





Библиотека сайта rus-linux.net
Виртуализация Linux и сквозной доступ к устройствам PCI
Оригинал: "Linux virtualization and PCI passthrough"Автор: M. Tim Jones
Дата публикации: 13 Oct 2009
Перевод: Н.Ромоданов
Дата перевода: март 2010 г.
Краткое содержание: Процессоры постоянно совершенствуются с целью повышения производительности работы в виртуальной среде, а как обстоят дела с вводом/выводом? Познакомьтесь с одним новшеством, связанным с вводом/выводом, которое улучшает производительность и называется сквозным доступом к устройству (или шине PCI). Это новшество повышает производительность устройств PCI благодаря аппаратной поддержке, реализованной фирмами Intel (VT-D) и AMD (IOMMU).
Когда платформа используется одновременно двумя или большим количеством операционных систем с целью достичь более эффективного использования ресурсов, то говорят о платформенной виртуализации. Но платформа подразумевает больше, чем просто процессор: она включает в себя также другие важные элементы, которые образуют платформу, например, устройства хранения данных, сетевое оборудование и другие аппаратные ресурсы. Некоторые аппаратные ресурсы, такие как процессор или устройства хранения данных, виртуализировать просто, а другие, такие как видео-адаптер или последовательный порт, плохо виртуализирутся. В технологии сквозного доступа к устройствам PCI (PCI passthrough) предоставлены средства, позволяющие использовать ресурсы второго вида эффективно в тех случаях, когда их совместное использование невозможно или нецелесообразно. В настоящей статье рассматривается понятие сквозного доступа (passthrough), обсуждается его реализация в гипервизорах, а также рассматриваются те особенности реализации гипервизоров, благодаря которым осуществляется поддержка этой самой новейшей технологии.
Платформенная эмуляция устройств
Прежде, чем перейти к технологии сквозного доступа, давайте рассмотрим, как эмуляция устройств используется в настоящее время в двух различных вариантах архитектуры гипервизоров. В первом варианте эмуляция устройств осуществляется в самом гипервизоре, тогда как во втором варианте эмуляция устройств переносится в отдельное приложение, внешнее по отношению к гипервизору.
Эмуляция устройства внутри гипервизора является обычным приемом, реализованным, например, в приложении VMware workstation (гипервизор на базе операционной системы). В этой модели внутри гипервизора реализована эмуляция обычных устройств, которые одновременно используются различными гостевыми операционными системами, это - виртуальные диски, виртуальные сетевые адаптеры и другие важные платформенные компоненты. Эта модель изображена на рис.1.
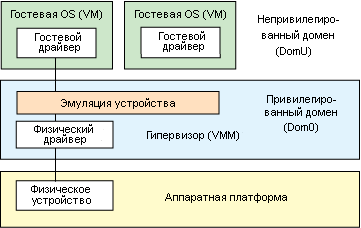
Рис.1. Эмуляция устройства внутри гипервизора
Второй вариант архитектуры называется эмуляцией устройств в пользовательском пространстве (см. рис.2). Как следует из названия, эмуляция устройств происходит не в гипервизоре, а в пользовательском пространстве. Например, приложение QEMU (в котором реализована не только эмуляция устройств, но также есть и гипервизор) само выполняет эмуляцию и используется большим количеством независимо реализованных гипервизоров (только два из них — виртуальная машина на базе ядра Linux KVM и VirtualBox). В этой модели преимущество в том, что эмуляция устройств независима от гипервизора и эти устройства могут одновременно использоваться несколькими гипервизорами. При таком подходе возможна эмуляция любых устройств, причем это не ляжет дополнительной нагрузкой на гипервизор (который оперирует в привилегированном режиме).
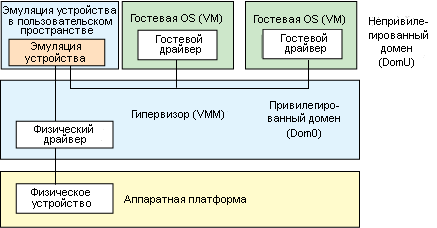
Рис.2. Эмуляция устройств в пользовательском пространстве
Перенос эмуляции устройств из гипервизора в пользовательское пространство дает некоторые очевидные преимущества. Наиболее важное касается базиса, обеспечивающего безопасную работу вычислительной системы TCB (trusted computing base). К TCB системы относятся все компоненты, которые критичны с точки зрения обеспечения безопасной работы системы. Разумеется, что если размер системы меньше, то меньше вероятность ошибок системы и система, следовательно, будет более безопасной. То же самое относится к гипервизору. Безопасность работы гипервизора имеет решающее значение, поскольку он изолирует несколько независимо работающих гостевых операционных систем. Чем меньше кода в гипервизоре (за счет переноса эмуляции устройств в менее привилегированное пользовательское пространство), тем меньше вероятность несанкционированного получения привилегий сторонними пользователями.
Еще одним вариантом эмуляции устройств с использованием гипервизора является использование драйверов паравиртуализации. В этой модели в состав гипервизора входят драйвера для работы с физически существующими устройствами, а в каждой гостевой операционной системе имеется специальный драйвер, который работает во взаимодействии с драйверами гипервизора (называемыми паравиртуализированными драйверами или PV драйверами).
Независимо от того, выполняется ли эмуляция устройства в гипервизоре или выше - в гостевой виртуальной машине (VM), методы эмуляции аналогичны. При эмуляции устройств могут имитироваться конкретные устройства (например, сетевой адаптер Novell NE1000), либо конкретный тип диска (например, диски Integrated Device Electronics - IDE). Физическое оборудование может существенно различаться, например, когда в гостевых операционных системах эмулируется диск IDE, в физической аппаратной платформе может использоваться диск Serial ATA (SATA). Это удобно, поскольку поддержка дисков IDE есть во многих операционных системах и это можно использовать в роли общего подхода вместо того, чтобы во каждой гостевой операционной системе осуществлять поддержку дисков более современного типа.
Сквозной доступ к устройствам
Как видно из двух вариантов эмуляции устройств, приведенных выше, есть некоторая цена, которую нужно заплатить за совместное использование устройств. Накладные расходы существуют независимо от того, осуществляется эмуляция устройств в гипервизоре или в пользовательском пространстве в отдельной виртуальной машине. Эти накладные расходы существуют до тех пор, пока устройство будет доступно одновременно нескольким гостевым операционным системам. Если совместное использование устройств не требуется, то есть более эффективные способы доступа к таким устройствам.
Итак, с самой общей точки зрения сквозной доступ к устройству является методикой, представляющей собой изоляцию устройств для конкретной гостевой операционной системы таким образом, что это устройство может использоваться исключительно этой гостевой системой (см. рис. 3). Но в чем здесь выгода? Очевидно, что существует целый ряд причин, по которым целесообразно использовать сквозной доступ к устройству. Двумя наиболее важными причинами являются повышение производительности и предоставление исключительного доступа к устройству, которое по сути не должно использоваться совместно.
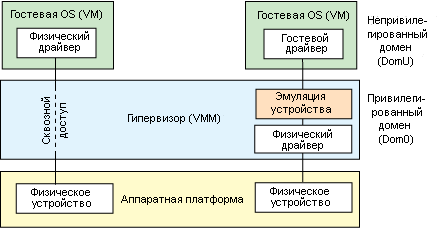
Рис.3. Сквозной доступ внутри гипервизора
При использовании сквозного доступа к устройству можно достичь производительности, почти равной производительности самого устройства. Это идеально для сетевых приложений (или тех, в которых большой объем ввода/вывода на диск), в которых не используется виртуализация из-за отсутствия согласованности с гипервизором (несогласованность с драйвером в гипервизоре) и снижения производительности (из-за эмуляции в гипервизоре пользовательского пространства). Но назначение устройств конкретным гостевым системам также выгодно в случае, если эти устройства нельзя использовать одновременно несколькими системами. Например, если в системе есть нескольких видеоадаптеров, то их можно индивидуально закрепить за каждым конкретным гостевым доменом.
Наконец, могут быть специализированные устройства PCI, которые может использовать только один гостевой домен, или устройства, которые не поддерживаются гипервизором и, следовательно, должны быть перенесены в гостевую систему. Для конкретного домена могут быть выделены отдельные USB порты, либо для конкретной гостевой системы может быть выделен последовательный порт (который, сам по себе, не может использоваться одновременно несколькими системами).
Заглянем "под капот" технологии эмуляции устройств
В ранних вариантах эмуляции устройств в гипервизоре создавался специальный вид интерфейса устройства, который в гостевой операционной системе реализовывал виртуальный интерфейс к аппаратному обеспечению. Этот виртуальный интерфейс должен был представлять собой общепринятый интерфейс устройства, в состав которого входят виртуальное адресное пространство для конкретного устройства (например, виртуальная шина PCI) и виртуальные прерывания. Но с драйвером устройства взаимодействует виртуальный интерфейс, а гипервизор транслирует это взаимодействие в фактически существующее оборудование, в результате возникали большие накладные расходы, особенно в случае использования устройств с высокой пропускной способностью, таких как сетевые адаптеры.
В Xen пропагандировался подход с использованием паравиртуализации (рассмотренный в предыдущем разделе), который уменьшал потерю производительности за счет того, что драйвер гостевой операционной системы имел информацию о том, что он виртуальный. В этом случае гостевая операционная система не обращалась к адресному пространству на шине PCI, выделенному для устройства (например, сетевого адаптера), а вместо этого использовала интерфейс прикладного программного обеспечения для этого сетевого адаптера (API), что позволяло использовать более высокий уровень абстракции (например, пакетный интерфейс). Недостаток этого подхода в том, что для использования паравиртуализации гостевую операционную систему нужно было модифицировать. Преимущество было в том, что в некоторых случаях вы могли достичь производительности, почти равной производительности аппаратного обеспечения.
В первых вариантах, реализующих сквозной доступ к устройствам, была предложена простая модель эмуляции, в которой гипервизор программным образом осуществлял управление памятью (трансляцию адресного пространства гостевой операционной системы в адресное пространство доверенного хоста). И хотя в первых реализациях были предоставлены средства, позволяющие изолировать использование устройства только конкретной гостевой операционной системой, у этого подхода не хватало производительности и масштабируемости, необходимой для больших виртуальных сред. К счастью, у поставщиков процессоров появились процессоры нового поколения, имеющие инструкции для поддержки гипервизоров, а также логики сквозного доступа к устройствам, в том числе виртуализации прерываний и поддержка прямого доступа к памяти (DMA). Таким образом, вместо того, чтобы отлавливать и эмулировать доступ к физическим устройствам, лежащим ниже гипервизора, в новых процессорах для эффективного сквозного доступа к устройствам поддерживается трансляция адресов DMA и проверка прав доступа.
Аппаратная поддержка сквозного доступа к устройствам
Как Intel, так и AMD обеспечивают поддержку сквозного доступа к устройствам в своих процессорах с новой архитектурой (в дополнение к новым инструкциям, которые поддерживают работу гипервизора). Intel использует свой вариант, называемый Virtualization Technology for Directed I/O (VT-d), в то время как AMD использует вариант I/O Memory Management Unit (IOMMU). В каждом случае, новые процессоры предоставляют средства отображения физических адресов шины PCI в виртуальные адреса гостевых систем. Когда выполняется это отображение, доступ (и защита) реализуются на уровне аппаратного обеспечения и гостевая операционная система может использовать устройство, как если бы система не была виртуальной. В дополнение к отображению гостевой системы в физическую память, поддерживается изоляция устройства таким образом, чтобы другие гостевые системы (или гипервизор) не имели к нему доступа. В процессорах Intel и AMD реализована поддержка еще многих функций, предназначенных для виртуализации. Подробности вы можете узнать из статей, перечисленных в разделе "Ресурсы" оригинала статьи.
Еще одно новшество, которое помогает масштабировать прерывания для большого числа виртуальных машин, называется Message Signaled Interrupts (MSI). Вместо того чтобы полагаться на физические прерывания, связанные с гостевой системой, MSI преобразует прерывания в сообщения, которые легче сделать виртуальными (что позволяет обрабатывать тысячи отдельных прерываний). MSI доступно в PCI с версии 2.2 и оно также доступно на шине PCI Express (PCIe), что составляет основу для масштабирования многих устройств. MSI идеально подходит для виртуализации ввода/вывода, поскольку оно позволяет изолировать источники прерываний (отличие от физических прерываний, которые мультиплексируются или маршрутизируются с помощью программ).
Поддержка в гипервизоре сквозного доступа к устройствам
Благодаря новейшим процессорам с архитектурой, поддерживающей виртуализацию, в ряде гипервизоров и схем виртуализации был реализован механизм сквозного доступ к устройствам. Вы сможете найти поддержку механизма сквозного доступа к устройствам (с использованием VT-D или IOMMU) в Xen и KVM, а также в других гипервизорах. В большинстве случаев, гостевая операционная система (домен 0) должны быть откомпилирована с использованием поддержки сквозного подхода, что реализовано как возможность, подключаемая во время создания ядра. Может также потребоваться механизм изоляции устройств от хостовой виртуальной машины (так, как это делается в Xen с помощью pciback). Есть некоторые ограничения, касающиеся PCI (например, устройства PCI, находящиеся за мостом PCIe-to-PCI, должны назначаться одному и тому же домену), но это ограничение не относится к PCIe.
Кроме того, механизм сквозного доступа к устройствам реализован в библиотеке libvirt (вместе с virsh), в которой предлагается абстракция конфигурационных схем, используемых в гипервизорах.
Проблемы со сквозным доступом к устройствам
Одна из проблем, связанная со сквозным с доступом к устройствам, возникает, когда требуется "живая миграция". "Живой миграцией" (Live migration) является приостановка виртуальной машины с последующим его переносом на новый физический хост, на котором виртуальная машина перезапускается. Это отличная возможность для поддержки балансировки нагрузки, связанной с виртуальными машинами, в сети из физических хостов, но возникает проблема, если используется сквозной доступ к устройствам. Горячее подключение к шине PCI (для которого есть несколько спецификаций) является одним из аспектов, которые нужно решить. При горячем подключении к шине PCI должна быть возможность добавлять устройства PCI к ядру и удалять их из ядра, что было бы идеальным, особенно когда миграция виртуальной машины осуществляется на гипервизор на новой хостовой машине (устройства должны быть отсоединены, а затем подключены к новому гипервизору) . Когда эмулируются устройства, такие как виртуальные сетевые адаптеры, то создается специальный слой, абстрагированный от физического оборудования. В этом случае виртуальный сетевой адаптер легко мигрирует в пределах виртуальной машины (поддерживается привязка к драйверам Linux и допускается привязка нескольких драйверов к одному и тому же интерфейсу).
Дальнейшее развитие виртуализации ввода/вывода
Уже сегодня виртуализация ввода/вывода развивается дальше. Например, шина PCIe поддерживает виртуализацию. Одна их концепций, которая идеальна для виртуализации серверов, называется Single-Root I/O Virtualization (SR-IOV). Эта технология виртуализации (созданная группой PCI-Special Interest Group, или PCI-SIG) обеспечивает виртуализацию устройств в сложных системах с одной корневой системой (случай, когда устройство используется на одном сервере с несколькими виртуальными машинами). Еще один вариант, называемый Multi-Root IOV, поддерживает более сложные варианты топологии (такие как блейд-сервера, где несколько серверов могут получить доступ к одному или нескольким устройствам PCIe). В некотором смысле, это позволяет использовать сколь угодно большие сети устройств, включающие в себя серверы, конечные устройства, и коммутаторы (со средствами идентификации устройств и средствами пакетной маршрутизации).
В рамках концепции SR-IOV устройство PCIe может экспортировать не только ряд физических функций шины PCI, но также ряд виртуальных функций, которые совместно используют ресурсы на устройстве ввода/вывода. Упрощенная архитектура сервреной виртуализации приведена на рис.4. В этой модели сквозной доступ к устройству не нужен, так как виртуализация осуществляется для конечного устройства, поэтому гипервизору для того, чтобы достичь производительности, равной производительности аппаратного обеспечения и обеспечить безопасность за счет изоляции, достаточно просто отобразить виртуальные функции в виртуальные машины.
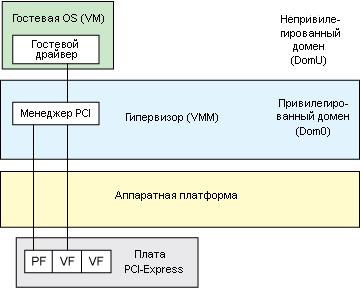
Рис.4. Сквозной доступ с использованием SR-IOV
Двигаемся дальше
Виртуализация развивается уже в течение приблизительно 50 лет, но только сейчас достаточное внимание уделяется виртуализации ввода/вывода. Коммерческие процессоры, поддерживающие виртуализацию, появились только пять лет назад. Так что, в сущности, мы находимся на пороге перехода к платформенной виртуализации и виртуализации ввода/вывода. И, как один из ключевых элементов архитектур вычислительных систем будущего, таких как облачные вычисления, виртуализация, безусловно, будет рассматриваться как интересная технология, которая будет развиваться. Как обычно, Linux находится на переднем крае поддержки этих новых архитектур и в последних версиях ядра (2.6.27 и выше) начинает появляться поддержка этих новых технологий виртуализации.