





Библиотека сайта rus-linux.net
Что каждый программист должен знать о памяти. Часть 5.
Оригинал: What every programmer should know about memory. Memory part 5: What programmers can do.
Автор: Ulrich Drepper
Дата публикации: 23.10.2007
Перевод: Капустин С.В.
Дата перевода: 30.10.2009
6. Что могут делать программисты - оптимизация кэша
6.3.2 Программная предварительная загрузка
Преимущество аппаратной загрузки в том, что программу не нужно подстраивать. Недостатки, как только что было описано, в том, что образцы доступа должны быть тривиальными и предварительная загрузка не может пересекать границы страниц. По этим причинам у нас есть больше возможностей, программная предварительная загрузка - самая важная из них. Программная предварительная загрузка требует модификации исходного кода встраиванием специальных инструкций. Некоторые компиляторы поддерживают псевдокомментарии, для того чтобы более или менее автоматически вставлять инструкции предварительной загрузки. На x86 и x86-64 для того, чтобы вставлять эти специальные инструкции, используется соглашение Intel по встроенным функциям компилятора:
#include <xmmintrin.h>
enum _mm_hint
{
_MM_HINT_T0 = 3,
_MM_HINT_T1 = 2,
_MM_HINT_T2 = 1,
_MM_HINT_NTA = 0
};
void _mm_prefetch(void *p,
enum _mm_hint h);
Программы могут применять эту функцию _mm_prefetch к любому указателю программы. Большинство процессоров (определенно все процессоры x86 и x86-64) игнорируют ошибки, возникающие из-за недействительных указателей, что делает жизнь программиста существенно проще. Однако, если переданный указатель ссылается на действительную память, то модуль предварительной загрузки будет проинструктирован загрузить эти данные в кэш и, если нужно, вытеснить другие данные. Нужно избегать необязательных предварительных загрузок, так как они могут снизить эффективность кэша и потребляют пропускную способность памяти (возможно даже на величину двух строк кэша, если вытесняемая строка грязная).
То, какие следует использовать значения параметров функции _mm_prefetch, определяется её реализацией. Это означает, что каждая версия процессора реализует её (немного) по-разному. В общем можно сказать, что _MM_HINT_T0 загружает данные на все уровни инклюзивного кэша и на нижние уровни эксклюзивного кэша. Если элемент данных находится в высших уровнях кэша, то он загружантся в L1d. Индикатор _MM_HINT_T1 помещает данные в L2, но не в L1d. Если есть L3, то _MM_HINT_T2 делает нечто подобное. Есть однако детали, которые слабо документированы и нуждаются в проверке для каждого используемого процессора. В общем, если данные должны использоваться немедленно, то использование _MM_HINT_T0 будет правильным выбором. Конечно, это требует того, чтобы размер кэша L1d был достаточно велик, чтобы содержать все предварительно загруженные данные. Если размер немедленно используемого рабочего пространства слишком велик, то предварительная загрузка всего его в L1d будет прохой идеей и нужно использовать другие два индикатора.
Четвертый индикатор, _MM_HINT_NTA, особый, в том смысле, что он говорит процессору о том, чтобы обращаться с предварительно выбранной строкой кэша по-особому. Мы уже объясняли в разделе 6.1 что такое NTA (non-temporal aligned). Программа говорит процессору о том, что не нужно загрязнять кэш этими данными, так как они используются только короткое время. Процессор может, следовательно, во время загрузки, отказаться от чтения данных в кэш нижнего уровня для инклюзивных реализаций кэша. Когда данные выталкиваются из L1d, их не нужно помещать в L2 или выше, но можно наоборот записать прямо в память. Могут быть и другие трюки, внедренные дизайнерами процессоров, если задан этот индикатор. Программист должен быть осторожен при использовании этого индикатора: если размер немедленно испльзуемого рабочего пространства слишком велик и приводит к исключению из кэша строки, загруженной с индикатором NTA, произойдет перезагрузка из памяти.
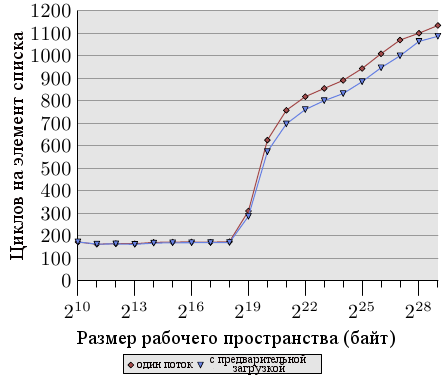
Рисунок 6.7: Среднее с предварительной загрузкой, NPAD=31
Рисунок 6.7 показывает результаты теста, использующего знакомый теперь алгоритм погони за указателями. Список рандомизирован. Отличие от предыдущего теста в том, что программа теперь тратит некоторое время на каждый узел списка (около 160 циклов). Как мы знаем из данных рисунка 3.15, производительность программы сильно падает, когда размер рабочего пространства начинает превышать размер кэша последнего уровня.
Теперь мы можем попытаться улучшить ситуацию выпуская запросы на предварительную загрузку перед вычислением. То есть при каждом обходе цикла мы предварительно загружаем новый элемент. Расстояние между предварительно загружаемым узлом в списке и узлом, над которым идет работа, должно быть тщательно выбрано. Имея в виду, что каждый узел обрабатывается за 160 циклов и что мы должны предварительно загрузить две строки кэша (NPAD=31), расстояние в пять элементов списка будет достаточным.
Результаты на рисунке 6.7 показывают, что предварительная загрузка действительно помогает. Пока размер рабочего пространства не превышает размера кэша последнего уровня (машина имеет 512Кб = 219Б L2), числа совпадают. Инструкции предварительной загрузки не накладывают заметной дополнительной нагрузки. Как только размер L2 превышен, предварительная загрузка экономит от 50 до 60 циклов, или до 8%. Использование предварительной загрузки не прячет весь ущерб, но немного помогает.
AMD внедряет в 10 модели семейства Opteron другую инструкцию: prefetchw. Эта инструкция пока не имеет эквивалента у Intel и не доступна через встроенные функции компилятора. Инструкция prefetchw предварительно загружает строку кэша в L1 так же как и другие инструкции предварительной загрузки. Разница в том, что строка кэша немедленно переходит в состояние 'M'. Это будет недостатком, если потом не последует никакой записи в строку кэша. Если есть одна или более запись, то они будут ускорены, так как им не нужно будет изменять состояние кэша - оно уже было изменено, когда строка кэша была предварительно загружена.
Предварительная загрузка может дать гораздо больше, чем скромные 8%, которые мы получили. Но это очень трудно сделать правильно, особенно если один и тот же бинарник предполагается использовать на большом разнообразии машин. Счетчики производительности, предоставляемые ЦПУ, могут помочь программисту анализировать предварительные загрузки. События, которые могут быть подсчитаны и сравнены, включают аппаратные предварительные загрузки, программные предварительные загрузки, полезные программные предварительные загрузки, промахи кэша на разных уровнях и т.д. В разделе 7.1 мы опишем многие такие события. Все эти счетчики специфичны для каждой машины.
При анализе программ, в первую очередь нужно смотреть на промахи кэша. Когда найден большой источник промахов кэша, нужно попытаться добавить инструкции предварительной загрузки для проблематичных доступов к памяти. Добавлять эти инструкции нужно по одной за раз. Результат каждой модификации нужно проверять с помощью счетчиков, измеряющих полезные программные предварительные загрузки. Если результаты этих счетчиков не повышаются, то предварительная загрузка может быть неверна, у неё может быть слишком мало времени для загрузки из памяти, или она выталкивает из кэша память, которая все еще нужна.
Сегодня gcc может выпускать инструкции предварительной загрузки автоматически в одной ситуации. Если цикл проходит по массиву, то можно использовать следующую опцию:
-fprefetch-loop-arrays
Компилятор посчитает, имеет ли предварительная загрузка смысл, и если да, то насколько далеко вперед она должна смотреть. Для небольших массивов это может не быть полезным, если величина массива неизвестна, то результаты могут ухудшиться. Руководство по gcc предупреждает, что польза этого действия зависит от формы кода и в некоторых ситуациях код может выполняться медленнее. Программисты должны использовать эту опцию осторожно.
| Назад | Оглавление | Вперед |