





Библиотека сайта rus-linux.net
Руководство по созданию простой UNIX-подобной ОС
7. Память типа куча
Оригинал: "7. The Heap"Автор: James Molloy
Дата публикации: 2008
Перевод: Н.Ромоданов
Дата перевода: январь 2012 г.
Для того, чтобы должным образом реагировать на те ситуации, которые вы не предусмотрели на этапе проектирования, и чтобы сократить размер вашего ядра, вам нужен некоторый механизм динамического выделения памяти. Существующая система выделения памяти (выделение с указанием адреса размещения данных) замечательная и, на самом деле, оптимальна как по времени, так и по распределяемому пространству. Проблема возникает, когда вы пытаетесь освободить часть памяти и затем хотите ее повторно использовать (это должно, в конце концов, потребоваться, в противном случае вам может не хватить памяти!). В механизме выделения нет никакого способа сделать это и, следовательно, он нежизнеспособен в большинстве ситуаций, связанных с выделением в ядре памяти.
В качестве дополнительного средства любая структура данных, для которой осуществляется выделение и освобождение памяти, может обращаться к памяти типа куча (или пул памяти). Стандарт на 'алгоритм работы с кучей', как таковой, не существует. В зависимости от требований, связанных с затрачиваемым временем, используемой памятью и эффективностью, используются различные алгоритмы. Наши требования следующие:
- (относительная) простота реализации
- возможность проверять правильность работы - отладка перезаписи памяти в ядре примерно в десять раз труднее, чем в обычных приложениях!
Алгоритм и структуры данных, представленные здесь, разработаны мною самостоятельно. Однако, они настолько просты, что я уверен, что они будут использоваться другими в первую очередь. Все это похоже на команду malloc (хотя и проще ее) Дага Ли (Doug Lea), которая используется в библиотеке GNU C.
7.1. Определение структуры данных
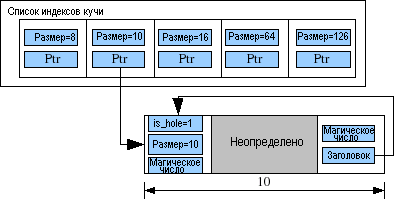
7.2. Описание алгоритма
7.2.1. Выделение памяти
Выделение памяти довольно простое, если не сказать, что даже немного скучное. Большинство шагов представляет собой проверку ошибок и выделение памяти из такого фрагмента, чтобы минимизировать утечку памяти.
- Поиск по таблице индексов с тем, чтобы найти наименьший фрагмент
памяти, который будет соответствовать запрашиваемому размеру памяти.
Поскольку таблица упорядочена, для поиска просто требуется итерация до тех пор, пока мы не найдем фрагмент, соответствующий нашему запросу.
- Если вы не нашли фрагмент памяти достаточного размера, то:
- Увеличьте кучу
- Если таблица индексов пуста (нет зарегистрированных фрагментов памяти), то добавьте в таблицу новую запись.
- В противном случае измените элемент, указывающий размер последнего заголовка блока и перепишите запись, находящуюся в конце блока.
- Чтобы уменьшить количество инструкций управления, мы можем просто снова рекурсивно вызвать функцию выделения памяти, полагая, что на этот раз будет найден достаточно большой фрагмент памяти.
- Если вы не нашли фрагмент памяти достаточного размера, то:
- Определите, должен ли фрагмент памяти быть разделен на две части. Как правило, это делается в случае, когда нам нужно гораздо меньше места, чем есть во фрагменте памяти. Единственное, когда этого не потребуется, если после выделения блока свободного места останется меньше, чем нужно на заголовок и на запись в конце блока. В этом случае мы можем просто увеличить размер блока и потом повторить все снова.
- Если блок должен быть выровнен по границе страницы, мы должны изменить начальный адрес блока так, что останется новый фрагмент памяти в неиспользованной области.
- Если это не так, то мы просто удаляем фрагмент из списка индексов.
- Запишите заголовок и завершающую запись новых блоков.
- Если фрагмент был разделен на две части, выполните это сейчас и запишите новый фрагмент в список индексов.
- Верните поользователю адрес блока + SizeOf (header_t).
7.2.2. Освобождение памяти
Возвращение (освобождение) памяти немного сложнее. Как уже упоминалось ранее, эффективность алгоритма управления памятью действительно проверена. Проблемой является эффективное повторное использование памяти. Наивным решением было бы просто объявить этот блок фрагментом неиспользуемой памяти и вернуть его обратно в список индексов фрагментов. Но, если я это делаю:
int a = kmalloc(8); // Выделяются 8 байтов: возвращает 0xC0080000 в качестве аргумента int b = kmalloc(8); // Выделяются еще 8 байтов: возвращается 0xC0080008. kfree(a); // Освобождается a kfree(b); // Освобождается b int c = kmalloc(16);// Что вернет эта операция выделения памяти?
Обратите внимание, что в этом примере для удобства чтения место, необходимое для заголовка блока и завершающей записи, преднамеренно не указывается.
Здесь мы дважды выделили место по 8 байтов. Затем мы освободили эти оба выделенные фрагменты. При использовании наивного решения освобождение памяти завершится наличием в списке индексов двух фрагментов размером по 8 байтов. При следующем выделении памяти (16 байтов) ни один из этих фрагментов нам не подходит, поэтому при обращении к kmalloc () мы получим адрес 0xC0080010. Это не оптимально. По адресу 0xC0080000 есть 16 байтов свободного места, поэтому мы должны их выделить заново!
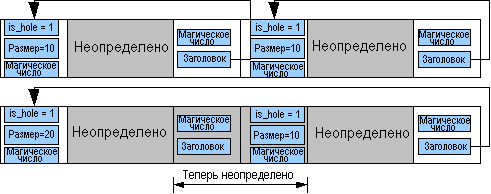
Решение этой проблемы в большинстве случаев представляет собой вариацию простого алгоритма, который я называю унификацией - то есть, преобразование двух соседних фрагментов в один. (Обратите внимание, что я воспользовался этим термином не из чувства собственной важности, а просто из-за отсутствия стандартизированного названия).
Это работает следующим образом: Когда происходит освобождение блока памяти, то делается попытка определить, что находится сразу слева перед заголовком блока (при условии, что адресация от 0 и до 4GB идет слева - направо). Если это завершающая запись другого блока, что можно обнаружить по значению магического числа, то по указателю переходим на заголовок этого блока и пытаемся определить, является ли он фрагментом свободного пространства или используемым блоком памяти. Если это фрагмент свободного пространства, то мы можем в его заголовке изменить атрибут размера так, чтобы он учитывал размер, как этого фрагмента, так и нашего освобождаемого блока памяти. После этого мы в заголовке этого фрагмента помещаем указатель на завершающую запись нашего блока. Таким образом, происходит объединение обоих фрагментов свободной памяти в один фрагмент (и в этом случае нет необходимости делать дорогостоящую операцию вставки значения в список индексов).
Это то, что я называю унификацией слева. Существует также унификация справа, которая должна также выполняться при освобождении памяти. В этом случае мы смотрим, что следует непосредственно после завершающей записи. Если мы обнаружим здесь заголовок, который опять же можно идентифицировать по магическому числу, мы проверяем, является ли это фрагментом неиспользуемой памяти. Затем мы можем использовать его размер с тем, чтобы найти его завершающую запись. Перепишем указатель в завершающей записи так, чтобы он указывал наш заголовок. Затем, все, что нужно сделать, это удалить старую запись о фрагменте из списка индексов кучи и добавить нашу собственную запись.
Обратите также внимание на того, как освобождается пространство памяти - если мы освобождаем последний блок в куче (после нет пустых фрагментов памяти или используемых блоков), то мы можем сократить размер кучи. Чтобы это не делать каждый раз, я в моей реализации определил минимальный размер кучи, меньше которого я размер кучи не уменьшаю.
7.2.2.1. Псевдокод
- Ищем заголовок, для этого мы берем данный указатель и определяем по нему значение sizeof(header_t).
- Проверяем корректность. Знаем, что магические номера, указываемые в заголовке и в завершающей записи блока, должны быть одинаковыми.
- Устанавливаем в нашем заголовке флаг is_hole, указывающий, что это пустой фрагмент, равным значению 1.
- Если непосредственно за нашей завершающей записью следует неиспользуемый фрагмент:
- Выполняем унификацию слева. В этом случае нам не нужно в конце алгоритма добавлять наш заголовок в список индексов неиспользуемых фрагментов (заголовок фрагмента, с которым выполняется унификация, уже находится в списке), так что устанавливаем флаг, который будет в алгоритме проверен позже.
- Если непосредственно перед нашим заголовком идет неиспользуемый фрагмент:
- Выполняем унификацию справа
- Если завершающая запись нашего блока последняя в куче ( footer_location+sizeof(footer_t) == end_address ):
- Уменьшаем размер кучи.
- В случае, если в пункте Унификация слева не установлен флаг, то добавляем наш заголовок в массив фрагментов неиспользуе6мой памяти.
7.3. Реализация упорядоченного списка
Итак, мы теперь мы переходим к реализации. Как обычно, я сначала собираюсь показать и объяснить вспомогательные типы данных и функции и завершить самими функциями выделения/освобождения памяти.
Первый тип данных, который нам потребуется в реализации, это упорядоченный список. Эта концепция будет использоваться в вашем ядре несколько раз (это обычная конструкция), так что, вероятно, хорошо выделить ее реализацию отдельно с тем, чтобы можно было воспользоваться ей снова.
7.3.1. Файл ordered_array.h
// ordered_array.h – Интерфейс создания упорядоченного массива и
// добавления к нему или удаления из него элементов.
// Написано для руководств по разработке ядра - автор James Molloy
#ifndef ORDERED_ARRAY_H
#define ORDERED_ARRAY_H
#include "common.h"
/**
Сортировка этого массива происходит при вставке элементов — он всегда будет отсортирован
(между двумя последовательными к нему обращениями)
В нем можно хранить все, что угодно; тип хранящихся объектов определяется как void*,
поэтому можно хранить u32int или какой-нибудь другой указатель .
**/
typedef void* type_t;
/**
Предикат должен возвращать ненулевое значение в случае, если первый аргумент меньше,
чем второй. В противном случае должно быть возвращено нулевое значение.
**/
typedef s8int (*lessthan_predicate_t)(type_t,type_t);
typedef struct
{
type_t *array;
u32int size;
u32int max_size;
lessthan_predicate_t less_than;
} ordered_array_t;
/**
Стандартный предикат less than (меньше, чем)
**/
s8int standard_lessthan_predicate(type_t a, type_t b);
/**
Создание упорядоченного массива
**/
ordered_array_t create_ordered_array(u32int max_size, lessthan_predicate_t less_than);
ordered_array_t place_ordered_array(void *addr, u32int max_size, lessthan_predicate_t less_than);
/**
Уничтожение упорядоченного массива
**/
void destroy_ordered_array(ordered_array_t *array);
/**
Добавление элемента в массив
**/
void insert_ordered_array(type_t item, ordered_array_t *array);
/**
Поиск элемента по индексу i.
**/
type_t lookup_ordered_array(u32int i, ordered_array_t *array);
/**
Удаление из массива элемента, расположенного по индексу i
**/
void remove_ordered_array(u32int i, ordered_array_t *array);
#endif // ORDERED_ARRAY_H
Обратите внимание, что в абстракции 'less than' (меньше, чем) у нас есть функция, определяемая пользователем. Мы будем использовать ее в реализации кучи для того, чтобы упорядочивать элементы по размеру, а не по адресам указателей. Также отметьте, что у нас есть два способа определения ordered_array. Определение create_ordered_array будет для получения некоторого пространства памяти использовать функцию kmalloc (). Определение place_ordered_array будет использовать указанное место, откуда нужно выделить память. Когда мы хотим размещать нашу кучу в определенном месте (и т. к. kmalloc еще не работает!), мы в коде реализации нашей кучи используем place_ordered_array.
7.3.2. Файл ordered_map.c
// ordered_array.c – Реализация функции создания упорядоченных массивов, а также
// функций вставки и удаления элементов упорядоченных массивов.
// Написано для руководств по разработке ядра - автор James Molloy
#include "ordered_array.h"
s8int standard_lessthan_predicate(type_t a, type_t b)
{
return (a<b)?1:0;
}
ordered_array_t create_ordered_array(u32int max_size, lessthan_predicate_t less_than)
{
ordered_array_t to_ret;
to_ret.array = (void*)kmalloc(max_size*sizeof(type_t));
memset(to_ret.array, 0, max_size*sizeof(type_t));
to_ret.size = 0;
to_ret.max_size = max_size;
to_ret.less_than = less_than;
return to_ret;
}
ordered_array_t place_ordered_array(void *addr, u32int max_size, lessthan_predicate_t less_than)
{
ordered_array_t to_ret;
to_ret.array = (type_t*)addr;
memset(to_ret.array, 0, max_size*sizeof(type_t));
to_ret.size = 0;
to_ret.max_size = max_size;
to_ret.less_than = less_than;
return to_ret;
}
void destroy_ordered_array(ordered_array_t *array)
{
// kfree(array->array);
}
void insert_ordered_array(type_t item, ordered_array_t *array)
{
ASSERT(array->less_than);
u32int iterator = 0;
while (iterator < array->size && array->less_than(array->array[iterator], item))
iterator++;
if (iterator == array->size) // just add at the end of the array.
array->array[array->size++] = item;
else
{
type_t tmp = array->array[iterator];
array->array[iterator] = item;
while (iterator < array->size)
{
iterator++;
type_t tmp2 = array->array[iterator];
array->array[iterator] = tmp;
tmp = tmp2;
}
array->size++;
}
}
type_t lookup_ordered_array(u32int i, ordered_array_t *array)
{
ASSERT(i < array->size);
return array->array[i];
}
void remove_ordered_array(u32int i, ordered_array_t *array)
{
while (i < array->size)
{
array->array[i] = array->array[i+1];
i++;
}
array->size--;
}
Надеюсь, что здесь ничего для вас не окажется удивительным. С помощью операции insert элемент помещается в необходимое место, а все последующие элементы сдвигаются на одну позицию. Поскольку это всегда сопровождается использованием сопутствующих типов данных, будет работать любая реализация. Есть более лучшие реализации упорядоченных массивов, чем эта (смотрите упорядочивание кучи, деревья бинарного поиска), но я решил воспользоваться в учебных целях более простым вариантом,
7.4. Собственно памяти типа куча
7.4.1. Файл kheap.h
Используются некоторые определения #defines и прототипы функций:
#define KHEAP_START 0xC0000000
#define KHEAP_INITIAL_SIZE 0x100000
#define HEAP_INDEX_SIZE 0x20000
#define HEAP_MAGIC 0x123890AB
#define HEAP_MIN_SIZE 0x70000
/**
Информация о размере неиспользуемого фрагмента/используемого блока памяти
**/
typedef struct
{
u32int magic; // Магическое число, используемое для контроля ошибок и индентификации.
u8int is_hole; // 1 — если это неиспользуемый фрагмент памяти; 0 — если используемый блок
u32int size; // Размер блока, в том числе завершающая запись блока.
} header_t;
typedef struct
{
u32int magic; // Магическое число, такое же самое, как и в header_t.
header_t *header; // Указатель на заголовок блока.
} footer_t;
typedef struct
{
ordered_array_t index;
u32int start_address; // Начало выделяемого пространства памяти.
u32int end_address; // Конец выделяемого пространства памяти. Может быть до значения max_address.
u32int max_address; // Максимальный адрес, до которого куча может расширяться.
u8int supervisor; // Должны ли дополнительные страницы, запрашиваемые вами, использоваться только в режиме супервизора?
u8int readonly; // Должны ли дополнительные страницы, запрашиваемые вами, использоваться только в режиме чтения?
} heap_t;
/**
Создаем новую кучу.
**/
heap_t *create_heap(u32int start, u32int end, u32int max, u8int supervisor, u8int readonly);
/**
Allocates a contiguous region of memory 'size' in size. If page_align==1, it creates that block starting
on a page boundary.
**/
void *alloc(u32int size, u8int page_align, heap_t *heap);
/**
Releases a block allocated with 'alloc'.
**/
void free(void *p, heap_t *heap);
Я решил, достаточно произвольно, поместить память типа куча, используемую в ядре, по адресу 0xC0000000, задав размер индексного списка в 0x20000 байтов, а минимальный размер памяти определить в 0x70000 байтов. Структуры заголовка и завершающей записи блока точно такие, как они заданы в начале данного раздела. Мы, на самом деле, можем использовать более одной кучи (в моем собственном ядре у меня также есть память типа куча пользовательского режима), поэтому для удобства я решил реализовать саму кучу как тип данных. В heap_t хранится информация об индекс списка кучи, об адресе начала / конце / максимуме и модификаторах, получаемых от alloc_page при дополнительном запросе памяти.
7.4.2. Файл kheap.c
Поиск наименьшего фрагмента, который будет соответствовать определенному количеству байт, является обычной задачей, которая выполняется при каждом выделении памяти. Поэтому было бы хорошо оформить ее в виде функции:
static s32int find_smallest_hole(u32int size, u8int page_align, heap_t *heap)
{
// Находим наименьший свободный фрагмент, который подходит.
u32int iterator = 0;
while (iterator < heap->index.size)
{
header_t *header = (header_t *)lookup_ordered_array(iterator, &heap->index);
// Если пользователь запросил память, которая выровнена по границе
if (page_align > 0)
{
// Выравниваем по границе начало заголовка.
u32int location = (u32int)header;
s32int offset = 0;
if ((location+sizeof(header_t)) & 0xFFFFF000 != 0)
offset = 0x1000 /* размер страницы */ - (location+sizeof(header_t))%0x1000;
s32int hole_size = (s32int)header->size - offset;
// Теперь подходит?
if (hole_size >= (s32int)size)
break;
}
else if (header->size >= size)
break;
iterator++;
}
// Когда выходить из цикла?
if (iterator == heap->index.size)
return -1; // Мы дошли до конца и ничего не нашли.
else
return iterator;
}
Мне кажется, что нужно объяснить следующие две строки:
if ((location+sizeof(header_t)) & 0xFFFFF000 != 0) offset = 0x1000 /* размер страницы */ - (location+sizeof(header_t))%0x1000;
Важно отметить, что когда пользователь запрашивает память, которая должна быть выровнена по границе страниц, он запрашивает память, к которой он получает доступ, выполняемый с учетом этого выравнивания. Это значит, что адрес заголовка на самом деле не будет выровнен по границе страниц. Адрес, если мы хотим, чтобы он попал на границу страницы, должен определяться как location + sizeof(header_t).
Создание кучи является простой процедурой. Единственное, на что нужно обратить внимание, это то, что мы отбрасываем первые HEAP_INDEX_SIZE*sizeof(type_t) байтов, поскольку они используются как список индексов. Список индексов помещается туда с помощью функции place_ordered_array, а реальный адрес начала кучи перемещается вперед. Именно поэтому, при тестировании ядра, вы увидите, что выделение памяти начинается с адреса 0xC0080000, а не с более очевидного адреса 0xC0000000. Также отметим, что мы создаем специальную функцию less_than, используемую для индексного массива. Это связано с тем, что стандартная функция less_than сортирует массив по адресам указателей, а не по размеру.
static s8int header_t_less_than(void*a, void *b)
{
return (((header_t*)a)->size < ((header_t*)b)->size)?1:0;
}
heap_t *create_heap(u32int start, u32int end_addr, u32int max, u8int supervisor, u8int readonly)
{
heap_t *heap = (heap_t*)kmalloc(sizeof(heap_t));
// Мы предполагаем, что startAddress и endAddress выровнены по границе страниц.
ASSERT(start%0x1000 == 0);
ASSERT(end_addr%0x1000 == 0);
// Инициализируем список индексов.
heap->index = place_ordered_array( (void*)start, HEAP_INDEX_SIZE, &header_t_less_than);
// Сдвигаем начальный адрес вперед, куда мы можем начать помещать данные.
start += sizeof(type_t)*HEAP_INDEX_SIZE;
// Обесчьте, чтобы начальный адрес был выровнен по границе страниц.
if (start & 0xFFFFF000 != 0)
{
start &= 0xFFFFF000;
start += 0x1000;
}
// Запишите начальный, конечный и максимальный адреса в структуру памяти типа куча.
heap->start_address = start;
heap->end_address = end_addr;
heap->max_address = max;
heap->supervisor = supervisor;
heap->readonly = readonly;
// Мы начинаем с одного большого фрагмента свободной памяти, указанной в списке индексов.
header_t *hole = (header_t *)start;
hole->size = end_addr-start;
hole->magic = HEAP_MAGIC;
hole->is_hole = 1;
insert_ordered_array((void*)hole, &heap->index);
return heap;
}
7.4.2.1. Расширения и ограничения
В ряде случаев нам нужно будет изменить размер нашей кучи. Если у нас не осталось свободного места, нам потребуется выделить еще памяти. Если мы возвращаем память, нам, возможно, потребуется куча меньшего размера.
static void expand(u32int new_size, heap_t *heap)
{
// Проверяем правильность значений.
ASSERT(new_size > heap->end_address - heap->start_address);
// Получаем следующую ближайшую границу страницы.
if (new_size&0xFFFFF000 != 0)
{
new_size &= 0xFFFFF000;
new_size += 0x1000;
}
// Убеждаемся, что мы не перехитрили сами себя
ASSERT(heap->start_address+new_size <= heap->max_address);
// Это значение должно всегда быть на границе страницы.
u32int old_size = heap->end_address-heap->start_address;
u32int i = old_size;
while (i < new_size)
{
alloc_frame( get_page(heap->start_address+i, 1, kernel_directory),
(heap->supervisor)?1:0, (heap->readonly)?0:1);
i += 0x1000 /* page size */;
}
heap->end_address = heap->start_address+new_size;
}
Я думаю, что код не требует пояснений. Выполняется несколько проверок, а затем параметр new_size изменяется таким образом, чтобы он попал на границу страницы. Затем в соответствии с параметрами, заданными при создании кучи (режим супервизора?, доступ только для чтения?) последовательно один за другим выделяются фреймы.
static u32int contract(u32int new_size, heap_t *heap)
{
// Проверяем правильность значений.
ASSERT(new_size < heap->end_address-heap->start_address);
// Получаем следующую ближайшую границу страницы.
if (new_size&0x1000)
{
new_size &= 0x1000;
new_size += 0x1000;
}
// Не следует уменьшать размер слишком сильно!
if (new_size < HEAP_MIN_SIZE)
new_size = HEAP_MIN_SIZE;
u32int old_size = heap->end_address-heap->start_address;
u32int i = old_size - 0x1000;
while (new_size < i)
{
free_frame(get_page(heap->start_address+i, 0, kernel_directory));
i -= 0x1000;
}
heap->end_address = heap->start_address + new_size;
return new_size;
}
Все аналогично расширению кучи, значение new_size должно попадать на границу страницы. Затем мы проверим, что мы не пытаемся уменьшить размер меньше нашего минимального размера и освобождаем фреймы до тех пор, пока не достигнем нужного размера.
7.4.2.2. Выделение памяти
Мы разберем функцию выделения памяти поэтапно.
void *alloc(u32int size, u8int page_align, heap_t *heap)
{
// Проверяем, что мы также учитываем размер заголовка / завершающей записи блока.
u32int new_size = size + sizeof(header_t) + sizeof(footer_t);
// Находим наименьший фрагмент свободный памяти, которые соответствует нашему запросу.
s32int iterator = find_smallest_hole(new_size, page_align, heap);
if (iterator == -1) // Если мы не нашли подходящего фрагмента
{
... // Заполним через секунду
}
Здесь мы настраиваем размер запрашиваемого блока с учетом его заголовка и его завершающей записи. Затем мы с помощью нашей функции find_smallest_hole запрашиваем наименьший свободный фрагмент, который подходит. Если мы не смогли найти такой фрагмент (find_smallest_hole () == -1), мы переходим к коду обработки некоторой ошибки. Такое решение в некоторой степени спорно, поэтому я вернусь к нему, чтобы его пояснить.
header_t *orig_hole_header = (header_t *)lookup_ordered_array(iterator, &heap->index);
u32int orig_hole_pos = (u32int)orig_hole_header;
u32int orig_hole_size = orig_hole_header->size;
// Сюда мы попадаем, если мы должны разделить фрагмент, который мы нашли, на две части.
// Является ли размер исходного (запрашиваемого) фрагмента меньше накладных расходов на добавление нового фрагмента?
if (orig_hole_size-new_size < sizeof(header_t)+sizeof(footer_t))
{
// Тогда просто увеличиваем запрашиваемый размер до размера найденного фрагмента.
size += orig_hole_size-new_size;
new_size = orig_hole_size;
}
Здесь мы из индексного списка, выданного нам функцией find_smallest_hole, получаем указатель на заголовок. Затем мы сохраняем адрес и размер этого заголовка на случай, если позже нам потребуется его переписать. После этого мы решаем, стоит ли делить фрагмент на два фрагмента (то есть, будет ли достаточно во втором фрагменте оставшегося места?) Если нет, то мы увеличиваем запрашиваемый размер так, чтобы не делать разбиение фрагмента.
// Если нам нужно выравнивать данные по границе страницы, то выполните это сейчас
// и сделайте так, чтобы новый фрагмент находился перед нашим блоком памяти.
if (page_align && orig_hole_pos&0xFFFFF000)
{
u32int new_location = orig_hole_pos + 0x1000 /* page size */ - (orig_hole_pos&0xFFF) - sizeof(header_t);
header_t *hole_header = (header_t *)orig_hole_pos;
hole_header->size = 0x1000 /* page size */ - (orig_hole_pos&0xFFF) - sizeof(header_t);
hole_header->magic = HEAP_MAGIC;
hole_header->is_hole = 1;
footer_t *hole_footer = (footer_t *) ( (u32int)new_location - sizeof(footer_t) );
hole_footer->magic = HEAP_MAGIC;
hole_footer->header = hole_header;
orig_hole_pos = new_location;
orig_hole_size = orig_hole_size - hole_header->size;
}
else
{
// В противном случае этот фрагмент нам больше не нужен, удалите его из списка индексов.
remove_ordered_array(iterator, &heap->index);
}
Если пользователь хочет, чтобы его память была выровнена по границе страниц, мы это здесь делаем. Новое положение размещаемого заголовка рассчитывается путем перехода к следующей границе страницы, а затем вычитания размера заголовка. Затем заполняются атрибуты заголовка нового фрагмента и добавляется завершающая запись. Обратите внимание, что поскольку мы создаем новый фрагмент по адресу старого фрагмента, мы, по сути, повторно используем старый фрагмент, так что удалять его из списка индексов фрагментов не требуется.
// Переписываем исходный заголовок ... header_t *block_header = (header_t *)orig_hole_pos; block_header->magic = HEAP_MAGIC; block_header->is_hole = 0; block_header->size = new_size; // ... И завершающую запись footer_t *block_footer = (footer_t *) (orig_hole_pos + sizeof(header_t) + size); block_footer->magic = HEAP_MAGIC; block_footer->header = block_header;
Здесь все должно быть понятно — все, что мы делаем, это корректируем заголовок и завершающую запись, в том числе и магические числа.
// Нам после выделенного блока может потребоваться записать новый фрагмент.
// Мы делаем это только если размер нового фрагмента положительный ...
if (orig_hole_size - new_size > 0)
{
header_t *hole_header = (header_t *) (orig_hole_pos + sizeof(header_t) + size + sizeof(footer_t));
hole_header->magic = HEAP_MAGIC;
hole_header->is_hole = 1;
hole_header->size = orig_hole_size - new_size;
footer_t *hole_footer = (footer_t *) ( (u32int)hole_header + orig_hole_size - new_size - sizeof(footer_t) );
if ((u32int)hole_footer < heap->end_address)
{
hole_footer->magic = HEAP_MAGIC;
hole_footer->header = hole_header;
}
// Помещаем новый фрагмент в индексный список;
insert_ordered_array((void*)hole_header, &heap->index);
}
Если нам требуется разделить наш фрагмент на два фрагмента, мы делаем это здесь, создавая при этом новый фрагмент.
// ...И мы все сделали! return (void *) ( (u32int)block_header+sizeof(header_t) ); }
... И это наша функция выделения памяти! Единственное, что осталось сделать, это добавить код, проверяющий ошибки, который мы ранее пропустили:
if (iterator == -1) // Если мы не нашли подходящий фрагмент
{
// Сохраняем некоторые ранее полученные данные.
u32int old_length = heap->end_address - heap->start_address;
u32int old_end_address = heap->end_address;
// Нам нужно выделить немного больше памяти.
expand(old_length+new_size, heap);
u32int new_length = heap->end_address-heap->start_address;
// Находим самый последний заголовок. (Последний не по размеру, а по месторасположению).
iterator = 0;
// В переменных хранятся индекс и значение самого последнего заголовка, найденного к текущему моменту.
u32int idx = -1; u32int value = 0x0;
while (iterator < heap->index.size)
{
u32int tmp = (u32int)lookup_ordered_array(iterator, &heap->index);
if (tmp > value)
{
value = tmp;
idx = iterator;
}
iterator++;
}
// Если мы вообще не нашли НИКАКИХ заголовков, на нужно один заголовок добавить.
if (idx == -1)
{
header_t *header = (header_t *)old_end_address;
header->magic = HEAP_MAGIC;
header->size = new_length - old_length;
header->is_hole = 1;
footer_t *footer = (footer_t *) (old_end_address + header->size - sizeof(footer_t));
footer->magic = HEAP_MAGIC;
footer->header = header;
insert_ordered_array((void*)header, &heap->index);
}
else
{
// Последний заголовок нужно настроить.
header_t *header = lookup_ordered_array(idx, &heap->index);
header->size += new_length - old_length;
// Переписываем завершающую запись.
footer_t *footer = (footer_t *) ( (u32int)header + header->size - sizeof(footer_t) );
footer->header = header;
footer->magic = HEAP_MAGIC;
}
// Теперь у над достаточно места. Снова обращаемся к этой функции рекурсивно.
return alloc(size, page_align, heap);
}
Эта часть очень проста по своей работе, но большая по размеру кода. Если не был найден фрагмент достаточного размера (iterator == -1), мы должны увеличить размер кучи (с помощью вызова функции expand). Затем мы должны для этого расширения сделать запись в индексном списке. Обычный способ сделать это - найти в индексном списке самый последний фрагмент и изменить его размер. Единственный случай, когда это не будет работать, это когда в индексном списке вообще нет никаких фрагментов (маловероятный, но возможный случай). В этом случае мы должны создать один фрагмент для того, чтобы перейти к известному решению.
7.4.2.3. Освобождение памяти
Снова мы разберем эту функцию поэтапно.
void free(void *p, heap_t *heap)
{
// Выход в случае нулевых указателей.
if (p == 0)
return;
// Берем заголовок и завершающую запись, связанные с этим указателем.
header_t *header = (header_t*) ( (u32int)p - sizeof(header_t) );
footer_t *footer = (footer_t*) ( (u32int)header + header->size - sizeof(footer_t) );
// Проверяем правильность значений.
ASSERT(header->magic == HEAP_MAGIC);
ASSERT(footer->magic == HEAP_MAGIC);
Сначала мы находим заголовок путем вычитания sizeof(header_t) из p, а затем используем его для того, чтобы найти завершающую запись. Всегда хорошо проверить правильность значений, поскольку можно сразу обнаружить ситуацию, когда в вашем коде перезаписаны важные данные.
// Создаем фрагмент свободной памяти. header->is_hole = 1; // Хотим ли мы добавит этот заголовок в список индексов 'фрагменты свободной памяти' index? char do_add = 1;
Этот блок в настоящее время освобожден, поэтому сейчас он является фрагментом свободной памяти. Мы также создаем переменную, в которой указываем, должны ли мы добавить заголовок в список индексов (смотрите описание алгоритма).
// Унификация слева
// Если непосредственно слева от фрагмента находится завершающая запись другого фрагмента ...
footer_t *test_footer = (footer_t*) ( (u32int)header - sizeof(footer_t) );
if (test_footer->magic == HEAP_MAGIC &&
test_footer->header->is_hole == 1)
{
u32int cache_size = header->size; // Кэшируем наш текущий размер.
header = test_footer->header; // Перезаписываем вместо нашего новый заголовок.
footer->header = header; // Заменяем нашу завершающую запись новой, на которую указывает новый заголовок.
header->size += cache_size; // Изменяем размер.
do_add = 0; // Поскольку этот заголовок уже в индексном списке, нам не нужно добавлять его снова.
}
В этой части кода выполняется наша левая унификация (объединение влево). Если мы вычтем sizeof(header_t) из адреса заголовка, мы можем получить указатель на завершающую запись. Мы проверяем, что это действительно правильная завершающая запись при помощи проверки в ней магического числа и проверкой того, что это фрагмент (а не выделенная память!). Если это так, мы перепишем нашу завершающую запись, на которую будет указывать переменная test_footer, находящаяся в заголовке, изменяем наш размер и указываем в алгоритме не добавлять запись в список индексов фрагментов (поскольку заголовок только что унифицированного фрагмента уже находится в индексном списке!).
// Унификация справа
// Если непосредственно справа от фрагмента находится заголовок другого фрагмента ...
header_t *test_header = (header_t*) ( (u32int)footer + sizeof(footer_t) );
if (test_header->magic == HEAP_MAGIC &&
test_header->is_hole)
{
header->size += test_header->size; // Увеличиваем наш размер.
test_footer = (footer_t*) ( (u32int)test_header + // Переписываем завершающую запись, на которую указывает наш заголовок.
test_header->size - sizeof(footer_t) );
footer = test_footer;
// Находим и удаляем этот заголовок из списка индексов.
u32int iterator = 0;
while ( (iterator < heap->index.size) &&
(lookup_ordered_array(iterator, &heap->index) != (void*)test_header) )
iterator++;
// Убеждаемся, что мы действительно нашли правильный объект.
ASSERT(iterator < heap->index.size);
// Удаляем его.
remove_ordered_array(iterator, &heap->index);
}
Аналогичным образом в этом коде выполняется правая унификация. Опять же, мы проверяем, находится сразу справа заголовок и является ли пространство памяти справа фрагментом неиспользуемой памяти. Перепишем его завершающую запись так, чтобы она указывала на наш заголовок, а затем удалим заголовок фрагмента, находящегося справа, из списка индексов.
// Если положение завершающей записи совпадает с конечным адресом кучи, мы можем уменьшить кучу.
if ( (u32int)footer+sizeof(footer_t) == heap->end_address)
{
u32int old_length = heap->end_address-heap->start_address;
u32int new_length = contract( (u32int)header - heap->start_address, heap);
//Проверяем насколько большой будет куча после изменения размера.
if (header->size - (old_length-new_length) > 0)
{
// Мы еще существуем - Теперь собственно изменяем размер.
header->size -= old_length-new_length;
footer = (footer_t*) ( (u32int)header + header->size - sizeof(footer_t) );
footer->magic = HEAP_MAGIC;
footer->header = header;
}
else
{
// Теперь нас нет :(. Удаляем нас из списка индексов.
u32int iterator = 0;
while ( (iterator < heap->index.size) &&
(lookup_ordered_array(iterator, &heap->index) != (void*)test_header) )
iterator++;
// Если мы себя не нашли, то нам и нечего удалять.
if (iterator < heap->index.size)
remove_ordered_array(iterator, &heap->index);
}
}
Это почти последний фрагмент кода (я обещаю!). Если мы поместили последний фрагмент в список индексов (то есть, один ближе всех к концу памяти), то мы можем уменьшить размер кучи. Мы должны запомнить старый размер кучи, а затем выполнить сжатие командой contract(). Здесь возможен один из двух следующих вариантов: либо команда contract() уменьшит кучу так, что нашего фрагмента больше не будет (вариант 'else'), или она уменьшит кучу частично или совсем ее не уменьшит. В этом случае фрагмент все еще будет существовать, но мы должны изменить его размер. Перепишем его завершающую запись с новым размером и выходим из алгоритма. Если фрагмент был удален, мы просто ищем его в списке индексов и сами удаляем его оттуда.
Еще чуть-чуть напоследок:
if (do_add == 1) insert_ordered_array((void*) header, &heap->index);
Если мы должны добавить фрагмент в список индексов, то это надо сделать здесь. И вот еще что! Следующее, что нужно сделать, когда инициализируется страничное управление памятью, это инициализировать кучу, :)
7.4.2.4. Файл paging.c
extern heap_t *kheap;
Мы объявляем переменную kheap как нашу память типа куча, используемую в ядре. Мы определяем ее в файле kheap.c (вы можете сделать это самостоятельно) и здесь на нее ссылаемся.
// Отображаем несколько страниц в область кучи ядра. Здесь мы вызываем функцию
// get_page, но не функцию alloc_frame. В результате можно создавать таблицы page_table_t
// там, где это необходимо. Мы не можем выделить фреймы еще потому, что для них сначала нужно
// выполнить взаимно однозначное отображение вниз и мы все еще не можем определить адрес размещения
// placement_address, используемый между однозначным отображением и механизмом поддержки кучи!
int i = 0;
for (i = KHEAP_START; i < KHEAP_START+KHEAP_INITIAL_SIZE; i += 0x1000)
get_page(i, 1, kernel_directory);
Перед тем, как мы выполним взаимно однозначное отображение из 0-placement_addr, мы перейдем к функции инициализации страниц initialise_paging. Есть причина для обращения к этому коду. Поскольку когда мы записываем в кучу ядра, она сдвигается вверх на адрес 0xC0000000, потребуется создать таблицы с несколькими страницами (т. к. ранее с этой областью никакие операции не производились). Тем не менее, после того как мы выполним цикл, позволяющий все взаимно-однозначно отобразить на адрес placement_address, мы больше не сможем пользоваться функцией kmalloc до тех пор, пока наша куча не будет активирована! Итак, прежде, чем мы зафиксируем адрес размещения, нам нужно будет принудительно создать таблицы. Это то, что делает следующий код:
// Теперь размещаем страницы, для которых ранее было выполнено отображение.
for (i = KHEAP_START; i < KHEAP_START+KHEAP_INITIAL_SIZE; i += 0x1000)
alloc_frame( get_page(i, 1, kernel_directory), 0, 0);
// Прежде, чем мы включим страничную организацию памяти, нам нужно
// зарегистрировать обработчик неверного обращения к страницам.
register_interrupt_handler(14, page_fault);
// Теперь включаем страницную организацию памяти!
switch_page_directory(kernel_directory);
// Инициализируем кучу ядра .
kheap = create_heap(KHEAP_START, KHEAP_START+KHEAP_INITIAL_SIZE, 0xCFFFF000, 0, 0);
И, вуаля! Вы все сделали! Было бы хорошо сделать такую штуку (которую я сделал в моем коде с примерами), чтобы функции kmalloc/kfree могли передавать обращения напрямую к функциям alloc/free в случае, если kheap! = 0. Я предлагаю вам сделать это самостоятельно ;)
7.5. Тестирование
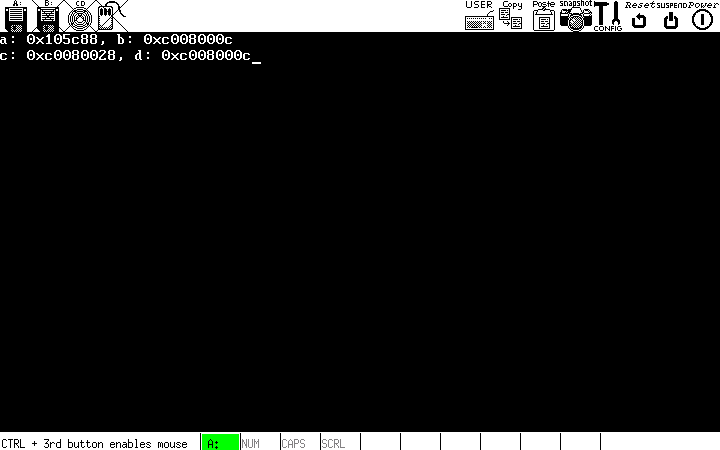
main.c
u32int a = kmalloc(8);
initialise_paging();
u32int b = kmalloc(8);
u32int c = kmalloc(8);
monitor_write("a: ");
monitor_write_hex(a);
monitor_write(", b: ");
monitor_write_hex(b);
monitor_write("\nc: ");
monitor_write_hex(c);
kfree(c);
kfree(b);
u32int d = kmalloc(12);
monitor_write(", d: ");
monitor_write_hex(d);
Вы, конечно, можете здесь поэкспериментировать с последовательностью, в которой выделяется и освобождается память. В коде, приведенном выше, память под переменную a выделяется раньше, чем происходит обращение к функции рinitialise_paging, так что это будет выполнено с использованием адреса размещения placement address. Память для переменных b и c выделяется в куче, а затем выдается сообщение о размещении переменных. Затем память, выделенная под последние переменные, освобождается и создается еще одна переменная - d. Если адрес переменной d точно такой же, как адрес переменной b, то пространство, использовавшееся переменными b и c, успешно утилизировано и все в порядке!
7.6. Итог
Динамическое выделение памяти является одной из немногих вещей, без которых очень трудно обойтись. Без него вам придется указывать абсолютно по максимуму количество запускаемых процессов (статический массив для значений pids), вы должны будете задавать статически размер каждого буфера - Вообще-то сделаете свою ОС тусклой и крайне неэффективной.
Пример кода, как всегда, можно найти здесь.
| Назад | К началу | Вперед |