





Библиотека сайта rus-linux.net
Регулярные выражения: сократите объем и увеличьте продуктивность своей работы
Оригинал: Work smarter with regular expressions
Автор: Marco Fioretti
Дата публикации: 30 октября 2015 г.
Перевод: А.Панин
Дата перевода: 19 января 2016 г.
Сохраните свое время и озадачьте друзей, воспользовавшись одним из наиболее мощных инструментов, доступных пользователям Linux - магическими регулярными выражениями.
Для чего это нужно?
- Вы сможете обрабатывать наборы данных любых типов без необходимости разработки сложного низкоуровневого программного обеспечения.
- Вы всегда сможете находить нужные вам файлы по их именам или содержимому.
- Вы сможете каталогизировать и установить тэги для всех типов документов, начиная от фотографий и заканчивая офисными отчетами.
Регулярное выражение (regular expression или сокращенно regex) является типом текстовой формулы, которая описывает структуру (или "шаблон") определенного фрагмента текста. Регулярные выражения передаются в качестве входных данных специальным программным компонентам, называемым движками регулярных выражений (regex engines), с целью поиска удовлетворяющих им строк в процессе обработки строк из одного или нескольких текстовых файлов или потоков данных. Движки регулярных выражений являются встроенными или встраиваемыми библиотеками, которые могут использоваться в программах написанных с использованием практически любого актуального на сегодняшний день языка программирования.
Начинающие пользователи чаще всего относятся к регулярным выражениям как к бреду, написанному кем-то не совсем трезвым в полной темноте. Исходя из этого, для начала следует дать пояснения относительно того, почему вообще стоит использовать их. И эти пояснения будут достаточно простыми: даже в том случае, если вы не являетесь программистом, регулярные выражения могут значительно облегчить вашу жизнь при возникновении необходимости в генерации или обработке больших объемов текстовых данных. Ниже будут рассмотрены примеры, которые наверняка убедят вас в том, что вы уже сталкиваетесь с подобной необходимостью или обязательно столкнетесь с ней в ближайшем будущем. Во всех примерах рассмотрены реальные ситуации, возникающие при работе с настольными системами и никоим образом не связанные с программированием.
Примеры использования регулярных выражений
Утилита exiftool и другие утилиты из пакета ImageMagick могут использовать геотэги, осуществлять кадрирование, изменение размера, переименование и каталогизацию всех ваших изображений в течение нескольких секунд в том случае, если вы передадите им корректные, понятные и гибкие инструкции. А наиболее эффективный способ передачи этих инструкций как раз связан с их генерацией на основе регулярных выражений.
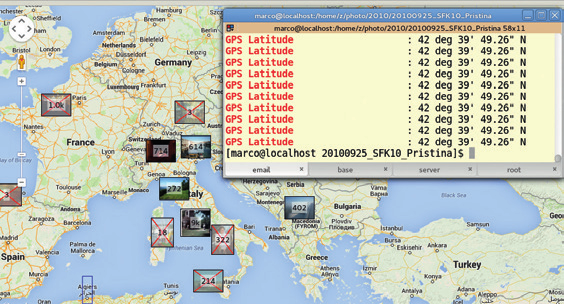
В качестве фона используется открытое в приложении Digikam изображение карты, на котором выведены миниатюры фотографий, сгруппированные в соответствии с местами, где они были сделаны. Для добавления геотэгов в изображения мы создали список городов с координатами и использовали утилиту find с регулярным выражением.
Это же утверждение справедливо и для процесса генерации отчетов о состоянии домашнего и мелкого бизнеса или любых других процессов, связанных с анализом данных. Инструменты, такие, как Gnuplot, могут создавать бесчисленное количество графиков, но извлечение лишь необходимых вам данных из 50000-строчной электронной таблицы будет достаточно сложной задачей без регулярных выражений.
Все приведенные выше утверждения также относятся и к дампам баз данных и архивам страниц веб-сайтов, которые по своей сути являются большими объемами текстовых данных. Быстрые сценарии на основе регулярных выражений позволяют переформатировать или обновить подобные коллекции документов и данных гораздо быстрее, чем в случае использования классических инструментов. Наконец, не стоит забывать об офисных документах: файлы формата OpenDocument, содержащие текстовые документы, электронные таблицы и презентации по своей сути являются всего лишь помещенными в архив формата zip текстовыми файлами, позволяющими осуществлять поиск данных, их анализ и обновление в случае использования регулярных выражений.
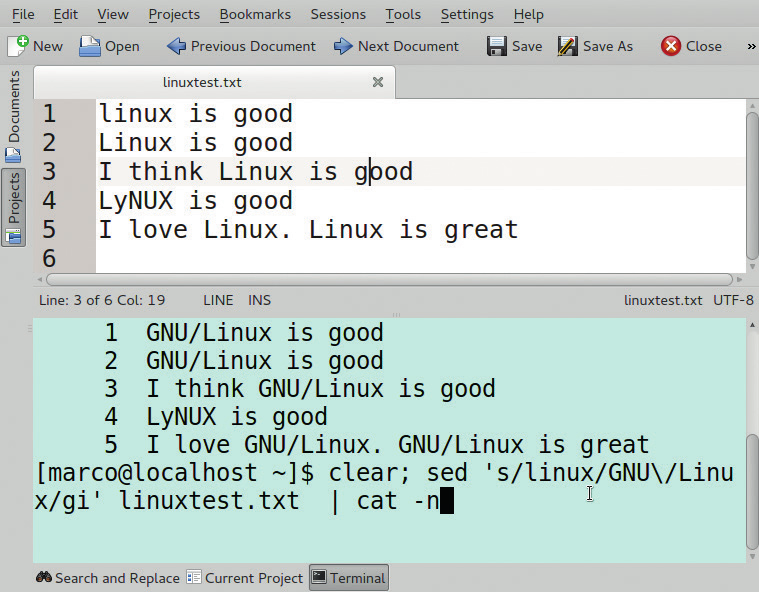
Отличная методика практического изучения регулярных выражений заключается в сохранении нескольких форм одной и той же строки в текстовом файле с последующим применением регулярного выражения к этому файлу для выявления совпадений.
Целью данного руководства является предоставление читателю достаточной информации о регулярных выражениях для создания простых регулярных выражений, а также адаптации многих более сложных регулярных выражений, которые могут быть найдены в сети, для собственных нужд. Мы надеемся, что вы почерпнете из данного руководства достаточное количество отличных идей, а также узнаете об инструментах, которые необходимы для их реализации. Мы продемонстрируем вам методику описания (и поиска) данных с помощью регулярных выражений; вы узнаете о том, где, как много раз и каким образом движок регулярных выражений может осуществлять поиск описанного вами фрагмента текста; наконец, мы обсудим условия, в которых регулярные выражения смогут помочь вам.
Так как регулярные выражения могут использоваться при работе практически с любым языком программирования, существует множество диалектов регулярных выражений. Описанные в данной статье принципы применимы к каждому из диалектов, но при этом не стоит удивляться дополнительному описанию особенностей некоторых из диалектов. Другой важной особенностью, о которой стоит помнить, является значение термина "символ". В случае английского алфавита и всех других алфавитов, символы из которых умещаются в таблицу ASCII, каждый из символов кодируется с помощью единственного байта, то есть восьми бит. Например, битовая последовательность 01011000 соответствует заглавной букве "X". В случае не буквенных символов и в общем случае всех символов, не входящих в таблицу ASCII, допустимо использование более одного байта на символ. При адаптации регулярного выражения к работе с мультибайтовыми символами могут потребоваться его дополнительные модификации, к которым также следует быть готовым.
Во-первых, о поиске совпадений
Процесс работы регулярных выражений или точнее движков регулярных выражений состоит из двух фаз. Во-первых, они ищут сами строки, совпадающие с описанным в рамках регулярного выражения шаблоном, в переданном тексте. Вторая фаза, описанная более подробно в одном из следующих разделов данного руководства, состоит в какой-либо обработке данного текста. Шаблоны могут включать как текстовые фрагменты, так и специальные символы, которые расширяют область их действия. Кроме того, они практически всегда разделяются с помощью слешей, зависят от регистра и работают с одной строкой переданного текста в каждый из моментов времени. Значение данного шаблона
/linux/
является следующим: "необходимо искать все строки, которые содержат заданные символы в нижнем регистре: l, i, n, u и x именно в данной последовательности, один за другим, в любой позиции в строке". Следовательно, данное регулярное выражение будет выполняться лишь для двух первых примеров строк из следующего списка:
- I love linux.
- linux is great.
- How great is Linux?
- I just misspelled lynux.
- I did it again: li nux.
Если в одной строке найдено более одного совпадения с шаблоном, движок регулярных выражений по умолчанию будет возвращать позицию самого первого совпадения и, соответственно, самую длинную строку. Более подробно об этом будет сказано далее.
Якоря
Совпадения, аналогичные тем, что были продемонстрированы в предыдущем разделе, будут обнаруживаться вне зависимости от расположения искомой последовательности в строке переданного текста. Вам потребуются дополнительные метасимволы (специальные символы), называемые якорями для того, чтобы сообщить движку регулярных выражений о том, что вам интересны лишь совпадения ,которые начинаются или заканчиваются в четко заданных позициях. Двумя наиболее часто используемыми якорями являются ^ и $ (см. Таблицу 1).
По умолчанию два соответствующих метасимвола относятся к строкам. При работе с текстом с множеством строк символы ^ и $ будут соответствовать совпадениям в начале и в конце каждой из строк. Для поиска совпадений лишь в начале и в конце всего многострочного текста следует использовать якоря \A и \Z соответственно.
Другим якорем, о котором следует знать, является якорь \b, который соответствует "границам слов": при использовании регулярных выражений \bk и k\b будет осуществляться поиск строк с словами, начинающимися и заканчивающимися буквой "k" соответственно (в регулярных выражениях под "словом" понимают любую непрерывную последовательность из букв, цифр, символов подчеркивания, символов тире и никаких других символов).
Классы символов
Вы можете сделать свое регулярное выражение более компактным и читаемым, используя стандартные или создавая свои собственные классы символов. Наиболее часто используемыми стандартными классами символов являются:
-
\d- соответствует одной цифре (0...9). -
\s- соответствует одному "пробелу", в качестве которого может выступать как сам символ пробела, так и символы табуляции, перехода на новую строку, и.т.д. -
\w- соответствует одному "символу слова", а именно, одной из букв, цифр, символу подчеркивания или символу тире. -
. (точка)- соответствует любому символу за исключением символа перехода на новую строку (если вы хотите явно указать на символ точки, вам придется экранировать этот символ с помощью слэша следующим образом:\.).
Версии трех рассмотренным идентификаторов в верхнем регистре противоположны рассмотренным классам символов: \D означает "любые символы кроме одной цифры", \S - "любые символы кроме одного пробела" и так далее.
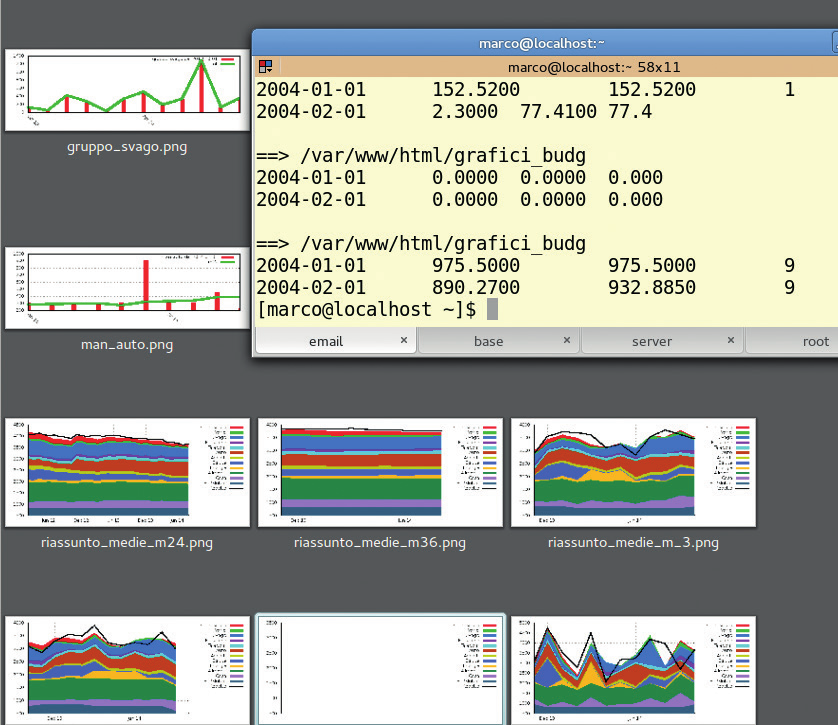
В данном случае мы создали сотни различных графиков в автоматическом режиме средствами утилиты Gnuplot после извлечения соответствующих наборов данных с помощью регулярных выражений из одного файла формата CSV большого объема. Учтите, что аналогичная операция не может осуществляться средствами систем управления базами данных, так как регулярные выражения значительно превосходят их по гибкости.
Если этих классов символов не достаточно, вы можете создать свои собственные классы с помощью символов квадратных скобок, используя в соответствии с необходимостью как обычные символы, так и метасимволы и помня о том, что расположенный в начале описания класса знак вставки приводит к отрицательному значению всего класса:
-
Класс
[aqF\d]будет соответствовать одной букве a или одной букве q или одной заглавной букве F или одной цифре. -
Класс
[^rtw]будет соответствовать любому символу, кроме r, t и w.
Диапазоны соответствующих символов могут быть сокращены с помощью символа тире. Для поиска любой из 10 первых строчных букв английского алфавита вы можете воспользоваться следующим классом символов: /[a-j]/.
Следует помнить и об основной западне, которая заключается в том, что отрицательное значение класса не обязательно означает то, что кажется на первый взгляд. Например, данное регулярное выражение:
/boar[^d]/
не позволит обнаружить строку "boar" в том случае, если она располагается в конце текста! Фактически, данное регулярное выражение означает "необходимо найти последовательность символов b, o, a, r, после которой должен располагаться как минимум один буквенный символ, причем этим символом не может быть символ d"!
Совет: попытайтесь вспомнить все решенные вами задачи, связанные с обработкой текстовых данных большого объема. Подходящих под данное описание задач должно быть на удивление много и, следовательно, есть смысл применять для их решения регулярные выражения.
Модификаторы
Одним из самых важных классов специальных символов регулярных выражений является класс модификаторов. В него входят символы, которые размещаются за пределами самих регулярных выражений и позволяют изменить механизм поиска соответствий. Существует большое количество модификаторов, специфичных для каждого из используемых языков программирования, причем они не работают аналогичным образом в различных языках программирования, поэтому мы рассмотрим лишь некоторые из них для демонстрации концепции.
В случае добавления модификатора i после регулярного выражения поиск соответствий будет осуществляться без учета регистра. Модификатор g позволяет осуществлять "глобальный" поиск соответствий, заключающийся в поиске всех соответствий в переданном тексте, а не первого из них. Модификатор e, напротив, сообщает движку регулярных выражений о необходимости обработки правой части регулярного выражения (которая будет описана во второй части данного руководства) таким же образом, как и в случае использования языка программирования.
Наконец, модификаторы m и s позволяют активировать режимы обработки множества строк и одной строки соответственно: в первом режиме переданный текст рассматривается как набор множества строк, причем якоря ^ и $ соответствуют началу и концу любой из этих строк. Модификатор s работает противоположным образом. Вы можете использовать и по нескольку модификаторов в рамках одного и того же регулярного выражения: к примеру, для поиска всех подстрок "linux" в строке вне зависимости от регистра вы можете использовать регулярное выражение /linux/gi.
Совет: желаете выяснить, какой из вариантов одного и того же регулярного выражения является самым быстрым? Вы можете воспользоваться простым, но не самым элегантным решением: добавьте одно длинное совпадающее с регулярным выражением предложение в пустой файл и создайте множество копий этого файла (десять тысяч или больше), после чего запустите сценарий с регулярным выражением с помощью утилиты time.
Жадные, ленивые регулярные выражения и поиск с возвратом
По умолчанию регулярные выражения являются "жадными" (greedy). Это означает всего лишь то, что на основе их всегда осуществляется поиск наиболее длинной совпадающей с шаблоном строки. В качестве простого, но понятного примера можно рассмотреть ситуацию, в которой необходимо найти все строки URL на какой-либо странице HTML с помощью следующего регулярного выражения:
/href=.*>/
Как вы думаете, в результате применения данного регулярного выражения по отношению к строке
<a href="http://www.linuxvoice.com">Linux Voice</a> is <b>great</b>
выделенная полужирным шрифтом часть строки не будет присутствовать в результирующей строке и мы получим лишь строку URL с кавычками? Правильный ответ "нет" и это объясняется тем, что движки регулярных выражений по умолчанию рассматривают все регулярные выражения как "жадные". Аналогичное приведенному выше регулярное выражение позволит включить в состав результирующей строки все символы до конечного символа "b", не исключая его. Ведь оно сообщает движку регулярных выражений о том, что стоит искать соответствие со столькими символами, со сколькими это возможно вне зависимости от этих символов (это обозначается с помощью точки и звездочки) до того момента, пока не встретится символ ">". Именно по этой причине данное регулярное выражение не остановится в конце строки URL. Для того, чтобы получить в качестве соответствия лишь строку "http://www.linuxvoice.com", нам придется использовать следующее регулярное выражение:
/href=[^>]*>/
Это корректное описание строки URL в кавычках и ничего более: оно позволяет добавить в результирующую строку столько символов, сколько возможно (обозначается с помощью звездочки), расположенных между подстрокой "href=" и символом ">" в том случае, если сами эти символы отличны от символа ">"!
Существуют ситуации в которых отрицание классов символов не позволит получить корректный результат. В таких случаях вы также можете использовать "ленивые" (lazy) регулярные выражения, при работе с которыми поиск соответствий заканчивается после нахождения самого короткого, а не длинного соответствия. Просто используйте знак вопроса:
/href=.*?>/
Это регулярное выражение принудит движок регулярных выражений остановиться на первом символе ">", который, в отличие от первого случая находится сразу же после строки URL в кавычках. На практике вы должны всегда пытаться использовать первую стратегию - поиск совпадений на основе регулярного выражения с отрицанием классов символов.
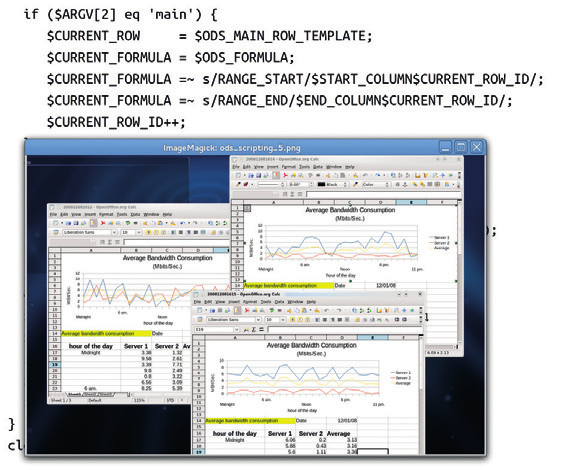
Аналогичная рассмотренной выше техника может быть использована по отношению ко всем типам офисных документов формата ODF. Для тестирования вы можете создать электронную таблицу и заполнить ее произвольными числами или строками, формулами и графиками.
Причина данного предпочтения заключается в том, что регулярные выражения с описанной структурой позволяют движкам регулярных выражений лишь единожды обрабатывать строки в одном и том же направлении слева направо. Выражение
/href=[^>]*>/
позволяет "прекращать поиск совпадений сразу же после обнаружения символа ">"". А в случае использования вместо него выражения
/href=.*?>/
движку регулярных выражений придется осуществлять поиск совпадений до достижения конца текста и быть жадным...до нахождения первого совпадения, после чего он должен будет осуществляться поиск более короткого совпадения в обратном направлении и его выбор в качестве результата в случае нахождения. Данное поведение называется поиском с возвратом (backtracking) и является очень мощным и в большинстве случаев единственным механизмом для обработки некоторых сложных регулярных выражений. Однако, после непродолжительного рассмотрения данного механизма несложно заметить, что для поиска корректного совпадения в случае его использования потребуется гораздо больше времени.
Совет: регулярные выражения также отлично подходят для обработки большого количества файлов без изменения их содержимого! Отличными инструментами для этой цели с поддержкой регулярных выражений являются утилиты egrep, sed и awk. Комбинируйте их с утилитой find для сортировки и каталогизации файлов любым удобным для вас способом.
Обратные ссылки
В последнем разделе теоретической информации относительно синтаксиса регулярных выражений необходимо рассмотреть механизм обратных ссылок. Это механизм, который вы можете использовать для того, чтобы сообщить движку регулярных выражений о о том, что следует запомнить найденные совпадения для их последующего использования. Механизм обратных ссылок может использоваться по нескольку раз в рамках одного регулярного выражения с помощью круглых скобок:
/I use Linux, my name is (\w+) and my favourite distro is (.+)$/
Эти две пары круглых скобок сообщают движку регулярных выражений о том, что необходимо сохранить имя пользователя в первой используемой механизмом обратных ссылок специальной внутренней переменной, а название дистрибутива - во второй. В зависимости от языка программирования, эти переменные могут называться $1, $2 или \1, \2 или аналогичным образом, но в любом случае, они имеют одинаковое назначение. К примеру, в языке программирования Perl используется долларовая нотация, поэтому при применении приведенного выше регулярного выражения для извлечения простых строк переменные будут называться $1 и $2 (см. Таблицу 4).

На переднем плане вы можете увидеть стандартную презентацию ODF. Фоном является сценарий с некоторым из регулярных выражений, которые использовались для ее создания и заполнения пустого шаблона данными из текстового файла.
Теперь вы можете расслабиться: с помощью простых, но весьма реалистичных примеров мы описали достаточно возможностей регулярных выражений, для того чтобы сделать очевидной необходимость их изучения и использования. В реальности любая программа, использующая движок регулярных выражений, может выполнить три операции сразу же после того, как движок обнаружит соответствие: во-первых, но может выполнить какое-либо предварительно описанное действие, во-вторых - передать результат операции поиска соответствия в следующую инструкцию для дополнительной обработки и в третьих - немедленно заменить соответствие на какую-либо другую строку, которая может быть как неизменной строкой, так и строкой, формируемой в процессе исполнения программы. Первая операция выполняется такими утилитами с интерфейсом командной строки, как grep и egrep. Если вы запустите egrep следующим образом:
#> egrep ^(Debian|Centos) install-list.txt
у нее не останется какого-либо выбора, кроме вывода с помощью терминала всех строк из файла install-list.txt, которые начинаются (вы ведь обратили внимание на символ "^"?) либо со слова Debian, либо со слова CentOS. Этот фрагмент кода на языке Perl демонстрирует операцию второго типа:
$_ =~ m/www\.(.*)\.com$/; print " .com domain name found: .$1\n" if ($1);
В языке программирования Perl переменная $_ содержит текущую строку текстового ввода, а операторы =~m позволяют "проверить, соответствует ли строка переданному регулярному выражению".
При обнаружении соответствия, оно помещается в специальную переменную $1 благодаря наличию двойных скобок. Вторая строка предназначена для вывода значения этой переменной, но только в том случае, если это значение установлено. Таким образом, данный код позволяет вывести все имена сетевых доменов формата www.ИМЯ_САЙТА.com из текстового потока.
Наконец, следует рассмотреть механизм подстановки значений. Что делать, если ваш начальник даст вам задание, заключающееся в изменении формата списка клиентов компании? Это не будет проблемой в том случае, если вы умеете работать с регулярными выражениями. Для простоты давайте предположим, что вы должны всего лишь поменять порядок следования имен и фамилий клиентов в строках списка таким образом, чтобы оригинальная строка
First Name: Winston Last Name: Churchill
превратилась в строку
Last Name: Churchill First Name: Winston
Регулярные выражения, предназначенные для подстановки текста, начинаются с модификатора s, после которого следует текстовый шаблон для замены в оригинальной строке. Вы можете сгенерировать новый список имен требуемого формата с помощью программы sed:
#> cat namelist.txt | sed -E s/First Name: (.*)Last Name: (.*)/Last Name: \2\t\tFirst Name: \1/ > newnamelist.txt
Обработка офисных документов
Документы формата OpenDocument являются по своей сути архивами формата zip, содержащими по нескольку файлов. Само содержимое документа находится в файле с именем content.xml, расположенном в этом архиве. К примеру, каждая строка электронной таблицы представлена с помощью длинной строки, аналогичной приведенной ниже (она была значительно сокращена для улучшения читаемости!):
<table:table-row><table:table-cell office:value-type="string"><text:p>ЧИСЛО</text:p></table:table-cell>.....</table:table-row>
Догадались, что я имею в виду? Как только вы создадите шаблон электронной таблицы с заданными именами определенных ячеек, создание необходимого количества копий этого шаблона с различными значениями в этих ячейках не будет представлять каких-либо сложностей в случае использования аналогичных регулярных выражений:
s/НАЗВАНИЕ_ЯЧЕЙКИ/$ТЕКУЩЕЕ_ЗНАЧЕНИЕ/
где $ТЕКУЩЕЕ_ЗНАЧЕНИЕ может быть любым числом, взятым из базы данных, рассчитанным или переданным пользователем. Мощный механизм, не так ли?
Что еще можно почитать?
Полная подборка сценариев для обработки документов формата ODF, использованных автором для генерации документов и электронных таблиц, показанных на иллюстрациях, вместе с некоторыми другими аналогичными сценариями, доступен в сети по адресу http://freesoftware.zona-m.net/tag/odf-scripting. Сценарии для работы с Gnuplot расположены на страницах этого же блога, но в другом разделе: http://freesoftware.zona-m.net/tag/gnuplot. Довольно подробное онлайн-руководство по использованию регулярных выражений, которое в то же время является достаточно обобщенным для использования при работе с различными языками программирования, расположено на веб-сайте www.regular-expressions.info. Наконец, если вам очень понравился данный инструмент, вам просто необходимо ознакомиться с наиболее полным руководством:отличной книгой от Jeffrey Friedl под названием "Mastering Regular Expressions, 3rd Edition, 2006", изданной O Reilly Media. Помимо невообразимо огромного количества информации о внутреннем устройстве и принципе работы движков регулярных выражений, а также процессе их разработки, данная книга содержит большой объем разнообразной дополнительной информации. По нашему мнению, лишь несколько книг, посвященных программированию, могут превосходить данную книгу по продуктивности и креативности, в то же время корректно описывая приемы работы с отличным программным обеспечением.
Таблица 1
| Символ | Пример | Совпадает? |
|---|---|---|
| Linux is great | ||
| ^ (начало строки) | /*Linux/ | Да |
| $ (конец строки) | /Linux$/ | Нет |
Якори и сокращения для классов символов являются всего лишь двумя специальными символами, которые могут использоваться для описания текстовых шаблонов с произвольной структурой. В данной таблице приведены практически все метасимволы, о которых вам следует знать.
Таблица 2. Дополнительные метасимволы
| Символ | Значение |
|---|---|
| | | Варианты: /(cat|dog)/ обозначает "соответствие cat ИЛИ dog" (не забывайте о круглых скобках!) |
| \ | Преобразует следующий специальный символ в литерал (т.е., вы можете использовать \| если вам нужен символ программного канала) |
| \n | Переход на новую строку |
| \t | Табуляция |
Нередко при создании регулярного выражения необходимо описать дополнительные или повторяющиеся символы, к примеру, для поиска и исправления опечаток. Для этого следует использовать приведенные в таблице метасимволы и конструкции, указывающие количество повторений.
Таблица 3. Указатели количества повторений
| Указатель | Совпадение | Пример | Совпадает со строками |
|---|---|---|---|
| ? | 0 или 1 раз | /liy?nux/ | linux, liynux |
| * | 0 или много раз | /li.*nux/ | linux, liynux, liiinux, liabc1234nux... |
| {m} | Ровно m раз | /liy{5}nux/ | liyyyyynux |
| {m,} | Как минимум m раз | /liy{6}nux/ | Предлагаем читателям самостоятельно привести пример |
| {m, M} | От m до M раз | /liy{2,4}nux/ | liyynux, liyyynux, liyyyynux |
Таблица 4
| Строка | Значение переменной $1 | Значение переменной $2 |
|---|---|---|
| I use Linux, my name is Paul and my favourite distro is Debian | Paul | Debian |
| I use Linux, my name is John and my favourite distro is Red Hat | John | Red Hat |