





Библиотека сайта rus-linux.net
Школа ассемблера: условные инструкции, циклы и библиотеки
Оригинал: AsmSchool: Conditions, loops and libraries
Автор: Mike Saunders
Дата публикации: 31 декабря 2015 г.
Перевод: А.Панин
Дата перевода: 15 февраля 2016 г.
Часть 2: Начинаем писать полноценные программы и создаем свою собственную библиотеку полезных подпрограмм.
Для чего это нужно?
- Для понимания принципов работы компиляторов.
- Для понимания инструкций центрального процессора.
- Для оптимизации вашего кода в плане производительности.
Вы прошлом месяце мы сделали первые шаги по пути программиста на языке ассемблера и убедились в том, что это язык не так страшен, как можно предположить. Да, он очень выделяется на фоне высокоуровневых языков программирования и не предоставляет в ваше распоряжение множество полезных типов данных и уровней абстракции, которые по своей сути являются защитой от некорректных приемов при непосредственной работе с памятью. Но при этом нельзя проигнорировать и ту особенность языка ассемблера, благодаря которой он пользуется популярностью - он наиболее близок аппаратному обеспечению и позволяет напрямую взаимодействовать с центральным процессором и компонентами операционной системы без каких-либо дополнительных преград.
В данной статье мы рассмотрим вопросы, связанные с процессом исполнения программы, не оставив в стороне циклы и условные инструкции, для того, чтобы вы имели возможность разрабатывать более мощные программы. Кроме того, мы рассмотрим процесс создания собственных подпрограмм для автоматизации выполнения стандартных задач и формирования библиотеки полезных фрагментов кода, которые вы сможете использовать позднее в других своих программах. А теперь самое время выключить свет, установить тему эмулятора терминала в стиле ретро с зеленым текстом и черным фоном и начать работу над кодом как в старые добрые времена.
Повторное использование кода в формате подпрограмм
Создание модулей кода для повторного использования не представляет каких-либо сложностей в случае работы с языком ассемблера. Вы должны проявлять осторожность, чтобы случайно не перезаписать данные, используемые в какой-либо другой точке программы, но окончательно разобравшись с принципом создания подпрограмм, вы сможете создавать небольшие черные ящики в формате процедур, на разработку каждый из которых придется потратить некоторое количество времени, после чего ее можно будет вызывать по мере необходимости. Например, в программе из статьи месячной давности мы использовали ядро ОС для вывода текста на экран. Если ваша программа часто осуществляет вывод текста на экран, вы можете избежать дополнительной работы (и сократить объем кода программы), вынеся в отдельную подпрограмму вызовы, предназначенные для помещения данных в регистры - как вы наверняка помните, для вывода текста на экран приходится помещать номер соответствующего системного вызова в регистр eax, идентификатор потока стандартного вывода в регистр ebx, значение длины строки в регистр ecx и так далее
Исходя из этого, давайте переместим код, предназначенный для вывода текста на экран, в отдельную подпрограмму, которую мы сможем вызвать в любой момент. Но не стоит торопиться с реализацией! Давайте также немного упростим использование нашей подпрограммы таким образом, чтобы нам больше не требовалось помещать значение длины строки в регистр edx. Ведь наша подпрограмма сможет выполнить эту работу за нас.
В первую очередь следует создать следующий вариант программы из статьи месячной давности и сохранить его в файле с именем test.asm:
section .text global _start _start: mov ecx, mymsg call lib_print_string mov eax, 1 mov ebx, 0 int 80h section .data mymsg db 'Pretty cool, huh?', 10, 0 %include "lib.asm"
Этот код полностью аналогичен коду, приведенному в статье месячной давности, но часть, ответственная за вывод строки на экран, значительно изменена. Вместо заполнения всех необходимых регистров и вызова int80h, мы просто помещаем указатель на строку в регистр ecx, после чего "вызываем" подпрограмму с именем lib_print_string. Этот вызов немного похож на старомодный вызов GOSUB - он передает управление заданной процедуре, которая выполняет всю свою работу, после чего возвращает управление основной программе.
На данном этапе у вас может возникнуть резонный вопрос: "Где же расположена сама подпрограмма lib_print_string?" Что же, пока мы ее не разработали, но в будущем мы разместим ее в файле lib.asm, который является еще одним файлом исходного кода языка ассемблера. В приведенном выше листинге в самом низу вы можете обнаружить строку с инструкцией %include, которая позволяет добавить содержимое файла исходного кода lib.asm в текущий файл исходного кода на этапе ассемблирования. Таким образом, вы можете разместить все часто используемые процедуры в отдельном файле исходного кода lib.asm, не захламляя ими основной файл исходного кода вашей программы.
Еще одной важной деталью является формат записи строки рядом с меткой mystring. На этот раз наряду с символом 10, являющимся символом новой строки, мы также добавляем к строке нулевой символ. Благодаря этому символу обычная строка превращается в "строку с завершающим нулевым символом" - впоследствии мы сможем на уровне кода определить позицию этого нулевого символа и вычислить таким образом длину строки.
Набор функций нашей библиотеки lib.asm будет неуклонно расширяться, а сама библиотека рано или поздно превратится в полезный набор фрагментов кода, предназначенных для выполнения таких операций, как преобразование чисел в строки.
Создание необходимого инструментария
Давайте приступим к реализации процедуры lib_print_string. Ее код будет более длинным и более запутанным, чем код, использованный для вывода текста на экран в программе из статьи месячной давности, из-за чего вы можете задаться вопросом: "А есть ли в этом смысл?". Ну, если вы разрабатываете сложную программу, код которой содержит сотни фрагментов для вывода текста на экран, общий объем ее кода, разумеется, уменьшится в случае использования одной и той же подпрограммы вместо помещения данных в регистры в ручном режиме. Кроме того, как упоминалось ранее, данная подпрограмма также сможет самостоятельно вычислять длины передаваемых строк.
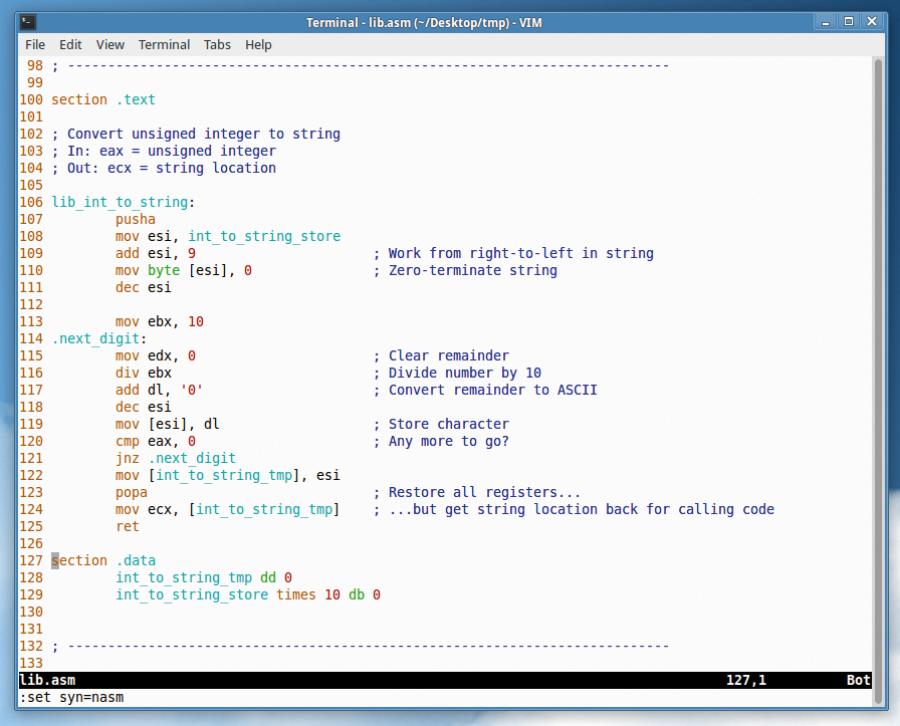
Разместите следующий код в файле с именем lib.asm (также вы можете загрузить данный файл с реализациями дополнительных подпрограмм, которые могут оказаться полезными, по адресу www.linuxvoice.com/code/lv013/lib.asm):
section .text ; Вывод строки на экран ; Входные данные: ecx = указатель на начало строки ; Выходные данные: Нет lib_print_string: pusha ; Сохранение состояния всех регистров mov eax, ecx ; Сохранение значения регистра ecx для последующего использования mov edx, 0 ; Счетчик символов .loop: cmp byte [eax], 0 ; Равно ли значение байта нулю? je .done ; Переход к метке в случае успешной проверки inc edx ; Увеличение значения счетчика символов inc eax ; Сдвиг вперед указателя на начало строки jmp .loop ; Возврат к метке для выполнения следующей итерации .done: mov eax, 4 ; sys_write mov ebx, 1 ; stdout int 80h ; Системный вызов на уровне ядра ОС popa ; Восстановление состояния всех регистров ret ; Возврат управления основной программе
В приведенном выше коде выполняется множество различных операций, но так как в нем также представлены такие новые концепции, как циклы и условные инструкции, мы не будем торопиться с его рассмотрением. Для начала важно уяснить одну простую вещь: символы точки с запятой используются для отделения комментариев от кода, то есть, любые последовательности символов, находящиеся справа от них (до окончаний соответствующих строк), будут игнорироваться ассемблером NASM. Использование подробных комментариев при работе с языком ассемблера является хорошим тоном, ведь в противном случае при рассмотрении кода по прошествии нескольких месяцев можно попросту растеряться.
Мы начинаем реализацию подпрограммы с передачи ассемблеру NASM указания на то, что весь следующий код должен размещаться в секции "text" результирующего бинарного файла - ведь это исполняемый код, а не данные. После этой строки размещаются три строки комментариев, в которых размещается информация о том, что делает наша подпрограмма, какие регистры она использует и состояние каких регистров она изменяет перед завершением работы. В данном случае нашей подпрограмме lib_print_string требуется лишь указатель на начало строки в регистре ecx, при этом она не изменяет состояния регистров - в регистрах будут храниться те же значения после возврата управления основной программе.
Другие регистры
Помимо четырех основных регистров общего назначения eax, ebx, ecx и edx существуют четыре дополнительных регистра, о которых нужно знать. Два из них используются главным образом для обработки строк: это регистры esi и edi. Первый регистр может использоваться в качестве "указателя на позицию в исходной строке", то есть, содержать значение позиции в строке, с которой должно осуществляться чтение, в то время как второй - в качестве "указателя на позицию в результирующей строке", создаваемой приложением. Рассмотрите следующий код:
mov esi, mystring mov edi, blankstring lodsb stosb
Предположим, что в данном случае mystring указывает на строку "Hello", а blankstring - на последовательность нулевых байт. Инструкция lodsb извлекает байт с позиции в строке, соответствующей значению в регистре esi, сохраняя его в регистре eax (точнее, в части al этого регистра размером в байт), после чего инструкция stosb перемещает байт из части этого регистра al в позицию строки, соответствующую значению в регистре edi. Таким образом осуществляется копирование символа "H" из одной строки в другую. При этом стоит обратить внимание на один важный аспект! Для упрощения обработки строк инструкция lodsb каждый раз автоматически передвигает указатель в регистре esi на байт (таким образом, указатель передвигается на следующий символ), причем инструкция stosb делает то же самое с регистром edi.
В это время регистр esp хранит указатель на текущую позицию в стеке. Она изменяется при добавлении данных в стек и извлечении их из него. Регистр eip является регистром для хранения "указателя на инструкцию" - он просто хранит указание на текущую инструкцию в коде. Его значение изменяется при исполнении таких инструкций, как jmp или call. Кроме того, имеется регистр EFLAGS, также известный, как регистр состояния, который хранит значение, биты которого указывают на результаты исполнения инструкций (например, был ли результат нулевым, произошло ли переполнение). Данный регистр используется при работе с множеством инструкций для реализации условных переходов.

В нескольких следующих статьях мы будем готовиться к запуску нашего кода на реальном устройстве без ОС!
Что такое шестнадцатеричная система?
Мы используем десятичную систему счисления (с основанием 10), так как у нас десять пальцев на руках и нам удобнее так считать. Но она не имеет особого смысла для центральных процессоров, поэтому в низкоуровневом программировании вы всегда будете сталкиваться с системой счисления с основанием 16 - она называется шестнадцатеричной. Если вы никогда ранее не использовали эту систему счисления, вам потребуется некоторое время для адаптации к ней.
Как и в десятичной системе счисления, в шестнадцатеричной системе используются цифры от 0 до 9. Но десятичное значение 10 соответствует шестнадцатеричному значению A, после которого следуют другие обозначаемые буквами значения вплоть до значения F (соответствующего десятичному значению 15). После него следует шестнадцатеричное значение 10, которое соответствует десятичному значению 16. Вы уже начали понимать принцип? Данная таблица должна помочь вам.
| Десятичная система | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | ... | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Шестнадцатеричная система | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | 10 | 11 | 12 | 13 | ... |
После шестнадцатеричного значения 19 следует значение 1A, после значения FF - значение 100 и так далее
Циклы и условные инструкции
Первой инструкцией из предыдущего блока кода является инструкция "pusha", которая позволяет переместить значения всех регистров в стек. Вы наверняка помните о назначении стека из предыдущей статьи серии: это временное хранилище, в которое вы можете помещать содержимое регистров при необходимости использования этих регистров для обработки каких-либо других значений. Мы помещаем значения из всех регистров в стек в самом начале рассматриваемой подпрограммы, работаем с ними и возвращаем их в регистры (с помощью инструкции popa) непосредственно перед возвратом к основному коду (осуществляемому с помощью инструкции ret). Это означает, что вызывающая подпрограмму программа не должна будет сохранять значения регистров - при ее разработке можно предполагать, что их состояние не изменится в результате исполнения подпрограммы.
Теперь указатель на начало строки размещен в регистре ecx, но нам необходимо сохранить его для последующей обработки. Ведь нам придется осуществить подсчет количества символов в строке, поэтому мы скопируем значение из регистра ecx в регистр eax и будем работать с последним регистром, не затрагивая первый. Мы будем обходить байты строки до того момента, пока не обнаружим нулевой байт (помните о том, что в данном примере мы используем строки, завершающиеся нулевыми символами), подсчитывая их количество для того, чтобы выяснить длину строки. А в качестве счетчика будет использоваться значение в регистре edx. Описанный алгоритм в псевдокоде:
10 Получение значения байта строки 20 Полученное значение является нулевым? 30 Если это так, следует выйти из цикла 40 Если это не так, следует увеличить значение счетчика и перейти к следующему байту строки 50 Переход к строке 10
Наш цикл начинается с метки .loop, причем точка в начале имени метки означает, что метка является локальной. Другими словами, имя данной метки раскрывается до lib_print_string.local. Для чего же нужна именно локальная метка? Ну, благодаря использованию локальной метки мы можем использовать метку с таким же именем .loop в других подпрограммах, что очень удобно, ведь в противном случае вам придется придумывать отличное имя для каждой из меток в коде. Разумеется, вы сможете использовать лишь одну локальную метку .loop для каждой из родительских меток, то есть в рамках каждой из подпрограмм.
Теперь указатель на позицию в строке хранится в регистре eax. В первую очередь нам нужно получить байт из строки следующим образом:
cmp byte [eax], 0
Инструкция cmp позволяет "сравнить одно число или (значение из регистра) с другим числом", причем квадратные скобки в данном случае крайне важны. Они позволяют указать на то, что следует сравнивать с нулем не значение указателя из регистра eax, а значение байта строки, на которое указывает указатель из этого регистра eax. Очевидно, регистр eax будет содержать большие числа, являющиеся адресами байтов строки в памяти, такие, как 2187612. Но нам интересны не эти адреса, а значения байтов, расположенных по этим адресам в памяти и именно поэтому мы используем квадратные скобки. Таким образом, мы сравниваем значение байта строки с нулевым значением. В следующей строке расположена инструкция je .done, которая является инструкцией условного перехода: она расшифровывается следующим образом: "если значения равны, следует перейти к определенной позиции в коде". Существуют и другие инструкции условного перехода, которые могут использоваться после инструкции cmp, такие, как jg (переход к позиции в коде в том случае, если первое знаковое число больше второго), которая работает с знаковыми числами ли ja (переход в позиции в коде, если первое беззнаковое число больше второго), которая работает с беззнаковыми числами. Мы рассмотрим их более подробно в следующем месяце.
Вернемся к коду: в том случае, если байт, находящийся в текущей позиции в строке (на которую указывает значение в регистре eax) является нулевым, то достигнут конец строки, поэтому следует перейти к метке .done. Но если байт не является нулевым, то исполняются инструкции, расположенные до инструкции je. В первую очередь осуществляется увеличение значения в регистре edx, а затем в регистре eax для перемещения указателя на следующий символ строки. После этого осуществляется переход назад к метке .loop и выполняется следующее сравнение.
Делайте больше с меньшими издержками
Мы упоминали ранее о том, что центральные процессоры работают следующим образом: они перемещают числовые значения между памятью и регистрами, используют их в расчетах и осуществляют переходы в различные точки кода в соответствии с результатами этих расчетов. Язык ассемблера на самом деле очень прост в некоторых своих аспектах - при разработке приложений большая часть времени обычно тратится на реализацию сложных функций на основе относительно малого набора инструкций. В качестве примера можно привести классический космический симулятор Elite для 8-битных процессоров: изначально он разрабатывался для центрального процессора, поддерживающего всего 56 инструкций (5602). Даже с помощью такого ограниченного набора инструкций вполне возможно создать полноценный трехмерный игровой движок и увлекательную игру на его основе.
В любом случае, достигнув метки .done в нашем коде, мы будем готовы обратиться к ядру ОС. Нам придется поместить значение 4 в регистр eax для того, чтобы указать на необходимость использования системного вызова sys_write, а также значение 1 в регистр ebx для того, чтобы указать на то, что строка должна быть записана в стандартный поток вывода, а все другие регистры уже заполнены необходимыми данными. Это объясняется тем, что мы не изменяли значение в регистре ecx с момента входа в подпрограмму, а вычисляемое в рамках цикла значение длины строки находилось в регистре edx, поэтому ядро ОС также сможет использовать его. Таким образом, все, что нам нужно сделать теперь - это осуществить вызов int 80h и, как говорится, дело сделано.
После этого мы возвращаем значения регистров из стека таким образом, как было описано ранее, и используем инструкцию ret для возврата к коду вызвавшей подпрограмму программы. В данном случае важно понять следующую особенность языка ассемблера: при "вызове" отдельного фрагмента кода информация о текущей позиции в коде помещается в стек для последующего извлечения. Инструкция ret позволяет извлечь эту информацию из стека и разместить ее в регистре eip (регистр для хранения указателя инструкций), поэтому исполнение продолжается с этой же точки. По этой причине нужно проявлять особую осторожность при работе со стеком: если вы извлечете из него больше данных, чем добавили, вы не позволите получить информацию о точке возврата соответствующей инструкции и ваша программа продолжит исполняться в какой-либо другой точке!
Вы можете собрать программу и осуществить ее связывание с помощью команд, аналогичных тем, что были приведены в статье месячной давности:
nasm -f elf -o test.o test.asm ld -m elf_i386 -o test test.o
После этого вы можете запустить собранную программу с помощью команды ./test. Да, она выводит строку на экран, как и программа из прошлой статьи серии! Но она выполняет гораздо большее количество операций и является отправной точкой для разработки вашей собственной библиотеки полезных подпрограмм.
Теперь вы знаете о том, как повторно выполнять операции в рамках циклов, которые просто необходимы для создания более сложных программ, а также можете выполнять операции в зависимости от содержимого регистра. Кроме того, теперь вы можете создавать свои собственные подпрограммы для выполнения стандартных задач и делать их модульными для того, чтобы не нарушать работу вызывающего кода программы. (По этой причине в случае использования регистров в подпрограмме отличной идеей является использование инструкции pusha в ее начале и popa в конце - таким образом вы сможете гарантировать то, что при возврате к вызывающему коду с помощью инструкции ret состояние регистров никоим образом не изменится).
В следующей статье серии мы рассмотрим аспекты процессов обработки ввода и файлов, которые следует учитывать при написании корректных и функциональных (а также молниеносно быстрых) программ. Таким образом мы еще немного приблизимся к нашей конечной цели, заключающейся в запуске скомпилированного кода на компьютере без загрузки какой-либо операционной системы. До встречи
Математические действия
До текущего момента мы рассматривали операции перемещения чисел между регистрами, но мы также можем выполнять простые математические операциями с значениями регистров. Например, так выполняется операция сложения:
mov eax, 10 mov ebx, 15 add eax, ebx add eax, 7
Помните о том, что в языке ассемблера операнды записываются справа налево (по крайней мере, это утверждение справедливо для синтаксиса ассемблера NASM). Так какое же значение будет содержать регистр eax в итоге? Во-первых, мы помещаем в него значение 10, затем мы помещаем значение 15 в регистр ebx. Мы прибавляем значения из регистра ebx к значению из регистра eax, поэтому последний в результате будет содержать значение 25. После этого мы прибавляем число (7), поэтому результирующее значение равно 32. Для осуществления операции вычитания также могут использоваться как регистры, так и числа:
mov eax, 100 sub eax, 99
В результате регистр eax будет содержать значение 1. Операции умножения и деления осуществляются отличным образом - вы можете обнаружить множество подобных несоответствий при разработке приложений для архитектуры x86 ввиду долгой истории ее развития! Для умножения значений вам в первую очередь придется поместить одно из значений в регистр eax; после этого вы можете осуществить операцию умножения, использовав значение из другого регистра. Например:
mov eax, 10 mov ebx, 5 mul ebx
В результате регистр eax будет содержать значение 50. Операции деления осуществляются аналогичным образом, причем остаток от деления будет сохранен в регистре edx:
mov eax, 10 mov ebx, 4 div ebx
В результате регистр eax будет содержать значение 2 (целая часть от деления 10 на 4), а регистр edx - значение остатка от деления, также равное 2.
Обратите внимание на то, что вы не можете использовать подпрограмму lib_print_string для непосредственного вывода на экран содержимого регистров, так как оно должно быть предварительно преобразовано в текстовый формат ASCII. Данный вопрос выходит за рамки статьи, но вы в любом случае можете воспользоваться ссылкой www.linuxvoice.com/code/lv013/lib.asm для загрузки файла исходного кода, который содержит две дополнительных подпрограммы: lib_int_to_string (которая принимает числовое значение в регистре eax и возвращает указатель на начало строки, являющейся текстовым представлением этого числового значения, с помощью регистра ecx), а также подпрограмму lib_print_registers, которая просто выводит содержимое всех регистров на экран. Поэтому попробуйте выполнить несколько математических операций, после чего используйте инструкцию:
call lib_print_registers
для ознакомления с их результатами.
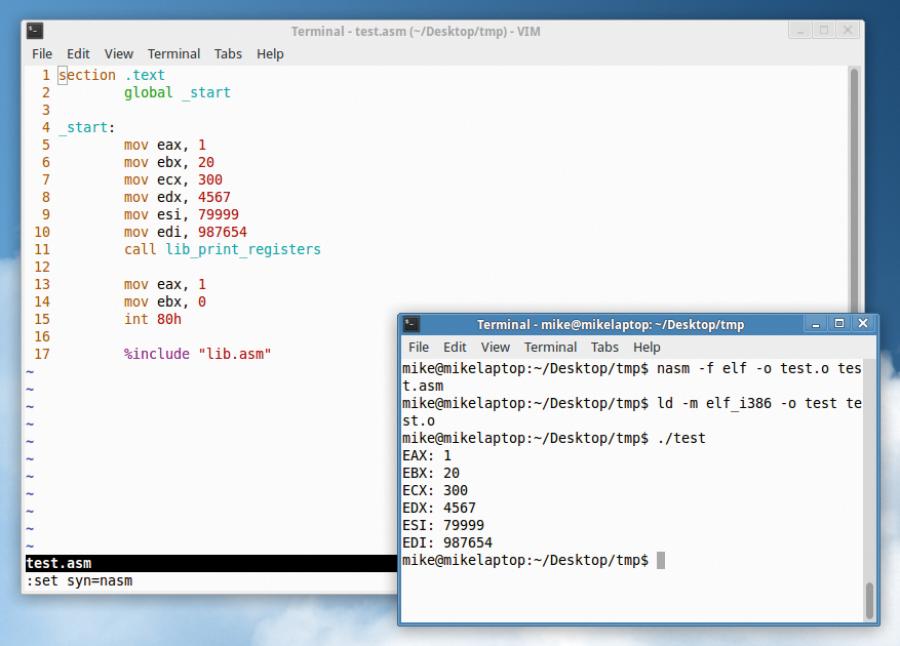
Используйте подпрограмму lib_print_registers из нашей библиотеки lib,asm для быстрого ознакомления с содержимым основных регистров.
Первые центральные процессоры с небольшими наборами инструкций все еще способны на многое - например, оцените игру Elite, запущенную на процессоре 6502.