Библиотека сайта rus-linux.net
Инструменты локального поиска в GNU/Linux: Tracker, Recoll, Strigi и Deskbar
Оригинал: Desktop search tools for GNU/Linux: the competition hots up – Tracker, Recoll, Strigi and Deskbar
Автор: Gary Richmond
Дата: 26 июня 2007
Перевод А.Тарасова, дата перевода: 16 июля 2007
В первой и второй частях своего блога я рассматривал Beagle и его альтернативные интерфейсы (Peagle, Yabi и Catfish). В этой, последней части, я рассмотрю еще несколько поисковых инструментов, которые можно рассматривать как альтернативу Beagle: Tracker, Recoll, Strigi и Deskbar – апплет, написанный на языке Python, функциональность которого также может быть расширена с помощью скриптов.
Tracker: по следам Beagle
В первой части был детально рассмотрен Beagle. Его можно критиковать за две вещи: во-первых, он потребляет много памяти, во-вторых, он основан на Mono/Net, и поэтому относится к империи MS/Novell. С другой стороны, у Tracker нет таких недостатков.
Строго говоря, правильное название инструмента – Metatracker, но он больше известен как Tracker, поэтому я буду называть его именно так.
Официальный сайт нисколько не преувеличивает функциональность Tracker. Там утверждается, что Tracker индексирует файлы с удивительной до смеха скоростью. Tracker ищет файлы не только по имени и пути, но также по его содержанию и метаданным. Tracker написан на C, стабилен и нуждается в не таком уж большом количестве зависимостей: sqlite, libdbus, dbus-glib bindings, glib, Zlib и GMime. Как и Beagle, Tracker может использовать inotify, который по умолчанию отключен, но вы, как я уже писал
в первой части, можете включить его в /etc/fstab. В то время как Beagle использует Lucene в качестве поискового backend'а, Tracker основан на
Sqlite3, который поддерживает базы данных до 2 тебибайт. Это должно удовлетворить любого пользователя, в том числе и системных администраторов! Утверждается, что Tracker чрезвычайно нетребователен к памяти: обычное потребление ОЗУ составляет от 3 до 9 мегабайт, что может быть спасением для обладателей слабых машин с малым количеством памяти.
Итак, что же индексирует Tracker? В данный момент имеется поддержка следующих форматов: видео, картинки, музыка, документы, тексты и исходные тексты. Также планируется поддержка других форматов, включая электронную почту, контакты, приложения, интернет-закладки, историю и многое другое. На главной странице проекта есть хорошая таблица с поддерживаемыми форматами, а также с теми, поддержка которых скоро будет. Инструмент не настолько расширяем, как Beagle (пока), однако имеет свои преимущества. Как и многие другие программы GNU/Linux, в зависимости от ваших предпочтений и вашей машины, вы можете запускать Tracker как из командной строки, так и с помощью GUI. Tracker можно отнести к проектам GNOME, но он также пойдет на KDE. Вы всегда можете загрузить маленькое GNOME-приложение и минимизировать его в панель задач. Это верно и для приложений KDE в GNOME-окружении.
Где можно достать Tracker?
Какая бы версия GNU/Linux у вас ни была, проверьте сперва репозитории. Почти везде можно найти бинарныеdeb- или rpm-пакеты. Если менеджер пакетов обнаружит, что в вашей системе не хватает зависимостей, установите также их. Я устанавливал Tracker из репозитория Fedora Core 6 и сразу же получилось его запустить. Однако на моей машине с Mepis, synaptic потерпел неудачу. Я давно не обновлял менеджер пакетов, это будет мне уроком!
Если у вас также ничего не получилось, а установку из исходников вы не любите, тогда обратитесь к самим разработчикам Tracker, они позаботились о вас. В разделе «Getting Started» вы увидите множество бинарных пакетов для различных дистрибутивов: Debian в Sid, Ubuntu Fiesty и Dapper, Gentoo-пакеты в Portage, Fedora Core 5 и 6 (в Extras), недавно выпущенная Fedora Core 7 также содержит пакет Tracker. Пользователи Mandriva (включая меня) не обделены вниманием, пакет Tracker включен в contrib-раздел дистрибутива Cooker (дистрибутив для разработчиков).
Tracker – графический интерфейс и командная строка
Наконец-то мы можем начать. Для запуска Tracker в командной строке, чтобы он сразу начал индексировать, просто введите под обычным пользователемtrackerd, запустится демон. Однако, если вы предпочитаете графический интерфейс, запуск демона произойдет автоматически. Если установка прошла нормально, вы можете запустить графический интерфейс Tracker из главного меню либо с помощью значка на рабочем столе, а для любителей запускать все из командной строки – tracker-search-tool.
Если вы запустите графический интерфейс Tracker, вы наверняка заметите одно упущение – это недостаток дополнительных настроек. Поэтому ради них вам придется заглянуть в консоль. К примеру, вам нужно сделать индексируемым какой-нибудь каталог, помимо home (который индексируется по умолчанию). Откройте файл ~/.Tracker/tracker.cfg в своем любимом редакторе, найдите поле WatchDirectoryRoots и введите через точку с запятой список каталогов, которые вы хотите сделать индексируемыми. После запуска Tracker вы можете следить за его отчетом, для этого откройте консоль и введите
# tail -f ~/.Tracker/tracker.logСуществует также множество других функций командной строки, но я не думаю, что они будут полезны пользователю средней руки. Хотя, если вам все-таки удобнее работать из консоли, вы можете получить детальную документацию на официальном сайте.
Также, как и Beagle работает со множеством приложений, Tracker интегрируется со следующими программами: Catfish, Affinity, Deskbar (так как Deskbar написан на языке Python, вы можете загрузить Python-скрипты для него, включая скрипт для Tracker, см. раздел «Python-расширения»), Daze (как Tomboy, но менее мощный), Kio-find и Nautilus. Связка с Nautilus довольно интересна: интеграция происходит не сразу «из коробки», а нужно указать поддержку Tracker на этапе конфигурирования при компиляции Nautilus из исходников. Но если вы установите Tracker, вам придется удалить поддержку Beagle из Nautilus. Если вы решитесь так сделать, перезапустите Nautilus с помощью Alt + F2 и введите nautilus -q. Готово. Можно начать пользоватья связкой Nautilus+Tracker. Для этого откройте Nautilus и нажмите кнопку «Искать файлы», введите искомое слово и увидите результат.
Главное окно Tracker не пресыщено элементами управления (главным образом из-за ограниченных возможностей графического интерфейса). Вы можете начать экспериментировать с различными запросами. Как видно из рисунков внизу, Tracker показывает впечатляющие результаты на простые запросы. Во всех этих примерах Tracker работал быстро (быстрее, чем Beagle) и стабильно, а в связке с Catfish были доступны дополнительные функции.
Несомненно, у кого-то может не получиться установить Tracker из-за внутренних ошибок или проблем совместимости. Понимаю. В любой статье разумно приводить некоторые предостережения: если что-то работает у меня, не факт, что оно будет работать у вас. В последнем разделе – «Бортовой журнал» – будет рассказана душераздирающая и поучительная история, которая пригодится большинству читателей. Я использую Tracker на Fedora Core 6, Ubuntu Dapper и Mandriva 2006 на ноутбуках 2-3-летней давности с 1.3-1.6 ГГц процессором и 384-769 Мб памяти, при этом скорость поиска довольно хороша. Было бы интересно узнать, экспериментировал ли кто-либо с более слабыми машинами и каковы результаты, т.е. является ли скорость удовлетворительной.
Снимки экрана Tracker
Tracker ищет HTML-файлы
Tracker нашел 4 типа файлов на запрос «Qemu»
Результаты поиска pdf с помощью интерфейса Catfish
Recoll*: название говорит само за себя
* recollect – вспоминать.
В зависимости от вашей версии GNU/Linux, вам может повезти и вы обнаружите Recoll в репозиториях. Но если ваш поиск ничего не дал, нет повода отчаиваться. Славные разработчики Recoll
предоставили
вам множество скомпилированных бинарных файлов для Fedora Core (5 и 6), Mandriva 2006, SUSE 10.1, Ubuntu (Dapper, Edgy, Fiesty), Debian unstable и 3.1, порты для FreeBSD и некоторые пакеты для FreeBSD 5.5 и Solaris 8 (sparc). Нет длинного списка зависимостей, единственное требование – Qt 3.3 или Qt 3.4. Если вы устанавливаете Recoll из исходников, нужно будет указать при конфигурировании configure -enable-qt4, чтобы сделать сборку с поддержкой Qt 4. Если все равно не работает (либо вы ненавидите работу с исходниками), ваша последняя надежда – запустить инструмент Alien, скачать Debian или RPM пакет и попробовать конвертировать пакет для вашей системы. Как обычно, результат может быть любой. Желаю удачи. Люди, не любящие Micronovell/Mono, будут рады, так как Recoll построен не на Mono, а на поисковом движке
Xapian, имеющем лицензию GPL.
Как мы все ожидали, Recoll имеет хорошую поддержку обычного перечня типов файлов: HTML, OpenOffice.org, электронная почта (Thunderbird и Evolution). Индексирование PDF, Word, Excel требует установки «внешних дополнений», и сайт Recoll поможет вам в этом. Эти дополнения могут быть установлены с помощью менеджера пакетов. Recoll также предоставляет поддержку некоторых продвинутых функций: множественные базы данных, поиск однокоренных слов (выделение корней происходит не во время запроса, а на стадии индексирования), индексирование в реальном времени, индексирование по расписанию Cron.
Recoll – загружаем и запускаем
После установки Recoll вы наверняка сразу захотите попробовать его в действии. При первом запуске Recoll спросит у вас, оставить ли настройки по умолчанию. Среднего пользователя они устраивают. Если же они не устраивают вас, поспешу вас огорчить, графической утилиты настройки нет. Для этого придется вручную редактировать конфигурационный файл. Хотя в руководстве пользователя обещают, что графический интерфейс настройки появится в ближайшем будущем. Можете заглянуть в раздел 4.4 руководства пользователя, чтобы узнать, как добавлять, изменять или удалять каталоги из списка индексирования. По умолчанию индексируется папка home, и для большинства пользователей это неплохо работает. Если вы работаете на сервере, вам следует подумать, нужно ли индексировать файлы, содержащие конфиденциальные данные. Приятная новость: программа Recoll продумана в плане безопасности. Она автоматически устанавливает разрешения на 0600, чтобы лишь сам пользователь имел доступ к своему индексу.Тонкая настройка Recoll
Принятие настроек по умолчанию создаст индекс домашнего каталога. Если индекс по какой-либо причине не был создан, запустите терминал и наберитеrecollindex. Если создание индекса будет занимать много времени, либо будет потреблять много системных ресурсов, вы можете прервать процесс создания индекса, нажав Ctrl + Z. Этого делать не рекомендуется, однако бывают случаи, когда все-таки нужно прерваться. Recoll может продолжить свое дело после того, как вы удалите базу данных ~/.recoll/xapiandb, чтобы индекс был корректным. Еще лучше, запустите Recoll с ключом -z. Это сбросит базу данных перед индексированием и предотвратит бесконечное редактирование конфигурационных файлов. Еще один путь преодолеть эту трудность – запуск процесса индексирования как задачу Cron, для этого вам нужно указать время, в течение которого ваша система будет не нагружена. Если по какой-либо причине задача по расписанию будет пропущена, она будет скомпенсирована с помощью
Anacron, когда машина будет включена. Еще одна опция командной строки – запуск индексирования в режиме реального времени. Это выполняется с помощью команды recollindex -m, при этом в фоновом режиме запускается демон, который будет отслеживать любые изменения в файловой структуре и индексе. Более подробную информацию ищите в разделе 2.5 руководства пользователя.
Есть альтернатива этим стратегиям. Она призвана уменьшить нагрузку при индексировании, и называется множественные базы данных (multiple databases). Эта функция позволяет вам указывать несколько конфигурационных каталогов, которые будут использоваться для индексирования различных частей файловой системы. После их установки вы можете запустить процесс индексирования с помощью recoll или recollindex с ключом -c. Настройка множественных баз данных производится вручную путем редактирования соответствующих конфигурационных файлов, либо с помощью графического интерфейса, для этого выберите вкладку «External indexes», находящуюся в настройках «Preferences». Раздел 3.8 руководства пользователя предоставит вам более подробную информацию об этой функции.
Функции поиска Recoll
После того, как вы настроили Recoll на свой вкус, вы наверняка захотите что-нибудь найти. Recoll предоставляет большие возможности по поиску. Вы можете создавать простые запросы, запросы по имени файла, запросы с маской, булевские запросы для построения более сложных запросов, сложные запросы, сужающие область поиска до типов файлов и даже каталогов. Что бы вы ни искали, Recoll представит результат в приятной форме, в обычном окне с двумя главными функциями – «Preview» («Просмотр») и «Edit» («Правка»). Первый пункт позволяет просмотреть неформатированный текст, извлеченный из файла (к примеру из pdf-документа), а второй в зависимости от контекста файла откроет его в какой-либо внешней программе (эти контекстные зависимости могут быть настроены в диалоговом окне «User Preferences» либо путем редактирования файлаmimeview). В некоторых случаях Recoll бывает чересчур мощным, чем надо. Пожалуй, для продвинутого пользователя это не проблема. Хороший способ лучше познакомиться со всеми поисковыми опциями – это экспериментировать с поиском, с руководством пользователя под рукой.
Прежде чем мы оставим Recoll, нужно рассмотреть еще одну замечательную функцию этой программы: Term Explorer. Она позволяет искать по тем ключевым словам, которые неточно известны либо пользователь не знает точного их написания. Функция поддерживает множество операций: поиск однокоренных слов (stem expansion), поиск слов по маске и по регулярному выражению, поиск по произношению. Этого должно хватить, если вы хоть что-то помните об искомом предмете. Для запуска функции нажмите Term Explorer или выберите пункт Term Explorer в меню Tools.
Снимки Recoll за работой
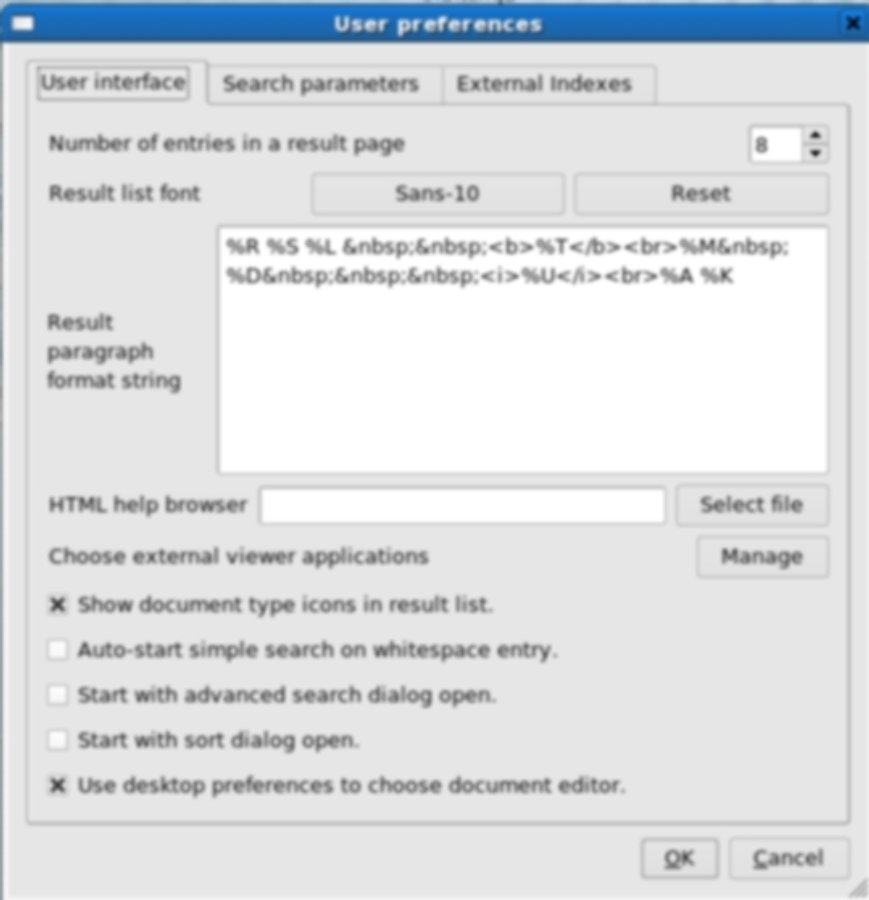
Пользовательские настройки Recoll
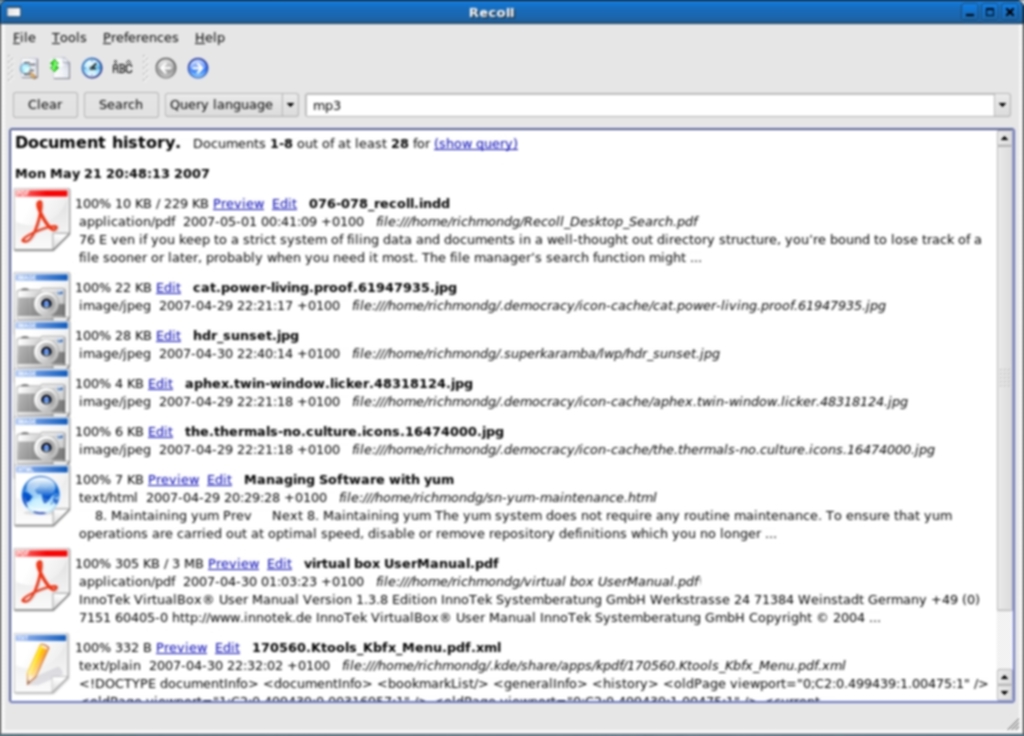
История документов Recoll
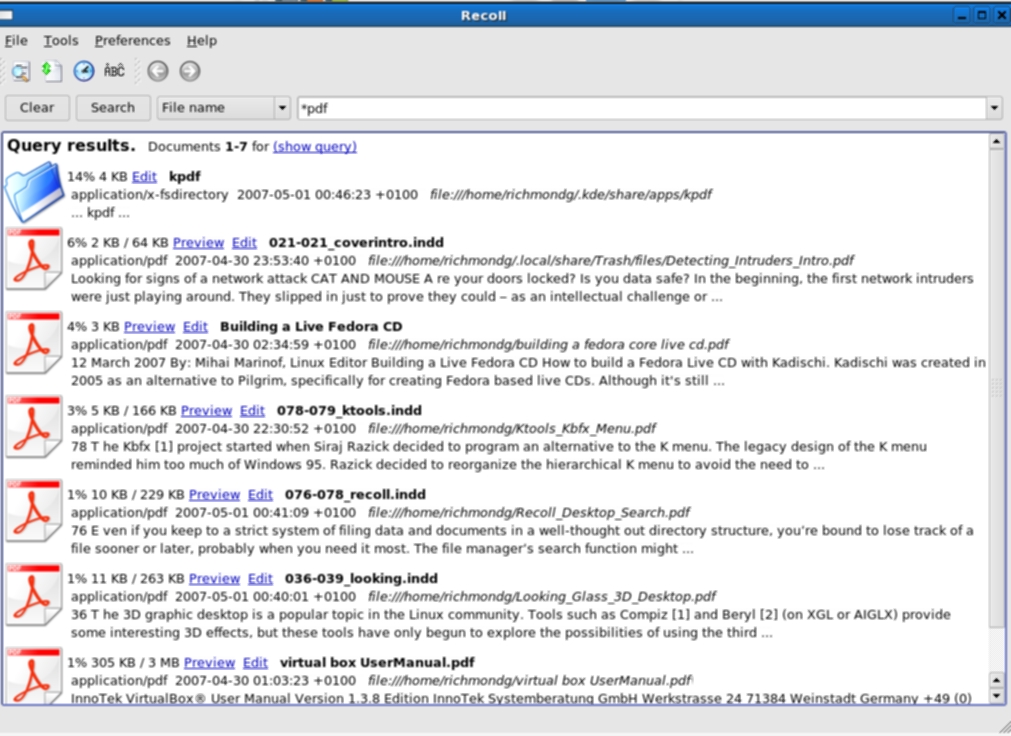
Маски Recoll для поиска pdf
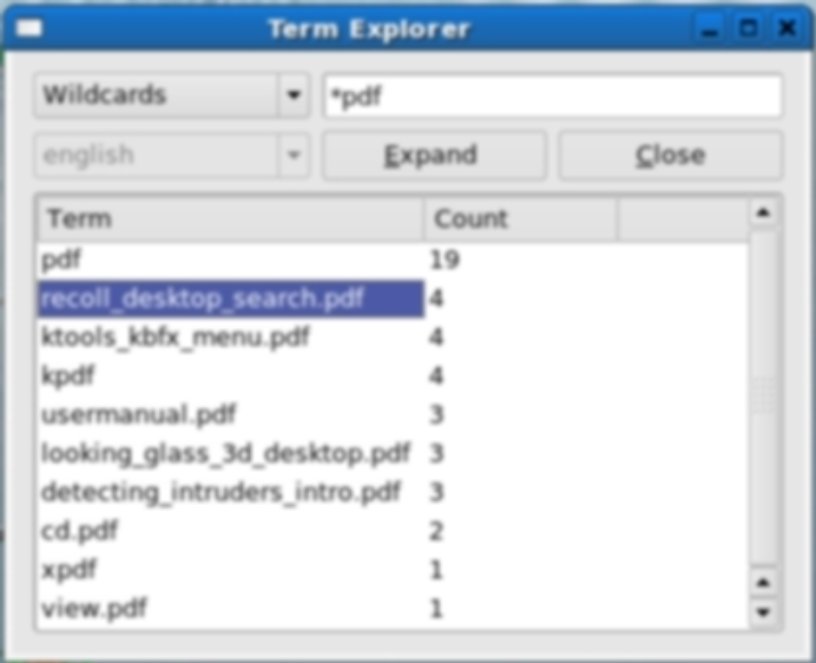
Term Explorer в действии
Strigi: строго для сов?
Я собирался добавить лишь небольшое упоминание о Strigi как о альтернативе Tenor в KDE4, но как только я положил ручку на стол, я обнаружил программу в репозитории Fedora Core 6. После простой установки инструмент был запущен.Вы наверняка поняли идею в названиях предыдущих поисковых движков – Beagle (англ. «гончая»), Tracker (англ. «следящий») и Recoll (англ. recall – «вспомнить»). Но что же значит Strigi? Короткое посещение Википедии развеяло тайну. «Strigi» – сокращение от «strigiformes», которое переводится как «совообразные» – это отряд хищных птиц. Вот почему на найденных PDF-файлах была изображена сова! Я плохо учился в младших классах, но помню, что сова была символом Афин, и даже была изображена на афинских монетах. Сова ассоциировалась с мудростью, что не совсем подходит для поискового движка. Хотя, как писал А.С. Пушкин, «что в имени тебе моем?»
На домашней странице Strigi утверждается, что это самая быстрая и в то же время самая легкая поисковая программа, что это поисковой движок, который индексирует диски без «истязания системы», и что она поддерживает многие типы файлов: пакеты Debian и RPM, PDF-документы, MP3, тексты, архивы и таблицы OASIS, презентации, и в то же время потребляет мало памяти.
Есть выбор между двумя backend'ами – это clucene (который был описан ранее) и
hyperestraier, имеющий лицензию LGPL. Есть надежда, что появится поддержка Sqlite3 и Xapian. Одна из интересных возможностей Strigi – инструменты, заменяющие find и grep – соответственно, deepfind и deepgrep. Они позволяют искать внутри файлов так же, как ищет файлы Strigi-демон.
Интеграция Strigi
Konqueror – это самоцветы в короне KDE, он напичкан функциями (есть такой термин, как «feature bloat» – «разрастание функций»). Одна из лучших –kio-slaves, которые добавляют функциональности адресной строке Konqueror. К примеру, в адресной строке может поселиться поисковой движок. Когда у вас запущен клиент и демон, попробуйте ввести strigi:/ в адресной строке браузера. Как альтернативный вариант, вы можете интегрировать Strigi в
KBFX. KBFX – это альтернатива классического KDE-меню. Я установил его на Mepis и Fedora Core 6 (вместе со Strigi). Последняя бинарная версия KBFX (KBFX Silk 0.4.9.3.1) имеет встроенную поддержку Strigi. Если у вас более старая версия, вы можете собрать KBFX из исходников, при конфигурировании включив функциональность Strigi, добавив --strigi или -s к build.sh (./build.sh --strigi). Кстати, если хотите увидеть Strigi/KBFX в действии, можете посмотреть
эту flash-демонстрацию. Strigi также имеет поддержку панели задач GNOME, я рассмотрю ее в следующем разделе – Deskbar.
Jstreams?
Отличительной особенностью Strigi является то, что она не индексирует файлы (как это делают другие программы). Вместо этого используются Jstreams. Что же это? Лучшее определение, которое я нашел – «перенос на C++ потомков Java InputStream». Не совсем понятно, но так было написано. Google Summer of Code так пишет об этом: «Strigi совмещает анализ потокового содержимого с абстрактным индексным интерфейсом». Утверждается, что основное достоинство Jstream – возможность считывания глубоко вложенных файлов при небольшом использовании процессора и памяти. Если вас интересуют все мельчайшие подробности, вам, наверное, нужно сходить сюда и сюда. Утверждается, что Jstreams гибок (в смысле поддержки новых типов файлов), быстр и легок в использовании. Также Jstreams хорошо интегрируется в KDE3 (и будет в KDE4) и использует Jstreams KIOslave.Снимки экрана Strigi
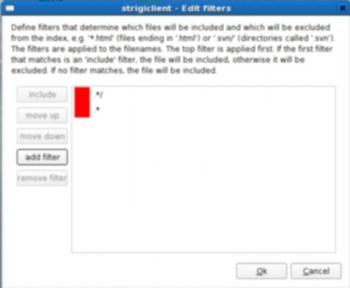
Strigi в режиме редактирования фильтра
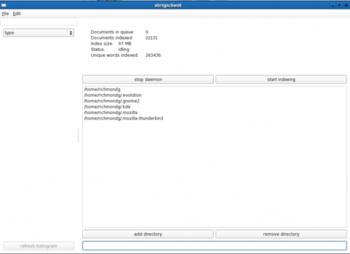
Окно настроек Strigi
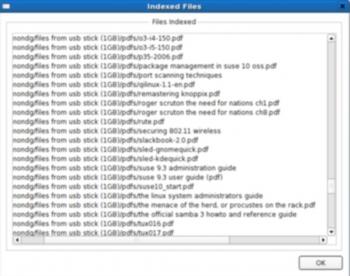
Что было проиндексировано Strigi
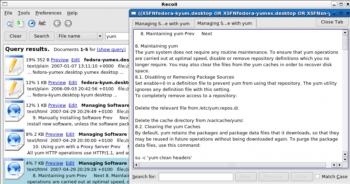
Результаты поиска представлены во вкладках
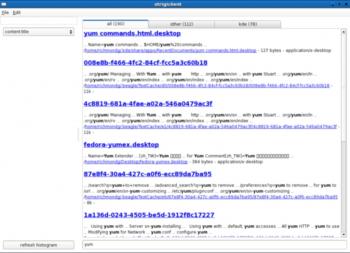
Результат поиска yum, пропущеный через фильтр
Ваш выбор: Beagle, Tracker, Recoll или Strigi?
Выбор средства для локального поиска зависит от множества факторов: мощность компьютера, доступность бинарных файлов для вашего дистрибутива, каковы ваши предпочтения по результату поиска, какие типы файлов вы хотите индексировать и какие внешние программы использовать, чтобы работать с найденными файлами. У каждого свои требования, которые порой бывают настолько субъективными, что их нельзя описать словами.Если вы хотите сделать выбор как можно объективней, самый простой способ – запустите поиск в интернете по упомянутым поисковым движкам, в сети есть множество других обзоров таких программ, вот один из них. В этом документе сравниваются поисковые движки по многим параметрам. Советую почитать.
Мое личное предпочтение – движок Tracker, но я даже не могу объяснить, почему. Просто мне он больше нравится. Программа стабильна, выглядит неплохо и интегрируется во множество приложений. Beagle порой бывает глючный, потребляет много ресурсов и несет клеймо платформы Mono. Recoll лучше в некоторых случаях, чем Beagle, меньше потребляет памяти и выдает хороший результат. Что же касается Strigi, то это новичок на сцене поисковых движков, а его огромная мощность требует соответствующей конфигурации компьютера.
Конечно, вы не должны себя ограничивать этими графическими инструментами поиска. Любой GNU/Linux содержит инструменты командной строки, которые решают поисковые задачи: locate, find и grep. Если у вас появляется чувство отвращения, когда вы слышите про командную строку, но вы хотите улучшить свои поисковые навыки, советую попробовать
SearchMonkey. Эта программа не только предоставит вам возможность просто обращаться с упомянутыми инструментами командной строки, но также даст вам шанс разобраться в регулярных выражениях с помощью мастеров регулярных выражений.
Deskbar: от поиска в компьютере к поиску из компьютера
Многие пользователи знакомы с апплетом Deskbar в GNOME. Я должен признать, что не находил ему применения. Но когда я писал эту статью, я внезапно понял, что можно извлечь из него пользу в комбинации с уже существующими и появляющимися поисковыми движками.
В отличие от описанных выше поисковых программ, Deskbar не только ищет файлы, приложения и папки на вашей машине, но также ищет в интернете. Что действительно интересно, так это то, как Deskbar может быть интегрирован с Beagle, Doodle, Tracker и Strigi. Deskbar написан на языке Python, и для него написано множество скриптов, о них мы сейчас и поговорим.
Наверняка Deskbar уже установлен в вашем GNOME-окружении. Если нет, идите в свой репозиторий (есть пакеты для Ubuntu, Debian, Fedora Core, Mandriva, Gentoo e-build и Arch), если не найдете, ищите здесь. Любители исходников могут скачать их здесь. Последняя версия Deskbar (2.19) поддерживает drag-and-drop, поэтому для установки python-скрипта достаточно перетащить его на Deskbar. Я попробовал на Fedora Core 6, результаты были разнообразными. Некоторые скрипты установились без всяких сообщений, как можно видеть на рисунках внизу, но некоторые не захотели сразу устанавливаться. Причина была в том, что политика безопасности SeLinux опознавала скрипты как угрозу безопасности. Для установки расширения мне пришлось выключить SeLinux. Иногда нужно так делать, чтобы установить какие-нибудь полезные программы, несмотря на сообщения о риске.
Обычно апплет Deskbar видим на панели GNOME. Если же нет, нажмите правой кнопкой мыши на панели и выберите «добавить на панель» («add to panel»). Откроется диалоговое окно, выберите там Deskbar. Когда вы добавляете или удаляете скрипты, возможно, вам понадобится перезапускать Deskbar. Кстати, если вы хотите попробовать Deskbar без собственно его установки, откройте терминал и наберите
# /usr/lib/deskbar-applet/deskbar-applet -wи вы увидите, как он работает.
Python-расширения
Deskbar динамичен: по мере того, как вы вводите слово, он сразу подбирает подходящее (включая историю). Вы можете даже ввести команду и увидеть вывод с помощью клавиатурной комбинацииAlt + T, это вынесет вывод в отдельное окно. Настройки позволяют выбирать, какой использовать поисковой движок, для каждого движка есть свой Python-скрипт. В этом и состоит главное достоинство Deskbar – его расширяемость. Установка Python-расширений проста: загружаете нужное расширение и копируете его в ~/.gnome2/deskbar-applet/handlers/. Существуют расширения, обеспечивающие такие функции как GMail, Tracker, Doodle, просмотр Man-страниц (через Yelp), поиск в Creative Commons, быстрая Apt-установка (безопасность учтена), HostLookup, история Firefox,
плагин для Flickr,
поисковый движок del.icio.us,
плагин для ssh и многие другие. Планируется поддержка адресной книги Thunderbird и контактов Gaim.
Deskbar и New Stuff Manager
Хотя установка Python-скриптов для Deskbar проста, вы наверняка подумали о том, что было бы неплохо иметь программу, которая автоматически бы искала, загружала и устанавливала скрипты. Такая программа есть – это New Stuff Manager, исходные тексты и пакеты для Debian расположены на официальной странице. Я попытался попробовать New Stuff Manager на своей Fedora Core 6, но, так как пакет был лишь для Debian, я решил установить Alien и преобразовать пакет в RPM, что закончилось неудачно. Установка из исходников также не дала результата, я потонул в море зависимостей. Поэтому вместо размещения снимков своего экрана я направляю вас на блог, на котором эти снимки есть. Вы увидите красивый интерфейс для управления расширениями и обновлениями. Я решил, что после обновления своей системы до Fiesty Fawn я обязательно установлю New Stuff Manager. Он слишком хорош, чтобы проходить мимо.Снимки экрана Deskbar
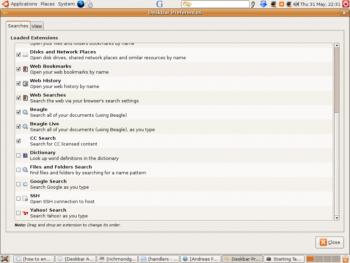
Настройка Deskbar
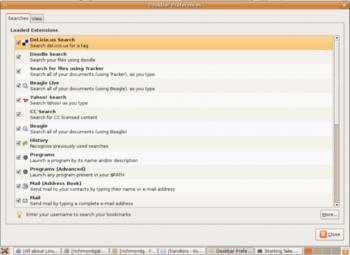
Deskbar с добавленными скриптами tracker и doodle
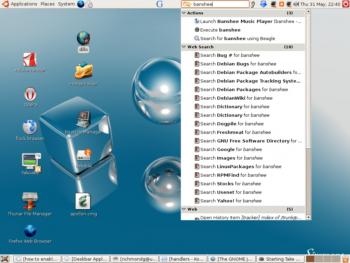
Deskbar выдал результаты на запрос «banshee»
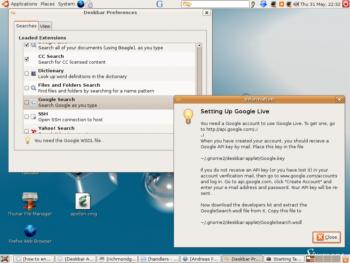
Настройка Google Live для Deskbar
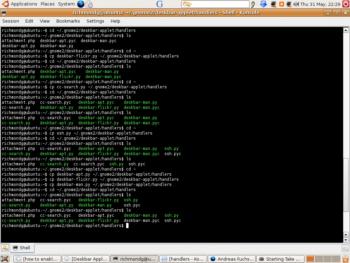
Сложный способ копирования python-скриптов
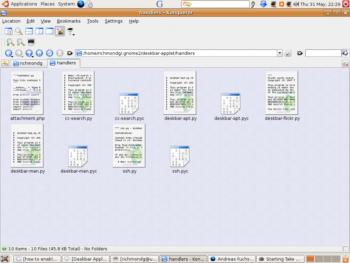
Python-скрипты расширений Deskbar
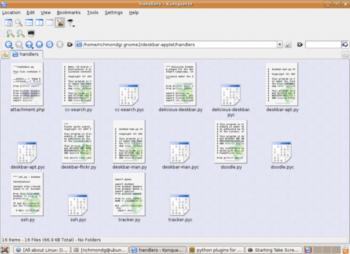
Python-скрипты расширений Deskbar, просмотр в Konqueror
Возможно, я отошел от главной цели статьи – рассмотреть лидеров среди программ локального поиска – и включил в рассмотрение Deskbar, который добавляет множество замечательных функций к любому компьютеру с работающей ОС GNU/Linux, однако для поиска лучшего идет в интернет. Все равно, я думаю, это стоящее дополнение.
Бортовой журнал
Этот краткий обзор средств для локального поиска показал достоинства и недостатки каждого. Я всегда был склонен к программам с «раздутой функциональностью», и порой это шло вразрез с моими желаниями безопасности и стабильности. Для меня «раздутая функциональность» – цветной бисер, рассыпанный на берегу, а пока ничего не подозревающие индейцы увлеченно его рассматривают, Капитан Кук поднимает флаг на острове. Я имею в виду установку New Stuff Manager. Мне казалось, что я с гордостью иду по улице GNU/Linux, однако на самом деле я скромно жую булочку.В общем, у меня не получилось установить New Stuff Manager, я обновил Mono в надежде, что это решит проблему с зависимостями, а также выключил демон Beagle, но все равно ничего не получалось. В такие моменты приходится сопротивляться соблазну взять GNU/Linux, выйти с ним на улицу и дать хорошего пинка, но вас встречает двуликий Янус и вам приходится остыть, а если у вас есть свободная неделя, весьма вероятно, что вас захватит эта задача, ведь после того, как вы установили беспроводную сетевую карту из командной строки с помощью Ndiswrapper вы хотите испытать опять то же хвастливое чувство – к тому же всегда в процессе решения неясное становится ясным. Поэтому я никогда не вернусь к Windows. Я не ищу острых ощущений – скорее, я поиграю в классики на минном поле в магнитных ботинках.