





Библиотека сайта rus-linux.net
Что каждый программист должен знать о памяти. Часть 6: На что еще способны программисты
Оригинал: Memory, part 6: More things programmers can doАвтор: Ulrich Drepper
Дата публикации: October 31, 2007
Перевод: М.Ульянов
Дата перевода: февраль 2010 г.
6.4.3 Решаем проблемы с пропускной способностью
Использование множества потоков, корректно работающих с кэшем (т.е. исключающих попытки доступа к одной и той же кэш-строке разными ядрами, приводящие к конфликту), не гарантирует отсутствия других проблем. Полоса пропускания канала между процессором и памятью имеет ограниченную ширину, которая к тому же делится между всеми ядрами и гиперпотоками данного процессора. А в зависимости от архитектуры (пример - рисунок 2.1), несколько процессоров также могут иметь общую шину памяти или северного моста.
Ядра современных процессоров работают на таких частотах, что даже работая на максимальной скорости и в идеальных условиях, соединение с памятью не позволяет обслуживать без задержек все запросы считывания и записи. А теперь вдобавок к этому разделите всю полосу пропускания на количество ядер, гиперпотоков и процессоров с общим доступом к северному мосту, и станет ясно, почему многопоточность внезапно может привести к серьезным проблемам. Производительность программ, в теории очень эффективных, на практике может быть ограничена пропускной способностью памяти.
На рисунке 3.32 мы видели, что повышение скорости шины процессора очень помогает в таких случаях. Поэтому с ростом количества ядер в процессорах наблюдается и увеличение скорости системной шины. Однако этого часто недостаточно, особенно если программа использует большие рабочие множества и недостаточно оптимизирована. Поэтому программист должен быть всегда готов распознать проблемы, связанные с пропускной способностью.
Счетчики производительности современных процессоров позволяют следить за загрузкой системной шины. Например, событие NUS_BNR_DRV процессоров Core 2 подсчитывает количество холостых тактов ядра, произошедших по причине неготовности шины. Это показывает, что шина перегружена и операции считывания/записи в основную память выполняются медленнее обычного. Процессорами Core 2 поддерживаются и другие события, позволяющие подсчитывать различные показатели, например запросы RFO или общую загрузку шины. Последнее, например, будет кстати, если при разработке приложения потребуется исследовать возможность его масштабируемости. Ясно, что когда уровень загрузки шины уже близок к единице, возможности масштабирования минимальны.
Допустим, диагноз ясен - проблема с пропускной способностью. Для ее решения существует несколько способов. Иногда они взаимоисключают друг друга, так что, быть может, придется поэкспериментировать. Ну, например, одно из решений - купить более быстрый компьютер, если такой существует. Поскольку это означает рост скорости системной шины и модулей памяти, а также возможное увеличение объема локальной памяти процессора, то такой способ может помочь - да и действительно, чаще всего помогает. Однако, подобное может влететь в копеечку. Конечно, если проблемная программа будет использоваться лишь на одной машине (или на небольшом их количестве), то разовая трата на оборудование может оказаться меньше, чем затраты на переработку программы. Но в абсолютном большинстве случаев лучше таки переделать программу.
Оптимизировав программу во избежание промахов кэша, остается лишь одна возможность уменьшить загрузку полосы пропускания - правильно распределить потоки по доступным ядрам. По умолчанию, планировщик в ядре распределяет потоки в соответствии со своей политикой. Перемещение потока между ядрами по возможности избегается. Тем не менее, планировщик ведь ничего не знает о рабочей нагрузке. Да, он может собирать информацию о промахах кэша и прочем, но в большинстве случаев это малоэффективно.
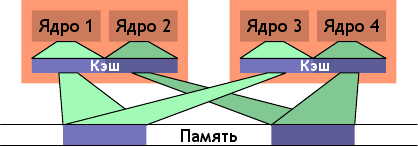
Рисунок 6.13: Нерациональное планирование
Один из вариантов, приводящих к большой загрузке шины - когда два потока выполняются на разных процессорах (или ядрах с разделенным кэшем), но используют при этом один и тот же набор данных. Такая ситуация показана на рисунке 6.13. Ядра 1 и 3 используют одни и те же данные (указатели доступа и области памяти показаны одним цветом). Аналогично для ядер 2 и 4. Но потоки распределены по разным процессорам. То есть каждый набор данных необходимо будет считать из памяти дважды. Эту ситуацию можно исправить.

Рисунок 6.14: Рациональное планирование
На рисунке 6.14 показано, как оно должно выглядеть в идеале. Общий размер используемого кэша уменьшен, так как пары ядер 1 + 2 и ядер 3 + 4 работают каждая со своим набором данных. Соответственно, наборы данных придется считать из памяти всего по разу.
Простой пример, конечно, но данный принцип действительно применим во многих ситуациях. Как упоминалось выше, планировщик в ядре не вникает в суть использования данных, поэтому на плечи программиста ложится задача - гарантировать эффективность планирования. Есть не так уж много интерфейсов ядра, с помощью которых можно выполнить это требование. Фактически, способ только один: использовать привязку потоков.
Под привязкой потоков понимается назначение потока одному или нескольким ядрам. И тогда, если планировщику будет необходимо решить, где запускать поток, он будет выбирать только из этих заданных ядер. Даже если другие ядра свободны, они не будут рассматриваться вообще. Это может показаться недостатком, но ведь всему есть своя цена. Если слишком много потоков привязано к конкретному набору ядер, то другие ядра будут частенько простаивать, и исправить такую ситуацию можно только поменяв привязку. По умолчанию привязка отсутствует, то есть потоки могут выполняться на любом ядре.
Интерфейсы, использующиеся для запросов о привязке и ее изменений, описаны ниже.
#define _GNU_SOURCE #include <sched.h> int sched_setaffinity(pid_t pid, size_t size, const cpu_set_t *cpuset); int sched_getaffinity(pid_t pid, size_t size, cpu_set_t *cpuset);
Эти два интерфейса используются в однопоточном коде. Аргумент pid определяет, привязку какого процесса следует установить или изменить. Естественно, для вызова необходимы соответствующие привилегии. Второй и третий параметры определяют битовую маску для ядер. Первая функция требует заполненную битовую маску для того, чтобы установить привязку. Вторая - заполняет битовую маску информацией о распределении (привязке) выбранного потока. Оба интерфейса объявлены в заголовочном файле <sched.h>.
В том же файле объявлен тип cpu_set_t, а с ним и соответствующие макросы для управления и использования объектов данного типа.
#define _GNU_SOURCE #include <sched.h> #define CPU_SETSIZE #define CPU_SET(cpu, cpusetp) #define CPU_CLR(cpu, cpusetp) #define CPU_ZERO(cpusetp) #define CPU_ISSET(cpu, cpusetp) #define CPU_COUNT(cpusetp)
Константа CPU_SETSIZE определяет максимальное количество процессоров, которое может быть представлено в структуре данных. Следующая тройка макросов используется для управления объектами cpu_set_t. CPU_ZERO инициализирует объект, а оставшаяся пара используется соответственно для включения во множество и исключения из него отдельных ядер либо процессоров. CPU_ISSET проверяет, входит ли процессор во множество, а CPU_COUNT возвращает текущее их количество во множестве. Максимальное число процессоров в cpu_set_t, установленное по умолчанию, вполне достаточно для работы. Но со временем, несомненно, этого станет мало, и придется вносить правки. В процессе написания программы всегда необходимо помнить об этом ограничении. Вышеприведенные макросы удобны, но, в соответствии с описанием cpu_set_t, управляют размером множества лишь косвенно. Для более динамичного управления следует использовать расширенный набор макросов:
#define _GNU_SOURCE #include <sched.h> #define CPU_SET_S(cpu, setsize, cpusetp) #define CPU_CLR_S(cpu, setsize, cpusetp) #define CPU_ZERO_S(setsize, cpusetp) #define CPU_ISSET_S(cpu, setsize, cpusetp) #define CPU_COUNT_S(setsize, cpusetp)
Эти интерфейсы принимают размер множества (массива) в виде дополнительного параметра. Для работы с динамическими массивами процессоров используется следующая тройка макросов:
#define _GNU_SOURCE #include <sched.h> #define CPU_ALLOC_SIZE(count) #define CPU_ALLOC(count) #define CPU_FREE(cpuset)
CPU_ALLOC_SIZE возвращает число байтов, которое необходимо выделить структуре cpu_set_t, могущей обработать количество процессоров, указанное в count. Для собственно выделения такого блока используется CPU_ALLOC. Память, выделенная подобным образом, освобождается через CPU_FREE. Скорее всего, внутри этих функций используются malloc и free, но это далеко не обязательно.
Над множествами процессоров определены также следующие операции:
#define _GNU_SOURCE #include <sched.h> #define CPU_EQUAL(cpuset1, cpuset2) #define CPU_AND(destset, cpuset1, cpuset2) #define CPU_OR(destset, cpuset1, cpuset2) #define CPU_XOR(destset, cpuset1, cpuset2) #define CPU_EQUAL_S(setsize, cpuset1, cpuset2) #define CPU_AND_S(setsize, destset, cpuset1, cpuset2) #define CPU_OR_S(setsize, destset, cpuset1, cpuset2) #define CPU_XOR_S(setsize, destset, cpuset1, cpuset2)
Имеем две группы по четыре макроса. Они могут сравнивать пары множеств, а также производить логические операции И, ИЛИ, исключающее ИЛИ (XOR). Это пригодится при использовании некоторых функций libNUMA (см. раздел 12).
Процесс может определить, на каком процессоре он в данный момент выполняется, используя интерфейс sched_getcpu:
#define _GNU_SOURCE #include <sched.h> int sched_getcpu(void);
Как результат возвращается номер процессора в массиве. В связи с самой природой планирования, этот номер не всегда 100% верен. Есть вероятность, что поток был перемещен на другой процессор между моментом возвращения результата и моментом возвращения потока на уровень пользователя. Программы всегда должны принимать эту вероятность во внимание. В любом случае, гораздо важнее само множество процессоров, на которых потоку разрешено выполняться. Его можно получить, используя sched_getaffinity. Множество привязки наследуется дочерними потоками и процессами. Но неизменность данного множества во время жизненного цикла потока ничем не гарантируется. Маска привязки может быть установлена извне (см. параметр pid в прототипах выше); к тому же Linux поддерживает горячую замену процессоров, а это значит, что процессор может исчезнуть из системы — и, таким образом, из множества привязки.
В соответствии с требованиями POSIX, в многопоточных программах отдельные потоки официально не имеют своего отдельного PID, и поэтому вышеуказанные две функции использовать не получится. Вместо них в <pthread.h> объявлено четыре других интерфейса:
#define _GNU_SOURCE
#include <pthread.h>
int pthread_setaffinity_np(pthread_t th, size_t size,
const cpu_set_t *cpuset);
int pthread_getaffinity_np(pthread_t th, size_t size, cpu_set_t *cpuset);
int pthread_attr_setaffinity_np(pthread_attr_t *at,
size_t size, const cpu_set_t *cpuset);
int pthread_attr_getaffinity_np(pthread_attr_t *at, size_t size,
cpu_set_t *cpuset);
Первые два интерфейса - по сути те же две функции, с которыми мы уже знакомы, за исключением того, что они принимают дескриптор (HANDLE) потока вместо идентификатора процесса (PID). Это позволяет адресовать отдельные потоки в процессе, а также означает, что данные интерфейсы никак не могут быть использованы из другого процесса, они предназначены строго для внутрипроцессного использования. Далее, третий и четвертый интерфейсы принимают атрибут потока. Атрибуты используются при создании нового потока. Устанавливая атрибут, мы можем прямо при запуске потока определить его множество привязки. Выбор целевых процессоров на таком раннем этапе во многом выгоднее выбора уже в процессе работы потока, и особенно это преимущество заметно при выделении памяти (см. NUMA в разделе 6.5).
Кстати, в программировании NUMA интерфейсы привязки также играют большую роль. Скоро мы к этому вернемся.
Пока что мы говорили только о той ситуации, когда рабочие множества двух потоков совпадают, и поэтому имеет смысл выполнение обоих потоков на одном ядре. Но бывают и противоположные случаи. Если два потока работают с совсем разными наборами данных, то их выполнение на одном ядре наоборот может стать проблемой. Во-первых, оба потока будут сражаться за один кэш, мешая друг другу эффективно его использовать. Во-вторых, оба набора данных должны находиться в одном и том же кэше, что фактически означает увеличение количества данных для загрузки, и в итоге доступная пропускная способность урезается вдвое.
Решение - привязать потоки таким образом, чтоы они не могли выполняться вместе на одном ядре. Это противоположность случаю, описанному прежде. И поэтому прежде чем что-то менять, необходимо полностью разобраться в ситуации, которую взялся оптимизировать.
Оптимизация работы с кэшем ради увеличения пропускной способности на деле является аспектом программирования NUMA, о нем пойдет речь в следующем разделе. Чтобы убедиться в справедливости этого утверждения, необходимо свои представления о таком понятии, как ⌠память■ в NUMA, распространить на кэш. И чем больше уровней имеет кэш-память, тем актуальнее становится такой подход. И именно в связи с этим решения по многопроцессорному планированию можно найти во вспомогательных библиотеках NUMA; взятые оттуда примеры по определению масок привязки без применения хардкодинга или углубления в файловую систему /sys находятся в разделе 12.
Замечания и предложения по переводу принимаются по адресу michael@right-net.ru. М.Ульянов.
| Назад | Оглавление | Вперед |