





Библиотека сайта rus-linux.net
Что каждый программист должен знать о памяти. Часть 5.
Оригинал: What every programmer should know about memory. Memory part 5: What programmers can do.
Автор: Ulrich Drepper
Дата публикации: 23.10.2007
Перевод: Капустин С.В.
Дата перевода: 30.10.2009
6. Что могут делать программисты - оптимизация кэша
6.3.3 Специальный вид предварительной загрузки: условная загрузка
Способность процессора выполнять инструкции не по порядку позволяет передвигать инструкции, если они не конфликтуют друг с другом. Например (в этом примере используется IA-64):
st8 [r4] = 12 add r5 = r6, r7;; st8 [r18] = r5
Этот код сохраняет 12 в адресе, заданном регистром r4, суммирует содержимое регистров r6 и r7 и сохраняет сумму в регистре r5. И в конце сумма сохраняется в адресе, заданном регистром r18. Смысл здесь в том, что инструкция суммирования может быть выполнена до, или одновременно, первой инструкции st8, так как нет зависимости данных. Но что произойдет, если одно из слагаемых нужно загрузить?
st8 [r4] = 12 ld8 r6 = [r8];; add r5 = r6, r7;; st8 [r18] = r5
Дополнительная инструкция ld8 загружает значение из адреса, заданного в регистре r8. Есть очевидная зависимость данных между инструкцией загрузки и последующей инструкцией add (вот почему после инструкции стоит ;;, спасибо за вопрос). Критично здесь то, что новая инструкция ld8, в отличие от инструкции add, не может быть помещена перед первой st8. Процессор не может достаточно быстро определить при декодировании инструкций, конфликтуют ли сохранение и загрузка, то есть имеют ли r4 и r8 одинаковое значение. Если они действительно имеют одинаковое значение, то инструкция st8 определяет значение, загружаемое в r6. Что ещё хуже, ld8 может сделать это с большой задержкой, если произойдет промах кэша. Для этого случая архитектура IA-64 поддерживает условную загрузку:
ld8.a r6 = [r8];; [... other instructions ...] st8 [r4] = 12 ld8.c.clr r6 = [r8];; add r5 = r6, r7;; st8 [r18] = r5
Новые инструкции ld8.a и ld8.c.clr связаны друг с другом и заменяют инструкцию ld8 из предыдущего примера кода. Инструкция ld8.a - это условная загрузка. Значение не может быть использовано сразу, но процессор может начать работу. К тому моменту, когда будет достигнута инструкция ld8.c.clr, содержимое уже наверное будет загружено (если в промежутке будет достаточное количество инструкций). Аргументы этой инструкции должны совпадать с аргументами инструкции ld8.a. Если предшествующая инструкция st8 не перезаписала значение (то есть r4 и r8 одинаковые), то ничего не нужно делать. Условная загрузка делает свое дело и задержка загрузки спрятана. Если загрузка и сохранение конфликтуют, то ld8.c.clr снова делает загрузку из памяти и мы имеем семантику обычной инструкции ld8.
Условная загрузка (пока?) не является распостраненной. Но, как показывает пример, - это простой и очень эффективный способ скрыть задержки. Предварительная загрузка в основном делает то же самое, поэтому для процессоров с небольшим количеством регистров условная загрузка вероятно не имеет большого смысла. Условная загрузка имеет (иногда большое) преимущество в том, что значение загружается непосредственно в регистр, а не в строку кэша, откуда оно может быть снова исключено (например когда процессор временно переключается на работу с другим потоком). Если условная загрузка доступна, её следует использовать.
6.3.4 Вспомогательные потоки
Если кто-то пытается использовать программную предварительную загрузку, он часто сталкивается со сложностью кода. Если код проводит итерацию по некоторой структуре данных (по списку в нашем случае), то придется строить две независимые итерации в том же цикле: обычная итерация проделывает работу, а вторая итерация смотрит вперед, обеспечивая предварительную загрузку. Это может усложнить код и привести к ошибкам.
Далее, нужно определить, насколько далеко вторая итерация должна смотреть вперед. Если ненамного, то память не будет загружена вовремя. Если слишком намного, то только что загруженные данные могут быть снова исключены из кэша. Ещё одна проблема состоит в том, что инструкции предварительной загрузки, хотя они и не блокируют и не ждут пока память загрузится, отнимают время. Инструкции нужно декодировать, что может стать заметным, если декодер очень занят, например из-за хорошо написанного/сгенерированного кода. И наконец, размер кода цикла увеличивается. Это снижает эффективность L1i. Если пытаться избежать части этих затрат, выпуская несколько запросов на предварительную выборку зараз (в случае если вторая загрузка не зависит от результата первой), то можно столкнуться с проблемой появления невыполненных запросов на предварительную выборку.
Альтернативный подход состоит в том, чтобы выполнять обычные операции и предварительную загрузку совершенно независимо. Этого можно добиться используя два стандартных потока. Потоки, очевидно, должны быть запланированы так, чтобы поток предварительной загрузки заполнял кэш, используемый обоими потоками. Есть два специальных решения, достойных упоминания:
- Использовать гиперпотоки (см. рисунок 3.22) на одном ядре. В этом случае предварительная загрузка пойдет в L2 (или даже L1d).
- Использовать ⌠глупые■ потоки, которые в отличие от потоков SMT могут делать только предварительную загрузку и другие простые операции. Это опция, которую производители процессоров должны исследовать.
Использование гиперпотоков особенно интересно. Как мы видели на рисунке 3.22, разделение кэша является проблемой, когда гиперпотоки выполняют независимый код. Если наоборот, один поток используется как вспомогательный для предварительной загрузки, то проблемы нет. Напротив, это желаемый эффект, так как предварительная загрузка идет в кэш низшего уровня. Кроме того, так как поток предварительной загрузки по большей части бездействует или ждет память, обычные операции другого вспомогательного потока не сильно страдают, если он не должен сам обращаться к основной памяти. Последнее - это в точности то, что вспомогательный поток предварительной загрузки предотвращает.
Единственная хитрость здесь в том, чтобы сделать так, что вспомогательный поток не будет убегать слишком далеко вперед. Он на должен полностью заполнить кэш, так что самые старые предварительно загруженные данные были бы снова исключены. На Linux синхронизация легко может быть сделана при помощи системного вызова futex (см. [2]) или, с немного большими затратами, используя примитивы синхронизации потоков POSIX.
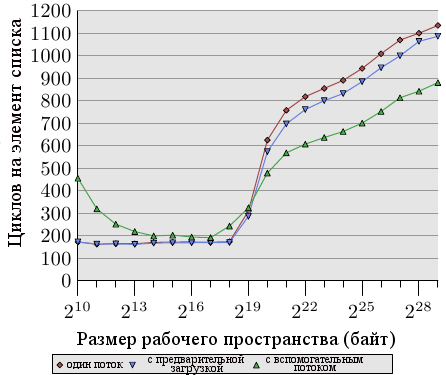
Рисунок 6.8: Среднее с вспомогательными потоками, NPAD=31
Преимущества такого подхода можно видеть на рисунке 6.8. Это тот же тест, что и на рисунке 6.7, только добавлен ещё один результат. Новый тест создает вспомогательный поток, который идет примерно на 100 записей впереди и читает (а не только делает предварительную загрузку) все строки кэша каждого элемента списка. Для этого случая мы имеем по две строки кэша на каждый элемент списка (NPAD=31 на 32-битной машине с 64-байтной строкой кэша).
Два потока запланированы на гиперпотоках на одном ядре. Тестовая машина имела только одно ядро, но результаты будут примерно те же, если ядер будет больше. Функции родства, которые мы введем в разделе 6.4.3, будут использоваться для связывания потока с соответствующим гиперпотоком.
Чтобы определить какие два (или более) процессора, которые видит операционная система, на самом деле являются гиперпотоками, можно использовать интерфейс NUMA_cpu_level_mask из libNUMA (см раздел 12).
#include <libNUMA.h>
ssize_t NUMA_cpu_level_mask(size_t destsize,
cpu_set_t *dest,
size_t srcsize,
const cpu_set_t*src,
unsigned int level);
Этот интерфейс можно использовать для того, чтобы определить иерархию процессоров и то, как они соединены через кэш и память. Нам здесь интересен уровень 1, который соответствует гиперпотокам. Чтобы запланировать два потока на двух гиперпотоках можно использовать функции libNUMA (обработка ошибок для краткости опущена):
cpu_set_t self;
NUMA_cpu_self_current_mask(sizeof(self),
&self);
cpu_set_t hts;
NUMA_cpu_level_mask(sizeof(hts), &hts,
sizeof(self), &self, 1);
CPU_XOR(&hts, &hts, &self);
После того, как этот код выполнен, мы имеем два набора битов ЦПУ. Можно использовать self, чтобы задать родство текущего потока и маска hts может быть использована, чтобы задать родство вспомогательного потока. В идеале, это должно случиться перед тем, как поток создан. В разделе 6.4.3 мы опишем интерфейс для задания родства. Если в наличии нет гиперпотоков, то NUMA_cpu_level_mask вернет 1. Это можно использовать как сигнал о том, что данной оптимизации делать не нужно.
Результат этого теста может показаться удивительным (а может и нет). Если рабочее пространство помещается в L2, то накладные расходы на вспомогательный процесс снижают производительность от 10% до 60% (мы снова игнорируем самые маленькие размеры рабочего пространства, так как в этом случае результаты неразличмы на уровне шума). Этого можно было ожидать, так как если данные уже в кэше L2, то вспомогательный процесс предварительной загрузки не помогает выполнению, а только зря расходует системные ресурсы.
Однако когда L2 исчерпан, картина меняется. Вспомогательный поток предварительной загрузки помогает сократить время выполнения примерно на 25%. Мы все еще видим восходящую кривую просто потому, что предварительная загрузка не может быть обработана достаточно быстро. Однако арифметические операции, выполняемые основным потоком и операции загрузки памяти вспомогательного потока дополняют друг друга. Соревнование за ресурсы минимально, что дает этот синергетический эффект.
Результаты этого теста могут быть перенесены на многие другие ситуации. Гиперпотоки, часто бесполезные из-за загрязнения кэша, в таких ситуациях блистают, и их преимущества нужно использовать. Файловая система sys позволяет программе найти родственные потоки (см. колонку thread_siblings в таблице 5.3). Если информация доступна, то программе просто нужно задать родство потоков и затем обходить цикл в двух режимах: обычные операции и предварительная загрузка. Количество предварительно загружаемой памяти должно зависеть от размера разделяемого кэша. В этом примере имеет значение размер L2 и программа может запросить этот размер используя
sysconf(_SC_LEVEL2_CACHE_SIZE)
Нужно или нет ограничивать движение вспомогательного потока - зависит от программы. В общем случае лучше всего убедиться, что есть какая-то синхронизация, иначе детали планирования могут вызвать значительный упадок производительности.
[1] Melo, Arnaldo Carvalho de. The 7 dwarves: debugging information beyond gdb. Proceedings of the linux symposium. 2007.
[2] Drepper, Ulrich. Futexes Are Tricky., 2005. http://people.redhat.com/drepper/futex.pdf.
[3] Huggahalli, Ram, Ravi Iyer and Scott Tetrick. Direct Cache Access for High Bandwidth Network I/O. , 2005.
| Назад | Оглавление | Вперед |