





Библиотека сайта rus-linux.net
Customers and users, on the other hand, tend to see complexity in terms of the program's interface complexity. In Chapter═11 we discussed the quality of ease and its inverse, mnemonic load. To a user, complexity correlates closely with mnemonic load. Poor expressiveness and concision can matter too, if a weak interface forces the user to perform lots of error-prone or merely tedious low-level operations rather than a few high-level ones.
Driven by both of these is a third measure that is much simpler: the total number of lines of code in the system, its codebase size. In terms of life-cycle costs, this is usually the most important measure. The reasons go back to perhaps the most important empirical result in software engineering, one we've cited before: the defect density of code, bugs per hundred lines, tends to be a constant independent of implementation language. More lines of code means more bugs, and debugging is the most expensive and time-consuming part of development.
Codebase size, interface complexity and implementation complexity may all rise together. That is the usual result of feature creep, and why programmers especially dread it. Premature optimization doesn't tend to raise interface complexity, but it has bad effects (often severely bad) on implementation complexity and codebase size. But those sorts of arguments against complexity are relatively easy to win; the difficult ones begin when these three measures have to be traded off against each other.
We've already mentioned one situation in which two measures vary in opposite directions: a user interface that has been designed primarily to preserve implementation simplicity, or keep codebase size down, may simply dump low-level tasks on the user. (A crude example of this, barely imaginable to a Unix programmer but all too common elsewhere, might be an editor that lacked a global-replace feature.) Though this sort of design failure is all too common, it does not traditionally have a name. We'll call it a manularity trap.
Pressure to keep the codebase size down by using extremely dense and complicated implementation techniques can cause a cascade of implementation complexity in the system, leading to an un-debuggable mess. This used to happen frequently when fitting programs onto very small systems demanded assembler programming or tricks like self-modifying code; nowadays it is uncommon except in embedded systems, and rapidly becoming rare even there. This kind of design failure doesn't have a traditional name, but one might call it a blivet trap, after an old Army term for the results of attempting to stuff ten pounds of horse manure into a five-pound bag.
The blivet trap won't appear in our case studies, but we've defined it for contrast with its opposite. It can happen that the designers of a project are so wary of implementation complexity that they reject a complex but unified way to solve a whole class of problems in favor of lots of duplicative, ad-hoc code that solves each individual one in turn. The result is bloat in the size of the codebase, and maintainability problems more severe than if the unified method had been accepted. For example, a Web project that really needs a centralized relational database behind its pages might instead spawn several different keyed data files containing information that has to be reintegrated at page generation time. This sort of failure is all too common. It doesn't have a traditional name; we'll call it an adhocity trap.
These are the three faces of complexity, and some of the traps designers fall into in attempts to avoid them.[114] We'll see more examples when we get to the case studies later in the chapter.
One of the most perceptive observations ever made about the Unix tradition by someone standing outside it was contained in Richard Gabriel's paper called Lisp: Good News, Bad News, and How to Win Big [Gabriel]. Gabriel is a long-time leader of the Lisp community, and the paper was primarily an argument for a particular style of Lisp design, but the author himself acknowledges that it is now remembered primarily for the section called ‘The Rise of Worse Is Better’.
To sharpen our vision, we need to begin by noticing a difference between accidental complexity and optional complexity.[115] Accidental complexity happens because someone didn't find the simplest way to implement a specified set of features. Accidental complexity can be eliminated by good design, or good redesign. Optional complexity, on the other hand, is tied to some desirable feature. Optional complexity can be eliminated only by changing the project's objectives.
When we fail to distinguish between optional and accidental complexity, design debates become seriously confused. Questions about what a project's objectives are get confused with questions about the aesthetics of simplicity, and whether people have been sufficiently clever.
So far, we've developed two different scales for thinking about complexity. These scales are actually orthogonal to each other. Figure═13.1 may help clarify the relationships. Each of the nine boxes of the figure lists a common source of a particular kind of complexity.
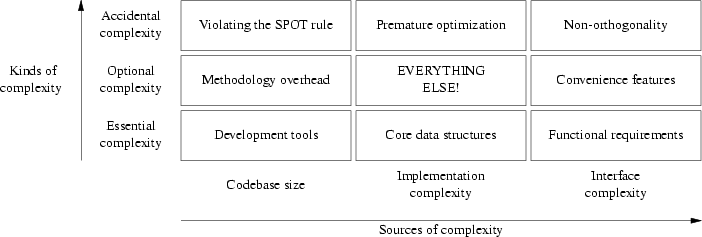
We've touched on some of these varieties of complexity earlier in this book, especially the accidental ones. In Chapter═4 we saw that accidental interface complexity often comes from non-orthogonality in the interface design — that is, failing to carefully factor the interface operations so that each does exactly one thing. Accidental code complexity (making code more complicated than it needs to be to get the job done) often results from premature optimization. Accidental codebase bloat often results from violating the SPOT rule, duplicating code or organizing it poorly so that opportunities for reuse aren't recognized.
Essential interface complexity usually can't be cut without trimming the basic functional requirements for the software (a theme we'll develop further in this chapter's case studies). Essential codebase size is related to choice of development tools because, if the feature list is held constant, the most important factor in codebase size is probably the choice of implementation language (as we implied in Chapter═8).
Sources of optional complexity are the most difficult to make useful generalizations about, because they so often depend on delicate judgments about which features it is worth paying the complexity cost for. Optional interface complexity often comes from adding convenience features that make life easier for users but aren't essential to the function of the program. Optional increases in codebase size (supposing the user-visible features and the algorithms used are held constant) can often come from various sorts of practices intended to make it more maintainable — adding mode comments, using long variable names, and so forth. Optional implementation complexity tends to be driven by everything that touches a project.
The sources of complexity have to be grappled with in different ways. Codebase size can be attacked with better tools. Implementation complexity can be addressed with better choice of algorithms. Interface complexity has to be addressed with better interaction design, a skill involving considerations of ergonomics and user psychology. This skill is less common (and possibly more difficult) than writing code.
Attacking the kinds of complexity, on the other hand, has to be done more with insight than with methods. You cut accidental complexity by noticing that there is a simpler way to do things. You cut optional complexity by making context-dependent judgments about what features are worthwhile. You can only cut essential complexity by having an epiphany, fundamentally redefining the problem you are addressing.