платой и модулем DRAM выражена через "эффективную" частоту. То есть она умножается на 2 из-за того, что передача данных идет при повышении и понижении уровня сигнала тактового генератора и число увеличивается. Итак, модуль 133МГц с шиной 266МГц имеет "частоту" FSB 533МГц.
Спецификация DDR3 (настоящей, а не GDDR3, используемой в графических картах) подразумевает дальнейшие изменения, продолжающие логику перехода к DDR2. Напряжение будет понижено с 1.8В для DDR2 до 1.5В для DDR3. Так как энергопотребление пропорционально квадрату напряжения это одно дает 30% улучшения. Добавьте к этому уменьшение микросхемы и другие электрические улучшения, и DDR3 может на той же частоте потреблять половину энергии. А на большей частоте обходиться таким же количеством. Или можно вдвое увеличить емкость для такого же количества выделения тепла.
Массив ячеек модуля DDR3 будет работать на четверти скорости внешней шины, что потребует восьмибитного буфера ввода/вывода, больше по сравнению с четырехбитным в DDR2. На рисунке 2.14 изображена схема.
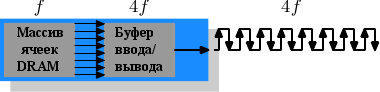
Рисунок 2.14: Операции DDR3 SDRAM
Скорее всего, поначалу модули DDR3 будут иметь немного большую задержку CAS чем DDR2, потому что DDR2 более зрелая технология. Поэтому использовать DDR3 будет иметь смысл только на более высоких частотах, чем те, которые достижимы для DDR2, или когда пропускная способность важнее, чем задержка. Уже ходят разговоры о модулях с напряжением 1.3В, у которых будет та же задержка CAS, как и у DDR2. В любом случае, возможность достичь более высоких скоростей из-за более быстрых шин перевесит увеличение задержки.
Одна возможная проблема с DDR3 состоит в том, что на скорости 1600Мб/с и выше, число модулей на канал может быть сокращено до одного. В ранних версиях это ограничение присутствовало для всех частот, так что можно надеяться, что со временем оно будет снято для всех частот. Иначе емкость систем будет жестко ограничена.
Рисунок 2.15 показывает ожидаемые имена модулей DDR3. JEDEC к этому времени одобрило первые четыре типа. Учитывая, что 45-нанометровые процессоры Intel имеют скорость FSB 1600Мб/с, необходимо иметь 1866Мб/с для рынка оверклокеров. Скорее всего, мы увидим это ближе к концу жизненного цикла DDR3.
Частота
массиваЧастота
шиныСкорость
данныхИмя
(скорость)Имя
(FSB)100МГц 400МГц 6400Мб/с PC3-6400 DDR3-800 133МГц 533МГц 8512Мб/с PC3-8500 DDR3-1066 166МГц 667МГц 10667Мб/с PC3-10667 DDR3-1333 200МГц 800МГц 12800Мб/с PC3-12800 DDR3-1600 233МГц 933МГц 14933Мб/с PC3-14900 DDR3-1866 Рисунок 2.15: Имена модулей DDR3
Вся память DDR имеет одну проблему - увеличение частоты шины делает трудным создание параллельных шин данных. Модуль DDR2 имеет 240 контактов. Все соединения до контактов данных и адреса должны быть сделаны так, чтобы они имели приблизительно одинаковую длину. Ещё более проблематично то, что когда на одной шине несколько модулей DDR, сигналы становятся все более и более искаженными для каждого дополнительного модуля. Спецификация DDR2 разрешает использовать только два модуля на одной шине (канале), DDR3 - только один модуль на высоких частотах. С 240 контактами на канал, один Северный мост не может хорошо управлять более чем двумя каналами. В качестве альтернативы можно использовать внешние контроллеры памяти (см. рисунок 2.2), но это очень дорого.
Все это означает, что материнские платы массовых компьютеров могут иметь не более четырех модулей DDR2 или DDR3. Это жестко ограничивает количество памяти, которое может иметь система. Даже старые 32-битные процессоры IA-32 поддерживали до 64Гб RAM, и потребность в большом количестве памяти растет даже для домашних систем, поэтому надо что-то делать.
Одно решение - это добавлять контролеры памяти в каждый процессор, как показано в начале этой главы. AMD делает это на линейке процессоров Opteron, и Intel будет делать в технологии CSI. Это может помочь до тех пор, пока количество памяти, которое способен использовать процессор, может быть присоединено к каждому процессору. В некоторых ситуациях это не так и этот подход приводит к архитектуре NUMA с её негативными эффектами. Для некоторых ситуаций нужно вообще другое решение.
Решение Intel для больших серверных машин, по крайней мере на ближайшие годы, называется Fully Buffered DRAM (FB-DRAM). Модули FB-DRAM используют те же компоненты, что и сегодняшние модули DDR2, что делает их относительно дешевыми в производстве. Разница в соединении с контроллером памяти. Вместо параллельной шины данных FB-DRAM использует последовательную шину (то же было у Rambus DRAM и у SATA, последователе PATA, и у PCI Express после PCI/AGP). Последовательной шиной можно управлять на значительно более высокой частоте, преодолевая негативный эффект сериализации, и даже увеличивая пропускную способность. Основные эффекты от использования последовательной шины:
- можно использовать больше модулей на одном канале,
- можно использовать больше каналов на одном Северном мосте/контроллере памяти,
- последовательная шина является полнодуплексной (две линии).
Модуль FB-DRAM имеет только 69 контактов, вместо 240 у DDR2. Использовать вместе несколько модулей FB-DRAM намного легче, так как электрическими эффектами такой шины легче управлять. Спецификация FB-DRAM позволяет использовать до 8 модулей на один канал.
Учитывая требования к соединениям, предъявляемые двухканальным Северным мостом, теперь возможно управлять шестью каналами FB-DRAM с меньшим количеством контактов: 2×240 против 6×69. Путь на плате до каждого канала также намного проще, что может помочь снизить цену материнских плат.
Параллельные шины с полным дуплексом слишком дороги для традиционных модулей DRAM - очень затратно удваивать количество линий. С последовательными линиями (даже если они разностные, как требует FB-DRAM) это не так, поэтому последовательная шина сделана полностью дуплексной, что означает, в некоторых ситуациях, что пропускная способность удваивается только из-за этого. Но это не единственный случай, когда параллелизм используется для увеличения пропускной способности. Так как контроллер FB-DRAM может обслуживать до шести каналов одновременно, пропускная способность при использовании FB-DRAM может быть увеличена даже для систем с небольшим количеством RAM. Там где система на DDR2 с четырьмя модулями имеет два канала, та же емкость может обслуживаться через четыре канала обычным контроллером FB-DRAM. Реальная пропускная способность последовательной шины зависит от того, какие чипы DDR2 (или DDR3) используются в модулях FB-DRAM.
Мы можем суммировать преимущества таким образом:
DDR2 FB-DRAM Контакты 240 69 Каналы 2 6 DIMM/канал 2 8 Max памяти 16Гб 192Гб Скорость ~10Гб/с ~40Гб/с
Есть отрицательные стороны FB-DRAM при использовании нескольких DIMM на одном канале. Сигнал задерживается, хотя и минимально для каждой DIMM в цепи, что означает увеличение задержки. Но для того же количества памяти на той же частоте FB-DRAM всегда будет быстрее, чем DDR2 и DDR3, так как на канал нужна только одна DIMM. Для систем с большим объемом памяти у DDR просто нет решения на массовых компонентах.
2.2.5 Выводы
Этот раздел должен был показать, что доступ к DRAM не может быть сколь угодно быстрым процессом. По крайней мере по сравнению со скоростью процессора и скоростью доступа процессора к регистрам и кэшу. Важно держать в уме различия между частотами ЦПУ и памяти. Процессор Intel Core 2 имеет частоту 2.933ГГц, и системная шина с частотой 1.066ГГц будут иметь отношение тактовых частот 11:1 (заметьте, что данные на шину подаются вчетверо быстрее её частоты). Простой в один цикл памяти означает простой 11 циклов процессора. В большинстве машин реально используются более медленные DRAM, что ещё более увеличивает задержку. Держите эти цифры в уме, когда мы будем говорить о простоях в последующих главах.
Графики для команд чтения показывают, что модули DRAM способны передавать данные с большой и устойчивой скоростью. Целые строки DRAM могут передаваться без единой задержки. Шина данных может оставаться на 100% загруженной. Для модулей DDR это означает, что в каждом цикле передается два 64-битных слова. Для модулей DDR2-800 на двух каналах это 12.8Гб/с.
Но доступ к DRAM не всегда последователен, если конечно он не специально так организован. Используются отдаленные друг от друга участки памяти, что означает, что неизбежно использование предварительной зарядки и новых сигналов RAS. Вот тогда все замедляется и модулям DRAM нужна помощь. Чем скорее случится предварительная зарядка и послан сигнал RAS, тем меньше расходы на использование новой строки.
Чтобы сократить простои и создать большее перекрытие по времени операций их вызывающих, используется аппаратная и программная предварительная выборка (см. раздел 6.3). Она также помогает переместить операции с памятью во времени так, что достаточно будет задействовать меньшее количество ресурсов позднее, перед тем как данные непосредственно понадобятся. Нередко возникает проблема, когда данные, произведенные в одном раунде нужно сохранить, а данные, необходимые в следующем раунде нужно прочитать. Перемещая чтение во времени, мы добьемся того, что операции чтения и записи не нужно будет делать одновременно.
2.3 Другие пользователи основной памяти
Кроме процессоров есть другие компоненты системы, имеющие доступ к основной памяти. Высокопроизводительные карты, например сетевые и контроллеры накопителей не могут позволить себе пропускать все используемые ими данные через процессор. Вместо этого они читают и записывают данные непосредственно в основную память (Direct Memory Access, DMA). На рисунке 2.1 мы можем видеть, что эти карты могут через Южный и Северный мосты обмениваться данными непосредственно с памятью. Другим шинам, например USB, также требуется пропускная способность FSB, хотя они и не используют DMA, так как Южный мост соединен с Северным также через FSB.
Хотя DMA определенно полезен, он подразумевает ещё большую конкуренцию за пропускную способность FSB. Во время высокой активности трафика DMA процессор может простаивать дольше обычного, ожидая данных от основной памяти. Этого можно избежать на соответствующем оборудовании. С архитектурой как на рисунке 2.3 вычисления используют память на узлах, на которые DMA не влияет. Также возможно присоединить Южный мост к каждому узлу, равномерно распределяя загрузку FSB между всеми узлами. Есть множество возможностей. В главе 6 мы обсудим техники и программные интерфейсы, которые позволят делать возможные в программном обеспечении улучшения.
И в конце нужно упомянуть, что некоторые дешевые системы содержат подсистемы графики без выделенной видеопамяти. Такие системы используют в качестве видеопамяти части основной памяти. Так как доступ к видеопамяти происходит часто (для дисплея размера 1024x76 с 16-битным цветом на 60Гц мы говорим о 94Мб/с) и системная память, в отличие от видеопамяти не имеет двух портов, это может сильно влиять на производительность системы и особенно на задержку. Когда производительность является приоритетом, лучше игнорировать такие системы. От них только больше хлопот, чем пользы. Люди, покупающие такие машины должны осознавать, что они не получат лучшей производительности.
[1] Wikipedia. Static random access memory. http://en.wikipedia.org/wiki/Static_Random_Access_Memory, 2006.
[2] Vinodh Cuppu, Bruce Jacob, Brian Davis and Trevor Mudge. High-Performance DRAMs in Workstation Environments. IEEE Transactions on Computers, 50(11):1133--1153, 2001.
[3] Stokes, Jon ``Hannibal''. Ars Technica RAM Guide, Part II: Asynchronous and Synchronous DRAM. http://arstechnica.com/paedia/r/ram_guide/ram_guide.part2-1.html, 2004.
[4] Dowler, M. Introduction to DDR-2: The DDR Memory Replacement. http://www.pcstats.com/articleview.cfm?articleID=1573, 2004.
[5] Double Data Rate (DDR) SDRAM MT46V. Micron Technology, 2003.
| Оглавление |