Библиотека сайта rus-linux.net
Языки, символы и кодировки.
Here is the whole set! a character dead at every word.
- Richard Brinsley Sheridan, The School for Scandal,
Act 2, scene 2
Language
Информация, полученная из "человеческого" мира и предназначенная для машинной обработки, как правило имеет специальный арибут : язык или language (lang). Причем, не только текстовая, но например audio :
Content-Description: Russian Argo audio sample :-) Content-Type: audio/basic Content-Language: ru
Однако нас инересует именно текстовая информация.
Большинство языков мира имеют письменнось, а некоторые языки даже несколько (например кириллица и глаголица для славянских языков или kana и kanji в японском и т.д.). Определенная система письменности называется script. Системы письменности существуют самые разнообразные (например узелковое :-), но большинство письменностей - это изображение последовательности специальных символов (character).
* ПРИМЕЧАНИЕ : Объяснение концепции символа выходит далеко за рамки данного документа. Мы не будем вдаваться в филологические и философские подробности, а рассмотрим лишь узкий аспект -- способы представления символов (национального) языка для автоматической (машинной) обработки. Тогда термин "символ" (character) можно определить как "единицу текстовой информации" (unit of textual information), которая передается письменно и участвует в машинной обрабоке. Очень важно четко представлять себе, что речь идет об "абстрактном" символе.
Character
Каждый "абстрактный" символ
имеет изображение -- glyph. Считается, что
каждый символ имеет "каноническое"
изображение , то есть такое, которое позволяет однозначно
идентифицировать данный символ, то есть
распознать и отличить его от других. Таким
образом, в модели POSIX и UNICODE не
уделяется никакого внимания вариантам
начертания символа, то есть шрифтам (fonts)
во всем их многообразии, . Поэтому все, что
изображено на примере ниже, будет одним и тем же
"абстрактным" символом :
ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА А (LATIN CAPITAL
LETTER A):
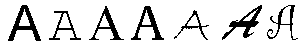
В стандарте UNICODE кроме определенного изображения каждому символу присвоено определенное имя :
| UNICODE | Character Name | |
|---|---|---|
| A | U+0041 | LATIN CAPITAL LETTER A |
| a | U+0061 |
LATIN SMALL LETTER A |
| Ю | U+042E |
CYRILLIC CAPITAL LETTER YU |
| 1 | U+0031 |
DIGIT ONE |
| + | U+002B |
PLUS SIGN |
U+03A9 |
GREEK CAPITAL LETTER OMEGA | |
|
U+2569 |
BOX DRAWINGS DOUBLE UP AND HORIZONTAL |
| и так далее. |
В настоящее время в стандарт UNICODE, входят практчески все употребимые символы (~40.000), и им соответственно присвоены стандартные имена. Последнее значительное изменение -- введение символа валюты EURO в сентябре 1998 г.
Посмотреть набор символов UNICODE можно здесь : http://charts.unicode.org/ .
Таким образом, для нас символ (character) - это единица тектовой информации, имеющая определенное изображение и определенное имя.
Encoding.
Наиболее важным понятием при обработке символов является понятие Coded Character Set (CCS).
Давайте попробуем разобраться, что это такое.
Как мы уже ранее выяснили, существуют определенные "наборы символов" для каждого конкретного языка (алфавит). Набор таких "абстрактных" символов называется character repertoire.
Для автоматической обработки, хранения и передачи символов необходимо каждый "абстрактный" символ перевести в числовую форму для размещения в ячейках ЭВМ.
C "программистской" точки зрения это задача совершенно тривиальна. Нужно просто присвоить каждому символу (абстрактному !) определенное число, которое и хранить в памяти ЭВМ, то есть закодировать символ. Другими словами, определить схему кодирования : CES "character encoding scheme". Например, условимся, что символу 'A' - LATIN CAPITAL LETTER A соответствует число (код) 61. И наоборот, условимся , что число (integer) 61 будет означать ни что иное, как символ 'A'. Таким образом образуется пара (61, 'A') код - символ. И наоборот, символ - код. Соответствие однозначное.
Пусть у нас теперь есть набор символов : character repertoire {'A','B','C'} (это маленькое подмножество символов латинского алфавита). Продолжим кодирование. Тогда из этого множества {'A','B','C'} у нас образуется множество пар : {(61,'A'),(62,'B'),(63,'C')}.
А теперь внимание ! Вот это самое пресловутое "множество пар" имеет колоссальное значение ! Формально оно называется CCS : coded character set. Именно ему присваивается имя : ASCII, ISO_8859-5 или KOI8-R ! Перечитать еще раз !
Давайте рассмотрим подробнее. Итак :
| 'A' | - это абстрактный символ, "character" |
| набор символов {'A','B','C'} | - "character repertoire" |
| соответствие : символ 'A' <--> число 61 | - это CES "character encoding scheme", или просто encoding |
| число 61 | - это "code point". |
| набор чисел {61,62,63} | - это "codeset" или "code space". |
| набор пар {(61,'A'),(62,'B'),(63,'C')} | - это CCS "coded character set", или сокращенно charset. |
Что собой представляет CCS ?
Фактически, CCS можно рассматривать как базу данных, в которой хранятся a)символы, b)коды и c)схема соответствия символов и кодов (CES - character encoding scheme) например в виде обычной таблицы - map (charmap). Тогда допустимы операции :
CES('A')=61
CES(61)='A'
Фактически это будет обозначать операции выборки из "базы" :
SELECT CODE FROM CCS WHERE CHAR='A' SELECT CHAR FROM CCS WHERE CODE=61
Естественно, CCS-ов существует огромное множество : ASCII, KOI8-R, ISO_8859-1 или даже UNICODE. И конечно же каждому CCS соответствует его специфицеская CES.
Как работает CCS ?
Очень просто. Пусть у нас есть поток
символов ("абстрактных") : "ABBACABCC".
Тогда применение CCS к этому потоку
(тексту) "ABBACABCC" будет равно применению его CES
к каждому символу в потоке :
CES('A') CES('B') CES('B') CES('A')...
и мы получим поток чисел (кодов) : 61 62 62 61
63 61 62 63 63.
Аналогично, применение CCS к потоку кодов
даст поток "абстрактных символов".
Отсюда следует один очень простой вывод : при хранении текста (потока символов) мы должны также хранить CCS ! А вот где его хранить - это вопрос. Можно в том же потоке ( "In-band" или "MARK-UP" способ). Можно где-то снаружи потока ("Out-band" способ). Можно хранить лишь имя (ссылку на) CCS.
К сожалению, в стандартном POSIX (например на stdin/stdout) мы имеем только потоки кодов. А вся информация о CCS потеряна. Подробнее про это можно прочитать в статье о локализации POSIX.
СharSets
Давайте теперь рассмотрим собственно наборы символов (character set). Первое что мы должны сделать - это обратить внимание на терминологию. Если мы говорим о наборе "абстрактных" символов, то употребляется термин character repertoire. Если же мы говорим о наборе символов вместе с их кодами и схемой преобразования символ<-->код, то речь идет о CCS : coded character set. Именно этому набору : coded character set и присваивается имя : KOI8-R, ISO_8859-1, ASCII. Иногда термин CCS сокращают до сharset.
Так например в стандарте MIME
употребляется термин сharset, хотя
подразумевается конечно же CCS:
Content-Type: text/plain; charset=koi8-r
Content-Type: text/plain; charset=Windows-1251
Content-Type: text/plain; charset=ibm-866
Как определяется character repertoire для определенного charset ?
Чаще всего набор символов определяется из языка (lang) и соответствующей ему системы письменности (script). Иногда рассматривается набор символов, воспризводимый конкретной аппаратурой ( например DEC VT-100 Character Set).
Иногда конкретный набор символов является подмножеством другого, более обширного набора символов или же комбинацией нескольких наборов (или их частей). Например, широко распространенный набор символов для представления русского языка : KOI8-R, содержит в себе символы из наборов LATIN, CYRILLIC, BOX DRAWING, BLOCK ELEMENT и т.д.. А конкурирующий с ним charset - Windows-1251 содержит больше символов из набора CYRILLIC (русские, украинские, белорусские), но меньше - из BOX и BLOCK. Кроме того в KOI8-R нет например символа EURO.

Старшая половина charset (CCS) KOI8-R и code points символов.
Младшая половина совпадает с US-ASCII.
(см. также описние KOI8-R в формате
POSIX.)
Существует минимальный (переносимый) (POSIX) Portable Charset - набор символов, который должны поддерживать любые информационные системы (определен в стандарте ISO 646) (он же ASCII). С другой стороны, существует также "универсальный" Universal Character Set (UCS, UNICODE) включающий в себя все возможные символы человеческих языков, технические, картографические и т.д. символы (~40.000 символов) (ISO 10646). Также, для примера, можно упомянуть один из довольно широко распространенных наборов символов : LATIN-1 (Czyborra ISO 8859-1).
Каждый charset имеет определенное имя.
Теперь насчет кодирования. Каким образом выбирается CES ?
Выполнить "кодирование" (encoding) довольно легко как для латинских так и для всех (?) индоевропейских языков (фонетическое письмо). Действительно, закодировать 26 латинских (ASCII) или 33 русских буквы не составляет труда (даже в варианте заглавных и прописных, плюс цифры, плюс знаки препинания). Количество символов (character repertoire) мало, соответственно не велико и code space и получается меньше 256 сode points, что позволяет уместить их в один байт (2^8=256 различных кодовых позиций).
Для языков, чья письменность построена по идеографическому (иероглифическому) принципу, ситуация несколько сложнее. Например в современном японском 1850 "официальных" иероглифов, тогда как в китайском их число доходит до 5000. Одного байта мало. Необходимы обширные CCS, например EUC-JP или UNICODE. Для поддержки таких языков в POSIX введены механизмы Multibyte и Wide Class chars.
В настоящее время в подавляющем большинстве charset-ов применяется 8-ми битное (байтовое) кодирование. Все настолько к этому привыкли, что charset-ы c большим количеством символов (>256) иногда называют large charset.
Проблемы могут возникнуть лишь при необходимости создания многоязычных текстов, например русско-японско-английских, или содержащих русский и иврит, e.t.c. В этом случае - практически единственное решение : UNICODE.
Также проблемы возникают в том случае, если заранее неизвестна кодировка текста (потеряна CES), так как в UNIX, да и в других OS файл не имеет никаких дополнительных атрибутов. Это также актуально для HTTP, в том случае, если кодировка (CES) файла .HTML неизвестна. Это довольно неудобно, поскольку часто единственный способ - это подбор подходящей кодировки... Вывод : указывать кодировку необходимо.
Standarts
Существует несколько стандартов описания сharset и способов их кодирования :
- RFC-1345 Character Mnemonics & Character Sets
- POSIX Character Set Definition File
- ISO 2022
- ISO 9945-2
- UNICODE (ISO10646) UCS-2, UTF-7, UTF-8
- (???)
Описание наборов символов KOI8-R, CP1251, IBM866 в формате POSIX.
Что касается имен зарегистрированных Charset-ов, то смотри здесь.
POSIX
Сначала - немного критики...
Теперь по делу.
Для установки в POSIX-системе новой locale c другим набором символов (charset) применяется утилита localedef для компиляции Файла Описания Локализации и Файла Описания Набора Символов (Character Set Description File).
$ localedef -c -i ru_RU -f KOI8-R ru_RU.KOI8-R
Для проверки установленных в POSIX-системе charset-ов применяется утилита locale :
$ locale -m $ locale charmap
Для преобразования потока символов из одного charset в другой, в стандарте POSIX существуют утилита iconv и функция iconv().
В системе Plan 9 существует утилита tcs.
Содержание "Locale AS IT IS"