Библиотека сайта rus-linux.net
Что каждый программист должен знать о памяти, часть 7. Инструменты для повышения производительности памяти
Оригинал: Memory part 7: Memory performance toolsАвтор: Ulrich Drepper
Дата публикации: ноябрь 2007 г.
Перевод: М.Ульянов
Дата перевода: 5 мая 2010 г.
Инструменты для повышения производительности памяти
Существует множество инструментов, помогающих программисту понять, как программа использует кэш и память. Современные процессоры позволяют оценивать производительность на аппаратном уровне. Но некоторые вещи не измеришь напрямую, поэтому нельзя отказаться и от программного моделирования. На верхнем функциональном уровне также имеются специальные инструменты контроля за выполнением процесса. Далее представлен набор широко используемых средств, доступных на большинстве Linux-систем.
7.1 Профилирование памяти
Для профилирования памяти необходима аппаратная поддержка. Конечно, можно собрать какую-то информацию исключительно программными средствами, но то будут либо грубые подсчеты, либо только моделирование. Примеры подобного моделирования можно наблюдать в разделах 7.2 и 7.5. В текущем же разделе сосредоточимся на том, что можно измерить напрямую аппаратными средствами.
В Linux доступ к аппаратному мониторингу производительности обеспечивается через oprofile, который предоставляет возможности по непрерывному профилированию (см. [continuous]); осуществляет статистическое общесистемное профилирование с удобным интерфейсом. Oprofile - далеко не единственный способ использования функциональности процессоров для оценки производительности; разработчики Linux работают над pfmon, который в перспективе может достаточно широко распространиться, став достойным представителем своего класса.
Oprofile предоставляет низкоуровневый интерфейс, простой и минималистичный, c возможностью использования графической оболочки. Из списка всех событий, которые может отслеживать процессор, пользователь должен выбрать нужные ему. В руководствах по архитектуре процессоров эти события описаны, но частенько для верного истолкования необходимо обладать обширными знаниями о самих процессорах. Дальше - больше: возникает проблема с интерпретацией собранных данных. Счетчики измерения производительности содержат абсолютные значения и могут возрастать произвольно. Отсюда вопрос: а насколько большим должно быть значение данного счетчика, чтобы оно действительно считалось большим?
Частичное решение проблемы: не обращать внимания на абсолютные значения, а вместо этого сравнивать значения счетчиков друг с другом. Процессоры могут отслеживать более чем одно событие; получив абсолютные значения, можно вычислить их отношения. Таким образом получаем сравнимые коэффициенты, с которыми можно работать. Часто в качестве делителя берется единица измерения длительности обработки, т.е. количество тактов либо количество команд. Для начала полезно сравнить хотя бы эти два параметра между собой.
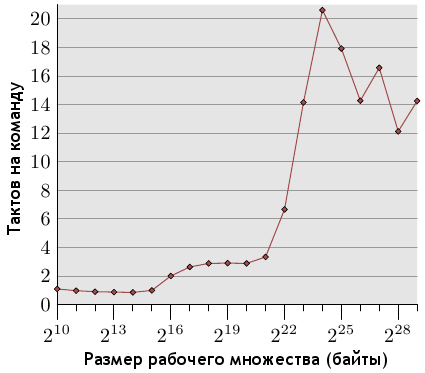
Рисунок 7.1: Количество тактов на команду (случайная выборка)
На рисунке 7.1 показано количество тактов на команду (Cycles Per Instruction, CPI) для простого теста в виде
выборки из памяти, выполняемой случайным образом для рабочих множеств разных размеров. В большинстве процессоров Intel события, получающие эту информацию, называются CPU_CLK_UNHALTED и INST_RETIRED. Имена говорят сами за себя: первое событие считает количество тактов, второе - количество команд. Наблюдается картина, схожая с проделанными ранее измерениями количества тактов на элемент списка. Для небольших рабочих множеств отношение равно 1 или даже меньше. Измерения проводились на мультискалярном процессоре Intel Core 2, который может работать одновременно с несколькими командами. Если программа не ограничена пропускной способностью памяти, отношение может быть значительно ниже единицы, но в нашем случае и единица - очень хороший результат.
Когда рабочее множество перестает помещаться в кэш L1d, коэффициент CPI возрастает до 3.0. Обратите внимание, что данный коэффициент усредняет расходы на доступ к кэшу L2 всех команд, а не только инструкций памяти. Используя данные отношения "тактов на элемент", можно вычислить, сколько команд тратится на доступ к элементу списка. Ну а когда и кэша L2 становится недостаточно, коэффициент CPI перешагивает планку в 20. Что вполне ожидаемо.
Но счетчики измерения производительности позволяют и глубже взглянуть на происходящее внутри ЦП. При этом следует помнить о различиях в реализации процессоров. Сейчас нас интересуют подробности работы с кэшем, так что соответствующие события и нужно рассматривать. Эти события, их имена и что именно они считают - всё зависит от конкретного процессора. Вот почему так сложно разобраться с использованием oprofile, несмотря на его простой интерфейс: пользователю приходится самостоятельно искать информацию о счетчиках производительности. В разделе 10 мы подробно рассмотрим несколько различных ЦП.
В случае использования Core 2 нам нужны события L1D_REPL, DTLB_MISSES и L2_LINES_IN. Последнее может измерять как все промахи разом, так и отдельно промахи, к которым привели инструкции, а не аппаратная предвыборка. На рисунке 7.2 показаны результаты выполнения теста случайной выборки.
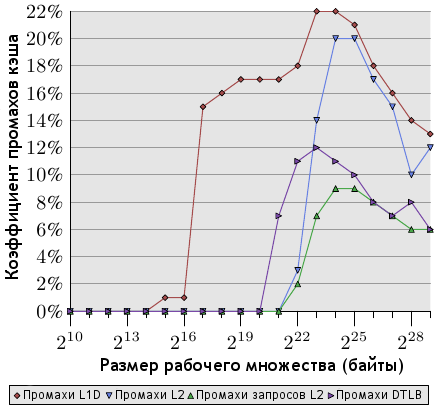
Рисунок 7.2: Промахи кэша (случайная выборка)
Коэффициенты вычислены с использованием количества всех выполненных команд (INST_RETIRED). Это значит, что считались также и те команды, которые не касаются памяти. А это, в свою очередь, значит, что число команд, связанных с памятью и вызвавших промах кэша, еще больше, чем показано на графике.
Число промахов L1d гораздо выше всех остальных потому, что в процессорах Intel используются инклюзивные (включающие, inclusive) кэши, то есть каждый промах L2 включает в себя также и промах L1d. Размер кэша L1d нашего ЦП составляет 32 Кб и мы видим, что, как и ожидалось, промахи L1d начинаются как раз когда рабочее множество достигает этого размера (промахи между отметками в 16 и 32 Кб вызваны использованием кэша, не связанным со структурой списка данных). Обратите внимание, что благодаря аппаратной предвыборке коэффициент промахов L1d держится на 1% при размерах рабочего множества до 64 Кб включительно, а затем прямо-таки взлетает.
Коэффициент промахов L2 держится на нуле до полного исчерпания объема кэша L2; пара промахов в связи с побочными использованиями кэша особо погоды не делают. Но как только размер L2 (221 байт) превышается, коэффициент промахов возрастает. Важно отметить, что коэффициент промахов запросов L2 (L2 demand miss rate) нулю не равен. Это говорит нам о том, что устройство аппаратной предвыборки загружает не все строки кэша, необходимые инструкциям в дальнейшем. И это ожидаемо: идеальная предвыборка невозможна ввиду случайности запросов доступа. Сравните с данными по последовательному чтению, показанными на рисунке 7.3.
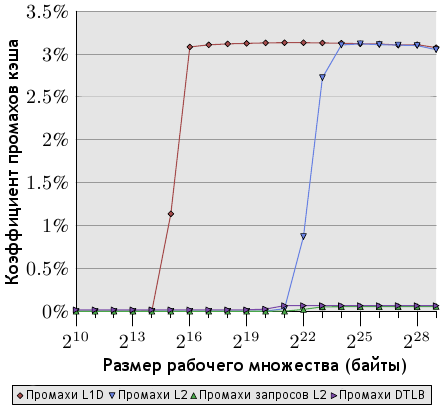
Рисунок 7.3. Промахи кэша (последовательная выборка)
Здесь мы видим, что промахи запросов L2 фактически отсутствуют (обратите внимание - масштаб рисунков 7.2 и 7.3 различен). То есть в случае последовательного доступа аппаратная предвыборка работает идеально и почти все промахи L2 вызваны самим устройством предвыборки. Коэффициенты промахов L1d и L2 одинаковы - это значит, что все промахи L1d обрабатываются в L2 без дальнейших задержек. Случай идеальный для любых программ, но, естественно, едва ли достижимый в реальных условиях.
Четвертый график на обоих рисунках - коэффициент промахов DTLB (Intel использует отдельные буферы TLB для кода и данных, и DTLB - это буфер данных). При случайном доступе его значение достаточно велико и заметно влияет на задержки. Любопытно, что эти промахи начинаются еще до появления промахов L2. В случае последовательного доступа промахи DTLB отсутствуют.
Вернувшись к примеру с перемножением матриц (в разделе 6.2.1) и примеру кода в разделе 9.1, сможем задействовать еще три счетчика. А именно, SSE_PRE_MISS, SSE_PRE_EXEC и LOAD_HIT_PRE могут быть использованы для оценки эффективности программной предвыборки. Запустив код из раздела 9.1, получим следующие результаты:
Описание Коэффициент Полезные предвыборки NTA 2.84% Поздние предвыборки NTA 2.65%
Низкое значение коэффициента полезной предвыборки NTA говорит о том, что многие команды предвыборки выполняются для уже загруженных строк кэша, когда никаких действий не требуется. То есть на декодирование таких команд и просмотр кэша процессор тратит время впустую. Тем не менее, слишком сильно придираться к коду не стоит. Многое зависит от объема кэшей в используемом процессоре, к тому же свою лепту вносит и само устройство аппаратной предвыборки.
Низкое значение коэффициента поздней предвыборки NTA на самом деле обманчиво. Этот коэффициент показывает, что 2,65% всех команд предвыборки выполняются слишком поздно. Инструкция, которой нужны данные, выполяется еще до того, как данные успевают оказаться в кэше. Нужно помнить, что всего лишь 2,84%+2,65%=5,5% всех команд предвыборки оказались полезными. А из всех полезных, 48% были выполнены с опозданием. Следовательно, код можно оптимизировать, учитывая следующие моменты:
- большинство команд предвыборки бесполезны.
- команды предвыборки следует использовать с учетом аппаратной основы.
В качестве упражнения пусть читатель попробует определить лучшее решение для доступного ему оборудования. Точная спецификация аппаратной части играет очень большую роль. На процессорах Core 2 задержка арифметических операций SSE составляет 1 такт. В прошлых версиях она составляла 2 такта, следовательно, устройство аппаратной предвыборки и команды предвыборки имели больше времени для загрузки данных.
Чтобы определить, нужно в данном случае использовать предвыборку или нет, используется программа opannotate. Она показывает исходники или ассемблерный код программы и выделяет команды с опознанным событием. Обратите внимание, что возможны два источника неопределенности:
- Oprofile выполняет вероятностное профилирование. Это значит, что записывается только каждое N-ое событие (порог N свой для каждого события, при этом имеется некое минимальное значение), дабы не слишком замедлять работу системы. Может случиться так, что какие-то строки кода вызывают сотню событий и тем не менее их не будет в отчете.
- Не все события записываются верно. К примеру, значение счетчика инструкций на момент записи определенного события может оказаться неправильным. Дать стопроцентно верное значение мешает мультискалярность процессоров. Хотя на некоторых процессорах есть и точные события.
Аннотированные листинги могут быть полезны не только для определения информации касательно предвыборки. Каждое событие записывается с указателем команды, а значит, можно найти и другие "горячие точки" программы. Области кода с большим количеством событий INST_RETIRED выполняются часто и потому заслуживают пристального внимания. Области, где происходит много промахов кэша, требуют использования инструкций предвыборки для избежания последних.
Есть тип событий, который можно отслеживать без аппаратной поддержки. Это ошибки отсутствия страниц, или страничные ошибки (page faults). За исправление этих ошибок отвечает операционная система, и в случае появления таковых, она же их и подсчитывает. Системой выделяются два вида страничных ошибок:
Легкие страничные ошибки (Minor Page Faults)
К ним относятся ошибки отсутствия анонимных (например, не связанных с файлами) страниц, которые пока еще не были использованы, ошибки копирования при записи (copy-on-write), а также ошибки страниц, содержимое которых уже находится где-то в памяти.
Значительные страничные ошибки (Major Page Faults)
Для разрешения этих ошибок необходим доступ к диску для получения связанных с файлами (или находящихся в файле подкачки) данных.
Очевидно, что значительные страничные ошибки обходятся системе значительно дороже легких. Но и последние тоже нельзя сбрасывать со счетов. В обоих случаях необходимо обратиться к ядру, найти новую страницу, очистить ее либо заполнить соответствующими данными, после чего отразить изменения в дереве таблиц страниц. Последний шаг потребует синхронизации с другими задачами чтения или изменения дерева таблиц страниц, что приведет к еще большим задержкам.
Легче всего получить информацию о количестве страничных ошибок - использовать инструмент time. Только заметьте: оригинальный инструмент, а не тот, что встроен в оболочку. Результаты вывода можно лицезреть на рисунке 7.4. {Обратная косая (бэкслэш) в начале предотвращает вызов встроенных команд.}
$ \time ls /etc [...] 0.00user 0.00system 0:00.02elapsed 17%CPU (0avgtext+0avgdata 0maxresident)k 0inputs+0outputs (1major+335minor)pagefaults 0swapsРисунок 7.4. Вывод утилиты time
Нас интересует последняя строка. Утилита докладывает о том, что произошла одна значительная и 335 легких страничных ошибок. Точные цифры постоянно меняются; в частности, если сразу же запустить программу повторно, скорее всего не будет обнаружено ни одной значительной страничной ошибки. Если программа выполняет одно и то же действие и окружающие условия не меняются, то общее количество страничных ошибок будет постоянной величиной.
Особенной фазой по отношению к страничным ошибкам является запуск программы. Каждая используемая страница вызовет страничную ошибку; внешне это проявляется (особенно в приложениях с графическим интерфейсом) в том, что чем больше страниц памяти используется, тем дольше программа запускается. В разделе 7.5 познакомимся с утилитой, позволяющей оценивать именно этот момент.
Заглянув внутрь time, можно обнаружить, что используется функциональность rusage. Системный вызов wait4 заполняет объект struct rusage, пока родитель ожидает завершения дочернего процесса; это именно то что нужно для инструмента, подобного time. Но процесс также может запросить информацию об использовании ресурсов (отсюда и пошло название rusage - Resource Usage, использование ресурсов) как своих, так и ресурсов завершенных дочерних процессов.
#include <sys/resource.h> int getrusage(__rusage_who_t who, struct rusage *usage)
Параметр who определяет процесс, о котором запрашивается информация. На данный момент, определены значения RUSAGE_SELF (о себе) и RUSAGE_CHILDREN (о дочерних процессах). Коэффициент использования ресурсов дочерними процессами определяется в момент завершения каждого из них. Эта величина - общая для всех дочерних процессов, а не для каждого из них по отдельности. В ближайшем будущем планируется реализовать возможность запроса информации об отдельных потоках, в связи с чем появится и третье значение - RUSAGE_THREAD. Структура rusage определена таким образом, что может содержать все типы показателей, включая время выполнения, количество посланных сообщений IPC, используемую память и число страничных ошибок. Последнее можно найти в членах ru_minflt и ru_majflt данной структуры.
Программист, желающий определить, снижается ли производительность его программы из-за страничных ошибок и где именно это происходит, может регулярно проверять данные члены и затем сравнивать полученные значения с предыдущими.
Такую информацию видно и "снаружи", если запрашивающий имеет необходимые привилегии. Псевдофайл /proc/<PID>/stat, где <PID> - идентификатор интересующего нас процесса, содержит информацию (в виде пар чисел) о страничных ошибках в полях с десятого по четырнадцатое. Эти пары представляют собой общее количество легих и значительных страничных ошибок процесса и его дочерних процессов соответственно.
| Назад | Оглавление | Вперед |