Библиотека сайта rus-linux.net
Чтение Excel-файлов в Perl
Оригинал: Reading Native Excel Files in Perl
Автор: Mike Diehl
Дата: 2 сентября 2008
Перевод: Александр Тарасов aka oioki
Дата перевода: 9 декабря 2008
В предыдущей статье для сайта Linux Journal я рассказывал о веб-скрипте, выполняющем SQL-запрос к базе данных и на основе полученных данных создающем Excel-файл. Та статья была основана на программе, которую я писал для клиента. Сегодня я хочу рассказать о прямо противоположной задаче; наша программа будет принимать на входе таблицу Excel, извлекать из нее данные и вводить ее в базу данных. Эта программа также основана на программе для одного из моих клиентов. В общем, обе программы были написаны для одного и того же клиента.
Раньше этот мой клиент загружал данные в базу данных через обычный текстовый файл. Они работали со своими данными в Excel, а затем, когда требовалось положить эти данные в базу, делали экспорт. Однако у них были сложности в запоминании, разделяются ли их данные запятыми или табами. Одно лишь это было проблемой. К тому же не единственной.
Данные, разделенные точками с запятой легко прочесть в текстовом редакторе, и к тому же с ними просто работать с точки зрения программирования. Этот формат хорош для хранения большинства типов данных, таких как имена или номера телефонов. Для большинства, но не для всех. К примеру, формат с разделением полей запятыми хорош для хранения сведений о моем друге:
John,Q,Public,15055551234
Очевидно, что мы храним здесь имя, первую букву отчества, фамилию и телефонный номер. Но такой формат не очень хорош для хранения сведений о сыне моего друга, его зовут John Q. Public, Jr:
John,Q,Public, Jr.,15055551234
Возможно, формат с разделением полей табами был бы более удобен:
John Q Public, Jr. 15055551234
Но так кажется лишь на первый взгляд. При вводе данных я ошибся и напечатал после имени не таб, а пробел. Вы его видите? Нет, и я тоже, но он есть и в дальнейшем обязательно приведет к некорректной работе обрабатывающей эти данные программы.
Наконец, что если у нас будет много-много полей? Формат с разделением табами будет выглядеть в редакторе чрезвычайно громоздко.
Так что хранить данные в формате Excel - хороший выбор. Вам может показаться, что я преувеличиваю, но у одного моего клиента постоянно возникали именно такие проблемы, это не шутка. Поэтому я решил пользоваться форматом Excel для ввода и вывода данных. Это было удобно для моего клиента, ведь он был знаком с обработкой данных в Excel, а я мог протестировать скрипты в OpenOffice Calc.
Единственный момент, о котором нужно договориться - это то, какие столбцы содержат какие данные. Однако мы напишем в программе немного кода, который бы автоматически распознавал это.
В этой статье будет приведен пример сценария, демонстрирующего возможности использования Perl-модуля Spreadsheet::ParseExcel.
Для демонстрации представим, что есть какие-то люди, которые ходят по школам и собирают информацию об учениках. Мы будет хранить полное имя и телефонный номер. Также мы хотим знать, в какой школе ребенок учится, и какая у него средняя оценка (от высшей A до F). Если средняя оценка A, тогда нужно раскрасить его ячейку в зеленый цвет; если же это плохой ученик, и его средняя оценка F, раскрасим его в красный. Для каждой школы имеется свой лист, названный по номеру школы. Очевидно, этот метод не очень эффективен, но как я уже сказал, этот вымышленный пример лишь демонстрирует нам возможности упомянутого модуля Perl.
Задачей демонстрации является получение исходных данных из таблицы, получение номеров всех школ из названий листов и получение информации о форматировании каждой ячейки таблицы. После того, как вы поймете, как именно это должно быть сделано, можно начинать пользоваться модулем и писать программу.
Для начала создадим базу данных, в которой мы будем хранить результаты выборки. Потребуется лишь одна таблица, вот такая:
drop table children;
create table children (
name varchar(50),
phone char(11),
school varchar(50),
code char(6)
);
Знаю, varchar(50) на имя ребенка и его школу - возможно, многовато. Обратите внимание на поле code типа char(6). В этом поле будет храниться цветовая информация, в шестнадцатиричном формате RRGGBB.
Теперь, когда у нас есть база данных, нам потребуется веб-форма для загрузки наших данных. Такой простой формы будет вполне достаточно:
<html> <head> <title>Страница загрузки данных</title> </head> <body> Загрузка данных <form name=main method=POST action=/cgi-bin/load.pl ENCTYPE="multipart/form-data"> <input type=file name=file> <input type=submit> </form> </body> </html>
Нужно сохранить этот код в html-файл куда-нибудь на веб-сервер. Тогда нашим пользователям будет достаточно открыть нужный URL-адрес с формой в веб-браузере, и они смогут загружать туда свои данные из файлов Excel в нашу базу данных.
Теперь нужно немного данных. Взгляните на следующие снимки.
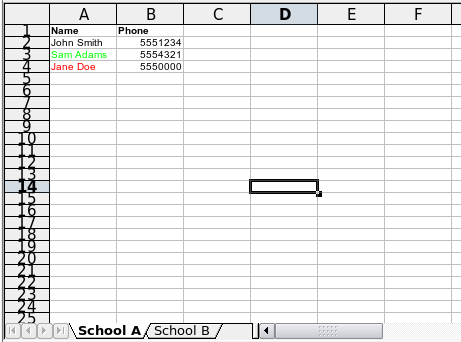
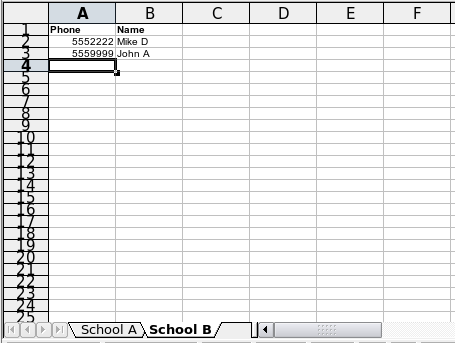
Кажется, все нормально, но столбцы перемешаны. Для школы A столбцы расположены в другом порядке, нежели для школы B. Лучше решать эту неувязку в нашей программе, чем заставлять пользователей что-либо править. В общем, у нас есть данные для школ A и B. Очевидно. что один из наших учеников - отличник (средняя оценка A), а другой - двоечник (оцена F). Остальных можно назвать нормальными учениками.
Давайте уже перейдем к программе.
Эта программа достаточно сложна, поэтому будем разобъем ее на части и рассмотрим их отдельно.
Сначала идут обычные команды:
==================================================
#!/usr/bin/perl
use DBI;
use CGI;
use Spreadsheet::ParseExcel;
$cgi = new CGI;
$dbh = DBI->connect("dbi:Pg:dbname=test;host=db.example.com", "postgres", "password") ||
die "Can't connect to database.\n";
$file = $cgi->param("file");
$workbook = Spreadsheet::ParseExcel::Workbook->Parse($cgi->param("file"));
==================================================
Как вы видите, этот код почти такой же, как и в программе из предыдущей статьи. Я не пользуюсь опциями Perl "-w" или "use strict", потому что эта программа работает и выдает правильный результат, и мне неинтересно, что какие-то переменные неинициализированы и т.п. вещи; меня интересуют лишь результаты работы программы.
Итак, в этом куске кода мы создаем объекты CGI, DBI и Spreadsheet::ParseExcel.
В данном случае конструктору объекта Spreadsheet::ParseExcel передается идентификатор файла из объекта CGI.
Идем дальше:
==================================================
foreach $sheet (@{$workbook->{Worksheet}}) {
foreach $col ($sheet->{MinCol} .. $sheet->{MaxCol}) {
if ($sheet->{Cells}[0][$col]->{Val} eq "Name") {
$name = $col;
}
if ($sheet->{Cells}[0][$col]->{Val} eq "Phone") {
$phone = $col;
}
}
==================================================
В этом куске кода мы запускаем цикл по всем листам рабочей книги. Затем в каждом листе мы ищем, в каком столбце хранятся имена (строка "Name"), а в каком номера телефонов (строка "Phone"). Теперь мы знаем, где хранятся наши данные, мы готовы к обработке данных.
==================================================
foreach $row ($sheet->{MinRow}+1 .. $sheet->{MaxRow}) {
$child_name = $sheet->{Cells}[$row][$name]->{Val};
$child_phone = $sheet->{Cells}[$row][$phone]->{Val};
$child_school = $sheet->{Name};
$child_code = Spreadsheet::ParseExcel->ColorIdxToRGB(
$sheet->{Cells}[$row][$name]->{Format}->{Font}->{Color});
==================================================
В этом блоке пробегаем по всем строкам, так же, как мы пробегали до этого по столбцам. Естественно, в этот раз мы пропускаем заголовок таблицы. Затем мы считываем через объекта $sheet содержимое ячеек: имя ученика в переменную $child_name, номер телефона - в $child_phone. Затем получаем название школы $child_school из названия листа.
Наконец, считываем информацию $child_code о цветовом форматировании ячейки, содержащей имя.
==================================================
$dbh->do("insert into children (name,phone,school,code) values
(\'$child_name\', \'$child_phone\',
\'$child_school\', \'$child_code\')");
}
}
==================================================
Далее, вставляем данные в базу данных.
================================================== print $cgi->header(); print <<EOF <html> <head> <title>File Has Been Uploaded </head> <body> Thank You. </body> </html> EOF ; exit; ==================================================
Наконец, нужно сообщить пользователю, что требуемые данные были успешно помещены в базу данных. Как видите, здесь нет ничего хитрого. На самом деле в реальной работе было бы здорово собрать статистику по выполненной работе, и проанализировав ее, сообщить, что ошибок не было обнаружено. Но для нашего простого примера этого вполне достаточно.
Теперь данные введены, и мы для проверки можем создать демонстрирующий это SQL-запрос.
Результат выполнения запроса select * from children; следующий:
name | phone | school | code
------------+-------------+----------+--------
John Smith | 5551234 | School A | 000000
Sam Adams | 5554321 | School A | 00FF00
Jane Doe | 5550000 | School A | FF0000
Mike D | 5552222 | School B | 000000
John A | 5559999 | School B | 000000
(5 rows)
Это именно то, что мы ожидали.
Итак, с помощью модуля Spreadsheet::ParseExcel, мы минимизировали риск неверной обработки данных, и в то же время пользователям не придется работать с экзотическими форматами. Нам как программистам тоже хорошо - все работает, и данные успешно помещаются в базу данных.
Я привел простой пример решения выдуманной задачи, но, надеюсь, она сполна демонстрирует легкость обращения с Excel-файлами в Perl.