





Библиотека сайта rus-linux.net
Виртуальные файловые системы в Linux: зачем они нужны и как они работают
Оригинал: Virtual filesystems in Linux: Why we need them and how they work
Автор: Alison Chaiken
Дата публикации: 8 марта 2019 года
Перевод: А. Кривошей
Дата перевода: май 2019 г.
Что такое файловая система? По словам , «файловая система - это иерархическое хранилище данных, привязанных к определенной структуре». Однако это описание одинаково хорошо применимо к VFAT (виртуальная таблица размещения файлов), Git и Cassandra (база данных NoSQL). Так что же отличает файловую систему?
Основы файловых систем
Ядро Linux требует, чтобы сущность, которая считается файловой системой, должна реализовывать методы open(), read() и write() для постоянных объектов, имеющих название. С точки зрения объектно-ориентированного программирования ядро рассматривает общую файловую систему как абстрактный интерфейс, и эти три главные функции являются «виртуальными», без определения по умолчанию. Соответственно, стандартная реализация файловой системы ядра называется виртуальной файловой системой (VFS).
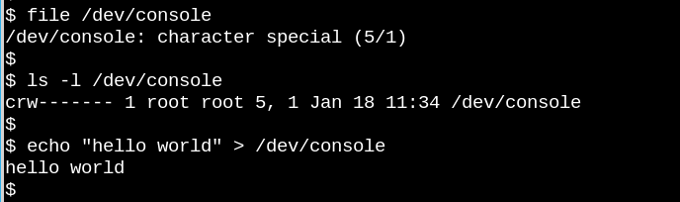
VFS лежит в основе известного наблюдения, что в Unix-подобных системах «все является файлом». Подумайте, как странно, что крошечное демо с символьным устройством /dev/console на самом деле работает. Изображение показывает интерактивный сеанс Bash по виртуальному телетайпу (tty). При отправке строки в устройство виртуальной консоли она появляется на виртуальном экране. VFS имеет другие, даже более странные свойства. Например, в ней можно производить поиск.
Все известные файловые системы, такие как ext4, NFS и /proc, предоставляют определения функций большой тройки в структуре данных на языке C, называемой file_operations. Кроме того, некоторые файловые системы расширяют и переопределяют функции VFS в рамках объектно-ориентированного подхода. Как указывает Роберт Лав, абстракция VFS позволяет пользователям Linux безболезненно копировать файлы в и из сторонних операционных систем или абстрактных объектов, таких как каналы, не беспокоясь о внутреннем формате данных. От имени пользовательского пространства с помощью системного вызова процесс может копировать из файла в структуры данных ядра с помощью метода read() одной файловой системы, а затем использовать метод write() другого типа файловой системы для вывода данных.
Определения функций, которые принадлежат самому базовому типу VFS, находятся в файлах fs/*.c в исходном коде ядра, а подкаталоги fs/ содержат определенные файловые системы. Ядро также содержит объекты, подобные файловой системе, такие как cgroups, /dev и tmpfs, которые необходимы на ранних этапах процесса загрузки и поэтому определяются в подкаталоге init/ ядра. Обратите внимание, что cgroups, /dev и tmpfs не вызывают три главные функции file_operations, а вместо этого непосредственно читают и записывают в память.
Диаграмма ниже примерно иллюстрирует, как пользовательское пространство обращается к различным типам файловых систем, обычно монтируемых в системах Linux. Не показаны такие конструкции, как pipe, dmesg и часы POSIX, которые также реализуют struct file_operations и доступ к которым, следовательно, происходит через уровень VFS.
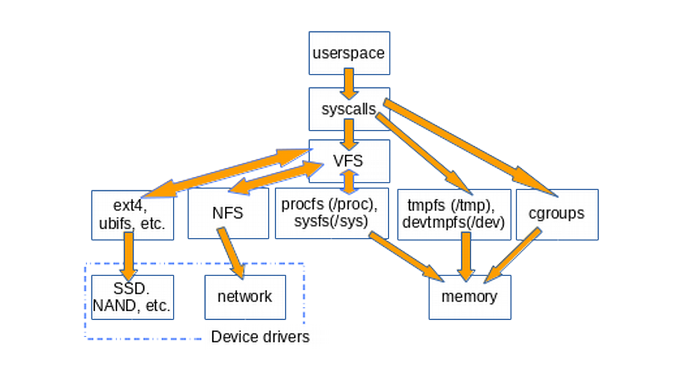
VFS - это "слой прокладки" между системными вызовами и разработчиками определенных файловых систем, таких как ext4 и procfs. Затем функции file_operations могут взаимодействовать либо с драйверами, специфичными для устройства, либо с аксессорами памяти. tmpfs, devtmpfs и cgroups не используют file_operations, но имеют прямой доступ к памяти.
Существование VFS способствует повторному использованию кода, поскольку базовые методы, связанные с файловыми системами, не нужно повторно реализовывать в каждом типе файловой системы. Повторное использование кода - это общепринятая лучшая практика разработки программного обеспечения! Увы, если повторно используемый код вносит серьезные ошибки, то от них страдают все реализации, которые наследуют общие методы.
/tmp: простой совет
Простой способ выяснить, какие VFS присутствуют в системе, набрать команду mount | grep -v sd | grep -v :/, которая выводит все смонтированные файловые системы, которые не находятся на диске и не являются NFS на большинстве компьютеров. Одной из перечисленных точек монитирования VFS наверняка будет /tmp, верно?

Все знают, что хранение /tmp на физическом носителе - это безумие!
Почему хранить /tmp на носителе нецелесообразно? Потому что файлы в /tmp являются временными (!), а устройства хранения данных работают медленнее, чем оперативная память, где создается tmpfs. Кроме того, физические устройства более подвержены износу при частой записи. Наконец, файлы в /tmp могут содержать конфиденциальную информацию, поэтому возможность их исчезновения при каждой перезагрузке - это преимущество.
К сожалению, установочные скрипты для некоторых дистрибутивов Linux по умолчанию создают /tmp на жестком диске. Не отчаивайтесь, если это произойдет с вашей системой. Следуйте простым инструкциям в великолепной Arch Wiki, чтобы решить эту проблему, помня, что память, выделенная для tmpfs, не доступна для других целей. Другими словами, система с гигантскими tmpfs с большими файлами в ней может исчерпать доступную память и зависнуть. Другой совет: при редактировании файла /etc/fstab обязательно заканчивайте его новой строкой, иначе ваша система не загрузится.
/proc и /sys
Помимо /tmp, VFS, с которыми большинство пользователей Linux лучше всего знакомы, это /proc и /sys. (/dev полагается на разделяемую память и не использует файловых операций). Почему две файловые системы? Давайте посмотрим их более подробно.
Procfs предлагает моментальный снимок состояния ядра и процессов, которые оно контролирует для пользовательского пространства. В /proc ядро публикует информацию о предоставляемых им средствах, таких как прерывания, виртуальная память и планировщик. Кроме того, /proc/sys - это место, где параметры, которые можно настроить с помощью команды sysctl, доступны для пользователя. Состояние и статистика по отдельным процессам указываются в каталогах /proc/
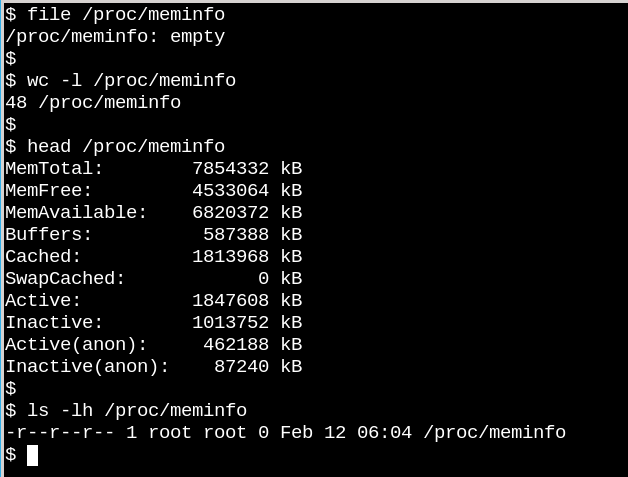
/proc /meminfo - это пустой файл, который, тем не менее, содержит ценную информацию.
Поведение файлов в /proc показывает, насколько VFS может отличаться от файловых систем на диске. С одной стороны, /proc/meminfo содержит информацию, представленную командой free. С другой стороны, он также пустой! Как это может быть? Ситуация напоминает известную статью, написанную физиком Корнелльского университета Н. Дэвидом Мермином в 1985 году, под названием «Есть ли луна там, куда никто не смотрит? Реальность и квантовая теория». Правда в том, что ядро собирает статистику о памяти, когда процесс запрашивает его, из /proc, и в файлах /proc фактически ничего нет, когда никто не просматривает их. Как сказал Мермин, «фундаментом квантовой доктрины является то, что измерение, как правило, не выявляет ранее существовавшее значение измеряемого свойства».

Файлы в /proc пустые, когда к ним не обращается ни один процесс (источник).
Кажущаяся пустота procfs имеет смысл, поскольку доступная там информация динамична. Ситуация с sysfs другая. Давайте сравним, сколько файлов размером не менее одного байта существует в /proc и /sys.

Procfs имеет именно одну, а именно экспортированную конфигурацию ядра, что является исключением, поскольку его нужно генерировать только один раз при загрузке. С другой стороны, /sys имеет много файлов большего размера, большинство из которых составляют одну страницу памяти. Как правило, файлы sysfs содержат ровно одно число или строку, в отличие от таблиц информации, создаваемой чтением таких файлов, как /proc/meminfo.
Цель sysfs - предоставить доступ для чтения и записи свойств того, что ядро называет "kobjects", в пространстве пользователя. Единственная цель kobjects - подсчет ссылок: когда последняя ссылка на kobject удаляется, система возвращает связанные с ним ресурсы. Тем не менее, /sys представляет собой большую часть знаменитого «stable ABI to userspace» ядра, которое никто и ни при каких обстоятельствах не может «сломать». Это не означает, что файлы в sysfs являются статическими, что противоречило бы подсчету ссылок изменчивых объектов.
Вместо этого стабильный ABI ядра ограничивает то, что может появиться в /sys, а не то, что действительно присутствует там в данный момент. Перечисление разрешений для файлов в sysfs дает представление о том, как настраиваемые параметры устройств, модулей, файловых систем и т. д., могут быть заданы или прочитаны. Логика заставляет прийти к заключению, что procfs также является частью стабильного ABI ядра, хотя в документации ядра это не указано явно.
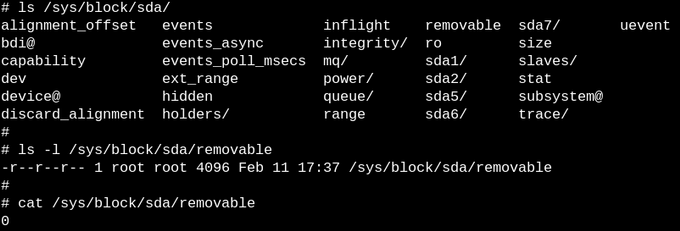
Файлы в sysfs описывают ровно одно свойство каждого объекта и могут быть читаемыми, записываемыми или все это вместе. «0» в файле показывает, что SSD не является съемным.
Отслеживание VFS с помощью утилит eBPF и bcc
Самый простой способ узнать, как ядро управляет файлами sysfs, - это посмотреть его в действии, а самый простой способ посмотреть это на ARM64 или x86_64 - использовать eBPF. eBPF (extended Berkeley Packet Filter) состоит из виртуальной машины, работающей внутри ядра, которую привилегированные пользователи могут запрашивать из командной строки. Код ядра сообщает читателю, что может сделать ядро; запуск инструментов eBPF в загруженной системе показывает, что фактически делает ядро.
К счастью, начать работу с eBPF довольно просто с помощью утилит bcc, которые доступны в виде пакетов из основных дистрибутивов Linux и подробно документированы Бренданом Греггом. Утилиты bcc - это скрипты Python с небольшими встроенными фрагментами C, поэтому любой, кто знаком с любым языком, может легко их изменить. На этот счет в bcc/tools есть 80 скриптов Python, поэтому весьма вероятно, что системный администратор или разработчик найдет соответствующий его потребностям.
Чтобы получить очень общее представление о том, какую работу выполняют VFS в работающей системе, попробуйте скрипты vfscount или vfsstat, которые показывают, что каждую секунду происходят десятки вызовов vfs_open() и подобных ему.
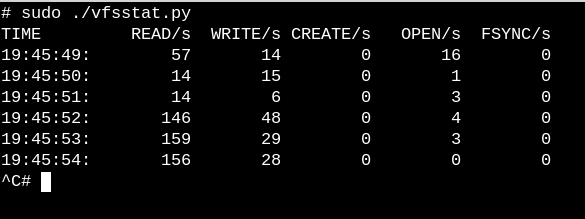
vfsstat.py - это скрипт Python со встроенным фрагментом C, который просто считает вызовы функций VFS.
Для менее тривиального примера давайте посмотрим, что происходит в sysfs, когда в работающую систему вставлена USB-флешка.
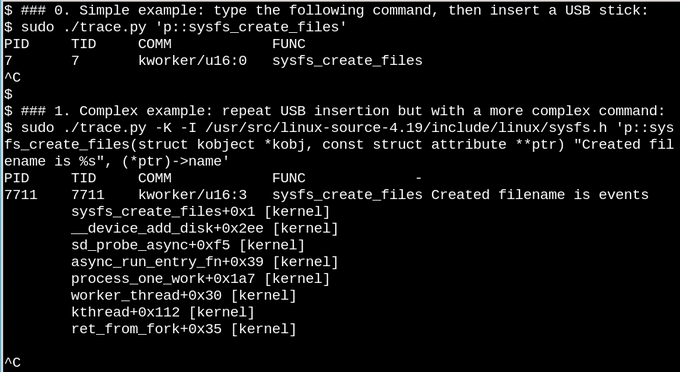
Посмотрите с помощью eBPF, что происходит в /sys, когда вставлена флешка.
В первом простом примере, приведенном выше, скрипт trace.py выводит сообщение всякий раз, когда запускается команда sysfs_create_files(). Мы видим, что sysfs_create_files() была запущена потоком kworker в ответ на вставку USB-накопителя, но какой файл при этом был создан? Второй пример иллюстрирует полную мощь eBPF. Здесь trace.py выводит обратную трассировку ядра (опция -K) плюс имя файла, созданного sysfs_create_files(). Фрагмент внутри одинарных кавычек представляет собой некоторый исходный код на C, включая легко распознаваемую строку format, которая побуждает компилятор LLVM на лету компилировать и выполнять код внутри виртуальной машины в ядре. Полная сигнатура функции sysfs_create_files() должна быть воспроизведена во второй команде, чтобы строка format могла ссылаться на один из параметров. Ошибки в этом фрагменте C приводят к распознаваемым ошибкам компилятора C. Например, если опущен параметр -I, результатом будет «Failed to compile BPF text». Разработчики, знакомые с C или Python, найдут, что утилиты bcc легко расширять и модифицировать.
Когда вставлен USB-накопитель, появляется обратная трассировка ядра, показывающая, что PID 7711 является потоком kworker, который создал файл с именем «events» в sysfs. Соответствующий вызов sysfs_remove_files() показывает, что удаление флешки приводит к удалению файла events в соответствии с идеей подсчета ссылок. Просмотр sysfs_create_link() с помощью eBPF во время вставки USB-накопителя (не показан) показывает, что создано не менее 48 символических ссылок.
В любом случае, какова цель файла events? Использование cscope для поиска function __device_add_disk() показывает, что она вызывает disk_add_events(), и либо «media_change», либо «eject_request» могут быть записаны в файл events. Здесь блочный уровень ядра информирует пространство пользователя о появлении и исчезновении «диска». Подумайте, насколько быстро этот метод исследует, как работает вставка USB-накопителя, в сравнении с попыткой изучить этот процесс исключительно из источников.
Доступные только для чтения корневые файловые системы делают возможными встроенные устройства.
Конечно, никто не выключает сервер или настольную систему, вынув вилку из розетки. Почему? Так как смонтированные файловые системы на физических устройствах хранения данных могут иметь отложенные ожидающие записи, а структуры данных, которые записывают их состояние, могут быть не синхронизированы с тем, что записано в хранилище. Если это произойдет, пользователи системы должны будут ждать при следующей загрузке, пока не запустится утилита восстановления файловой системы fsck, и в худшем случае они потеряют данные.
Тем не менее, многие слышали, что большинство IoT и встроенных устройств, такие как маршрутизаторы, термостаты и автомобили, теперь работают под управлением Linux. У многих из этих устройств почти полностью отсутствует пользовательский интерфейс, и нет способа их «чистой» перезагрузки. Подумайте о запуске автомобиля с разряженной батареей, когда питание бортового компьютера под управлением Linux скачет. Как получается, что система загружается без длинного fsck, когда двигатель наконец запускается? Ответ заключается в том, что встроенные устройства используют корневую файловую систему только для чтения (для краткости ro-rootfs).
ro-rootfs - это то, почему встраиваемые системы часто не нуждаются в fsck.
Ro-rootfs предлагают множество преимуществ, которые менее очевидны, чем неубиваемость. Одно из них заключается в том, что вредоносные программы не могут писать в /usr или /lib, как и ни один процесс Linux. Другое заключается в том, что неизменяемая файловая система в значительной степени имеет решающее значение для полевой поддержки удаленных устройств, поскольку вспомогательный персонал обладает локальными системами, которые номинально идентичны системам на местах. Возможно, самое важное (но также и самое тонкое) преимущество заключается в том, что ro-rootfs заставляет разработчиков решать на этапе разработки проекта, какие системные объекты будут неизменными. Работа с ro-rootfs часто может быть неудобной или даже болезненной, как это часто бывает с константами в языках программирования, но преимущества легко окупают дополнительные издержки.
Создание rootfs только для чтения требует дополнительных усилий для разработчиков встраиваемых систем, и именно здесь на помощь приходит VFS. Linux требует, чтобы файлы в /var были доступны для записи, и, кроме того, многие популярные приложения, которые запускаются встраиваемыми системами, будут пытаться создать конфигурационные файлы в $HOME. Одно из решений для конфигурационных файлов в домашнем каталоге, как правило, состоит в том, чтобы сгенерировать их предварительно и встроить в rootfs. Для /var один из подходов заключается в монтировании его в отдельный доступный для записи раздел, а / - только для чтения. Использование монтирования с привязкой и наложением (bind and overlay mounts) является еще одной популярной альтернативой.
Монтирования с привязкой и наложением, и их использование в контейнерах
Запуск man mount - лучшее место для изучения монтирования с привязкой и наложением, которое позволяет разработчикам встроенных систем и системным администраторам создавать файловую систему в одном месте, а затем предоставлять ее приложениям в другом. Для встроенных систем это означает, что можно сохранять файлы в /var на неперезаписываемом флэш-устройстве, но накладывать или привязывать-монтировать путь в tmpfs на путь /var при загрузке, чтобы приложения могли просматривать их у себя. При следующем включении изменения в /var исчезнут. Оверлейные монтирования обеспечивают объединение между tmpfs и базовой файловой системой и позволяют вносить видимые изменения в существующий файл в ro-rootfs, в то время как монтирования с привязкой делает так, чтобы новые пустые каталоги tmpfs отображались как доступные для записи в путях ro-rootfs. Хотя overlayfs является подходящим типом файловой системы, монтирование с привязкой осуществляется с помощью средств пространства имен VFS.
Основываясь на описании оверлеев и связываний, никто не удивится, что контейнеры Linux активно их используют. Давайте посмотрим, что происходит, когда мы используем systemd-nspawn для запуска контейнера, запустив утилиту bcc mountsnoop:

Вызов system-nspawn запускает контейнер во время работы mountsnoop.py.
И посмотрим, что случилось:
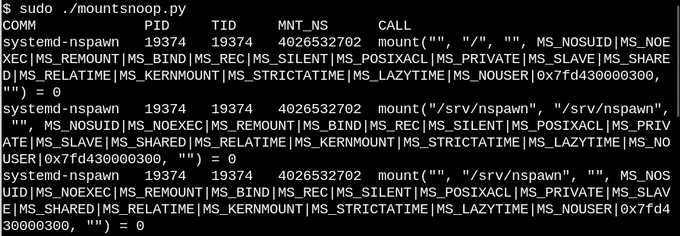
Запуск mountsnoop во время «загрузки» контейнера показывает, что среда выполнения контейнера сильно зависит от привязки монтирования (отображается только начало длинного вывода).
Здесь systemd-nspawn предоставляет выбранные файлы в procfs и sysfs хоста контейнеру по путям в его rootfs. Помимо флага MS_BIND, который устанавливает привязку-монтирование, некоторые другие флаги, которые вызывает системный вызов mount, определяют взаимосвязь между изменениями в пространстве имен хоста и в контейнере. Например, bind-mount может либо распространять изменения в /proc и /sys на контейнер, либо скрывать их, в зависимости от вызова.
Заключение
Понимание внутренних возможностей Linux может показаться невыполнимой задачей, поскольку само ядро содержит гигантский объем кода, даже оставляя в стороне приложения пользовательского пространства Linux и интерфейс системных вызовов в библиотеках C, таких как glibc. Один из способов добиться прогресса - это прочитать исходный код одной подсистемы ядра с акцентом на понимание системных вызовов и заголовков, обращенных к пользовательскому пространству, а также основных внутренних интерфейсов ядра, примером которых является таблица file_operations. Файловые операции - это то, что заставляет работать принцип "все - это файл", поэтому особенно полезно получить управление ими. Исходные файлы ядра C в каталоге / верхнего уровня представляют собой реализацию виртуальных файловых систем, которые представляют собой слой, обеспечивающий широкую и относительно прямую совместимость популярных файловых систем и устройств хранения. Монтирование с привязкой и наложением через пространства имен Linux - это магия VFS, которая делает возможными контейнеры и корневые файловые системы только для чтения. В сочетании с изучением исходного кода, набор утилит eBPF и его интерфейс bcc делают исследование ядра более простым, чем когда-либо прежде.