





Библиотека сайта rus-linux.net
Разбор документов XML со скоростью света
Глава 4 из книги "Производительность приложений с открытым исходным кодом".
Оригинал: Parsing XML at the Speed of Light
Автор: Arseny Kapoulkine
Перевод: А.Панин
Оптимизация строковых преобразований
На чтение и преобразование значений символов в pugixml тратится чрезвычайно много времени. К примеру, давайте рассмотрим случай чтения простых символьных данных (plain-character data - PCDATA); т.е., текста между тэгами XML. Любая соответствующая стандарту реализация системы разбора, как говорилось ранее, должна выполнить операции раскрытия ссылок и нормализации символов завершения строк в процессе обработки данных типа PCDATA.9
A < B.
A < B.
Функция разбора данных PCDATA получает указатель на начальный символ строки данных PCDATA и производит ее обработку путем чтения оставшихся данных с проведением непосредственного преобразования символов и завершением результирующей строки нулевым символом.
Так как функция имеет два логических флага, в нашем распоряжении находятся четыре варианта этой функции. Для предотвращения ресурсоемких проверок в процессе работы приложения мы используем шаблон логических аргументов для этих флагов - таким образом мы компилируем четыре варианта функции с помощью единственного шаблона, после чего в процессе работы приложения производим поиск для получения корректного указателя на функцию перед началом разбора документа. Система разбора вызывает функцию с помощью полученного указателя на функцию.
template <bool opt_eol, bool opt_escape> struct
strconv_pcdata_impl {
static char_t* parse(char_t* s) {
gap g;
while (true) {
while (!PUGI__IS_CHARTYPE(*s, ct_parse_pcdata)) ++s;
if (*s == '<') { // данные PCDATA заканчиваются здесь
*g.flush(s) = 0;
return s + 1;
} else if (opt_eol && *s == '\r') { // 0x0d или пара 0x0d 0x0a
*s++ = '\n'; // замена первого символа на 0x0a
if (*s == '\n') g.push(s, 1);
} else if (opt_escape && *s == '&') {
s = strconv_escape(/s, g);
} else if (*s == 0) {
return s;
} else {
++s;
}
}
}
};
Дополнительная функция получает указатель на подходящую реализацию в зависимости от значений флагов во время работы приложения; т.е., &strconv_pcdata_impl<false, true>::parse.
Одним нестандартным элементом этого кода является экземпляр класса gap. Как было показано ранее, в том случае, если мы выполняем строковые преобразования, результирующая строка становится короче, так как некоторые символы приходится удалять. Существует несколько способов выполнения этой операции.
Одна стратегия (которая не применяется в рамках библиотеки pugixml) заключается в использовании независимых указателей чтения (read) и записи (write), которые должны указывать позицию в одном и том же буфере. В этом случае указатель read используется для отслеживания текущей позиции чтения, а указатель write используется для отслеживания текущей позиции записи. При этом всегда должно выполняться условие write <= read. Любой символ, который становится частью результирующей строки, должен размещаться в позиции указателя записи. Эта техника помогает избежать квадратичных степеней показателей затрат ресурсов на непосредственное удаление символов, но является неэффективной, так как в данном случае нам приходится читать и записывать все символы строки каждый раз, даже в том случае, когда модификации строки не требуется.
Очевидным усовершенствованием этой идеи является пропуск префикса исходной строки, который не должен быть модифицирован, и последующая запись символов только после этого префикса - в действительности так зачастую работают алгоритмы, аналогичные реализованному в рамках функции std::remove_if().
В библиотеке pugixml используется другой подход (обратитесь к Рисунку 4.3). В любой момент должно существовать не более одного разрыва строки. Разрыв строки является последовательностью символов, которые не рассматриваются, так как они уже не являются частью результирующей строки. В момент, когда должен быть добавлен новый разрыв (например, замена " на символ " приводит к генерации разрыва из 5 символов), существующий разрыв (в том случае, если он существует) закрывается путем переноса находящихся между двумя разрывами данных в начало первого разрыва и сохранения позиции второго разрыва. По сложности данный подход эквивалентен подходу с указателями чтения и записи; однако, он позволяет нам использовать более быстрые функции для закрытия разрывов строк. (Pugixml использует функцию memmove, которая может копировать данные более эффективно, чем это делается в цикле посимвольного копирования, в зависимости от длины разрыва строки и реализации библиотеки времени исполнения языка C.)
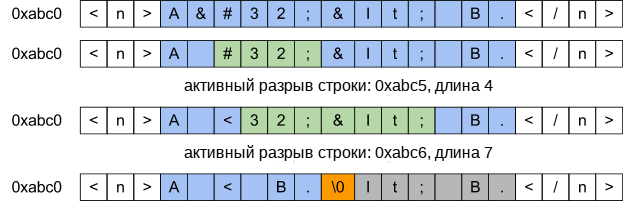
Рисунок 4.3 - Пример операций обработки разрывов строк в ходе преобразования данных PCDATA
Продолжение статьи: Оптимизация механизма передачи управления.