





Библиотека сайта rus-linux.net
Что каждый программист должен знать о памяти, часть 7. Инструменты для повышения производительности памяти
Оригинал: Memory part 7: Memory performance toolsАвтор: Ulrich Drepper
Дата публикации: ноябрь 2007 г.
Перевод: М.Ульянов
Дата перевода: 5 мая 2010 г.
Инструменты для повышения производительности памяти
Существует множество инструментов, помогающих программисту понять, как программа использует кэш и память. Современные процессоры позволяют оценивать производительность на аппаратном уровне. Но некоторые вещи не измеришь напрямую, поэтому нельзя отказаться и от программного моделирования. На верхнем функциональном уровне также имеются специальные инструменты контроля за выполнением процесса. Далее представлен набор широко используемых средств, доступных на большинстве Linux-систем.
7.3 Оценка использования памяти
Первый шаг к оптимизации использования памяти - узнать, сколько памяти выделяет для себя программа и, если возможно, где именно (в каком месте кода). К счастью, для данной цели существуют простые в применении утилиты, даже не требующие рекомпиляции или какой-либо модификации испытуемой программы.
Для первого такого инструмента, massif, важно не удалять информацию отладки, автоматически генерируемую компилятором. Данная утилита предоставляет обзор использования памяти за некоторый период времени. На рисунке 7.7 показан пример выходных данных.
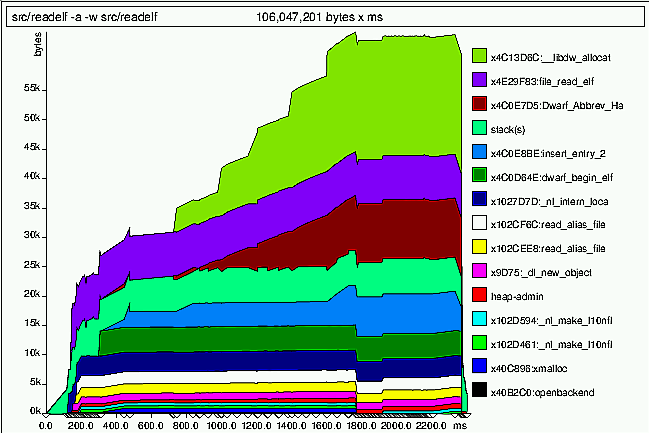
Рисунок 7.7. Выходные данные massif
Как и cachegrind (раздел 7.2), massif использует инструментарий valgrind. Запускается через
valgrind --tool=massif command arg
где command arg - наблюдаемая программа и ее параметр(ы). В процессе моделирования работы распознаются все вызовы функций выделения памяти. Место и время каждого вызова записываются; выделенный объем памяти добавляется к памяти, выделенной предыдущими вызовами из этого же места, а также к общему объему памяти всей программы. По тому же алгоритму обрабатываются и функции, освобождающие память, только, естественно, наоборот: размер освобожденного блока вычитается из соответствующих суммарных объемов. В дальнейшем собранная таким образом информация может быть использована для построения диаграммы, описывающей использование памяти за весь жизненный цикл программы и устанавливающей соответствие каждого момента времени месту кода, откуда было вызвано выделение памяти. Перед завершением процесса, massif создает два файла: massif.XXXXX.txt и massif.XXXXX.ps, где XXXXX в обоих случаях - идентификатор процесса (PID). Файл .txt содержит суммарную информацию по использованию памяти для всех мест вызова, а .ps вы видите на рисунке 7.7.
Также massif может контролировать использование стека программой, что может помочь определить общий объем памяти, которую занимает программа. Но иногда это невозможно. Бывает, что valgrind не может определить границы стека - например, когда используется signaltstack или стеки потоков. В таких случаях не имеет смысла добавлять размеры этих стеков к общей сумме. Есть и другие примеры, когда контролировать стек бессмысленно. В любом из этих случаев massif следует запускать с дополнительным параметром --stacks=no. Обратите внимание, это параметр valgrind, и поэтому он ставится перед именем испытуемой программы.
В некоторых программах используются их собственные функции выделения памяти, либо т.н. "интерфейсные" функции, предоставляющие интерфейс вызова системных функций выделения памяти. В первом случае выделение памяти проходит незамеченным; во втором - записанные места вызова несут дезинформацию, поскольку записывается адрес вызова внутри интерфейсной функции, а не адрес самой этой функции. В связи с этим, существует возможность дополнять список функций выделения памяти дополнительными функциями. Параметр --alloc-fn=xmalloc говорит программе, что xmalloc - тоже функция выделения памяти, что нередко в программах GNU. Тогда будут записываться вызовы самой xmalloc, а не вызовы выделения памяти изнутри нее.
Вторая утилита - memusage; это часть библиотеки GNU C. Представляет собой упрощенную версию massif (и существовавшая задолго до появления последней). Всё, что она контролирует - общий объем памяти, выделенной из кучи (включая возможные вызовы mmap и им подобных, если используется параметр -m), и, при необходимости, использование стека. Результаты могут быть показаны в виде диаграммы либо общего использования памяти за время работы, либо в виде разбиения по вызовам функций выделения памяти. Диаграммы создаются по отдельности сценарием memusage, который (как и valgrind), необходимо использовать для запуска приложения:
memusage command arg
При использовании параметра -p IMGFILE диаграмма будет создана в файле IMGFILE с расширением PNG. Код, собирающий информацию, запускается прямо в самой программе, это не моделирование, в отличие от valgrind. Следовательно, memusage гораздо быстрее, чем massif, и используется даже тогда, когда утилита massif бесполезна. Помимо суммарного потребления памяти, программа также записывает размеры выделенной памяти при каждом вызове и выводит их в виде гистограммы. Эта информация также показывается при возникновении ошибки.
Иногда программу, которую нужно исследовать, невозможно (или запрещено) запускать напрямую. Например, стадия компиляции gcc, запускаемая драйвером gcc. В таких случаях имя исследуемой программы необходимо предоставить сценарию memusage, передав его через параметр -n NAME. Также этот параметр полезен, если исследуемая программа запускает другие программы. В случае, когда имя программы не указано, профилированию подвергаются все запускаемые приложения.
У обеих утилит, massif и memusage, есть дополнительные параметры. Когда программисту нужна дополнительная функциональность, сперва стоит прочесть мануал или справку, дабы убедиться, не реализована ли уже данная функциональность.
Теперь мы знаем, каким образом собираются данные касательно выделения памяти, и далее необходимо обсудить, как эти данные можно интерпретировать в контексте использования памяти и кэша. Главные моменты эффективного динамического распределения памяти - последовательное выделение и компактность выделенной области памяти. Таким образом мы возвращаемся к повышению эффективности предвыборки и снижению количества промахов кэша.
Когда программе нужно считать некоторое количество данных для последующей обработки, это можно организовать, создав список, каждый элемент которого содержит новый элемент данных. Потери при таком методе выделения памяти теоретически должны быть минимальны (один указатель для простого связанного списка), но на деле использование таких данных кэшем может чрезвычайно снизить производительность.
Например, одна из проблем - нет никаких гарантий, что последовательно выделенная память окажется в лежащих рядом областях. Тому есть множество возможных причин:
- адреса блоков памяти внутри большого участка, управляемого распределителем памяти, возвращаются от конца к началу;
- свободное место на участке памяти заканчивается, и происходит переход к новому участку, в совсем другой области адресного пространства;
- запросы на выделение разных объемов памяти обслуживаются разными пулами памяти;
- чередование выделений памяти разными потоками многопоточных приложений.
Если нужно распределить память для данных заранее для будущей обработки, применение связанного списка - явно плохая идея. Нет никакой гарантии (и даже вероятности), что соседние элементы списка окажутся соседними и в памяти. Для гарантии смежности выделенных областей память ни в коем случае нельзя распределять мелкими участками. Необходимо использовать другой слой работы с памятью; и программист легко может его применить. Я имею в виду реализацию obstack, доступную в библиотеке GNU C. Этот распределитель запрашивает большие блоки памяти у системного распределителя и затем уже из этих блоков выделяет произвольные области, маленькие или не очень. Области, выделяемые таким образом, всегда будут расположены последовательно, если только не закончится место в том самом большом блоке. Что, учитывая объемы, запрашиваемые на выделение, происходит довольно редко. Применение obstack не означает полный отказ от стандартного распределителя памяти, поскольку obstack ограничен в возможностях освобождения объектов. Подробнее см. руководство к библиотеке GNU C.
Итак, каким же образом, используя диаграммы, можно понять, где лучше использовать obstack (или другие подобные приемы)? Точное место возможной оптимизации нельзя определить, не обратившись к исходникам, но диаграмма помогает выбрать отправную точку для поисков. Если из одного и того же места происходит много запросов на выделение памяти, значит, тут может помочь выделение большого блока (см.obstack). На рисунке 7.7 вероятный кандидат на оптимизацию наблюдается по адресу 0x4c0e7d5. На промежутке от 800мс и до 1800мс с начала работы это единственная растущая область, ну за исключением верхней, зеленой. Более того, возрастание не резкое - значит, имеем дело с большим числом выделений относительно малых объемов памяти. Вне всяких сомнений, это наш кандидат на применение технологии obstack или ей подобных.
Другая проблема, которую помогают увидеть диаграммы - слишком большое суммарное число попыток выделения памяти. Особенно легко это заметить, если диаграмма строится в зависимости не от времени, а от количества вызовов (установлено по умолчанию в memusage). В этом случае пологий склон диаграммы означает большое количество выделений малых объемов памяти. Утилита memusage не может сказать, где именно происходят запросы выделения, но это "лечится" сравнением с выводом massif, а иногда программист и сам сразу может определить проблемное место. Множество мелких запросов выделения памяти следует объединить, чтобы достичь последовательного использования памяти.
Касательно последнего случая есть еще один момент, не менее важный: множество небольших выделений приводит к увеличению административной (управляющей) информации. Само по себе это не страшно. На диаграмме вывода massif (рис.7.7) область такой информации называется "heap-admin" и она довольно мала. Но в зависимости от реализаций malloc эта административная информация может выделяться вместе с блоками данных, в той же области памяти. Что сейчас и имеет место в текущей реализации malloc в библиотеке GNU C: каждый выделенный блок начинается с двухсловного (минимум) заголовка: 8 байт для 32-битных платформ, 16 байт для 64-битных. К тому же, размеры блоков обычно немного больше, чем нужно, из-за особенностей управления памятью (размеры блоков округляются до определенных значений).
Всё вышесказанное означает, что память, используемая программой, смешивается с памятью, используемой распределителем исключительно для административных целей. И мы получаем что-то вроде этого:

Каждый блок представляет собой одно слово (word) памяти и всего на этой небольшой области мы видим четыре выделенных блока. Заголовки и заполнение незначащей информацией привели к издержкам (потерям полезного места) в 50%. Такое расположение заголовка автоматически снижает коэффициент эффективной предвыборки процессора на те же 50%. Если бы блоки обрабатывались последовательно (для получения максимальной пользы от предвыборки), процессор бы считал все слова, содержащие заголовки и заполнители, в кэш, несмотря на то что само приложение никогда не будет к ним обращаться ни для записи, ни для чтения. Заголовки используются только средой выполнения, а она вступает в дело только при освобождении блока памяти.
Можно прийти к выводу, что следует использовать другую реализацию, дабы поместить административную информацию отдельно. Несомненно, в некоторых реализациях так и делается, и это может быть полезно. Но при этом необходимо помнить о множестве нюансов, и не в самую последнюю очередь - о безопасности. Независимо от того, к чему мы придем в будущем, проблема заполнения блоков [незначащей информацией] никогда не исчезнет (а одни эти "пустышки", без учета заголовков, занимают 16% всего объема памяти в нашем примере). Этого можно избежать только если программист возьмет на себя прямой контроль за выделением памяти. "Пустышки" также могут появиться в связи с требованиями выравнивания памяти, но и этот момент - во власти программиста.
| Назад | Оглавление | Вперед |