





Библиотека сайта rus-linux.net
Фрагментация под Linux: Настройка файловой системы Ext3
Оригинал: Tuning
the Linux file system Ext3
Автор: Oliver Diedrich
Дата: 27 октября 2008
Свободный перевод: Алексей
Дмитриев
Дата перевода: 8 ноября 2008
Ext3 - это стандартная файловая система для Линукс; она надежная, быстрая, устойчивая к ошибкам, и подходит для любой сферы использования. Однако, с точки зрения эффективности, Ext3 может стать узким местом. Даже по поводу фрагментации к этой файловой системе есть вопросы.
Как и предшествовавшая ей Ext2, файловая система Ext3 утвердилась в качестве стандарта файловой системы для Линукс; Ext2/Ext3 обеспечивают хорошую производительность, а уж испытаны они лучше, чем какая-либо другая Линуксовая файловая система, в силу своего широкого распространения. Больше того, они столь надежны, что позволяют спасти большую часть информации с частично поврежденного жесткого диска. Это отличает Ext2/Ext3 от других файловых систем типа ReiserFS, которая, вследствие чувствительности структур управления жесткими дисками, может потерять все данные из-за повреждения нескольких секторов.
В дополнении к надежным структурам метаданных, Ext3 имеет хороший инструмент проверки: e2fsck может спасти большую часть данных из поврежденных файловых систем. Позже в этой статье мы раскроем несколько секретов успешного применения команды fsck даже в практически безнадежных ситуациях. Если уже не помогает e2fsck, значит файловая система настолько повреждена, что данные могут быть извлечены только посекторно при помощи низкоуровневых поисковых программ вроде dd_rescue и вручную собраны в файлы.
В этой статье, говоря о Ext3, мы также имеем в виду и Ext2. Главное различие между ними в том, что Ext3 имеет журнал, который гарантирует постоянство файловой системы и уменьшает время проверки смонтированной файловой системы с нескольких часов до нескольких секунд. Ext2 и Ext3 полностью совместимы; Ext3 можно примонтировать как Ext2, в этом случае ее журнал просто не будет использован. А при помощи команды
tune2fs -j
можно "научить" Ext2 вести журнал.
Простота
Как и всякая порядочная Юникс-подобная файловая система, Ext3 использует три главных структуры данных: директории, индексные дескрипторы (inode) и блоки данных (data blocks). Директории содержат только записи имен файлов и соответствующих им номеров индексных дескрипторов (индексы файлов). При этом на один и тот же индексный дескриптор могут указывать записи нескольких директорий. Это положение называется жесткой ссылкой. Мягкой или символической ссылкой (симлинк) называется положение, когда содержимое одного файла указывает на другой файл, а не на индексный дескриптор. Сами директории сохраняются на жестком диске как обычные файлы, отличающиеся от последних только типом файла и тем, что их содержимое представляет собой обязательную структуру.
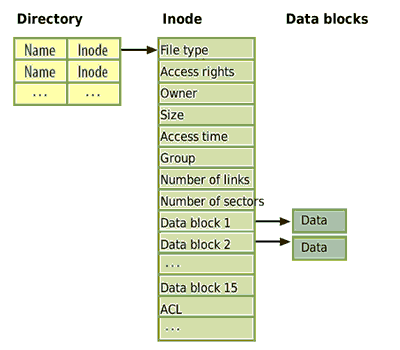
Рис 1. Основная структура информации в файловых системах Ext2/Ext3: директории, индексные дескрипторы и блоки данных.
Индексные дескрипторы содержат всю необходимую информацию о
файлах, кроме их имени: размер, тип файла (обычный файл, директория,
файл устройства, именованный канал, сокет, или символическая ссылка),
владельца файла, количество жестких ссылок, права и время доступа, а
также номера блоков данных, содержащих информацию. Эти сведения, за
исключением номеров блоков данных, можно получить при помощи команды
stat. Некоторые сведения можно получить при помощи команды ls.
Команда ls -i выводит номер индексного дескриптора файла.
Индексные дескрипторы сохраняются в таблицах, создаваемых программой mke2fs в зарезервированных участках файловой системы. Если имя симлинка короче 60 символов, то оно также сохраняется прямо в дескрипторе (это называется быстрой символической ссылкой). Во всех остальных случаях имя файла, на который указывает симлинк, сохраняется в файле, имеющем индексный дескриптор.
И, наконец, собственно информация сохраняется в блоках данных. Они занимают несколько секторов по 512 байт (наименьший адресуемый участок жесткого диска). Ext3 использует размер блоков в 1024, 2048 или 4096 байт - нужный размер задается при создании файловой системы при помощи программы mke2fs, форматирующей носитель в файловую систему Ext3. Теоретически, Ext3 поддерживает размер блоков вплоть до 64 килобайт, но на практике архитектуры х86 и х64 устанавливают максимум в 4 Кб - такой размер блока соответствует размеру страницы памяти в RAM, которыми оперирует ядро. Это делает манипуляции со страницами памяти проще для операционной системы.
Большие блоки упрощают работу с данными, и позволяют создавать файловые системы большего размера. Так, Ext3 использует 32-битный доступ к номерам блоков, что означает примерно миллиард адресуемых блоков - 4Тб при размере блока 1024 байта, и 16 Тб при размере блока 4096 байт. Кроме того, для управления мелкими блоками файловой системе требуется больше места на диске.
С другой стороны, крупные блоки впустую тратят много дискового
пространства, так как файл всегда занимает целый блок, даже если в
нем содержится всего несколько байт. В среднем, каждый файл
использует только половину блока - чем крупнее блоки и меньше файлы,
тем ощутимее потери. Этот эффект называется внутренней фрагментацией.
Ext3 содержит структуры, позволяющие управлять несколькими
фрагментами внутри одного блока данных (эти фрагменты являются
остаточными частями файлов, не занимающими целый блок), и программа
mke2fs предлагает для этого параметр -f. Но, к сожалению,
это свойство файловой системы пока не реализовано.
При форматировании носителя, программа mke2fs приводит размер
блока в соответствие с размером файловой системы: для системы до 512
Мб размер блока будет 1Кб, в остальных случаях размер блока равен
4Кб. Опция mke2fs -b позволяет определять размер блока
вручную - это имеет смысл, когда файловая система предназначена для
размещения преимущественно очень мелких файлов, и потери дискового
пространства будут иметь значение.
Скорость
В целом, устройство файловой системы Ext3 оптимизировано для выполнения приложениями типичной для них работы - читать файлы с определенными именами или записывать в эти файлы. Для файловой системы это означает необходимость быстро находить данные, принадлежащие данному имени файла. Вся система крутится вокруг индексных дескрипторов, которые доступны через записи в директориях, и которые содержат метаданные и указатели на блоки данных. Обратное отображение невозможно: чтобы выяснить, какому файлу принадлежит определенный блок данных, придется прочесать все дескрипторы в поисках нужного номера блока, а затем все директории в поисках соответствующего номера дескриптора. Отладочные программы низкого уровня, входящие в набор программы debugfs делают это при помощи команд icheck и ncheck (см. Приложение, Отладчик файловой системы).
Чтобы быстро перебрать все дескрипторы, доступ к ним должен быть чрезвычайно эффективен. Система гарантирует это, в процессе форматирования записывая дескрипторы в стационарные таблицы на диске. Одним из следствий этого является невозможность изменить количество дескрипторов после установки системы. Так как каждый файл должен соответствовать отдельному дескриптору, в системе не может быть больше файлов, чем дескрипторов. По умолчанию, mke2fs создает один дескриптор на каждые 4Кб в системе размером до 512Мб, в остальных случаях - один дескриптор на каждые 8Кб.
Тот, чье мнение не совпадает с мнением программы mke2fs, и хочет,
скажем, разместить немного крупных файлов, или наоборот, очень много
мелких файлов, может воспользоваться опцией -i при запуске
команды mke2fs, чтобы самому задать, сколько байт данных будет
приходиться на каждый дескриптор. Если будет мало дескрипторов, то
можно создать мало файлов, но при этом освободится несколько мегабайт
места на диске, так как конструктивно каждый дескриптор занимает 128
байт на жестком диске. Большое количество дескрипторов позволяет
создать больше файлов.
Опция программы mke2fs -T type дает доступ к нескольким
настройкам, прописанным в файле /etc/mke2fs.conf:
- small (по умолчанию с файловыми системами размером до 512Мб) задает размер блока 1Кб при соотношении: один дескриптор на каждые 4 блока;
- news задает размер блока в 4Кб при одном дескрипторе на блок;
- largefile задает размер блока 4 Кб при одном дескрипторе на 256 блоков;
- largefile4 задает размер блока 4Кб при одном дескрипторе на 1024 блоков.
Фиксированный размер дескриптора в 128 байт также способствует быстрому доступу к этому центральному элементу организации информации. Применив при создании файловой системы опцию
mke2fs -I inode size
пользователь может задать большее значение, которое должно делиться без остатка на 128. Ext3 может использовать увеличенные дескрипторы для сохранения дополнительных атрибутов.
Не всегда прямо
Каким образом удается втиснуть номера миллионов блоков данных, необходимых для описания гигабайтных файлов в статичную информационную структуру размером 128 байт? - Один дескриптор в файловой системе Ext3 сохраняет ровно 15 номеров блоков. Первые 12 указывают напрямую на блоки данных; блок 13 указывает на блок данных, содержащий номера блоков (непрямая адресация блоков, иногда называемая косвенной), блок 14 указывает на блоки, указывающие на блоки с номерами блоков (двойная непрямая адресация блоков), а блок 15 производит тройную непрямую адресацию блоков. Таким образом, при размере блока в 4Кб (а это 1024 номеров блоков, если считать по 4 байта на непрямой блок) один дескриптор может содержать 12 + 1024 + 10242 + 10243, то есть около миллиарда номеров блоков.
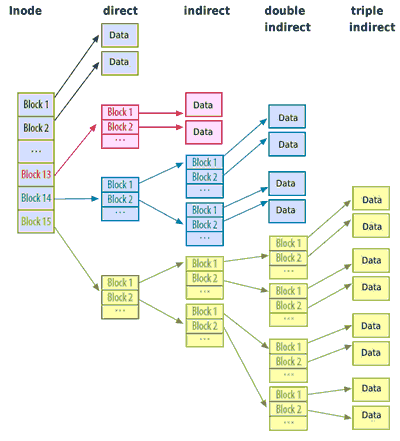
Рисунок 2. Непрямая адресация блоков позволяет при помощи 15 номеров блоков адресовать несколько терабайт данных
Найденный нами максимальный размер файла более 4 Тб есть только теоретическое предположение, так как в дескрипторе сохраняется номер принадлежащего файлу сектора жесткого диска размером в 512 байт. Команда stat программы debugfs выводит это значение как "block count" (счет блоков). А так как этот счет блоков 32-битный, то максимальный размер файла в Ext3 на самом деле только 2Тб.
Между прочим, двухтерабайтный максимальный размер файла не обусловлен свойствами файловой системы Ext3, а является следствием организации системных вызовов доступа к файлам. Работа и структура информации доступа к файлу традиционно использует предварительно заданное 32-битное смещение (адресная ссылка (pointer), адресующая любой байт внутри файла). В результате, максимальный размер файла равен 231-1 байт. Это ограничение было снято введением Поддержки Длинных Файлов (Large File Support, LFS), использующим 64-битное смещение.
Группы блоков
Помимо директорий, таблиц индексных дескрипторов и блоков данных, файловая система Ext3 применяет еще несколько информационных структур. Две битовые карты содержат записи о том, какие из блоков данных находятся в работе, а какие свободны. Чтобы обеспечить эффективный доступ в эту область, Ext3 организует файловую систему в группы блоков - нечто вроде разделов внутри файловой системы.
В процессе чтения, записи и создания файлов, считывающие головки жестких дисков перепрыгивают между блоками данных, директориями, таблицами дескрипторов, самими дескрипторами, битовыми картами блоков. Между тем, каждое перемещение головок занимает в среднем несколько миллисекунд - время достаточное, чтобы прочитать мегабайт данных с быстрого диска. Учитывая, что перемещения головок занимают тем больше времени, чем дальше нужные сектора диска находятся друг от друга, предпочтительнее сохранять "родственные" части структуры файловой системы и данных в близком соседстве.
Ext3 достигает этого при помощи групп блоков. Каждая группа блоков содержит:
- идентификатор группы блоков (block group descriptor), ведущий статистику о количестве групп блоков, находящихся в работе, кроме того,
- "кусок" таблицы дескрипторов и
- ту часть битовой карты дескрипторов и блоков, которая относится к этому "куску"
- и сами блоки данных, принадлежащие к этой группе блоков.
Ext3 старается создавать файлы таким образом, чтобы метаданные - дескрипторы и директории - и связанные с ними блоки данных, находились внутри одной группы блоков.
Количество созданных групп блоков зависит от размеров файловой
системы. Хотя этот параметр может быть установлен при помощи опции
mke2fs -g, разработчики Ext3 советуют не настраивать его,
так как программа mke2fs выберет оптимальное значение. Вследствие
того, что только один блок данных выделен для битовой карты группы
блоков, то эта группа может содержать максимально 32 768 блоков, или
128Мб при размере блока в 4Кб.
Суперблок
И последняя информационная структура файловой системы Ext3 - это суперблок, описывающий саму файловую систему. Он содержит всю необходимую информацию для правильной расшифровки структуры файловой системы:
Размер блока
Количество блоков и дескрипторов
Группы блоков
- Размер дескриптора
Первый незарезервированный дескриптор (несколько дескрипторов зарезервированы для внутренних нужд системы, например второй дескриптор - за корневой директорией, а восьмой - за журналом в Ext3)
Всю эту (и много другой) информации можно получить при помощи
программы debugfs. Нужно запустить в терминале программу
debugfs, которая содержит много инструментов отладки файловой
системы. В данном случае, понадобится ее команда stats. Помимо
debugfs, существует команда dumpe2fs -h, которая также
выводит информацию о суперблоках.
Блоки, помеченные как резервные (5% от общего числа блоков по
умолчанию, этот процент может быть изменен опцией mke2fs -m),
доступны только суперпользователю (root); это сделано, чтобы дать
системе немного жизненного пространства, на случай если пользователи
полностью заполнят файловую систему.
Кроме всего этого, супеблок несет информацию о состоянии системы: о количестве свободных дескрипторов и блоков; о том, когда система в последний раз была примонтирована, когда в последний раз была проверена программой e2fsck; о текущем статусе (чистая - clean, если все в порядке). Здесь же находятся все остальные настройки, позволяющие провести проверку файловой системы каждый раз, когда пользователю нужно "по быстрому" запустить систему. Ext3 помнит: и сколько месяцев прошло, и сколько раз система была запущена с момента последней проверки e2fsck. Когда один из лимитов достигнут, система запускает принудительную проверку. Если ваш компьютер запускается часто, то можно без опаски увеличить эти лимиты при помощи команды:
tune2fs -c 100 -i 180
Что означает 100 месяцев, или 180 запусков системы между проверками e2fsck (при ежедневном запуске компьютера это составит примерно полгода). Нулевое значение совершенно отключает автоматическую проверку. Хотя советы не делать этого слышны по всему Интернету, они в большой степени потеряли актуальность - дефекты диска скорее выявит программа smartmontools, которая напрямую проверяет состояние дисков, а также выявляет проблемы с памятью или чипсетом раньше, чем выявятся повреждение структуры Ext3.
Надежность
Поскольку суперблок жизненно важен для файловой системы, программа mke2fs обращается с ним весьма осторожно и записывает на диск в нескольких различных местах. Если программа e2fsck отказывается работать с поврежденной файловой системой по причине испорченного суперблока, можно проинструктировать программу воспользоваться запасным суперблоком:
e2fsck -b superblock
Программа mke2fs сообщает номера блоков с альтернативными суперблоками сразу после создания файловой системы, однако пользователи часто забывают их записать. Существует полезная опция программы mke2fs, которая может помочь:
mke2fs -n device
программа только делает вид, что создает файловую систему, но при этом выводит все ее параметры, включая местоположение суперблоков. Естественно, что этот фокус сработает, только если mke2fs запущена с теми же самыми параметрами, что и при создании файловой системы. К счастью, процесс форматирования обычно не нуждается ни в каких опциях вообще - mke2fs автоматически выбирает значения, подходящие для большинства приложений.
Для самого плохого случая mke2fs предлагает опцию -S,
которая только переписывает заново суперблок и идентификаторы
(описатели) групп блоков, тогда как директории, также как дескрипторы
и битовые карты остаются нетронутыми. После этой процедуры требуется
запустить программу e2fsck. При удачном развитии событий, после этого
все файлы снова становятся доступны, но, увы, гарантии никакой, и в
худшем случае, все данные пропадут. Само собой разумеется, что
команду mke2fs -S следует запускать с теми же параметрами,
что и при создании файловой системы.
Дополнительные параметры
Среди прочей информации суперблок может содержать сведения об опциях монтирования файловой системы, которые будут использованы без явного указания их пользователем. Так, например, команда:
tune2fs -o acl
означает, что файловая система всегда будет монтироваться с
поддержкой Списков Управления Доступом (Access Control Lists - ACL).
Метки, или имена томов файловой системы, которые используются в
/etc/fstab некоторых дистрибутивов также сохраняются в суперблоке, и
могут быть заданы командой tune2fs -L когда файловая система
уже создана, или программой mke2fs при ее создании.
"Свойства файловой системы" (file system features) определяют всевозможные особенности файловой системы:
- Нуждается ли система в проверке (флаг needs_recovery устанавливается при монтировании и удаляется при отмонтировании файловой системы и показывает, была ли файловая система правильно отмонтирована)
- Может ли файловая система быть увеличена при помощи команды resize2fs (resize_inode)
- Поддерживает ли файловая система файлы более 2Гб размером (large_file)
- Было ли создано ограниченное число запасных суперблоков (sparse_super)
- Содержат ли записи в директориях сведения о типе файла (filetype)
- Должны ли записи в директориях быть представлены в виде дерева (dir_index)
Некоторые из этих свойств могут быть заданы при помощи команды
tune2fs -O (приставка ^ отключает уже заданное
свойство). По соображениям безопасности, после этой процедуры следует
запустить команду e2fsck -f. А еще лучше все эти свойства
задавать программой mke2fs -O при создании файловой системы.
Те свойства, что должны быть установлены по умолчанию, программа
mke2fs находит в файле /etc/mke2fs.conf. Большинство дистрибутивов
устанавливают по умолчанию sparse_super, filetype, resize_inode
и dir_index, а если файловая система поддерживает длинные
файлы, то и large_file.
Списки или деревья
Свойство dir_index, также иногда называемое htree,
чрезвычайно важно для эффективности файловой системы. Ext2
первоначально сохраняла имена файлов внутри директории как связный
список. Эта простая информационная структура имеет существенный
недостаток - операции становятся все медленнее по мере роста числа
записей. В сравнении файловых систем, проведенном пять лет назад, мы
выяснили, что скорость Ext3 резко падает, если директория содержит
всего несколько тысяч файлов.
С того времени Ext3 научилась управлять директориями при помощи
древовидных структур, также как и ее конкуренты ReiserFS, XFS и JFS.
Если установлено свойство dir_index, скорость операций в
директориях радикально повышается. Падение производительности
происходит только если директории заполнены сотнями тысяч файлов.
Обычно это вызвано эффектом кэширования - чем меньше основная память,
тем раньше наступает снижение производительности. Похоже, что ядро
Линукс не использует избытки памяти для кэширования структур
директорий - в однопользовательском режиме не наблюдалось повышения
производительности при увеличении RAM с 1 до 2 Гб. В обычных
операциях с сериями дополнительных процессов, мы, однако, хорошо
видели разницу между одним и двумя гигабайтами RAM.
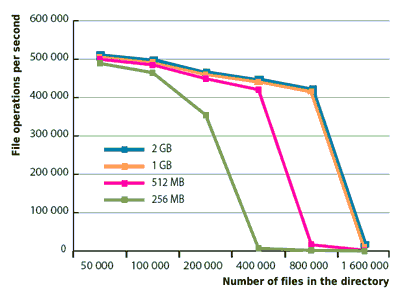
Рисунок 3. В зависимости от количества доступной
памяти, скорость Ext3 может снижаться в "густонаселенных"
директориях. Мы измеряли заполнение директорий программой readdir()
в однопользовательском режиме.
Можно подключить опцию dir_index уже после создания
файловой системы при помощи команды:
tune2fs -O dir_index
хотя в этом случае она будет применяться только ко вновь
создаваемым директориям. Существующие директории на отмонтированной
файловой системе могут быть переведены в режим dir_index при
помощи команды
e2fsck -fD
после того, как свойство dir_index будет активировано
предыдущей командой. Из соображений надежности, после этой процедуры
нужно снова запустить команду e2fsck -f.
Эта опция также полезна, если файлы в директориях постоянно
создаются и удаляются. Так как Ext3 не удаляет имена удаленных файлов
из файлов директорий (а мы помним, что директория - это тоже тип
файла) и они продолжают расти, даже если большинство записей не
используется. Команда e2fsck -fD удаляет ненужные записи из
файлов директорий и пересоздает дерево имен файлов, что может
существенно повысить скорость операций в больших директориях.
Журналирование
Основное отличие Ext3 от Ext2 - это наличие журнала, о котором мы уже упоминали. Его идея проста. Любое изменение в файловой системе, например создание нового файла, отражается во многих местах системы:
создается новая запись в директории,
создается новый индексный дескриптор,
блоки данных и дескриптор помечаются как зарезервированные в битовых картах блоков и дескрипторов,
изменяется дата последнего доступа в дескрипторе директории,
обновляется статистика файловой системы в суперблоке,
- и сами данные записываются в соответствующие блоки.
Если во время всех этих операций произойдет отключение питания, либо случится сбой системы, то файловая система станет неполноценной, например будет существовать дескриптор без соответствующей ему записи в директории, что в результате даст безымянный файл в директории lost+found после проверки e2fsck.
Чтобы предотвратить такое развитие событий, Ext3 первым делом записывает изменения в свой журнал. До тех пор пока все перечисленные групповые изменения (транзакция) не войдут в журнал, старые метаданные файловой системы останутся неизменными. Когда транзакция закончится, и новые метаданные будут в журнале, только тогда они могут быть перенесены в файловую систему при первой возможности. Если случается сбой, e2fsck достаточно перенести завершенные транзакции из журнала в файловую систему, чтобы обеспечить целостность и связность системы. Незавершенные транзакции в журнале игнорируются, так как старые метаданные в файловой системе остались в силе.
Ext3 имеет несколько различных режимов работы с журналом. Эти режимы могут быть выбраны во время монтирования при помощи команды:
mount -O data=MODE
По умолчанию устанавливается режим data=ordered, - Ext3 сразу
пишет данные на диск, прежде чем измененные метаданные попадут в журнал; в
этом случае обеспечивается только целостность метаданных. Если происходит
сбой или потеря питания прежде чем завершится транзакция в журнал, то уже
записанные на диск данные пропадут, так как вновь занятые блоки не будут
связаны со своими дескрипторами и не будут помечены как занятые в битовой
карте блоков.
Опция data=journal означает, что сами данные проходят
через журнал, но это радикально снижает быстродействие системы, так
как все данные приходится записывать на диск дважды.
При выборе опции data=writeback, метаданные в журнале могут
быть записаны прежде чем сами данные. Это немного повысит скорость,
так как Ext3 в этом случае лучше оптимизирует доступ на запись,
однако в случае сбоя, старые данные могут оказаться в якобы вновь
созданных файлах, и файлы, которые считались правильно созданными,
окажутся пустыми.
Чтобы повысить быстродействие системы, журнал можно разместить на другом диске, отдельно от файловой системы - это позволит осуществлять одновременный доступ к файловой системе и к журналу. Для этого необходимо сначала создать внешний журнал при помощи команды:
mke2fs -O journal_dev DEVICE
а затем запустить команду
mke2fs -J device=DEVICE
Есть между файловыми системами Ext2 и Ext3 еще одно отличие. Эти файловые системы по-разному удаляют файлы. Ext2 только записывает в дескриптор время удаления файла (и помечает данные блоки данных и дескриптор как свободные в битовых картах блоков и дескрипторов). Ext3, кроме этого, еще удаляет номера блоков в дескрипторе, что облегчает восстановление системы после сбоя.
В результате Ext2 имеет программы восстановления удаленных файлов - команду lsdel - часть набора программ debugfs, и специальные программы восстановления удаленных файлов (undelete)[1]. В Ext3 эти программы не работают.
Фрагментация
Если вы спросите приверженца Линукс о программе дефрагментации, обычным ответом будет: "Она не нужна", или: "Ext3 не фрагментирует", или: "Только Windows требует дефрагментации". Но фрагментация затрагивает в той или иной степени все файловые системы.
Рассматривая вопрос о фрагментации в Ext3, необходимо различать два весьма различных понятия: внутренняя фрагментация, о которой мы уже упоминали, и внешняя фрагментация. Последняя относится к файлам, чьи блоки данных не следуют непрерывной чередой друг за другом, но разбросаны по всему диску. В результате считывающие головки тратят больше времени на доступ для чтения и записи. Внутренняя фрагментация "только" транжирит дисковое пространство, тогда как внешняя снижает быстродействие системы.
Ext3 весьма успешно справляется с внешней фрагментацией и минимизирует перемещения считывающих головок - например пытается заготовить сектор из восьми последовательно идущих блоков для вновь создаваемых файлов. Кэширование записи также обеспечивает запись на диск "в один проход" тех данных, которые приложение записывало кусками, что гарантирует непрерывную область на диске. Конечно, кэширование записи не помогает, когда файлы растут медленно, например директории, которые заполняются от случая к случаю. Фрагментация также неизбежна в файлах различного размера, постоянно создаваемых и удаляемых, что приводит к появлению брешей из пустых блоков.
Борьба с фрагментацией накладывается на еще одну оптимизирующую стратегию - локализацию данных и метаданных, которую пытаются достичь при помощи групп блоков. Из-за того, что Ext3 пытается сохранить файлы одной директории в одной группе блоков, в ней возникает фрагментация, хотя рядом на диске может находиться большая непрерывная свободная область. Утверждение, что Ext3 начинает фрагментировать только при заполнении файловой системы на 80-90% не всегда верно. В зависимости от стиля работы, файловая система может быть фрагментирована и при изобилии свободного места.
Так, например, мы обнаружили сильно фрагментированные свободные области на интенсивно работающем IMAP сервере, сохраняющий все письма в индивидуальных файлах, несмотря на то, что более 900Гб дискового пространства на 1,4Тб диске было свободно.
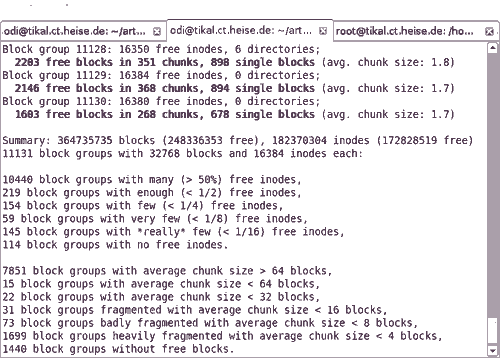
Рисунок 4. На почтовом сервере IMAP, который сохраняет каждое письмо в индивидуальном файле, свободные зоны во многих группах блоков сильно фрагментированы.
Проверка
Степень фрагментации можно проверить программой dumpe2fs, которая, будучи запущена без опций, выведет фрагментацию свободного пространства для каждой группы блоков. В идеале должна существовать одна непрерывная зона свободных блоков в каждой группе блоков; чем меньше зона свободных блоков, тем больше вероятность расщепления вновь создаваемых файлов на несколько фрагментов. В худшем случае, по всей группе блоков разбросаны отдельные свободные блоки. Можно осторожно использовать программу dumpe2fs на примонтированной файловой системе, хотя это может дать противоречивые результаты - первоначальные статистические сводки для каждой группы блоков, например, могут показывать иное количество блоков, чем результирующий список индивидуальных блоков.
Так как вывод программы dumpe2fs может стать весьма обескураживающим с сотнями и тысячами групп блоков, то мы создали скрипт на языке perl: eval_dumpe2fs perl script[2], который читает вывод dumpe2fs и выдает суммарную сводку статистики.
Скрипт определяет для каждой группы блоков, сколько свободных блоков объединены в зоны минимум по два блока ("ломти" - chunks), а сколько индивидуальных блоков, и вычисляет средний размер этих ломтей ("avg. chunk size"). Критические значения выделяются полужирным шрифтом. Суммарная статистическая сводка показывает, сколько групп блоков фрагментированы и в какой степени.
Программа dumpe2fs также показывает, сколько дескрипторов остаются незанятыми в каждой группе блоков. Если группа блоков содержит множество мелких файлов, все дескрипторы могут быть израсходованы раньше, чем закончатся свободные блоки. Хотя такая ситуация не влияет поначалу на быстродействие, если слишком много групп блоков останутся без дескрипторов, то Ext3 не сможет больше гарантировать местонахождение данных и метаданных. А если в файловой системе закончатся все дескрипторы, то она не сможет больше создавать файлы, несмотря на обилие свободных блоков.
Измерение
Понятно, что знание степени фрагментации свободного места на диске не является самоцелью - это лишь позволяет судить, насколько успешно Ext3 сможет избежать фрагментации вновь создаваемых файлов. Степень фрагментации уже существующей файловой системы также представляет интерес.
После проверки файловой системы, e2fsck выдает процент несмежных
файлов. Для правильно отмонтированной файловой системы, проверку
усиливают опцией -f. Даже при заполненной файловой системе,
этот процент поразительно мал - обычно выражается однозначным числом.
Причина в том, что e2fsck считает среди прочих и файлы, вовсе не
содержащие блоков данных, такие как: пустые файлы, файлы
символических ссылок, файлы устройств. Кроме того, типичная Линукс
система содержит множество файлов, меньших 4Кб, то есть занимающих
один блок (если размер блока 4Кб), тут нечего фрагментировать. Даже
при максимальной фрагментации, количество фрагментированных файлов не
может превысить общего количества файлов, занимающих больше одного
блока.
Наша программа ext2_frag[3] использует другой подход, и не учитывает пустые файлы и файлы устройств. Она группирует файлы в несколько классов, в соответствии с количеством занимаемых ими блоков. Статистическая сводка этой программы показывает процент фрагментации среди файлов, занимающих больше одного блока, и этот процент обычно в два-три раза выше того, что выдает e2fsck, считающая все файлы.
Вообще говоря, подсчет количества фрагментированных файлов, не говорит ничего о степени фрагментации файла - просто различаются фрагментированные и нефрагментированные файлы. Поэтому программа ext2_frag подсчитывает количество фрагментов на один файл для каждого класса файлов.
Общая фрагментация станет особенно наглядной, если соотнести количество несмежных блоков с количеством потенциальных перемещений головок диска. Чтобы его вычислить, нужно: для каждого файла, из количества блоков вычесть единицу (n_blocks-1). Эта цифра и будет теоретическим максимумом перемещений головок диска. В самом деле, если в файле всего два блока, то возможно лишь одно перемещение - между блоком 1 и блоком 2, и так далее. Теперь возьмем общее число несмежных блоков и разделим его на теоретический максимум перемещений головок (суммированный по всем файлам). Получим число от 0 до 1, а если умножить его на 100, то получим некий процент - Индекс Фрагментации, как он называется в программе ext2_frag (fragmentation index). Здесь есть одна натяжка, или особенность: Если каждый файл состоит из одного блока, то несмежных блоков нет вообще, так что и число реальных, и число максимально возможных перемещений головок равно нулю. На ноль делить нельзя, но мы принимаем в этом случае 0/0 = 0. Нулевое значение Индекса Фрагментации означает, что все файлы сохранены в одном месте, а значение 100 означает максимальную фрагментацию.
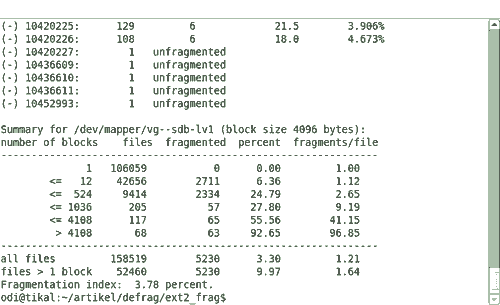
Рисунок 5. На персональных рабочих станциях фрагментация весьма незначительна.
В пакете e2fsprogs имеется также программа filefrag,
подсчитывающая, на сколько фрагментов разбит файл. Программа также
сообщает минимальное число фрагментов, необходимое для размещения
файла (файлы длиннее 128Мб не влезут в одну группу блоков, и
вынужденно должны быть разбиты на фрагменты).
Немного менее удобной является программа fragments[4],
которая просматривает целые директории и может работать с древовидной
структурой, используя опцию -r. Программа выдает как
статистическую сводку по директории (опция -d), так и
сведения о фрагментации отдельного файла (опция -f).
В то время как программа ext2_frag осуществляет доступ к файловой системе на низком уровне, и анализирует содержимое каждого дескриптора, чтобы подсчитать занятые блоки, программы filefrag и fragments используют специальную программу ioctl, которая определяет блоки данных, занятые данным файлом. Программа ioctl может работать только с обычными файлами, а не с директориями. Поэтому результаты этих программ для одной и той же файловой системы могут слегка различаться. Смотрите Приложение Измерение фрагментации для более подробного ознакомления.
Дефрагментация
Фрагментация снижает быстродействие ввода/вывода, так как операции считывания и записи замедляются излишними передвижениями головок дисков. Однако для многих приложений это не слишком важно, в большинстве случаев доступ к диску имеют сразу несколько приложений, что приводит к одновременной обработке нескольких файлов. Линукс минимизирует перемещения головок, так организуя доступ на чтение и запись, что большинство файлов обрабатываются из кэша. Благодаря опережающему считыванию (readahead) файлов, данные зачастую бывают прочитаны прежде, чем приложение запросит их.
Однако, при интенсивном вводе/выводе, например при постоянной записи и считывании большого количества данных, влияние фрагментации на производительность системы может стать вполне заметным. Мы экспериментировали с нашим Cyrus IMAP сервером, обрабатывающим интенсивный почтовый трафик, и сохраняющим каждое письмо в отдельном файле. Несмотря на обилие свободного места, четверть всех файлов, превышающих один блок, были фрагментированы. В том числе небольшие файлы, длиною меньше 48Кб, использующие прямую адресацию блоков (см. таблицу) В таких случаях очень возможно, что дефрагментация улучшит ситуацию.
|
number of blocks |
files |
fragmented |
percent |
fragments/file |
|
1 |
5722303 |
0 |
0.00 |
1.00 |
|
<= 12 |
3492714 |
761372 |
21.80 |
1.37 |
|
<= 524 |
513126 |
154964 |
30.20 |
9.30 |
|
<= 1036 |
26247 |
9233 |
35.18 |
64.78 |
|
<= 4108 |
21673 |
9670 |
44.62 |
148.23 |
|
> 4108 |
2462 |
1518 |
61.66 |
380.00 |
|
all files |
9778525 |
936757 |
9.58 |
2.16 |
|
files > 1 block |
4056222 |
936757 |
23.09 |
3.80 |
|
Fragmentation index: 8.80 percent. |
||||
Таблица 1. Только треть файловой системы задействована, однако Ext3 фрагментирована.
Между тем дефрагментатора для Ext3 не существует. Программа
ext2_defrag, созданная много лет тому назад, долгое время не
развивалась, и не поддерживает современные версии Ext2 и Ext3.
Единственный способ дефрагментации системы состоит в том, чтобы
скопировать все файлы во вновь созданную файловую систему. А можно
упаковать их в tar архив, который, в идеале, расположен в другой
файловой системе. Затем следует удалить оригиналы файлов, а потом
распаковать архив. Эта операция имеет приятный побочный эффект:
воссозданные директории будут содержать только действительно
находящиеся в них файлы.
При помощи вышеописанных программ, измеряющих фрагментацию, вы можете выявить директории, наиболее подверженные фрагментации (например те, что часто используются каким-либо приложением для создания и удаления файлов) и можете провести дефрагментирующее копирование только этих директорий. В случае с нашим IMAP сервером, копирование дало ощутимый эффект - во время интенсивного почтового трафика, пики ввода/вывода существенно снизились (odi[5]).
Приложения
Отладчик файловой системы
Программа debugfs (входящая в пакет e2fsprogsм) это прекрасный инструмент для исследования лабиринтов Ext3. Команды:
stat file_name
и
stat <inode number>
выдают всю информацию относительно дескриптора, включая блоки данных, задействованные файлом.
mi используется для изменения содержания дескриптора -
иногда это последний способ спасти поврежденный файл; ls
служит для исследования структур директории; stats сообщает
подробности про суперблок; lsdel выводит список удаленных
файлов в Ext2; ncheck определяет имя файла, принадлежащего
дескриптору, но не принимает в расчет жесткие ссылки; icheck
выводит все дескрипторы, указывающие на блок данных; cat
выводит содержимое файла на экран, а dump - в новый файл;
help выводит список всех команд debugfs.
Программа debugfs может смело применяться к файловым системам, смонтированным и находящимся в работе, так как открывает по умолчанию доступ только на чтение (ro). Однако, если вы используете команду
debugfs -w device
для записи в вашу систему, вы должны иметь в виду, что эта программа может быстро разрушить структуры администрирования вашей системы до степени, когда даже e2fsck уже не поможет.
Измерение фрагментации
Чтобы определить степень фрагментации внутри файла, мы должны узнать, какие блоки данных использует этот файл и сопоставить порядок следования данных блоков с идеальным порядком следования.

Рисунок 6. В нефрагментированном файле блоки располагаются в соответствии с порядком, в котором файловая система будет их читать
Блоки данных файла могут быть установлены тремя различными
способами. Прямой путь - читать диск сектор за сектором и
расшифровывать индивидуальные структуры Ext3, что в итоге приведет к
необходимости перепрограммировать драйвер Ext3.
К счастью, в этом нет необходимости. Библиотека libext2fs
обеспечивает механизмы прямого доступа к работе драйвера файловой
системы. Функции ext2fs_get_next_inode() и
ext2fs_block_iterate() итерируют все дескрипторы,
используемые в файловой системе, и все блоки данных, принадлежащие
дескриптору. Вызов произвольной функции с каждым номером блока данных
можно включить в ext2fs_get_next_inode(), чтобы сравнить
действительное расположение блоков на диске с идеальным порядком
следования. Такой подход использует программа e2fsck, и наша
программа ext2_frag[6].
Программа ext2_frag должна быть запущена с именем устройства, которое нужно проверить (раздел или логический том на системах LVM):
ext2_frag DEVICE [-s|-f|-v|-d] [-i INODE]
По умолчанию, программа проверяет всю файловую систему и выводит
данные о том, фрагментирован ли каждый файл, и в какой степени. Опция
-f для большей ясности ограничивает вывод только
фрагментированными файлами. Опция -s выводит только
статистическую сводку всей системы. Итак, данные о фрагментации
файловой системы на устройстве /dev/sda1 могут быть получены при
помощи команды:
ext2_frag -s /dev/sda1
Опция -i исследует детали фрагментации отдельных файлов
по номерам их дескрипторов; -v и -d выдают
дальнейшие подробности о расположении блоков файла.
Третий способ установить номера блоков, принадлежащих файлу,
использовать программу ioctl, из набора FIBMAP, хотя она
работает только с обычными файлами, а не с директориями. Она
используется в программе filefrag из пакета e2fsprogs,
а также программой fragments[7]. В отличие от
ext2fs_block_iterate(), программа ioctl(FIBMAP)
выводит только номера блоков, и не выводит номера непрямых блоков -
они могут быть идентифицированы только как пробелы в порядке
следования блоков.
Программу fragments нужно запускать с именем директории:
fragments [-r] [-d] [-f] [-b] [-x] DIRECTORY
С опцией -r, программа рекурсивно исследует субдиректории
указанной директории; -d выводит статистику по каждой
субдиректории; добавив -x заставим программу игнорировать
субдиректории, являющиеся точками монтирования других файловых
систем.
Вся файловая система в общем случае проверяется командой:
fragments -d -x /
Опция -f выдает информацию о фрагментации отдельных
файлов; -b добавляет расположение блоков каждого файла.
Ссылки в этой статье