





Библиотека сайта rus-linux.net
Ceph: Распределенная файловая система петабайтных масштабов для Linux
Оригинал: "Ceph: A Linux petabyte-scale distributed file system"Автор: M. Tim Jones
Дата публикации: 04 May 2010
Перевод: Н.Ромоданов
Дата перевода: 27 мая 2010 г.
| Краткое содержание: Linux продолжает вторгаться в область масштабируемых вычислений и, в частности, в область масштабируемых систем хранения данных. Последним дополнением к впечатляющим набору файловых систем, имеющемуся в Linux, является Ceph, распределенная файловая система, в которой есть средства репликации и обеспечения отказоустойчивости при одновременном сохранении совместимости со стандартами POSIX. Познакомимся с архитектурой Ceph и узнаем, как в ней обеспечивается отказоустойчивость и облегчается управление огромными объемами данных. |
Как архитектор индустрии хранения данных, я достаточно близко знаком с файловыми системами. Эти системы являются пользовательскими интерфейсами систем хранения данных, и хотя все они, как правило, предлагают аналогичный набор функций, в них также могут быть заметные различия. Ceph — обычная система и большую часть того, что в ней предлагается, можно найти в любой файловой системе.
Разработка Ceph была начата Сейдж Вейлем (Sage Weil) в Калифорнийском Университете в Санта-Круз (University of California, Santa Cruz - UCSC) как исследовательский проект по системам хранения данных, выполняемый на звание доктора философии. Но уже с конца марта 2010 года вы можете обнаружить Ceph в основной ветке ядра Linux (с версии 2.6.34). Хотя система Ceph, возможно, еще не готова для промышленной эксплуатации, она по-прежнему интересна с точки зрения ее оценки. В этой статье рассматривается файловая система Ceph и те уникальные особенности, которые делают её привлекательной в качестве варианта масштабируемой распределенной системы хранения данных.
Почему "Ceph"?
Название "Ceph" является странным для файловой системы и прерывает обычную тенденцию использовать сокращения, которой следует большинство разработчиков. Название указывает на талисман Калифорнийского Университета Санта-Круз (место создания Ceph), которым оказался "Сэмми", банановый слизняк, моллюск из класса головоногих, не имеющий раковины. Головоногие, с их многочисленными усиками, являются хорошей метафорой распределенной файловой системы.
Назначение Ceph
Разработка распределенной файловой системы является сложным предприятием, но оно чрезвычайно ценно, если решены определенные проблемы. Назначение Ceph можно просто определить следующими задачами:
- Легкость масштабирования до петабайтных размеров
- Высокая производительность при различных нагрузках (числа операций ввода/вывода в секунду и различной полосе пропускания)
- Повышенная надежность
К сожалению, эти задачи могут конкурировать друг с другом (например, масштабируемость может снижать производительность или мешать ее увеличению, либо может влиять на надежность). В Ceph используется несколько очень интересных концепций (таких как динамическое разделение метаданных и распределение/репликация данных), которые рассматриваются в настоящей статье. В архитектуру Ceph заложена также устойчивость к одиночным отказам, причем предполагается, что на больших объемах данных (петабайты данных) отказы в системе хранения являются обычным явлением, а не исключением. Наконец, система не разрабатывалась под конкретную нагрузку, она может адаптироваться к изменению распределенной нагрузки и это обеспечивает наилучшую производительность. Все функции системы совместимы со стандартами POSIX, благодаря чему развертывание системы не окажет влияние на существующие приложения, действующие в рамках POSIX (используются расширения, предлагаемые в Ceph). Наконец, Ceph является распределенной системой хранения данных с открытым исходным кодом, которая входит в основную ветку ядра Linux (с версии 2.6.34).
Архитектура Ceph
Давайте теперь изучим самый верхний уровень архитектуры Ceph и ее основные компоненты. Затем перейдем на следующий уровень, на котором познакомимся с некоторыми ключевыми аспектами Ceph и продолжим более подробное изучение системы.
Экосистему Ceph можно грубо поделить на четыре части (см. рис.1): клиенты (пользователи данных), сервера метаданных (которые кэшируют и синхронизируют распределенные метаданные), кластер хранения объектов (в котором в виде объектов хранятся как данные,так и метаданные, и в котором реализованы другие ключевые особенности), и, наконец, кластерные мониторы (с помощью которых реализованы функции мониторинга).
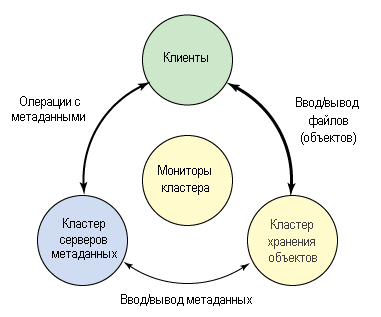
Рис.1. Концептуальный взгляд на экосистему Ceph
Как видно на рис.1, клиенты с помощью серверов метаданных выполняют операции с метаданными (для определения местонахождения данных). Сервера метаданных управляют размещением данных, а также указывают, куда помещать новые данные. Обратите внимание, что метаданные хранятся в кластере хранения данных (отмечено как "Metadata I/O" — ввод / вывод метаданных). Фактический файловый ввод/вывод происходит между клиентом и кластером хранения объектов. Таким образом, управление высокоуровневыми функциями POSIX (такими, как открытие, закрытие и переименование) осуществляется с помощью серверов метаданных, тогда как управление обычными функциями POSIX (такими, как чтение и запись) осуществляется непосредственно через кластер хранения объектов.
Другой взгляд на архитектуру системы показан на рис.2. Набор серверов получает доступ к экосистеме Ceph через клиентский интерфейс, в котором реализована взаимосвязь между серверами метаданных и хранилищем объектов данных. Распределенную систему хранения данных можно рассматривать в виде нескольких слоев, среди которых есть слой устройств хранения данных (Extent and B-tree-based Object File System [EBOFS] - объектная файловая система с масштабированием и использованием двоичных деревьев или альтернативная) и выше его управляющий слой, предназначенным для управления репликацией данных, обнаружения отказов и восстановления данных с последующей их миграцией, который называется RADOS (Reliable Autonomic Distributed Object Storage- надежное автономное распределенное хранилище объектов данных). И наконец, для выявления отказов компонентов и последующего уведомления об этом используются мониторы.

Рис.2. Упрощенная схема слоев экосистемы Ceph
Ядро или пользовательское пространство
В ранних версиях Ceph использовался механизм Filesystems in User SpacE (FUSE), в котором файловая система помещалась в пользовательское пространство, и это позволило существенно упростить разработку. Но сегодня Ceph включена в основную ветвь ядра, что делает ее быстрее, поскольку теперь для выполнения файлового ввода/вывода не нужно переключаться в контекст пользовательского пространства.
Компоненты Ceph
Покинем концептуальный уровень архитектуры Ceph и перейдем на следующий уровень, чтобы рассмотреть основные компоненты, реализованные в экосистеме Ceph. Одно из основных различий между Ceph и традиционными файловыми системами в том, что вместо того, чтобы сосредотачивать логику в самой файловой системе, в Ceph она распределена по всей экосистеме.
На рисунке 3 показана упрощенная схема экосистемы Ceph. Клиент ( Ceph Client) является пользователем файловой системы Ceph. С помощью демона метаданных (Ceph Metadata Daemon) реализуется сервис метаданных, а с помощью демона хранилища объектов (Ceph Object Storage Daemon ) реализуется фактическое хранение (как данных, так и метаданных). Наконец, с помощью монитора (Ceph Monitor) реализуется управление кластером. Обратите внимание, что может быть много клиентов, много узлов хранилищ объектов данных, огромное количество серверов метаданных (зависит от емкости файловой системы), и, по крайней мере для обеспечения избыточности, пара мониторов. Итак, как эта файловая система функционирует распределенно?
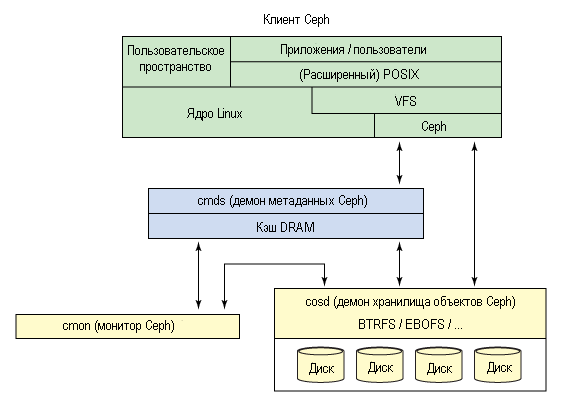
Рис.3. Упрощенная схема экосистемы Ceph
Клиент Ceph
Поскольку в Linux предоставляется обычный интерфейс файловых систем (через переключатель виртуальной файловой системы [VFS]), то, с точки зрения пользователя, файловая система Ceph является прозрачной. С точки зрения администратора отличие, безусловно, есть, поскольку появляется потенциальная возможность добавлять к системе хранения данных большое количество серверов (информацию о том, как создать кластер Ceph, смотрите в разделе "Ресурсы" оригинала статьи). С точки зрения пользователей, они просто имеют доступ к огромной системе хранения данных и не осведомлены об используемых для этого серверах метаданных, мониторах и отдельных устройствах, составляющих массивный пул системы хранения данных. Пользователи просто видят точку монтирования, в которой могут быть выполнены стандартные операции файлового ввода / вывода.
Файловая система Ceph или, по крайней мере, клиентский интерфейс реализуется в ядре Linux. Обратите внимание, что в подавляющем большинстве файловых систем, все управление и логика реализованы в файловой системе ядра. Но в случае с Ceph, логика файловой системы рассредоточена по узлам, что упрощает клиентский интерфейс и делает возможным осуществлять существенное масштабирование (даже динамически).
Вместо того, чтобы использовать списки размещения данных (метаданные, в которых для данного файла указаны блоки данных на диске), в Ceph используется другой интересный вариант. Файлу, если рассматривать его в среде Linux, сервером метаданных присваивается номер инода (INO), который представляет собой уникальный идентификатор файла. Затем файл разрезается на некоторое количество объектов (зависит от размера файла). Каждому объекту присваивается идентификатор объекта (OID), которые зависит от INO и от номера объекта (ONO). С помощью простой хэш-функции, применяемой к OID, каждый объект назначается группе размещения. С концептуальной точки зрения группа размещения (идентифицируется с помощью PGID) является контейнером объектов. И наконец, группа размещения отображается на устройства хранения данных; это отображение является псевдо-случайным отображением, осуществляемым с помощью алгоритма, называемым Controlled Replication Under Scalable Hashing — CRUSH (управляемая репликация с масштабируемым хешированием). Следовательно, отображение групп размещения (и репликаций) на устройства хранения данных не зависит от каких-либо метаданных, а выполняется с помощью функции псевдо-случайного отображения. Такая функциональность является идеальной, поскольку минимизирует нагрузку по хранению данных и упрощает размещение и выборку данных.
Последней компонентой распределения данных является карта кластера. Карта кластера является эффективным средством представления информации об устройствах, используемых в кластере хранения данных. С помощью PGID и карты кластера вы можете найти любой объект.
Сервер метаданных Ceph
Работа сервера метаданных (cmds) состоит в управлении пространством имен файловой системы. Хотя как метаданные, так и данные хранятся в кластере хранения объекта, для поддержки масштабирования управление ими осуществляется раздельно. Более того, метаданные дополнительно распределяются по кластеру серверов метаданных, которые могут адаптивно реплицировать и расширять пространство имен с тем, чтобы предотвратить локальную перегрузку. Как показано на рис.4, сервера метаданных управляют частями пространства имен, причем эти части могут перекрывать друг друга (для обеспечения избыточности и повышения производительности). Сервера метаданных распределяются в Ceph по пространству имен с использованием алгоритма динамического разделения на поддеревья, что позволяет Ceph адаптироваться к меняющейся нагрузке (миграция пространств имен среди серверов метаданных) и сохранять локальную производительность.

Рис.4. Разбиение пространства имен Ceph по серверам метаданных
Но поскольку каждый сервер метаданных попросту управляет пространством имен для некоторого количества клиентов, его первоочередной задачей является интеллектуальное кэширование метаданных (поскольку действительные метаданные хранятся, в конечном счете, в кластере хранения объектов данных). Метаданные, предназначенные для записи, кэшируются в краткосрочном журнале, который, в конечном счете, помещается на физический носитель. Такая функциональность позволяет серверу метаданных сервера возвращать последние метаданные обратно клиентам (что является обычным при выполнении операций с метаданными). Журнал также полезен при восстановлении после отказа: если произойдет отказ сервера метаданных, его журнал можно повторно обработать и гарантировать, что метаданные будут надежно записаны на диск.
Сервера метаданных управляют пространством инодов, преобразуя имена файлов в метаданные. Сервер метаданных трансформирует имя файла в инод, в значение, указывающее на размер файла, и в "порции" данных (компоновка данных), которые клиент Ceph использует для файлового ввода / вывода.
Мониторы Ceph
В Ceph имеются мониторы, с помощью которых реализовано управление картой кластера, но некоторые элементы управления отказоустойчивостью реализованы в самом хранилище объектов данных. Когда происходит отказ устройства или добавляется новое устройство, мониторы обнаруживают это событие и поддерживают карту кластера в актуальном состоянии. Эта функция выполняется в распределенном режиме, причем обмен обновленными картами осуществляется в рамках существующего трафика. В Ceph используется Paxos - семейство алгоритмов выработки консенсуса в распределенных системах.
Хранилище объектов Ceph
Узлы хранения данных в Ceph не только сохраняют данные так, как и в традиционных системах хранения объектов, но и реализуют дополнительную логику. Традиционные накопители просто принимают команды от инициирующих устройств. Но устройства хранения объектов данных являются интеллектуальными, которые как получают команды, так и сами посылают команды с тем, чтобы поддерживать взаимодействие с другими устройствами хранения объектов данных.
Если рассматривать хранение объектов, устройства хранения объектов данных в Ceph выполняют отображение объектов в блоки (задача, традиционно выполняемая на клиенте в слое файловой системы). Такая функциональность позволяет на локальным уровне решать, как хранить объект. В ранних версиях Ceph на каждом локальном устройстве хранения использовалась настраиваемая низкоуровневая файловая система, называемая EBOFS. В этой системе был реализован нестандартный интерфейс, соответствующий семантике работы с объектами на нижнем уровне, и некоторые другие возможности (например, асинхронные уведомления, подтверждающие действия с диском). Сегодня на узлах хранения объектов можно использовать файловую систему с двоичными деревьями (BTRFS), в которой уже реализованы некоторые необходимые возможности (такие как встроенная проверка целостности данных).
Посколку в клиенте Ceph реализован алгоритм CRUSH и клиент не знает о блочном отображении файлов на диски, устройства нижнего уровня, используемые для хранения данных, могут благополучно управлять отображением объектов в блоки. Это позволяет узлам хранения реплицировать данные (если обнаружено, что произошел отказ устройства). Рассредоточенное восстановление, осуществляемое в случае возникновения отказа, также допускает масштабирование системы хранения, поскольку обнаружение отказов и восстановление после отказов распределены по всей экосистеме. В Ceph это называется RADOS (см. рис.3).
Другие интересные особенности
В Ceph в добавок к динамичности и адаптивности, которыми обладает файловая система, реализованы также некоторые интересные особенности, доступные пользователю. Пользователь, например, может создавать в Ceph мгновенные снимки любого поддиректория (с сохранением всего содержимого поддиректория). Кроме того, можно на уровне поддиректория вести учет количества файлов и их размеров и для заданного поддиректория (и всех его вложенных компонентов) сохранять сведения о размере занимаемого пространства и числе файлов.
Текущее состояние Ceph и ее будущее
Хотя Ceph уже интегрирована в основную ветвь ядра Linux, необходимо отметить, что это экспериментальная возможность. Файловые системы в этом состоянии полезны для оценки, но еще не готовы для промышленной эксплуатации. Но если учитывать включение системы Ceph в ядро Linux и интерес ее разработчиков к продолжению разработок, эту систему вскоре можно будет использовать для решения задач, связанных с большими хранилищами данных.
Другие распределенные файловые системы
Система Ceph не является уникальной среди распределенных файловых систем, но она уникальна тем, как она управляет огромной экосистемой хранения данных. К числу других примеров распределенных файловых систем относятся Google File System (GFS), General Parallel File System (GPFS), и Lustre, и это лишь некоторые из них. Идеи, лежащие в основе Ceph, открывают интересные перспективы распределенных файловых систем, заключающиеся в возможности широкого масштабирования, что открывает новые горизонты в создании огромных хранилищ данных.
Двигаемся дальше
Ceph не только файловая система, но и экосистема хранения объектов данных уровня предприятия. Информацию о том, как создать простой кластер Ceph (в том числе сервера метаданных, сервера объектов данных, а также мониторы), вы сможете найти в разделе "Ресурсы" оригинала статьи. Ceph заполняет пробел в системах распределенного хранения данных, и будет интересно узнать, как будет развиваться это начинание, предложенное системами с открытым исходным кодом.