





Библиотека сайта rus-linux.net
Глава 9. Подключение и настройка аппаратных устройств
| Предыдущий раздел | Оглавление | Следующий раздел |
9.3. Клавиатура
Клавиатура к вашему компьютеру уже, скорее всего, подключена, вопрос может состоять только в том, чтобы настроить ее. Настройка клавиатуры заключается в настройке таких вещей, как:
- раскладка клавиатуры;
- скорость повтора посылаемых клавиатурой сигналов в случае удержания клавиш пользователем;
- длительность интервала задержки от момента нажатия клавиши до того момента, когда клавиатура начинает повторять посылку сигналов.
Два последних параметра (скорость повтора и время задержки) устанавливаются с помощью специальной команды kbdrate.
9.3.1. Команда kbdrate
Скорость повтора задается в символах в секунду и может принимать только определенные значения в пределах от 2 до 30 символов в секунду. Но задать (после опции –r) вы можете любое значение в этих пределах, программа сама выберет ближайшее допустимое значение. Число после опции -d задает задержку в миллисекундах (допустимы значения от 250 до 1000 с шагом 250). Чтобы не устанавливать эти значения после каждого перезапуска компьютера, можно добавить в файл /etc/rc.d/rc.sysinit сроку следующего вида:
/sbin/kbdrate -s -r 16 -d 500
где опция -s просто подавляет вывод ненужных в данном случае сообщений. Если эту команду выполнить без указания параметров, для скорости повтора и задержки будут установлены значения по умолчанию: для скорости повтора — 10,9 символов в секунду, а для задержки — 250 миллисекунд.
Еще один вопрос, относящийся к настройке клавиатуры, — это способ изменения положения переключателей NumLock, CapsLock и ScrollLock. Для этого можно воспользоваться командой setleds. Например, для того, чтобы переключатель NumLock был по умолчанию включен, добавьте в файл /etc/rc.d/rc.sysinit следующие строки:
for tty in /dev/tty[1-9]*; do
setleds -D +num < $tty
done
Изменение раскладки клавиатуры — это вопрос значительно более сложный. Но, поскольку этот вопрос имеет большое значение как вообще для настройки клавиатуры, так и для решения проблемы русификации, его необходимо рассмотреть подробнее.
И начать придется с краткого изложения проблем кодировки символов.
9.3.2. Таблицы кодировки символов
В человеческом мире информация представляется последовательностями символов. Каждый символ имеет каноническое изображение, которое позволяет однозначно идентифицировать данный символ. Шрифты задают разные варианты начертания символов.
В вычислительных машинах для представления информации используются цепочки байтов. Поэтому для перевода информации из машинного представления в человеческий необходимы таблицы кодировки символов — таблицы соответствия между символами определенного языка и кодами символов.
Самой известной таблицей кодировки является код ASCII (Американский стандартный код для обмена информацией), который был разработан для передачи текстов по телеграфу задолго до появления компьютеров. Этот код является 7 битовым, т. е. для кодирования символов английского языка, служебных и управляющих символов используются только 128 7-битовых комбинаций. При этом первые 32 комбинации (кода) служат для кодирования управляющих сигналов (начало текста, конец строки, перевод каретки, звонок, конец текста и т. д.).
При разработке первых компьютеров фирмы IBM этот код был использован для представления символов в компьютере. Поскольку в исходном коде ASCII было всего 128 символов, для их кодирования хватило тех однобайтовых кодов, у которых 8-й бит равен 0. Во второй половине кодовой таблицы (значения байта с 8-м битом равным 1) фирма IBM разместила символы псевдографики, математические знаки и некоторые символы из языков, отличных от английского (немецкие умляуты, французские диакритические знаки, символы греческого алфавита и т.п.). Эту кодовую таблицу стали называть кодировкой IBM.
Когда IBM-совместимые персональные компьютеры стали использовать в других странах, потребовалось обеспечить обработку информации на языках, отличных от английского. Для того, чтобы полноценно поддерживать другие языки, фирма IBM ввела в употребление несколько кодовых таблиц, ориентированных на конкретные страны. Так для скандинавских стран была предложена таблица 865 (Nordic), для арабских стран — таблица 864 (Arabic), для Израиля — таблица 862 (Israel) и так далее. В этих таблицах часть кодов из второй половины кодовой таблицы использовалась для представления символов национальных алфавитов (за счет исключения некоторых символов псевдографики). Для представления символов кириллицы была введена кодировка IBM-866.
Однако с русским языком ситуация развивалась особым образом. Очевидно, что замену символов во второй половине кодовой таблицы можно произвести разными способами. В других европейских странах сумели найти единое решение, а для русского языка появилось несколько разных таблиц кодировки символов кириллицы: IBM-866, CP-1251, KOI8-R, ISO-8859-5. Все они одинаково изображают символы первой половины таблицы (от 0 до 127) и различаются представлением символов русского алфавита и псевдографики во второй половине.
Одна из самых известных кодовых таблиц для кириллицы получила название альтернативной (по отношению к кодировке IBM-866, наверное). Она была разработана фирмой Microsoft для MS-DOS. При ее разработке постарались сделать так, чтобы результирующая таблица была насколько это возможно совместима с кодировкой IBM. Поэтому альтернативная кодировка — это кодировка IBM, в которой все специфические европейские символы в верхней половине были заменены на кириллицу, оставляя псевдографические символы нетронутыми. Следовательно, это не портило вид программ, использующих для работы текстовые окна, что было очень существенным фактором для работы в среде MS-DOS, основой которой был именно текстовый режим.
Кодировка KOI-8 была разработана изначально с ориентировкой на UNIX. Так как UNIX в своей основе сетевая ОС, то основной идей при создании KOI-8 была идея об обеспечении перемещения кириллической информации по сети. Но для передачи-то использовался 7-битный стандарт ASCII. Разработчики поместили кириллические символы в верхней части таблицы таким образом, что позиции кириллических символов соответствуют их фонетическим аналогам в английском алфавите в нижней части таблицы. Это означает, что, если в тексте, написанном в KOI-8, мы убираем восьмой бит каждого символа, то мы все еще имеем "читабельный" текст, хотя он и написан английскими символами! Не удивительно, что KOI8-R быстро стал фактически стандартом для кириллицы в Интернет, что и нашло отражение в RFC 1489 ("Registration of a Cyrillic Character Set"). Автором этого документа является Андрей А. Чернов, который проделал огромный объем работы, чтобы превратить KOI-8 в стандарт Интернет.
Международная организация по стандартизации (ISO) внесла свою лепту в создание различных кодировок кириллицы, когда ввела семейство стандартов, известных как ISO 8859-X. Это семейство есть совокупность 8-битных кодировок, где младшая половина каждой кодировки (символы с кодами 0—127) соответствует ASCII, а старшая половина определяет символы для различных языков. Например:
- 8859-0 — новый европейский стандарт (так называемый Latin 0);
- 8859-1 — Европа, Латинская Америка (также известный как Latin 1);
- 8859-2 — Восточная Европа;
- 8859-5 — кириллица;
- 8859-8 — идиш.
Фирма Microsoft еще больше запутала ситуацию с кодировками для русского языка, когда при разработке Windows ввела кодировку CP-1251.
Таблицы кодировок, содержащие 256 символов, стали называть расширенными кодами ASCII (потому что в основе любой из них лежит 128-символьный код ASCII), кодовыми страницами или английским термином character set (который часто сокращают до charset).
Но в мире есть языки, такие как китайский или японский, для которых 256 символов в принципе недостаточно. Кроме того, всегда существует проблема вывода или сохранения в одном файле одновременно текстов на разных языках (например, при цитировании). Поэтому была разработана универсальная кодовая таблица UNICODE, содержащая символы, применяемые в языках всех народов мира, а также различные служебные и вспомогательные символы (знаки препинания, математические и технические символы, стрелки, диакритические знаки и т. д.). Очевидно, что одного байта недостаточно для кодирования такого большого множества символов. Поэтому в UNICODE используются 16-битовые (2-байтовые) коды, что позволяет представить 65 536 символов. К настоящему времени задействовано около 49 000 кодов (последнее значительное изменение — введение символа валюты EURO в сентябре 1998 г.). Для совместимости с предыдущими кодировками первые 128 кодов совпадают со стандартом ASCII. На рис. 9.1 схематично представлено размещение символов разных языков в кодовом пространстве UNICODE.
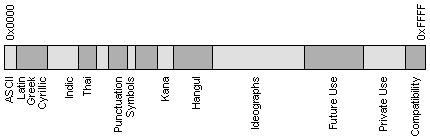
Рис. 9.1. Структура UNICODE.
В стандарте UNICODE кроме определенного двоичного кода (эти коды принято обозначать буквой U, после которой следуют знак + и собственно код в шестнадцатеричном представлении) каждому символу присвоено определенное имя. В следующей таблице приведено несколько примеров кодов и имен символов из стандарта UNICODE.
Таблица 9.2. Примеры именования кодов UNICODE
|
Символ |
UNICODE |
Название символа (Character Name) |
|
A |
U+0041 |
LATIN CAPITAL LETTER A |
|
a |
U+0061 |
LATIN SMALL LETTER A |
|
Ю |
U+042E |
CYRILLIC CAPITAL LETTER YU |
|
+ |
U+002B |
PLUS SIGN |
|
1 |
U+0031 |
DIGIT ONE |
|
Ω |
U+03A9 |
GREEK CAPITAL LETTER OMEGA |
|
┻ |
U+2569 |
BOX DRAWINGS DOUBLE UP AND HORIZONTAL |
Еще одним компонентом стандарта UNICODE являются алгоритмы для взаимно-однозначного преобразования кодов UNICODE в последовательности байтов переменной длины. Необходимость таких алгоритмов обусловлена тем, что не все приложения умеют работать с UNICODE. Некоторые приложения понимают только 7-битовые ASCII-коды, другие приложения — 8-битовые (расширенные) ASCII-коды. Для представления символов, не поместившихся, соответственно, в 128 символьный или 256 символьный набор, такие приложения используют цепочки байтов переменной длины. Алгоритм UTF-7 служит для обратимого преобразования кодов UNICODE в цепочки 7-битовых ASCII-кодов, а UTF-8 — для обратимого преобразования кодов UNICODE в цепочки из расширенных 8-битовых ASCII-кодов. Подробнее об алгоритмах UTF-7 и UTF-8 и кодировках вообще вы можете прочитать в [П11.3 — П11.5].
Отметим, что и ASCII, и UNICODE, и другие стандарты кодировки символов не определяют изображения символов, а только состав набора символов и способ его представления в компьютере. Кроме того (что, может быть, не сразу очевидно) они еще задают порядок перечисления символов в наборе, который очень важен, так как он влияет самым существенным образом на алгоритмы сортировки. Именно таблицу соответствия символов из какого-то определенного набора (скажем, символов, применяемых для представления информации на английском языке, или на разных языках, как в случае с UNICODE) и обозначают термином таблица кодировки символов или charset. Каждая стандартная кодировка имеет имя, например, KOI8-R, ISO_8859-1, ASCII. К сожалению, стандарта на имена кодировок не существует.
9.3.3. Ввод символов с клавиатуры
В процессе ввода символов с клавиатуры можно выделить четыре соответствия или отображения (в математическом смысле этого слова).
- На клавиатуру нанесены (или наклеены) символы. Это первое соответствие: символ -> клавиша.
- Микропроцессор клавиатуры реализует второе соответствие: комбинация клавиш -> скан-код.
- Далее скан-код клавиатуры преобразуется в код символа, понятный приложению, например, ASCII-код или UNICODE; это третье соответствие: скан-код -> код символа, используемый приложением.
- И, наконец, для изображения символа на экране или принтере используется четвертое соответствие: ASCII-код -> изображение символа.
О наличии этих соответствий полезно помнить при рассмотрении вопросов взаимодействия пользователя с приложениями. А теперь вернемся к вопросу о том, как работает клавиатура.
Управление работой клавиатуры в текстовом режиме осуществляется драйвером терминала, который входит в состав ядра Linux. Драйвер терминала состоит как бы из двух отдельных драйверов: драйвера клавиатуры и драйвера экрана. Драйвер клавиатуры обрабатывает нажатия клавиш пользователем и передает результат прикладной программе, которая, в свою очередь, посылает экранному драйверу символы, которые должны быть отображены на экране.
При каждом нажатии на клавишу микропроцессор клавиатуры генерирует последовательность так называемых скан-кодов, которая представляет собой последовательность из двух или большего числа байтов. Эта последовательность передается драйверу клавиатуры, который может работать в одном из 4 режимов:
- K_RAW, когда прикладной программе передается последовательность скан-кодов, сгенерированных клавиатурой. Этот режим используется при работе с приложениями, которые имеют собственный драйвер клавиатуры. Примером такого приложения является система X Window.
- K_MEDIUMRAW, когда скан-код клавиши преобразуется в один из 127 возможных кодов, называемых кодами клавиш (keycodes). Каждый код клавиши состоит из кода нажатия клавиши и кода отпускания клавиши. Преобразование скан-кодов в коды клавиш осуществляется в соответствии с внутренней таблицей драйвера клавиатуры. Обычно эта таблица фиксирована, и изменять ее не требуется, хотя в системе существуют команды getkeycodes и setkeycodes, с помощью которых можно просмотреть или изменить некоторые соответствия в этой таблице. Эти команды используются только в том случае, если у вас программируемая клавиатура.
- K_XLATE (или режим ASCII), когда код клавиши преобразуется в ASCII-код символа или некоторую последовательность ASCII-кодов символов в соответствии с таблицей раскладки клавиатуры, которая хранится в виде отдельного файла. Например, для Red Hat Linux 5.2 по умолчанию используется файл defkeymap.map в каталоге /usr/lib/kbd/keymaps/i386/qwerty. Команда dumpkeys выводит на экран содержание действующей в данный момент таблицы раскладки клавиатуры, а команда loadkeys загружает в драйвер таблицу раскладки клавиатуры из указанного файла.
- K_UNICODE, когда скан-коды преобразуются в двухбайтовые коды таблицы UNICODE (этот режим пока используется очень редко).
Выбор режима работы драйвера терминала определяется прикладной программой, которая в данный момент времени выполняется компьютером. Чаще всего используется третий режим, когда код клавиши либо преобразуется в ASCII-код символа или строку таких кодов в соответствии с таблицей раскладки клавиатуры, либо выполняется действие, определенное для конкретной комбинации клавиш в таблице раскладки клавиатуры. Например, нажатие <Ctrl>+<Alt>+<Del> эквивалентно вызову команды shutdown -r 0, т. е. приводит к останову системы и перезагрузке компьютера.
Режим работы драйвера клавиатуры можно узнать или изменить с помощью команды kbd_mode. Однако не торопитесь менять режим, так как перевод драйвера клавиатуры в режим RAW или MEDIUMRAW может сделать его недоступным для большинства приложений, т. е. легко можно вообще потерять возможность ввода команд.
Не для всех клавиш и комбинаций клавиш процесс обработки проходит так прямолинейно, как это описано выше. Во-первых, имеется несколько особых клавиш, так называемых клавиш-переключателей. Это клавиши <Shift> (левая и правая), <Alt> (левая и правая), <Ctrl> (левая и правая), <Caps Lock>, <Num Lock>, <Ins>. Нажатие на клавишу-переключатель изменяет значение одного из разрядов (битов) в двухбайтовом слове, которое хранит состояние клавиш-переключателей. Поэтому драйвер клавиатуры вначале должен проанализировать состояние этого слова, а затем соответственно преобразовать коды.
Клавиша <Ins> является единственной из клавиш переключателей, нажатие которой не только заносит признак в слово состояния переключателей, но и порождает передачу соответствующего кода драйверу терминала.
С помощью ASCII-кодов можно представить 256 различных символов, а, значит, ASCII-коды можно сопоставить 256-ти кодам клавиш. Учитывая наличие клавиш переключателей, комбинаций клавиш существует гораздо больше. Поэтому некоторые комбинации клавиш драйвер клавиатуры преобразует в цепочки из нескольких байтов, так называемые Escape-последовательности, в которых два первых байта служат признаком Escape-последовательности, а последующие представляют собой собственно значащие байты. Escape-последовательности обычно представляют те комбинации клавиш, которые используются для управления работой программ, таких как стрелки, клавиши <Page Down>, <Page Up>, <Home>, <End>, <F1> — <F12>, <Ins>, <Del> и т. д.
В комплект Red Hat Linux входит программа showkey, которая показывает все три вида кодов, связанных с нажатиями клавиш. Если запустить эту программу с параметром -s, она будет показывать скан-коды нажатий клавиш (чтобы выйти из программы, надо просто выждать 10 секунд, не нажимая в это время ни одной клавиши). Ввод команды showkey -k приводит к выводу на экран кодов клавиш (выходим так же). Ввод команды showkey -m позволяет просмотреть ASCII-коды, которые выдаются драйвером клавиатуры после того, как скан-код клавиши будет оттранслирован с помощью таблицы раскладки клавиатуры. Попробуйте в этом режиме нажать <Ctrl>+<=> или <Ctrl>+<Esc>, и вы увидите, что не каждая комбинация клавиш порождает ASCII-код (попробуйте также клавиши-переключатели). В новых версиях программы showkey появилась опция –u, при которой отображаются коды UNICODE.
Примечания:
Если вы уже перешли в графический режим, то программа showkey может работать некорректно, о чем она вежливо сообщает при запуске. Обратите внимание на эти сообщения! Кстати, showkey неправильно работает не только в графическом режиме, но и при подключении через telnet и т.п.
Поскольку чаще всего используется режим преобразования в ASCII-коды, например, при работе в текстовом режиме и в эмуляторе терминала, таблица раскладки клавиатуры имеет такое большое значение. Возможно, вас не устраивает та раскладка, которая используется по умолчанию. Давайте рассмотрим, как ее поменять.
9.3.4. Изменение раскладки клавиатуры для текстового режима
В дистрибутиве Red Hat загрузка таблицы раскладки клавиатуры и системного фонта производится в файле /etc/rc.d/rc.sysinit. Но лезть в этот файл и корректировать его содержимое для изменения раскладки не требуется. Дело в том, что файлы с различными раскладками находятся в каталоге /lib/kbd/keymaps/i386/qwerty или /usr/lib/kbd/keymaps/i386/qwerty, а выбор конкретного файла раскладки задается файлом /etc/sysconfig/keyboard. Этот файл можно отредактировать вручную, а можно — с помощью программы kbdconfig.
Команда kbdconfig прописывает новое значение в файл /etc/sysconfig/keyboard и загружает указанную таблицу в оперативную память. Того же эффекта можно добиться, если прописать имя новой таблицы в файл /etc/sysconfig/keyboard и выполнить команду
[root]# /etc/rc.d/init.d/keytable start
Оба этих варианта позволяют переключиться на новую раскладку "на ходу".
Если же только откорректировать содержимое файла /etc/sysconfig/keyboard, то перезагрузка таблицы произойдет только после перезапуска компьютера или после выполнения команды (в примере загружается раскладка из файла ru-win.map):
[root]# loadkeys /usr/lib/kbd/keymaps/i386/qwerty/ru-win.map
Впрочем, переключение "на ходу" вряд ли требуется делать, поскольку обычно человек привыкает к одной раскладке, и пальцы сами находят привычные клавиши, так что всякое изменение тут только осложнит работу. Поэтому имеет смысл поэкспериментировать один раз с различными раскладками, выбрать наиболее удобную (считай, привычную) и на этом можно успокоиться.
При установке русифицированных дистрибутивов Linux (по крайней мере Black Cat) обычно выбирается раскладка ru1 (точка на <Shift>+<7>, запятая на <Shift>+<6>). Для тех, кто привык работать в Windows, может оказаться более привычной раскладка как в Windows (в русском регистре точка и запятая находятся рядом с правой кнопкой <Shift>). Для таких пользователей имеется раскладка ru_ms. Если вас не удовлетворяют эти варианты, то можете выбрать любую из имеющихся в вашей системе, либо найти что-либо подходящее в Интернет. Предположим, что вы нашли и скачали файл ru_win_ctrl.map.gz от IP Labs (http://www.iplabs.ru/Linux/ru_win_ctrl.map.gz). Остается только положить этот файл в /usr/lib/kbd/keytables/i386/qwerty/, запустить kbdconfig и выбрать ru_win_ctrl.
После установки новой таблицы раскладки клавиатуры иногда возникают затруднения в определении того, какая именно клавиша или комбинация клавиш переключает из режима ввода английских символов в режим ввода русских. Гадать тут не надо, достаточно просмотреть файл таблицы раскладки клавиатуры. Обычно в самом начале файла эта комбинация указывается открытым текстом, правда, в большинстве случаев английским. (Если вы забыли, какая именно таблица загружена, то посмотрите файл /etc/sysconfig/keyboard).
9.3.5. Создание собственной раскладки
Если вас не устраивает ни одна из тех раскладок клавиатуры, которые имеются в каталоге /usr/lib/kbd/keytables/i386/qwerty/, можете попробовать подправить ту раскладку, которая ближе всего к вашему идеалу. Попробуем показать, как это делается, на примере выбора клавиши переключения между русской и латинской клавиатурой (этот совет позаимствован у Романа Минакова, pharao@kma.mk.ua).
Для переключения между русской и латинской клавиатурой часто используется правая клавиша <Ctrl>, в то время как на любой более-менее современной IBM-клавиатуре есть три клавиши, которые, как правило, в Linux не задействованы. Вот одну из них и приспособим для переключения алфавитов. Для начала надо узнать какой у них код. Запускаем команду showkey с опцией --keycodes (запуск showkey, естественно, производится с консоли и необходимо предварительно выйти из mc) и последовательно (слева направо) нажимаем эти три клавиши, чтобы узнать их коды:
[root]# showkey --keycodes
kb mode was XLATE
press any key (program terminates after 10s of last keypress)...
keycode 125 press
keycode 125 release
keycode 126 press
keycode 126 release
keycode 127 press
keycode 127 release
Числа 125, 126, 127 и есть коды этих клавиш. Далее переходим в каталог /usr/lib/kbd/keytables/i386/qwerty, находим файл, который используется в данный момент (что-то типа ru1.map, если в каталоге /usr/lib/kbd/keytables/i386/qwerty вы найдете только ru1.map.gz, то выполните предварительно разархивацию: gunzip ru1.map.gz).
Для того, чтобы заставить клавишу работать как временный переключатель с русского на латинский (пока клавиша удерживается), надо придать ей значение AltGr, а чтобы она использовалась как постоянный переключатель — AltGr_Lock. Находим внутри ru1.map:
keycode 125 =
keycode 126 =
keycode 127 =
и меняем на:
keycode 125 =
keycode 126 = AltGr
keycode 127 = AltGr_Lock
Далее надо изменить установки тех клавиш, которые ранее использовались для переключения. Например, если в качестве постоянного переключателя использовалась клавиша <Ctrl> (код клавиши 97), находим строку
keycode 97 =
и вписываем:
keycode 97 = Control
В итоге получаем: клавиша, расположенная возле правой клавиши <Ctrl>, — фиксированный переключатель "рус/лат", а та что рядом с правой клавишей <Alt> — временный переключатель "рус/лат" (т. е. действующий только на то время, пока удерживается в нажатом положении соответствующая клавиша).
После редактирования сохраняем файл под новым именем (например, mymap.kmap) и записываем это имя в /etc/sysconfig/keyboard.
9.3.6. Работа с клавиатурой в графическом режиме
В графическом режиме работа с клавиатурой организована значительно сложнее. Подробное описание этого вопроса можно найти в обстоятельном (но, к сожалению, очень трудном для понимания) материале Ивана Паскаля "X Keyboard Extension" [П11.6]. Приведем очень краткий конспект основных положений этого материала.
Как было сказано выше, при работе в системе X Window клавиатура передает этой системе чистые скан-коды. Клавиатурный модуль X-сервера передает сообщение о нажатии (и отпускании) кнопки прикладной программе. В этом сообщении указывается только скан-код нажатой кнопки и "состояние клавиатуры" — набор битовых "флагов", который отражает состояние клавиш-модификаторов (<Shift>, <Control>, <Alt>, <CapsLock> и т.п.). "Клиентская" программа должна сама решить — какой код символа, соответствующий скан-коду, надо выбрать при таком сочетании битов-модификаторов. Разумеется, при создании программ никто не пишет каждый раз программу для интерпретации скан-кодов. Для этих целей существуют специальные подпрограммы в библиотеке X-lib. Процедуры из X-lib, зная скан-код и "состояние клавиатуры", выбирают подходящий символ в соответствии с таблицей символов, которая хранится в X-сервере и которую они обычно "запрашивают" у X-сервера при старте программы. Эта таблицу можно менять с помощью утилиты xmodmap. Действующая таблица выводится командой xmodmap –pk.
9.3.7. Модуль XKB
В последних версиях дистрибутивов Linux устанавливается дополнительный модуль работы с клавиатурой — XKB. Модуль XKB точно также сообщает программе только скан-код и свое "состояние". Но в отличие от "старого" модуля (который называют "core protocol", или "core-модуль") XKB имеет более сложную таблицу символов, другой набор "модификаторов" и некоторые дополнительные параметры "состояния клавиатуры". Поэтому для полноценной работы с XKB, библиотека X-lib должна содержать модифицированные процедуры интерпретации скан-кодов (процедуры, "знающие" о XKB). Естественно, все версии X-Window, у которых X-сервер "укомплектован" модулем XKB, имеют и соответствующую библиотеку X-lib. Таким образом, XKB фактически делится на две части — модуль, встроенный в X-сервер, и набор подпрограмм, входящих в библиотеку X-lib.
Однако, поскольку существуют программы, которые были рассчитаны на работу со старой библиотекой X-lib, "не подозревающей" о существовании XKB, возникает "проблема совместимости". То есть, модуль XKB должен уметь общаться как со "своей" X-lib, так и со "старой" (работающей в соответствии с "core protocol"). Естественно, "общение" не ограничивается только передачей сообщений о нажатии/отпускании клавиш. Процедуры X-lib могут обращаться к X-серверу с различными запросами (например — взять таблицу символов) и командами (например, поменять в этой таблице расположение символов). На все эти запросы и команды модуль XKB должен реагировать так, чтобы даже "старая" X-lib могла работать правильно (насколько это возможно).
При старте X-сервера, модуль XKB зачитывает все необходимые данные из текстовых файлов, которые образуют "базу данных" настроек XKB. Строго говоря, большинство из этих файлов сам модуль XKB не читает. Он вызывает программу xkbcomp, которая переводит содержимое этих файлов в двоичный формат, понятный непосредственно модулю XKB. Но для настройки это не так уж важно, поскольку вызов xkbcomp происходит автоматически, незаметно для пользователя.
База данных, необходимых модулю XKB, находится в каталоге /usr/X11R6//lib/X11/xkb и состоит из 5 компонентов, расположенных в подкаталогах с именами:
- keycodes
Здесь расположены таблицы, которые просто задают символические имена для скан-кодов. Например
<TLDE>= 49;
<AE01> = 10;
- types
Здесь описываются возможные типы клавиш. Тип клавиши определяет как должно меняться значение, выдаваемое клавишей в зависимости от модификаторов (<Control>, <Shift> и т. п.). Так, например, "буквенные" клавиши относятся к типу ALPHABETIC, что означает, что они имеют разное значение в зависимости от состояния <Shift> и <Caps Lock>. А клавиша <Enter> имеет тип ONE_LEVEL, что означает, что ее значение всегда одно и то же, независимо от состояния модификаторов.
- compat (сокращение от compability)
Здесь описывается "поведение" модификаторов. В модуле XKB имеется несколько внутренних переменных, которые, в конечном счете, и определяют, какой символ будет генерироваться при нажатии клавиши в конкретной ситуации. Так вот, в файлах из каталога compat как раз описывается, как должны меняться эти переменные при нажатии различных клавиш-модификаторов. В этом же разделе обычно описывается и поведение "лампочек-индикаторов" на клавиатуре.
- symbols
Это каталог содержит таблицы, в которых для каждого скан-кода (задаваемого именем скан-кода, определенным в keycodes) перечисляются все значения (symbols), которые должна выдавать клавиша. Естественно, количество различных значений зависит от типа клавиши (которые описываются в types), а какое именно значение будет выдано в конкретной ситуации, определяется состоянием модификаторов и их "поведением" (которое описывается в compat).
- geometry
Здесь описываются варианты "геометрии" клавиатуры, т. е. расположение клавиш на клавиатуре. Эти описания нужны не столько самому X-серверу, сколько прикладным программам, которые рисуют изображение клавиатуры.
Надо сказать, что в каждом из этих каталогов имеется несколько файлов (иногда, довольно много) с разными настройками. Более того, каждый файл внутри себя может содержать несколько блоков (секций, разделов) вида
тип_компонента "имя_блока" {........};
Поэтому, для того, чтобы выбрать конкретную настройку, ее обычно указывают в виде имя_файла(имя_блока), например, us(pc104). В то же время, обычно один из блоков в файле (не обязательно самый первый) помечается флагом default. Это означает, что если указать только имя файла, то будет выбран именно этот блок.
Полная конфигурация XKB задается в секции ImputDevice, определяющей клавиатуру, файла конфигурирования пакета XFree86, т. е. в файле /etc/X11/XF86Config-4. При этом имеется три способа задания конфигурации клавиатуры в этом файле.
Первый способ задания конфигурации заключается в том, что вы можете указать непосредственно каждый из компонентов, например
Option "XkbKeycodes" "xfree86" Option "XkbTypes" "default" Option "XkbCompat" "default" Option "XkbSymbols" "us(pc104)" Option "XkbGeometry" "pc(pc104)"
Как легко догадаться, это означает, что:
- описание keycodes берется из файла "xfree86" в подкаталоге keycodes, причем из файла будет выбран тот блок, который помечен в нем флагом default;
- описание types берется из файла "default" в подкаталоге types;
- описание compat берется из файла "default" в подкаталоге compat;
- описание symbols берется из файла "us" в подкаталоге symbols, причем будет выбран блок "pc104";
- описание geometry берется из файла "pc" в подкаталоге geometry, блок "pc104";
Надо заметить, что в любом блоке (в любых компонентах) может встретиться инструкция include "имя_файла(имя_блока)" (естественно, имя_блока может отсутствовать) что означает, что в текущий блок должно быть вставлено другое описание из указанного файла (указанного блока). Поэтому полное описание может неявно включать в себя данные из многих других файлов, кроме тех, которые вы явно укажете в файле конфигурации X-сервера.
Второй способ задания конфигурации клавиатуры заключается в том, что вы можете указать одной инструкцией сразу полный набор настроек. Такие наборы называются keymaps и, также как и обычные компоненты конфигурации XKB, располагаются в отдельных файлах (которые, тоже содержат в себе несколько именованных блоков) в подкаталоге keymap.
Обычно, в каждом блоке в файлах из keymap просто указывается из каких файлов XKB должен извлечь соответствующие компоненты (хотя, в принципе, там может быть и полное описание всех компонентов), например
xkb_keymap "ru" {
xkb_keycodes { include "xfree86" };
xkb_types { include "default" };
xkb_compatibility { include "default" };
xkb_symbols { include "en_US(pc105)+ru" };
xkb_geometry { include "pc(pc102)" };
};
Обратите внимание, что в одной инструкции include может быть указано несколько файлов (блоков) через знак "+". Понятно, что это означает, что должны быть вставлены последовательно все указанные файлы.
Таким образом, в файле конфигурации X-сервера можно вместо пяти компонентов указать сразу один из готовых наборов keymap, например
Option "XkbKeymap" "xfree86(ru)"
Кроме того, эти два способа можно комбинировать. Например, если вы выбрали один из подходящих наборов keymap, но вас не устраивает один из компонентов, например geometry, то в файле конфигурации можно указать
Option "XkbKeymap" "xfree86(ru)"
Option "XkbGeometry" "pc(pc104)"
При этом, в соответствии с первой инструкцией, все компоненты будут взяты из keymap "xfree86(ru)", а вторая инструкция "перепишет" geometry, не затрагивая остальные компоненты.
Третий способ несколько отличается от предыдущих. Набор настроек можно указывать не перечислением компонентов, а с помощью задания "правил" (Rules), "модели" (Model), "схемы" (Layout), "варианта" (Variant) и "опций" (Option).
В этом наборе только Rules представляют собой некий файл (эти файлы тоже находятся в отдельном подкаталоге rules каталога /usr/X11R6//lib/X11/xkb), в котором находится таблица правил — "как выбрать все пять компонентов настроек XKB в зависимости от значений Model, Layout и т. д.". Все остальные параметры представляют собой просто "ключевые слова":
- Model обычно определяет тип "железа" — клавиатуры;
- Layout — язык или, точнее, алфавит, который "навешивается" на кнопки клавиатуры;
- Variant — различные варианты размещения знаков алфавита (заданных Layout'ом);
- Options — обычно меняет "поведение" или "расположение" модификаторов Control и Group (переключатель групп — это переключатель "языка", например, русский/латинский).
По этим словам модуль XKB при старте ищет в таблицах "правил" подходящие файлы настроек (keycodes, types, compat, symbols и geometry). Другими словами, Rules определяет некоторую функцию, аргументами которой являются Model, Layout, Variant и Options, а значение, которое возвращает эта функция, представляет собой полный набор из компонентов настроек XKB — keycodes, types, compat, symbols и geometry (или полная keymap).
Итак, если вы используете третий способ указания конфигурации XKB, то в файле конфигурации X-сервера, надо задать параметры XkbRules, XkbModel, XkbLayout и, если вам нужно что-то не совсем стандартное — XkbVariant и XkbOptions.
Например,
Option "XkbRules" "xfree86" Option "XkbModel" "pc104" Option "XkbLayout" "ru" Option "XkbVariant" "" Option "XkbOptions" "ctrl:ctrl_ac"
означает, что модуль XKB должен в соответствии с правилами, описанными в файле ./rules/xfree86, выбрать настройки для клавиатуры типа "pc104" (104 кнопки), русского алфавита (английский алфавит будет включен "по умолчанию"), вариант — "стандартный" (т. е., этот параметр можно было не писать) и, наконец, дополнительные опции для вашей "раскладки клавиатуры" — "ctrl:ctrl_ac".
Что означают различные опции, а также какие "модели" и "схемы" определены в "правилах" (и что они означают), можно посмотреть в файле xfree86.lst (или другом файле *.lst, если вы выбрали "правила", отличные от xfree86), который находится в той же директории, что и файл "правил", т. е. в подкаталоге rules.
Небольшое отступление о клавише — переключателе "рус/лат". В первых вариантах модуля XKB раскладка "русской" клавиатуры включала в себя и "переключатель групп" — рус/лат, "подвешенный" на клавишу CapsLock. С одной стороны это было удобно: в простейшем случае достаточно было выбрать "русскую раскладку" и вы автоматически получали и клавишу для переключения "на русский". Но, с другой стороны, это было неудобно для тех, кто предпочитает в качестве переключателя рус/лат другую клавишу (или комбинацию клавиш). Конечно, выбрать другой переключатель не составляло труда, но при этом оставался и переключатель на CapsLock, что многим не нравилось. Для того, чтобы убрать его, надо было "залезть" в соответствующий файл и вручную подправлять соответствующую раскладку.
В конце концов (начиная с версии 3.3.4) сами разработчики Xfree86 убрали этот "переключатель" из "русской раскладки". Но, в связи с этим появились и некоторые проблемы — теперь клавишу-переключатель надо явно "заказывать" при конфигурировании XKB.
9.3.8. Несколько практических рекомендаций по настройке модуля XKB
Самый простой способ — использовать программу для автоматической настройки X-Window. В XFree86 версии 3 такая программа называется XF86Setup. Она использует третий метод задания конфигурации XKB. При этом "по умолчанию" используются "правила" (XkbRules) — xfree86. Вам нужно будет только выбрать "модель" (XkbModel), "схему" (XkbLayout) и "способ переключения групп" (переключатель "РУС/ЛАТ").
Кроме того, при желании вы можете изменить "положение клавиши Ctrl". Естественно, в конфигурации это будет выглядеть как соответствующие строчки XkbOptions. Итак, запустите программу XF86Setup, выберите раздел Keyboard. В этом разделе выберите из меню Model (тип клавиатуры) и Layout (язык). Не забудьте отметить в отдельных списках (в правой части) подходящий "переключатель групп" и, если хотите — "расположение Ctrl". При выходе из программы она запишет соответствующие строчки в файл конфигурации Xfree86 в секции Keyboard.
А теперь рассмотрим то, как можно задать эти настройки путем прямого редактирования секции InputDevice (Keyboard) файла /etc/X11/XF86Config.
Прежде всего, надо сказать, что "ключевыми словами" в этих настройках будут:
- xfree86 — название "архитектуры" X-Window;
- pc101 (pc104, pc105 и т.п.) — тип клавиатуры (количество кнопок);
- ru — название "раскладки клавиатуры" с русским алфавитом.
Проще всего сразу задать конфигурацию клавиатуры с помощью keymap. В файлах конфигурации есть набор "полных keymap'ов" для архитектуры xfree86, отличающихся "языком". Все они лежат в файле xfree86, а название блока внутри файла отражает название "языка" (точнее — алфавита) — xfree86(us), xfree86(fr), xfree86(ru) и т. д. Полный список keymap-файлов можно посмотреть в файле /usr/X11R6//lib/X11/xkb/keymap.dir.
Для "русифицированной" клавиатуры вполне подойдет
Option "XkbKeymap" "xfree86(ru)"
К сожалению, после исключения CapsLock как переключателя рус/лат из русской раскладки (см. замечание в конце предыдущего раздела) получилось так, что "полная keymap" для русского языка осталась вообще без какого-либо переключателя "по умолчанию". Но вы можете добавить его вручную. Для этого придется найти в файле /keymap/xfree86 блок "ru". И дописать в строчку xkb_symbols ссылку на описание соответствующего переключателя групп. Для CapsLock это будет — group(caps_toggle). То есть, строчка xkb_symbols будет выглядеть как
xkb_symbols { include "en_US(pc105)+ru+group(caps_toggle)"};
Полный список возможных переключателей групп (т. е. возможных переключателей "рус/лат") можно найти в файле /usr/X11R6//lib/X11/xkb/symbols/group (проведите в этом файле поиск по ключевому слову xkb_symbols).
Теперь рассмотрим случай, когда для задания конфигурации клавиатуры используется третий способ — через "правила", "модель", "схему" и т. д. Как было сказано выше:
- название "правил" (rules) соответствует "архитектуре" (xfree86);
- "модель" (model) соответствует типу клавиатуры (pc101, pc102 и т.п.);
- "схема" (layout) отражает "язык" (ru).
Поэтому, подходящая конфигурация будет выглядеть примерно так:
Option "XkbRules" "xfree86"
Option "XkbModel" "pc104"
Option "XkbLayout" "ru"
С помощью строки XkbOptions можно подобрать "поведение" управляющих клавиш. Возможные значения XkbOptions и их смысл можно подсмотреть в файле /rules/xfree86.lst в той части, которая начинается строкой "! option".
Не забудьте, что, как и в предыдущем случае, надо явно выбрать переключатель групп. Для CapsLock это будет
Option "XkbOptions" "grp:caps_toggle"
И, наконец, рассмотрим первый способ — описание отдельных компонентов настройки (keycodes, compat, types, symbols, geometry).
Если вы не знаете с чего начать, подсмотрите соответствующий набор в keymap. Или попробуйте "вычислить" его через rules/model/layout. Чаще всего подойдут следующие значения:
- для keycodes выбрать файл xfree86;
- для types и compat подойдут файлы default ("по умолчанию") или complete ("полная");
- geometry, скорее всего, "pc", а количество кнопок задается названием блока в файле pc — pc(pc101), pc(pc102), pc(pc104). Полный список "геометрий" имеется в файле /usr/X11R6/lib/X11/xkb/geometry.dir.
А вот на symbols обратите особое внимание. Файл symbols/ru описывает только "буквенные" клавиши. Если вы укажете только его, то у вас не будут работать все остальные кнопки (включая Enter, Shift/Ctrl/Alt, F1-F12 и т. д.). Поэтому symbols должен состоять по крайней мере из двух файлов — en_US(pc101) (в скобках — тип клавиатуры) и, собственно, ru. Полный список symbols — в файле /usr/X11R6/lib/X11/xkb/symbols.dir.
Сюда же надо добавить и описание подходящего "переключателя рус/лат" (как уже говорилось, их перечень — в файле symbols/group).
Для первого метода список может выглядеть так
Options "XkbKeycodes" "xfree86" Options "XkbTypes" "complete" Options "XkbCompat" "complete" Options "XkbSymbols" "en_US(pc101)+ru+group(alt_shift_toggle)" Options "XkbGeometry" "pc(pc101)"
Если вам хочется задать дополнительные изменения "поведения" управляющих клавиш (то, что в третьем методе задается XkbOptions), то подсмотрите подходящую "добавку" в rules/xfree86.lst и "приплюсуйте" ее в строчку XkbSymbols. Например,
XkbSymbols "en_US(pc101)+ru+group(shift_toggle)+ctrl(ctrl_ac)"
На этом мы ограничим описание методов настройки клавиатуры, а точнее — настройки модуля XKB. Если вы хотите разобраться с этим детальнее, то обратитесь к исходному материалу И. Паскаля [П11.6].
| Предыдущий раздел | Оглавление | Следующий раздел |