





Библиотека сайта rus-linux.net
Что каждый программист должен знать о памяти
Оригинал: What every programmer should know about memoryАвтор: Ulrich Drepper
Дата публикации: 21.09.2007
Перевод: Капустин С.В.
Дата перевода: 25.03.2009
2 Современное массовое аппаратное обеспечение
2.2 Технические детали доступа к DRAM
В предыдущем разделе мы видели, что чипы DRAM мультиплексируют адреса, чтобы сэкономить ресурсы. Мы также видели, что доступ к ячейкам DRAM требует времени, так как конденсаторы в этих ячейках разряжаются таким образом, что не сразу выдают стабильный сигнал. Мы также видели, что ячейки DRAM необходимо подзаряжать. Теперь пришло время собрать это все вместе и посмотреть, как эти факторы определяют детали доступа к DRAM.
Мы сконцентрируемся на современной технологии, мы не будем обсуждать асинхронную DRAM и её варианты, так как они неактуальны. Читатели, заинтересованные этой темой, отсылаются к [2] и [3]. Мы также не будем говорить о Rambus DRAM (RDRAM), хотя эта технология и не является вышедшей из употребления. Просто она не используется широко в системной памяти. Мы сконцентрируемся исключительно на синхронной DRAM (SDRAM - Synchronous DRAM) и её последовательнице Double Data Rate DRAM (DDR).
Синхронная DRAM, как следует из её названия, работает по источнику времени. В контроллере памяти имеется тактовый генератор, частота которого определяет частоту системной шины (FSB - Front Side Bus) - интерфейс контроллера памяти, используемый чипами DRAM. Во время написания этого текста используются частоты 800МГц, 1066МГц, и даже 1333МГц, а частота 1600МГц анонсирована для следующего поколения. Это не означает, что частота шины действительно такая высокая. Вместо этого за один такт данные передаются два или четыре раза. Большие числа лучше продаются, поэтому производители рекламируют шину 200МГц с учетверенной скоростью передачи данных как шину с "эффективной" частотой 800МГц.
Сегодня для SDRAM одна порция передачи данных составляет 64 бит - 8 байт. Следовательно, скорость передачи данных для FSB это 8 байт умножить на эффективную частоту шины (6.4Гб/с для шины 200МГц с учетверенной скоростью передачи данных). Кажется, что это много, но это пиковая скорость, максимум, который невозможно превзойти. Как мы увидим, протокол обмена данными с модулем RAM предполагает наличие множества отрезков времени, когда никакие данные не передаются. Это как раз такие отрезки времени, которые мы должны научиться понимать и минимизировать, чтобы добиться наилучшей производительности.
2.2.1 Протокол доступа к чтению
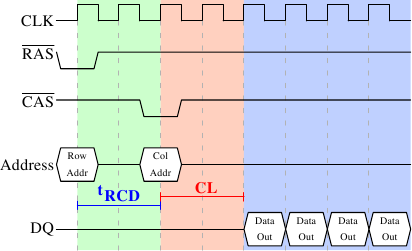
Рисунок 2.8: Временные диаграммы протокола доступа к чтению из SDRAM
Рисунок 2.8 показывает активность на некоторых выходах модуля DRAM, которую можно разделить на три фазы, которые на рисунке окрашены в разные цвета. Как обычно, время течет слева направо. Многие детали опущены. Здесь мы говорим только о тактовых импульсах шины, сигналах RAS и CAS и шинах адреса и данных. Цикл чтения начинается с того, что контроллер памяти посылает по адресной шине адрес строки и понижает уровень сигнала RAS. Все сигналы читаются во время повышения уровня сигнала тактового генератора (CLK), поэтому не имеет значения, что сигналы не совсем прямоугольной формы - лишь бы они были стабильны, когда их начнут читать. Установка адреса строки побуждает чип RAM фиксировать адресную строку.
Сигнал CAS может быть послан через tRCD (RAS-to-CAS Delay) тактов. Затем по адресной шине передается адрес колонки и понижается уровень сигнала CAS. Здесь мы видим как две части адреса (практически половинки) могут быть переданы по одной и той же адресной шине.
Наконец адресация закончена и можно передавать данные. Чипу RAM нужно некоторое время, чтобы подготовить это. Эта задержка обычно называется CAS Latency (CL). На рисунке 2.8 она равна 2. Она может быть выше или ниже, в зависимости от качества контроллера памяти, материнской платы и модуля DRAM. Она также может принимать половинные значения. При CL=2.5 первые данные начнут передаваться на первом понижении сигнала тактового генератора в синей области.
Со всеми этими приготовлениями было бы расточительно передавать только одно слово данных. Вот почему модули DRAM позволяют контроллеру памяти задавать количество передаваемых данных. Обычно выбор между 2, 4, или 8 словами. Это позволяет заполнить целые строки кэшей без новой последовательности RAS/CAS. Контроллер памяти может также послать сигнал CAS без нового выбора строки. Так можно считывать или записывать последовательно идущие адреса памяти значительно быстрее, из-за того, что не нужно посылать сигнал RAS и деактивировать строку (см. ниже). Контроллер памяти должен решать, хранить ли строку "открытой". Теоретически, если держать её все время открытой, то это может иметь отрицательные последствия в существующих приложениях (см. [2]). Когда посылать новый сигнал CAS - определяется свойством Command Rate модуля RAM (обычно обозначается как Tx, где x это значение такое как 1 или 2, оно будет равно 1 для высокопроизводительных модулей DRAM, которые принимают новые команды каждый цикл).
В этом примере SDRAM выдает одно слово за цикл. Это то, что может делать первое поколение. DDR может передавать два слова за цикл. Это сокращает время передачи, но не изменяет задержку. В принципе, DDR2 работает так же, хотя на практике это выглядит по-другому. Здесь нет необходимости углубляться в детали. Достаточно отметить, что DDR2 можно сделать быстрее, дешевле, более надежной и более энергоэффективной (см. [4] для более подробной информации).
2.2.2 Предварительная зарядка и активация
Рисунок 2.8 не покрывает полный цикл. Он показывает только часть полного цикла доступа к DRAM. Перед тем как можно будет послать новый сигнал RAS текущая выбранная строка должна быть деактивирована и новая строка должна быть заряжена. Мы можем сконцентрироваться здесь на случае, когда это делается явной командой. Есть улучшения протокола, которые, в некоторых случаях, позволяют обойтись без этого дополнительного шага. Однако задержка, вызванная зарядкой, все равно влияет на операцию.
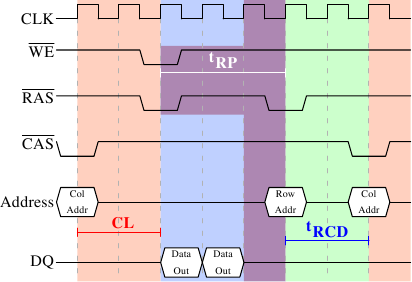
Рисунок 2.9: Предварительная зарядка и активация SDRAM
Рисунок 2.9 показывает активность, начинающуюся от одного сигнала CAS, и заканчивающуюся сигналом CAS для другой строки. Данные, затребованные первым сигналом CAS, появляются как и раньше через CL циклов. В этом примере затребованы два слова, на передачу которых SDRAM требуется два цикла. Можно представить себе четыре слова на чипе DDR.
Даже на модулях DRAM с command rate равным 1 команда на предварительную зарядку не может быть запущена сразу. Необходимо ждать пока передаются данные. В нашем случае это два цикла. Получается то же, что и CL, но это просто совпадение. Сигнал на предварительную зарядку не имеет специальной выделенной линии. Вместо этого на некоторых реализациях используется одновременное понижение уровней Write Enable (WE) и RAS. Эта комбинация не имеет смысла сама по себе (см. подробности кодирования в [5]).
После того, как команда на предварительную зарядку передана, нужно ждать tRP (Row Precharge time) циклов до того как строка может быть выбрана. На рисунке 2.9 большая часть этого времени (обозначенная фиолетовым цветом) пересекается с передачей данных (светло-синий). Это хорошо! Но tRP больше, чем время передачи данных, поэтому следующий сигнал RAS задерживается на один цикл.
Если бы мы продолжили ось времени в диаграмме, то обнаружили бы, что следующая передача данных начинается через 5 циклов после окончания текущей. Это значит, что шина данных используется только в двух циклах из семи. Умножьте это на скорость FSB, и теоретические 6.4Гб/с для шины частотой 800МГц превратятся в 1.8Гб/с. Это плохо, и этого следует избегать. Техники, описанные в главе 6, помогут увеличить эту скорость. Но программист должен для этого постараться.
Есть ещё одна временная константа для модулей SDRAM, которую мы не обсудили. На рисунке 2.9 команда на предварительную зарядку ограничена только временем передачи данных. Другое ограничение состоит в том, что модулю SDRAM необходимо время после сигнала RAS, прежде чем он сможет заряжать другую строку (это время обозначается tRAS). Это число обычно довольно высоко, в два или три раза больше значения tRP. Это проблема, если после сигнала RAS следует только один сигнал CAS и передача данных заканчивается через несколько циклов. Предположим, что на рисунке 2.9 первому сигналу CAS непосредственно предшествует сигнал RAS и tRAS равно 8 циклам. Тогда команду на предварительную зарядку нужно отложить на один цикл, так как сумма tRCD, CL, и tRP (т.к. оно больше, чем время передачи данных) составляет всего 7 циклов.
Модули DDR часто описываются, используя специальную нотацию: w-x-y-z-T. Например: 2-3-2-8-T1. Это означает:
w 2 CAS Latency (CL) x 3 RAS-to-CAS delay (tRCD) y 2 RAS Precharge (tRP) z 8 Active to Precharge delay (tRAS) T T1 Command Rate
Есть ещё множества временных констант, которые влияют на то, как должны даваться и исполняться команды. Но на практике этих пяти констант достаточно, чтобы определять производительность модуля.
Иногда полезно знать эту информацию об используемом компьютере, чтобы правильно интерпретировать определенные измерения. И определенно полезно знать эти детали, когда покупаешь компьютер, так как они, вместе со скоростями FSB и SDRAM, являются одними из важнейших факторов, определяющих производительность компьютера.
Склонный к приключениям читатель может также попытаться настроить систему. Иногда BIOS позволяет изменять некоторые или все из этих значений. У модулей SDRAM имеются программируемые регистры, где можно установить эти значения. Обычно BIOS выбирает наилучшее из значений по умолчанию. Если модуль RAM высокого качества, то может быть будет возможно уменьшить одну из задержек, не влияя на стабильность компьютера. Многочисленные оверклокерские сайты в Интернете предлагают уйму документации об этом. Делайте это на свой страх и риск, но не говорите потом, что вас не предупреждали.
2.2.3 Перезарядка
Наиболее часто упускаемая тема при рассмотрении доступа к DRAM это перезарядка. Как было показано в разделе 2.1.2, ячейки DRAM нужно постоянно освежать. И это не происходит незаметно для остальной части системы. Когда строка перезаряжается (единица измерения здесь строка (см. [5]) хотя в [2] и другой литературе утверждается иное), доступ к ней невозможен. Исследование в [2] показывает, что "удивительно, но организация перезарядки DRAM может драматически влиять на производительность".
Согласно спецификации JEDEC (Joint Electron Device Engineering Council), каждая ячейка DRAM должна перезаряжаться каждые 64мс. Если массив DRAM имеет 8192 строк, это означает, что контроллер памяти должен посылать команду на перезарядку в среднем каждые 7.8125 микросекунд (эти команды могут быть поставлены в очередь и поэтому на практике максимальный интервал между двумя из них может быть больше). Управлять расписанием команд на перезарядку является обязанностью контроллера памяти. Модуль DRAM помнит адрес последней перезаряженной строки и автоматически увеличивает счетчик адреса для каждой новой команды.
Программист мало может влиять на перезарядку и моменты времени, когда эти команды даются. Но важно иметь эту часть жизненного цикла DRAM в виду, когда интерпретируешь измерения. Если важное слово должно быть прочитано из строки, а строка в этот момент перезаряжается, процессор может быть в простое довольно большое время. Как долго длится зарядка, зависит от модуля DRAM.
2.2.4 Типы памяти
Стоит потратить немного времени на описание существующих типов памяти и их ближайших последователей. Мы начнем с SDR (Single Data Rate) SDRAM, так как они являются базисом для DDR (Double Data Rate) SDRAM. SDR были очень простыми. Скорость ячеек памяти и передачи данных была одинаковой.
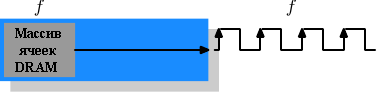
Рисунок 2.10: Операции SDR SDRAM
На рисунке 2.10 ячейка памяти DRAM может выдавать содержимое памяти с той же скоростью, с которой оно транспортируется по шине памяти. Если ячейка DRAM может работать на частоте 100МГц, то скорость передачи данных шиной будет 100Мб/с. Частота f для всех компонентов одинакова. Повышать пропускную способность чипа DRAM дорого, так как потребление энергии растет с ростом частоты. Учитывая огромное число массивов ячеек это невозможно дорого. {Энергопотребление = Динамическая емкость × Напряжение2 × Частота}. В действительности это ещё большая проблема, так как увеличение частоты также требует увеличения напряжения для поддержания стабильности системы. В DDR SDRAM (впоследствии называемая DDR1) пропускная способность была повышена без увеличения какой-либо из задействованных частот.
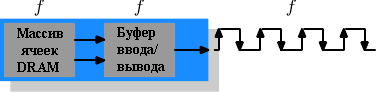
Рисунок 2.11: Операции DDR1 SDRAM
Различие между SDR и DDR1, как можно увидеть на рисунке 2.11 и понять из имени, в том, что за один цикл передается двойной объем данных. То есть чип DDR1 может передавать данные на увеличении и уменьшении уровня сигнала. Это иногда называют шиной с "двойной прокачкой". Чтобы сделать это возможным без увеличения частоты массива ячеек памяти применяется буфер. Буфер хранит по два бита на каждую линию данных. Для этого, в свою очередь требуется, чтобы массив ячеек на рисунке 2.7 имел шину данных из двух линий. Реализация этого тривиальна: нужно использовать одинаковый адрес колонки для двух ячеек DRAM и обращаться к ним параллельно. Изменения массива ячеек будут минимальными.
SDR DRAM были известны просто по их частоте (например, PC100 для 100МГц SDR). Чтобы улучшить звучание DDR1 DRAM маркетологи должны были изменить эту схему, так как частота не изменилась. Они приняли имя, которое содержит скорость передачи в байтах, которую поддерживает модуль DDR (он имеет шину шириной 64 бит):
100МГц × 64бит × 2 = 1600Мб/с
Следовательно, модуль DDR с частотой 100МГц называется PC1600. С 1600 > 100 все маркетинговые требования соблюдены - звучит намного лучше, хотя реальное улучшение только в два раза. {Я бы понял, если бы увеличили в два раза, а то получаются дутые числа.}
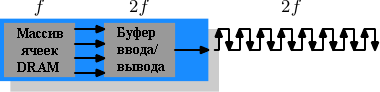
Рисунок 2.12: Операции DDR2 SDRAM
Чтобы получить от технологии ещё больше DDR2 включает ещё немного инноваций. Самое очевидное изменение, как можно видеть из рисунка 2.1 это удвоение частоты шины. Удвоение частоты означает удвоение пропускной способности. Так как удвоение частоты экономически неоправданно для массива ячеек, теперь требуется, чтобы буфер ввода/вывода получал по четыре бита за один цикл, которые он затем передает по шине. Это означает, что изменения в модуле DDR2 состоят в увеличении скорости буфера ввода/вывода DIMM. Это определенно возможно и не требует значительно больше энергии - это всего лишь один небольшой компонент, а не весь модуль. Имя, которое маркетологи придумали для DDR2, аналогично имени для DDR1, только в вычислении значения множитель два заменяется на четыре (теперь у нас шина с "четверной прокачкой"). Рисунок 2.13 показывает используемые сегодня имена модулей.
Частота
массиваЧастота
шиныСкорость
данныхИмя
(скорость)Имя
(FSB)133МГц 266МГц 4256Мб/с PC2-4200 DDR2-533 166МГц 333МГц 5312Мб/с PC2-5300 DDR2-667 200МГц 400МГц 6400Мб/с PC2-6400 DDR2-800 250МГц 500МГц 8000Мб/с PC2-8000 DDR2-1000 266МГц 533МГц 8512Мб/с PC2-8500 DDR2-1066 Рисунок 2.13: Имена модулей DDR2
В названии есть ещё один трюк. Скорость FSB, используемая ЦПУ, материнской платой и модулем DRAM выражена через "эффективную" частоту. То есть она умножается на 2 из-за того, что передача данных идет при повышении и понижении уровня сигнала тактового генератора и число увеличивается. Итак, модуль 133МГц с шиной 266МГц имеет "частоту" FSB 533МГц.
Спецификация DDR3 (настоящей, а не GDDR3, используемой в графических картах) подразумевает дальнейшие изменения, продолжающие логику перехода к DDR2. Напряжение будет понижено с 1.8В для DDR2 до 1.5В для DDR3. Так как энергопотребление пропорционально квадрату напряжения это одно дает 30% улучшения. Добавьте к этому уменьшение микросхемы и другие электрические улучшения, и DDR3 может на той же частоте потреблять половину энергии. А на большей частоте обходиться таким же количеством. Или можно вдвое увеличить емкость для такого же количества выделения тепла.
Массив ячеек модуля DDR3 будет работать на четверти скорости внешней шины, что потребует восьмибитного буфера ввода/вывода, больше по сравнению с четырехбитным в DDR2. На рисунке 2.14 изображена схема.
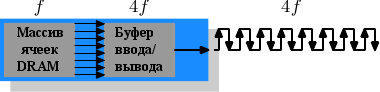
Рисунок 2.14: Операции DDR3 SDRAM
Скорее всего, поначалу модули DDR3 будут иметь немного большую задержку CAS чем DDR2, потому что DDR2 более зрелая технология. Поэтому использовать DDR3 будет иметь смысл только на более высоких частотах, чем те, которые достижимы для DDR2, или когда пропускная способность важнее, чем задержка. Уже ходят разговоры о модулях с напряжением 1.3В, у которых будет та же задержка CAS, как и у DDR2. В любом случае, возможность достичь более высоких скоростей из-за более быстрых шин перевесит увеличение задержки.
Одна возможная проблема с DDR3 состоит в том, что на скорости 1600Мб/с и выше, число модулей на канал может быть сокращено до одного. В ранних версиях это ограничение присутствовало для всех частот, так что можно надеяться, что со временем оно будет снято для всех частот. Иначе емкость систем будет жестко ограничена.
Рисунок 2.15 показывает ожидаемые имена модулей DDR3. JEDEC к этому времени одобрило первые четыре типа. Учитывая, что 45-нанометровые процессоры Intel имеют скорость FSB 1600Мб/с, необходимо иметь 1866Мб/с для рынка оверклокеров. Скорее всего, мы увидим это ближе к концу жизненного цикла DDR3.
Частота
массиваЧастота
шиныСкорость
данныхИмя
(скорость)Имя
(FSB)100МГц 400МГц 6400Мб/с PC3-6400 DDR3-800 133МГц 533МГц 8512Мб/с PC3-8500 DDR3-1066 166МГц 667МГц 10667Мб/с PC3-10667 DDR3-1333 200МГц 800МГц 12800Мб/с PC3-12800 DDR3-1600 233МГц 933МГц 14933Мб/с PC3-14900 DDR3-1866 Рисунок 2.15: Имена модулей DDR3
Вся память DDR имеет одну проблему - увеличение частоты шины делает трудным создание параллельных шин данных. Модуль DDR2 имеет 240 контактов. Все соединения до контактов данных и адреса должны быть сделаны так, чтобы они имели приблизительно одинаковую длину. Ещё более проблематично то, что когда на одной шине несколько модулей DDR, сигналы становятся все более и более искаженными для каждого дополнительного модуля. Спецификация DDR2 разрешает использовать только два модуля на одной шине (канале), DDR3 - только один модуль на высоких частотах. С 240 контактами на канал, один Северный мост не может хорошо управлять более чем двумя каналами. В качестве альтернативы можно использовать внешние контроллеры памяти (см. рисунок 2.2), но это очень дорого.
Все это означает, что материнские платы массовых компьютеров могут иметь не более четырех модулей DDR2 или DDR3. Это жестко ограничивает количество памяти, которое может иметь система. Даже старые 32-битные процессоры IA-32 поддерживали до 64Гб RAM, и потребность в большом количестве памяти растет даже для домашних систем, поэтому надо что-то делать.
Одно решение - это добавлять контролеры памяти в каждый процессор, как показано в начале этой главы. AMD делает это на линейке процессоров Opteron, и Intel будет делать в технологии CSI. Это может помочь до тех пор, пока количество памяти, которое способен использовать процессор, может быть присоединено к каждому процессору. В некоторых ситуациях это не так и этот подход приводит к архитектуре NUMA с её негативными эффектами. Для некоторых ситуаций нужно вообще другое решение.
Решение Intel для больших серверных машин, по крайней мере на ближайшие годы, называется Fully Buffered DRAM (FB-DRAM). Модули FB-DRAM используют те же компоненты, что и сегодняшние модули DDR2, что делает их относительно дешевыми в производстве. Разница в соединении с контроллером памяти. Вместо параллельной шины данных FB-DRAM использует последовательную шину (то же было у Rambus DRAM и у SATA, последователе PATA, и у PCI Express после PCI/AGP). Последовательной шиной можно управлять на значительно более высокой частоте, преодолевая негативный эффект сериализации, и даже увеличивая пропускную способность. Основные эффекты от использования последовательной шины:
- можно использовать больше модулей на одном канале,
- можно использовать больше каналов на одном Северном мосте/контроллере памяти,
- последовательная шина является полнодуплексной (две линии).
Модуль FB-DRAM имеет только 69 контактов, вместо 240 у DDR2. Использовать вместе несколько модулей FB-DRAM намного легче, так как электрическими эффектами такой шины легче управлять. Спецификация FB-DRAM позволяет использовать до 8 модулей на один канал.
Учитывая требования к соединениям, предъявляемые двухканальным Северным мостом, теперь возможно управлять шестью каналами FB-DRAM с меньшим количеством контактов: 2×240 против 6×69. Путь на плате до каждого канала также намного проще, что может помочь снизить цену материнских плат.
Параллельные шины с полным дуплексом слишком дороги для традиционных модулей DRAM - очень затратно удваивать количество линий. С последовательными линиями (даже если они разностные, как требует FB-DRAM) это не так, поэтому последовательная шина сделана полностью дуплексной, что означает, в некоторых ситуациях, что пропускная способность удваивается только из-за этого. Но это не единственный случай, когда параллелизм используется для увеличения пропускной способности. Так как контроллер FB-DRAM может обслуживать до шести каналов одновременно, пропускная способность при использовании FB-DRAM может быть увеличена даже для систем с небольшим количеством RAM. Там где система на DDR2 с четырьмя модулями имеет два канала, та же емкость может обслуживаться через четыре канала обычным контроллером FB-DRAM. Реальная пропускная способность последовательной шины зависит от того, какие чипы DDR2 (или DDR3) используются в модулях FB-DRAM.
Мы можем суммировать преимущества таким образом:
DDR2 FB-DRAM Контакты 240 69 Каналы 2 6 DIMM/канал 2 8 Max памяти 16Гб 192Гб Скорость ~10Гб/с ~40Гб/с
Есть отрицательные стороны FB-DRAM при использовании нескольких DIMM на одном канале. Сигнал задерживается, хотя и минимально для каждой DIMM в цепи, что означает увеличение задержки. Но для того же количества памяти на той же частоте FB-DRAM всегда будет быстрее, чем DDR2 и DDR3, так как на канал нужна только одна DIMM. Для систем с большим объемом памяти у DDR просто нет решения на массовых компонентах.
2.2.5 Выводы
Этот раздел должен был показать, что доступ к DRAM не может быть сколь угодно быстрым процессом. По крайней мере по сравнению со скоростью процессора и скоростью доступа процессора к регистрам и кэшу. Важно держать в уме различия между частотами ЦПУ и памяти. Процессор Intel Core 2 имеет частоту 2.933ГГц, и системная шина с частотой 1.066ГГц будут иметь отношение тактовых частот 11:1 (заметьте, что данные на шину подаются вчетверо быстрее её частоты). Простой в один цикл памяти означает простой 11 циклов процессора. В большинстве машин реально используются более медленные DRAM, что ещё более увеличивает задержку. Держите эти цифры в уме, когда мы будем говорить о простоях в последующих главах.
Графики для команд чтения показывают, что модули DRAM способны передавать данные с большой и устойчивой скоростью. Целые строки DRAM могут передаваться без единой задержки. Шина данных может оставаться на 100% загруженной. Для модулей DDR это означает, что в каждом цикле передается два 64-битных слова. Для модулей DDR2-800 на двух каналах это 12.8Гб/с.
Но доступ к DRAM не всегда последователен, если конечно он не специально так организован. Используются отдаленные друг от друга участки памяти, что означает, что неизбежно использование предварительной зарядки и новых сигналов RAS. Вот тогда все замедляется и модулям DRAM нужна помощь. Чем скорее случится предварительная зарядка и послан сигнал RAS, тем меньше расходы на использование новой строки.
Чтобы сократить простои и создать большее перекрытие по времени операций их вызывающих, используется аппаратная и программная предварительная выборка (см. раздел 6.3). Она также помогает переместить операции с памятью во времени так, что достаточно будет задействовать меньшее количество ресурсов позднее, перед тем как данные непосредственно понадобятся. Нередко возникает проблема, когда данные, произведенные в одном раунде нужно сохранить, а данные, необходимые в следующем раунде нужно прочитать. Перемещая чтение во времени, мы добьемся того, что операции чтения и записи не нужно будет делать одновременно.
| Назад | Оглавление | Вперед |