





Библиотека сайта rus-linux.net
Что каждый программист должен знать о памяти. Часть 6: На что еще способны программисты
Оригинал: Memory, part 6: More things programmers can doАвтор: Ulrich Drepper
Дата публикации: October 31, 2007
Перевод: М.Ульянов
Дата перевода: февраль 2010 г.
6.4 Многопотоковая оптимизация
Говоря о многопоточности, выделяют три разных аспекта использования кэша, на которые следует обращать внимание. Это:
- Параллельный доступ
- Атомарность
- Пропускная способность
Подобное деление справедливо и для многозадачных сценариев, но так как задачи (процессы) обычно выполняются независимо друг от друга, работу с ними не так легко оптимизировать. А возможные способы их оптимизации представляют собой лишь подмножество способов оптимизации многопотоковых сценариев. Поэтому мы будем рассматривать исключительно последние.
Под параллельным (совместным) доступом в нашем случае понимается организация работы с памятью для процессов, выполняющихся в несколько потоков. Одним из свойств потоков является тот факт, что они все используют одно и то же адресное пространство и потому могут получать доступ к одному и тому же участку памяти. В идеале каждый поток использует свою отдельную область памяти, при этом потоки почти не связаны между собой (разве что общими входами/выходами, к примеру). Если несколько потоков одновременно используют одни и те же данные, то необходимо согласование - тут в дело вступает атомарность. Наконец, доступные процессорам память и пропускная способность межпроцессорной шины ограничены типом используемой архитектуры. Ниже мы разберем все эти три аспекта по отдельности — хотя они, конечно же, тесно между собой связаны.
6.4.1 Оптимизация параллельного доступа
Итак, начнем. В данном разделе мы обсудим две различные проблемы, требующие по сути принципально противоположных подходов к оптимизации. Пусть многопотоковое приложение использует общие данные для нескольких потоков. Стандартная оптимизация кэша требует нахождения таких данных в одной кэш-строке, чтобы приложение было компактнее - таким образом максимизируя количество памяти, которое кэш сможет вместить в любой момент времени.
Однако с таким подходом возникает следующая проблема: чтобы несколько потоков могли производить запись в память, строки кэшей L1d соответствующих ядер должны иметь статус ‘E’ (Exclusive). Это означает, что появится множество RFO-запросов, в худшем случае - по запросу на каждую попытку записи. В результате обыкновенная процедура записи внезапно становится очень ресурсоемкой. К тому же, если речь идет об одной и той же области памяти, то тут необходима синхронизация (при этом могут помочь атомарные операции, о них поговорим в следующем разделе). Но проблема остается даже когда все потоки используют разные области памяти и предположительно не зависят друг от друга.
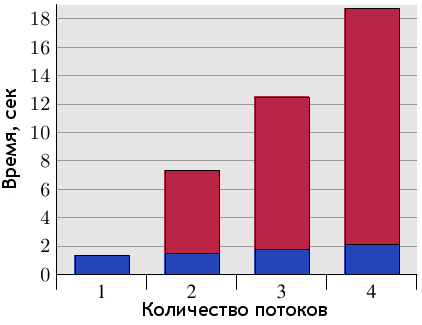
Рисунок 6.10: Задержки при параллельном доступе с использованием общей кэш-строки
Описанная проблема получила название ⌠ложного совместного доступа■. На рисунке 6.10 наглядно показано, чем он опасен. Тестовая программа (см. листинг в разделе 9.3) создает некоторое количество потоков, которые увеличивают значение, хранящееся в памяти, на единицу (500 миллионов раз). Измеряется время, прошедшее с момента запуска программы и до момента ее завершения после того, как последний поток закончит работу. Для теста используется машина с четырьмя процессорами P4, при этом каждый поток закреплен за своим процессором. Синим цветом показаны результаты, когда данные каждого потока обслуживались отдельными кэш-строками. Красный цвет демонстрирует задержки, полученные при использовании одной общей кэш-строки для данных всех потоков.
Результаты, показанные синим цветом (отдельные кэш-строки для каждого потока) в точности совпадают с тем, что обычно ожидается в таких случаях. Программа выполняется в несколько потоков, фактически без потерь. Кэш-строка каждого потока находится в кэше L1d соответствующего процессора и отсутствуют проблемы с пропускной способностью, поскольку нет необходимости считывать большие куски кода или данных (по сути, всё уже кэшировано). А полученное небольшое увеличение во времени объясняется наличием системного шума и, возможно, эффектом упреждающей выборки (ведь потоки используют последовательные кэш-строки).
Задержка в процентном соотношении вычисляется делением времени, потраченного с использованием общей кэш-строки, на время, потраченное с использованием индивидуальных кэш-строк для каждого потока, и составляет 390%, 734% и 1147% соответственно. Настолько большие числа могут поначалу удивить, но если разобраться, как в нашем случае взаимодействуют кэши, всё становится понятно. "Общая" строка выгружается из кэша текущего процессора сразу после окончания записи. И все процессоры, кроме того, в кэше которого на данный момент находится кэш-строка, простаивают и ничего не могут делать. Каждый дополнительный процессор попросту увеличивает время таких простоев.
Естественно, что подобного сценария необходимо избегать при программировании. И хотя в большинстве случаев проблему будет легко определить по огромным задержкам (профилирование как минимум локализует проблему в коде), тут есть свои подводные камни. Один из них - современное аппаратное обеспечение. На рисунке 6.11 показаны те же измерения, только сделанные на машине с одним четырехъядерным процессором (Intel Core 2 QX 6700). Даже с учетом наличия двух раздельных кэшей второго уровня (L2), тест не выявил никаких проблем. При неоднократном использовании одной и той же кэш-строки имеется небольшая задержка, но она не зависит от количества ядер. {Я никак не могу объяснить уменьшение данной задержки при использовании всех четырех ядер, но данный результат легко воспроизводится.} Конечно, при использовании более чем одного такого процессора мы бы получили результаты, схожие с показателями рисунка 6.10. Несмотря на то, что многоядерные процессоры распространяются все шире, многопроцессорные машины пока никуда не денутся, и потому важно корректно обрабатывать вышеприведенный сценарий. А это значит, что придется проверять код на реальных многопроцессорных машинах.
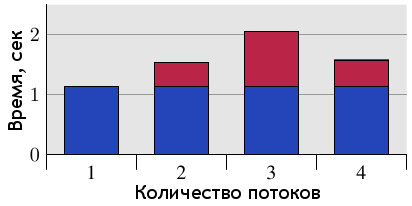
Рисунок 6.11: Задержки при использовании четырехъядерного процессора
Навскидку, простейшее решение проблемы "в лоб": хранить каждую переменную в отдельной строке кэша. И вот здесь проявляется конфликт с первоначально описанным вариантом оптимизации, а именно - ни о какой компактности приложения речи уже не идет, объем занимаемой памяти в кэше сильно увеличится. Это неприемлемо, так что необходимо искать более изящный вариант.
Чтобы его найти, необходимо определить, какие переменные используются только одним потоком в каждый момент времени, какие используются вообще только одним потоком, ну и можно выделить те, к которым нужен совместный доступ лишь временами. Для каждого из этих сценариев возможны самые различные решения. Простейший критерий разделения переменных - ответ на вопрос, происходит ли вообще запись в данную переменную во время работы и если да, то как часто.
Переменные, в которые никогда не происходит запись и которые инициализируются лишь однажды - по сути являются константами. Так как запросы RFO необходимы только для операций записи, то константы можно сделать общими (статус ‘S’). Они не требуют какого-то особого обращения, достаточно просто сгруппировать их вместе. Если корректно пометить нужные переменные как const, то toolchain сам отделит их от "нормальных" переменных и поместит в секции .rodata (данные только для чтения) или .data.rel.ro ("только для чтения" после перемещения). {секции, идентифицируемые по именам - это атомарные единицы, содержащие код и данные в файле ELF} Никаких других действий не потребуется. Если же по каким-то причинам переменные невозможно пометить как const, то на их размещение можно повлиять, объявив такие переменные в специальной секции.
При компоновке итогового исполняемого файла сначала собираются вместе секции с одинаковыми именами из всех входных файлов, затем эти секции располагаются в порядке, определяемом скриптом компоновщика. Это означает, что если все переменные, не помеченные как константы, но по сути являющиеся таковыми, объявлять в специальных (одинаково поименованных) секциях, то такие переменные окажутся сгруппированными вместе. Среди них не окажется переменной, в которую часто происходила бы запись. А выровняв первую переменную в такой секции нужным образом, можно гарантировать защищенность от ложного совместного доступа. Рассмотрим следующий небольшой пример:
int foo = 1;
int bar __attribute__((section(".data.ro"))) = 2;
int baz = 3;
int xyzzy __attribute__((section(".data.ro"))) = 4;
Будучи скомпилированным, такой входной файл определяет четыре переменные. Интересный момент заключается в том, что пары переменных foo и baz, bar и xyzzy соответственно будут сгруппированы вместе. Если бы не были определены атрибуты, компилятор расположил бы все четыре переменные в секции .data, причем в том порядке, в каком они определены в исходном коде. {Это не гарантируется ISO-стандартом для языка C, но тем не менее gcc работает именно так.} Наш же код расположит переменные bar и xyzzy в секции .data.ro. Имя секции, .data.ro, выбрано относительно произвольно. "Относительно" - ибо префикс .data. гарантирует, что компоновщик GNU поместит секцию вместе с другими секциями данных.
Этот же прием можно применить, чтобы выделить переменные "в основном для чтения", т.е. часто читаемые, но в которые редко происходит запись. Просто выберите другое имя секции. Но такое разделение имеет смысл лишь в некоторых случаях, например в ядре Linux.
Если переменная используется только внутри потока, можно использовать другой способ объявления. В этом случае можно и нужно использовать локальные переменные потока
(см. [mytls]). Языки C и C++ в gcc позволяют определять переменные как принадлежащие потоку, используя ключевое слово __thread.
int foo = 1; __thread int bar = 2; int baz = 3; __thread int xyzzy = 4;
Переменные bar и xyzzy не будут помещены в обычном сегменте данных. Вместо этого, каждый поток имеет свою отдельную область для хранения таких переменных. Хранящиеся подобным образом переменные могут иметь статические инициализаторы. Все локальные переменные потока адресуемы другими потоками, но пока поток-владелец не передаст им указатель на свою переменную, они никак не смогут ее найти. Поскольку переменная является локальной в пределах данного потока, проблема ложного совместного доступа попросту отсутствует — если, конечно, не создать ее искусственно. Такое решение легко реализовать (всю работу делают компилятор и компоновщик), но и оно имеет свою цену. При создании потока, последнему необходимо инициализировать локальные переменные, а это требует и времени, и памяти. К тому же, адресация локальной переменной потока обычно более ресурсоемка, чем использование глобальных или автоматических переменных
(в [mytls] объясняется, как происходит автоматическое снижение ресурсоемкости в случаях, когда это возможно).
Одним из недостатков использования локальной памяти потока (далее TLS = thread-local storage) является тот факт, что если переменная все-таки передается другому потоку, то текущее значение переменной в старом потоке недоступно для нового владельца. У него будет своя копия переменной, не связанная с оригиналом. Обычно это вообще не проблема, но если таки это важно, то передача переменной другому потоку потребует некоторой координации, для копирования текущего значения.
Второй недостаток посерьезней - возможна пустая трата ресурсов. Если переменную использует только один поток в каждый момент времени, все остальные потоки за это расплачиваются памятью. В случае, когда TLS-переменные не используются вообще, проблему решает отложенное ("ленивое") выделение памяти TLS (исключая локальную память в самом приложении). Но при использовании потоком всего одной переменной TLS в разделяемой библиотеке, будет выделена память и для всех остальных TLS-переменных этой библиотеки. При широком использовании переменных TLS это потенциально может вылиться в серьезную проблему.
В целом, можно дать следующие советы:
- Как минимум, разделяйте переменные "только для чтения" (после их инициализации) и "обычные" модифицируемые переменные. Можете также выделить переменные "в основном для чтения" в третью категорию.
- Группируйте модифицируемые переменные, используемые вместе, в структуру. Использование структуры - единственный способ гарантировать при использовании любой версии gcc, что области памяти для этих переменных находятся рядом друг с другом.
- Модифицируемые переменные, в которые часто происходит запись разными потоками, помещайте в отдельную кэш-строку. Место, которое останется в строке, можно заполнить незначащей информацией. В сочетании с шагом 2 это может оказаться отнюдь не столь расточительно, как кажется. Дополнив вышеприведенный пример и полагая, что
barиxyzzyдолжны использоваться вместе, получим следующий код:int foo = 1; int baz = 3; struct { struct al1 { int bar; int xyzzy; }; char pad[CLSIZE - sizeof(struct al1)]; } rwstruct __attribute__((aligned(CLSIZE))) = { { .bar = 2, .xyzzy = 4 } };Понадобятся небольшие исправления в коде (ссылки на
barпоменять наrwstruct.bar, сxyzzyаналогично), но не более того. Компилятор с компоновщиком доделают остальное. {В командной строке этот код необходимо компилировать с-fms-extensions.} - Если переменная используется множеством потоков, но каждый из потоков использует ее независимо от других, помещайте такую переменную в TLS.
Замечания и предложения по переводу принимаются по адресу michael@right-net.ru. М.Ульянов.
| Назад | Оглавление | Вперед |